Linux系统启动过程简介
发布时间: 2024-01-23 04:32:22 阅读量: 49 订阅数: 43 
# 1. 引言
## 1.1 什么是Linux系统启动
Linux系统启动是指从计算机开启到操作系统完全加载并准备好接受用户登录的整个过程。在Linux系统中,启动过程是一个复杂的过程,包括BIOS的初始化、引导加载程序的加载、内核的启动、系统服务的启动以及用户登录过程等。
## 1.2 Linux系统启动的重要性
Linux系统启动是整个计算机系统正常运行的基础,它负责初始化硬件设备、加载操作系统、启动系统服务,为用户提供一个可用的操作环境。一个良好的启动过程是保证系统稳定性和可靠性的关键。因此,了解Linux系统的启动过程对于系统管理员、开发人员和运维人员来说是非常重要的。在故障排除和性能优化方面,对启动过程的理解也能帮助我们更好地解决问题和提高系统性能。
接下来,我们将详细介绍Linux系统启动的各个环节,并深入探讨每个环节的作用和关键步骤。让我们一起开始吧!
# 2. BIOS(基本输入输出系统)的作用
BIOS (Basic Input Output System) 是计算机系统中的一个重要组成部分,它负责在计算机启动时进行初始化和自检,并为操作系统的加载和执行提供基本的输入输出功能。
### 2.1 BIOS的定义
BIOS 是嵌入在计算机主板上的一组固件程序,它与硬件紧密相关,并提供了访问硬件功能的接口。它通常存储在主板的只读存储器中,可以直接被计算机系统引导。
### 2.2 BIOS初始化过程
当计算机电源启动时,BIOS 程序会首先进行初始化过程。具体步骤如下:
1. 电源自检:BIOS 检测计算机电源是否正常,并根据需要启动电源自检。
2. 启动自检(POST):BIOS 进行硬件设备的自检,包括检测和测试主板、内存、显卡、硬盘、键盘等设备,以确保它们的正常工作。
3. 系统配置:BIOS 根据硬件设备的检测结果,自动配置系统参数。例如,设置内存大小、硬盘顺序、启动设备等。
4. 启动顺序选择:BIOS 根据用户的设置,选择合适的启动设备。通常情况下,BIOS 会按照设定的启动顺序依次尝试启动设备,直到找到可启动的设备为止。
5. 引导加载程序的加载:BIOS 会在启动设备上查找引导加载程序(Bootloader),并将其加载到内存中。
### 2.3 BIOS中的自检(POST)
自检(Power-On Self-Test,简称POST)是BIOS初始化过程中的重要一步。它主要用于检测计算机硬件的功能和状态,以确保计算机系统的可靠性。POST过程通常包括以下几个方面的检查和测试:
- 主板及其组件:包括CPU、芯片组、总线等的检测和测试;
- 内存:检测内存模块是否损坏或存在问题;
- 显卡:检测显卡是否正常工作;
- 键盘和鼠标:检测键盘和鼠标是否连接正常;
- 硬盘和其他外部设备:检测硬盘、光驱、USB设备等是否正常连接;
- CMOS:检查CMOS内存中的系统配置信息是否正确。
POST过程中,如果发现硬件问题或错误,BIOS会发出警告提示,如蜂鸣声或屏幕上的警告信息。如果没有错误,BIOS会继续执行后续的启动过程。
总之,BIOS是计算机系统启动过程中的关键组成部分,通过自检和初始化硬件设备,并加载引导加载程序,为操作系统的启动提供基本的支持和环境。
# 3. 主引导记录(MBR)和引导加载程序(Bootloader)
在Linux系统启动过程中,主引导记录(MBR)和引导加载程序(Bootloader)起到了至关重要的作用。下面我们将详细介绍它们的定义和作用。
#### 3.1 MBR的作用
主引导记录(MBR)位于硬盘的第一个扇区,占据了512个字节的空间。它的作用是引导计算机启动。当计算机启动时,BIOS会读取MBR的内容并将控制权转交给MBR中的引导加载程序。
#### 3.2 引导加载程序的作用
引导加载程序,也称为bootloader,是一个小型的程序,负责加载操作系统的内核并启动系统。它位于MBR之后的扇区,一般是硬盘的第一个分区的引导扇区。引导加载程序的主要作用是定位内核文件的位置并将其加载到内存中,然后启动内核。
#### 3.3 GRUB(GRand Unified Bootloader)介绍
GRUB是一种流行的引导加载程序,被广泛应用于Linux系统中。它支持多重操作系统的启动,并提供了一个菜单界面,让用户选择不同的操作系统或系统选项。
GRUB具有以下特点:
- 支持多种文件系统格式,如ext4、NTFS、FAT等。
- 具备模块化结构,可以加载额外的模块来提供更多功能。
- 支持通过命令行来启动操作系统或执行其他任务。
- 提供了图形界面和命令行界面两种使用方式。
GRUB的配置文件一般位于`/boot/grub/grub.cfg`,我们可以通过修改该文件来配置GRUB的启动选项。
通过MBR和引导加载程序,计算机能够正常加载操作系统的内核并启动系统。下一章我们将介绍内核启动过程。
# 4. 内核启动过程
在BIOS将引导加载程序(Bootloader)加载到内存后,系统接下来会开始执行内核的启动过程。这个过程涉及到内核的加载、初始化以及init进程的启动。
#### 4.1 内核的加载
BIOS在加载引导加载程序后,控制权会转交给引导加载程序,它会负责将内核文件从磁盘上加载到系统的内存中。引导加载程序通常会在硬盘的MBR或EFI系统分区中进行搜索,并根据配置文件的设置找到合适的内核文件。
