【iText高级技巧解锁】:中文内容在PDF中的完美呈现技巧揭秘
发布时间: 2024-12-17 06:55:07 阅读量: 4 订阅数: 4 

基于Java的iText扩展库:简化PDF创建与中文字体应用设计源码

参考资源链接:[解决iText将HTML转PDF中文显示及字体排版难题](https://wenku.csdn.net/doc/57bcwp91x2?spm=1055.2635.3001.10343)
# 1. iText概述及基础使用
iText 是一个流行的Java库,它允许开发者创建和操作PDF文档。它是用于生成PDF文件的一个强大工具,适用于创建动态生成的报表、表单和文档。iText库被广泛应用于企业级应用,尤其适合于需要在后端服务器上生成文档的场景。
## 1.1 iText的安装和基本配置
首先,确保你的开发环境中已安装Java,并且添加了iText依赖。如果你使用Maven,可以在`pom.xml`中添加以下依赖:
```xml
<dependency>
<groupId>com.itextpdf</groupId>
<artifactId>itext7-core</artifactId>
<version>7.1.16</version>
</dependency>
```
接下来,我们创建一个简单的程序来生成一个PDF文件:
```java
import com.itextpdf.kernel.pdf.PdfDocument;
import com.itextpdf.kernel.pdf.PdfWriter;
import com.itextpdf.layout.Document;
import com.itextpdf.layout.element.Paragraph;
import java.io.File;
import java.io.FileNotFoundException;
public class SimpleITextExample {
public static void main(String[] args) {
try {
// 创建PdfWriter实例
PdfWriter writer = new PdfWriter(new File("example.pdf"));
// 创建PdfDocument实例
PdfDocument pdf = new PdfDocument(writer);
// 创建Document实例
Document document = new Document(pdf);
// 添加一个段落
document.add(new Paragraph("Hello, World!"));
// 关闭文档
document.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
}
```
在上述代码中,我们首先创建了一个`PdfWriter`,它负责向PDF文件中写入内容。然后创建`PdfDocument`对象,它作为文档的容器。最后,通过`Document`对象添加内容到文档中,完成PDF的生成。
通过这个简单的例子,我们可以看到如何使用iText库来创建一个基础的PDF文档。接下来,我们将深入了解iText在中文处理上的挑战与对策。
# 2. iText在中文处理上的挑战与对策
## 2.1 iText中中文编码的正确处理
### 2.1.1 字符编码的重要性与原理
在处理中文文档时,字符编码是构建正确显示的基础。字符编码,通常指一种将字符集中的字符映射到字节序列的规则。这个规则对于存储和传输文本非常重要,尤其是当文本需要在不同平台或程序间共享时。常见的字符编码有ASCII、Unicode等。Unicode编码解决了不同语言字符集之间的兼容问题,其中UTF-8是最常用的Unicode字符编码方式。
### 2.1.2 iText中的编码设置与注意事项
在iText库中处理中文文本时,正确的编码设置是避免乱码问题的关键。iText通常默认使用UTF-16编码,但是当处理纯中文文档时,我们应该明确指定使用UTF-8编码以保证兼容性和效率。在创建PDF时,需要配置合适的编码参数:
```java
PdfWriter writer = new PdfWriter(dest, new WriterProperties().setPdfVersion(PdfVersion.PDF_1_7).setCompressionLevel(CompressionConstants.BEST_COMPRESSION));
PdfDocument pdfDoc = new PdfDocument(writer);
Document document = new Document(pdfDoc);
document.setTextAlignment(TextAlignment.JUSTIFIED);
document.setMargins(50, 50, 50, 50);
PdfFont font = PdfFontFactory.createFont(StandardFonts.HELVETICA);
document.setFont(font);
// 设置内容
document.add(new Paragraph("中文文本处理示例"));
// ... 其他文档内容
document.close();
```
在上述代码中,设置字体为Helvetica,并没有直接涉及到中文处理。对于中文内容,你需要使用支持中文字符的字体文件,例如使用`StandardFonts.SIMHEI`来指定中文字体。
```java
PdfFont font = PdfFontFactory.createFont(StandardFonts.SIMHEI);
document.setFont(font);
```
## 2.2 中文文本的排版与样式设计
### 2.2.1 字体嵌入与选择
在处理PDF中文本排版时,合适的中文字体是实现高质量文档的关键。iText支持将字体嵌入到PDF文件中,这确保了文档在不同环境下的可读性。
```java
PdfFont font = PdfFontFactory.createFont("path/to/your/font.ttf", PdfEncodings.IDENTITY_H);
```
在上述代码中,我们通过指定字体文件路径和编码格式来创建一个PDF字体对象。`IDENTITY_H`是用于处理Unicode字体的编码格式。为了更好的