以下是一个示例的Python代码,用于演示引导加载程序的加载内核的过程:
```python
import os
def load_kernel():
bootloader_path = "/boot/grub/grub.conf"
config = parse_config(bootloader_path)
kernel_path = config["kernel"]
load_to_memory(kernel_path)
def parse_config(file_path):
config = {}
with open(file_path, 'r') as file:
lines = file.readlines()
for line in lines:
line = line.strip()
if line.startswith("kernel"):
config["kernel"] = line.split(" ")[1]
return config
def load_to_memory(file_path):
# 读取并加载内核文件到内存中的代码实现
pass
load_kernel()
```
上述代码中,`parse_config`函数用于解析引导加载程序的配置文件,其中包含了内核文件的路径。`load_to_memory`函数则是用于加载内核文件到系统的内存中。
#### 4.2 内核初始化过程
一旦内核成功加载到内存,系统将开始执行内核的初始化过程。在该过程中,内核会对硬件进行初始化并配置各种驱动程序,以便能够与硬件设备交互和通信。
以下是一个简化的Java代码示例,用于说明操作系统内核的初始化过程:
```java
public class Kernel {
// 内核初始化过程的代码实现
public void init() {
initialize_hardware();
load_drivers();
setup_network();
}
private void initialize_hardware() {
// 硬件初始化的代码实现
}
private void load_drivers() {
// 驱动程序加载的代码实现
}
private void setup_network() {
// 网络配置的代码实现
}
}
public class Main {
public static void main(String[] args) {
Kernel kernel = new Kernel();
kernel.init();
}
}
```
在上述代码中,`Kernel`类表示操作系统的内核,`init`方法用于初始化操作系统。在`init`方法中,会调用`initialize_hardware`方法对硬件进行初始化,`load_drivers`方法加载驱动程序,`setup_network`方法进行网络配置等。
#### 4.3 init进程的启动
一旦内核完成初始化,它将启动第一个用户空间进程,即init进程。init进程是用户空间中最先运行的进程,负责接管系统初始化的任务,例如启动其他系统服务和进程。
以下是一个简单的Go语言代码示例,用于说明init进程的启动过程:
```go
package main
import (
"fmt"
"os/exec"
)
func startInitProcess() {
cmd := exec.Command("/sbin/init")
err := cmd.Start()
if err != nil {
fmt.Println("Failed to start init process:", err)
}
}
func main() {
startInitProcess()
}
```
上述代码中,`startInitProcess`函数通过执行`/sbin/init`命令启动init进程。通过调用`exec.Command`创建一个执行init进程的命令对象,并通过`Start`方法来启动进程。
通过以上的操作,系统顺利完成了Linux系统的启动过程,并开始提供相应的服务。
接下来,我们将继续介绍Linux系统启动过程中的其他关键步骤和环节。
# 5. 系统服务的启动
系统服务的启动是在内核初始化完成后进行的,它是Linux系统启动过程中非常重要的一部分。系统服务包括各种守护进程,如网络服务、时间服务、打印服务等,它们需要在系统启动时自动启动并保持运行。
### 5.1 运行级别的概念
在Linux系统中,运行级别是指系统的工作状态。通常有以下几个运行级别:
- 运行级别0:系统停机状态,关机。
- 运行级别1:单用户状态,只有root用户可以登录,用于系统维护和修复。
- 运行级别2:多用户状态,没有网络服务。
- 运行级别3:完全的多用户状态,具有完整的功能。
- 运行级别4:非标准运行级别,可以根据需要定义。
- 运行级别5:图形化界面模式。
- 运行级别6:系统重新启动。
### 5.2 SysVinit和systemd的区别
在过去,SysVinit是Linux系统中最常用的初始化系统。它使用脚本文件来控制系统服务的启动和关闭。每个服务都有一个对应的启动脚本,根据运行级别来决定是否启动该服务。
而现在,很多Linux发行版开始使用systemd作为默认的初始化系统。systemd采用了更加先进的方式来管理系统服务。它使用单位(unit)文件来描述每个服务,并且可以实现并行启动服务,提高系统的启动速度。
### 5.3 服务启动的脚本和配置文件
在SysVinit中,服务的启动脚本位于`/etc/init.d/`目录下。每个脚本文件都包含了启动、停止、重启和查看状态等功能的实现。
而在systemd中,服务的配置文件位于`/etc/systemd/system/`目录下,以`.service`为后缀。配置文件包含了服务的各种设置,如启动命令、依赖关系、用户权限等。
例如,对于Apache Web服务器,SysVinit的启动脚本为`/etc/init.d/httpd`,而在systemd中对应的配置文件为`/etc/systemd/system/httpd.service`。
需要注意的是,在使用systemd时,可以通过`systemctl`命令来管理服务的启动、停止和重启等操作。例如,启动Apache服务可以使用以下命令:
```
systemctl start httpd
```
## 结论
系统服务的启动是Linux系统启动过程中不可或缺的一环。通过设置运行级别和使用适当的初始化系统,可以灵活地控制系统服务的启动和运行,从而满足不同需求的系统配置。同时,合理配置服务的启动脚本和配置文件,可以确保系统服务的正确启动和运行。
# 6. 用户登录过程
用户登录过程是指用户通过终端设备登录到Linux系统的过程。在用户登录之前,系统会先启动getty程序,然后启动登录shell,并初始化用户的环境。
## 6.1 getty程序的启动
getty程序是Linux系统中用于与用户终端进行通信的程序。它的主要作用是打开用户终端设备,并在上面显示登录提示信息,等待用户输入用户名和密码。当用户输入完用户名和密码后,getty程序将把这些信息传递给登录shell进行验证。
在传统的系统中,getty程序是通过init进程的配置文件(/etc/inittab)来启动的。但在现代的Linux发行版中,通常使用systemd来管理系统服务,getty程序会作为一个systemd服务来启动。
以下是一个使用systemd来启动getty程序的示例:
```bash
[Unit]
Description=Getty on %I
Documentation=man:agetty(8) man:systemd-getty-generator(8)
# 启动时执行的命令
ExecStart=-/sbin/agetty -o '-p -- \\u' --noclear %I $TERM
# 当用户注销后重新启动getty
Restart=always
# 定义getty程序的运行级别
Wants=getty.target
# 定义getty程序服务的依赖关系
After=systemd-user-sessions.service plymouth-quit-wait.service
[Service]
ExecStartPre=/usr/lib/systemd/systemd-sysv-install enable agetty@%I.service
# 为getty进程设置TTY和运行级别
TTYVTDisallocate=yes
TTYPath=/dev/%I
#TTYReset=yes
#TTYVHangup=yes
TTYVTConsole=yes
#TTYVHangup=yes
#TTYVTDisallocate=no
#TTYReset=yes
#TTYVHangup=yes
TTYReset=no
TTYVHangup=no
TTYVTDisallocate=yes
TTYVTConsole=yes
# 设置getty程序的环境变量
Environment=LANG=zh_CN.UTF-8
# 定义getty程序的标准输入输出
StandardInput=tty
StandardOutput=tty
StandardError=tty
[Install]
WantedBy=getty.target
```
## 6.2 登录shell的启动
登录shell是用户登录成功后执行的程序。它负责读取并解析用户的配置文件,设置用户的环境变量,并提供交互式的命令行界面供用户进行操作。
在Linux系统中,常见的登录shell有bash、sh、zsh等。登录shell的启动通常是由getty程序负责,当用户输入正确的用户名和密码后,getty会通过PAM(Pluggable Authentication Modules)进行验证并启动登录shell。
以下是一个使用bash作为登录shell的示例:
```bash
#!/bin/bash
# 用户的登录shell脚本
# 读取用户的配置文件
source ~/.bashrc
# 设置用户的环境变量
export PATH=$PATH:/usr/local/bin
# 显示欢迎信息
echo "Welcome to Linux system!"
# 提供命令行界面供用户操作
while true; do
read -p "$USER@$HOSTNAME:~$ " command
case "$command" in
"exit")
break
;;
*)
eval "$command"
;;
esac
done
# 退出登录shell
echo "Goodbye, $USER!"
```
## 6.3 用户环境的初始化
用户登录成功后,登录shell会读取用户的配置文件来初始化用户的环境。常见的用户配置文件有:
- ~/.bash_profile:用于登录shell启动时执行的命令。
- ~/.bashrc:用于每个新的交互式非登录shell启动时执行的命令。
- ~/.profile:在某些发行版中,用于登录shell启动时执行的命令。
用户可以在配置文件中设置环境变量、别名、函数等。
以下是一个使用`~/.bashrc`配置文件的示例:
```bash
# ~/.bashrc
# 设置环境变量
export PATH=$PATH:/usr/local/bin
# 设置别名
alias ll='ls -alF'
alias grep='grep --color=auto'
# 定义函数
function mkcd() {
mkdir $1
cd $1
}
```
以上示例中,`export PATH=$PATH:/usr/local/bin`将`/usr/local/bin`加入到环境变量`$PATH`中,用户可以在命令行中直接执行`/usr/local/bin`下的可执行文件;`alias ll='ls -alF'`定义了一个名为`ll`的别名,用户可以执行`ll`来显示当前目录下的文件和文件夹;`function mkcd()`定义了一个函数`mkcd`,用户可以执行`mkcd <directory>`来创建一个目录并进入该目录。
用户登录成功后,登录shell会执行用户的配置文件,从而完成用户环境的初始化。
通过上述步骤,用户可以成功登录到Linux系统,并开始进行各种操作和应用的使用。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Linux运维-Linux系统启动原理与故障排除》专栏深入探讨了Linux系统启动的原理与故障排除方法,涵盖了BIOS与UEFI启动流程、Linux内核加载、init进程与系统初始化、Systemd引入与启动流程等多个主题。专栏以详细介绍Linux系统启动过程为切入点,解析了运行级别配置、Shell脚本、Bootloader故障排除、硬盘故障引发的启动问题等实际操作技巧,帮助读者深入理解Linux系统启动流程。此外,专栏还详细讨论了系统日志文件分析与故障排除、网络配置与故障排除、内存管理与内存错误修复、文件系统检查与修复、BIOS与UEFI固件更新等内容,为读者提供了全面的Linux系统启动故障排除解决方案。同时,专栏还介绍了GRUB启动界面美化与自定义、Systemd服务管理详解、定时任务与自动启动应用程序等内容,旨在帮助运维人员更加高效地管理和维护Linux系统。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【权威解读】:富士伺服驱动器报警代码的权威解读与故障预防
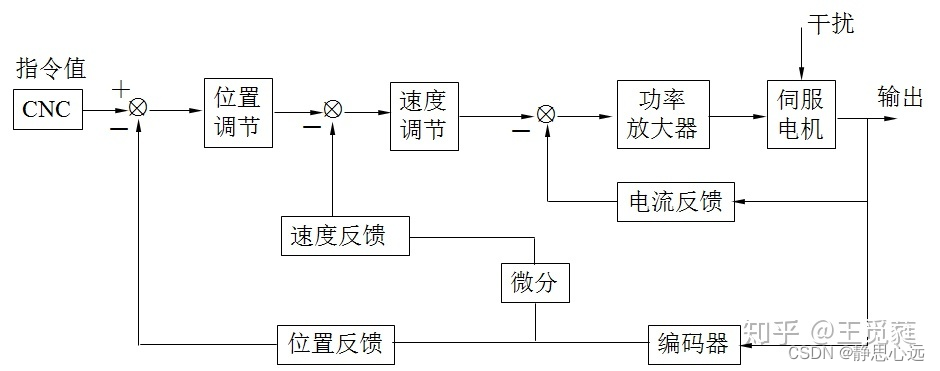
# 摘要
本文对富士伺服驱动器报警代码进行了全面概述,详细阐述了报警代码的理论基础、实践解析以及故障预防和系统维护的策略。首先介绍富士伺服驱动器的工作原理及其核心功能,随后分类讨论了报警代码的结构与意义,并分析了触发报警代码背后的故障机理。接着,通过实践解析,本文提供了常见报警代码的分析、处理方法、系统诊断步骤及实战技巧。文章第四部分强调了预防性维护的重要性,并提出了常见故障的预防措施和报警代码监控与管理系统的建立。最后,探讨了新一代伺服驱动器
邮件管理大师:掌握Hotmail与Outlook的高级规则与过滤器
# 摘要
本文系统地介绍了Hotmail与Outlook邮件管理的核心功能与高级技巧。首先概述了邮件规则与过滤器的创建与管理,随后深入探讨了邮件过滤器的类型和应用,并提供了设置复杂邮件过滤条件的实践案例。文章进一步探讨了高级规则的创建和管理,以及过滤器在高级邮件管理中的深入定制与应用。此外,本文还强调了邮件管理策略的维护、优化和自动化,并分享了企业和个人在邮件管理优化方面的最佳实践与个性化设置。通过这些案例研究,本文旨在提供一套全面的邮
【心冲击信号采集进阶教程】:如何实现高精度数据捕获与分析
# 摘要
本文系统地介绍了心冲击信号采集技术的最新进展,重点关注高精度采集系统的构建和信号分析方法。首先概述了心冲击信号采集技术,并详细讨论了构建高精度心冲击信号采集系统时的关键技术和设备选择。随后,本文深入分析了信号预处理技术及其对增强信号质量的重要性。在软件分析方法方面,本文着重介绍了专业软件工具的使用、高级信号处理技术的应用以及数据分析和结果可视化的策略。最后,通过实际
【Java I_O系统深度剖析】:输入输出流的原理与高级应用
# 摘要
Java I/O系统是构建应用程序的基础,涉及到数据输入和输出的核心机制。本文详细介绍了Java I/O系统的各个方面,从基本的流分类与原理到高级特性的实现,再到NIO和AIO的深度解析。文章通过对流的分类、装饰者模式应用、流的工作原理以及核心类库的分析,深化了对Java I/O系统基础的理解。同时,针对Java NIO与AIO部分,探讨了非阻塞I/O、缓冲流、转换流以及异步I/O的工作模式,强
NVIDIA ORIN NX系统集成要点:软硬件协同优化的黄金法则

# 摘要
NVIDIA ORIN NX作为一款面向嵌入式和边缘计算的高性能SoC,整合了先进的CPU、GPU以及AI加速能力,旨在为复杂的计算需求提供强大的硬件支持。本论文详细探讨了ORIN NX的硬件架构、性能特点和功耗管理策略。在软件集成方面,本文分析了NVIDIA官方SDK与工具集的使用、操作系统的定制以及应用程序开发过程中的调试技巧。进一步,本文聚焦于软硬件协同优化的策略,以提升系统性能。最后,通过案例研究,本文
IRIG-B码生成技术全攻略:从理论到实践,精确同步的秘密

# 摘要
本文对IRIG-B码生成技术进行了全面的概述,深入探讨了IRIG-B码的基本原理、标准、硬件实现、软件实现以及在不同领域中的应用。首先,介绍了IRIG-B码的时间编码机制和同步标准,随后分析了专用芯片与处理器的特点及硬件设计要点。在软件实现方面,本文讨论了软件架构设计、编程实现协议解析和性能优化策略。文章还对军事和工业自动化中的同步系统案例进行了分析,并展望了IRIG-B码技术与新兴
【时序图的深度洞察】:解密图书馆管理系统的交互秘密

# 摘要
时序图作为一种表达系统动态行为的UML图,对于软件开发中的需求分析、设计和文档记录起着至关重要的作用。本文首先对时序图的基础知识进行了介绍,并详细探讨了时序图在软件开发中的实践方法,包括其关键元素、绘制工具和技巧。接着,本文通过图书馆管理系统的功能模块分析,展示了时序图在实际应用中的交互细节和流程展示,从而加
零基础学习FFT:理论与MATLAB代码实现的终极指南
# 摘要
快速傅里叶变换(FFT)是一种高效计算离散傅里叶变换(DFT)及其逆变换的算法,它极大地推动了信号处理、图像分析和各类科学计算的发展。本文首先介绍了FFT的数学基础,涵盖了DFT的定义、性质、以及窗函数在减少频谱泄露中的作用。接着,文章深入探讨了FFT算法在MATLAB环境下的实现方法,并提供了基础和高级操作的代码示例。最后,通过应用实例详细说明了FFT在信号频谱分析、滤波去噪以及信号压缩与重构中的重要作用,并讨论了多维FFT、并行FFT算法和FFT优化技巧等高级话题。
# 关键字
快速傅里叶变换;离散傅里叶变换;窗函数;MATLAB实现;信号处理;算法优化
参考资源链接:[基4
FCSB1224W000性能提升黑科技:系统响应速度飞跃秘籍

# 摘要
本文首先介绍了FCSB1224W000系统的性能概况,随后深入探讨了系统硬件和软件的优化策略。在硬件优化方面,重点分析了内存管理、存储性能提升以及CPU负载平衡的有效方法。系统软件深度调优章节涵盖了操作系统内核、应用程序性能以及系统响应时间的监控与调整技术。此外,本文还探讨了网络响应速度的提升技巧,包
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )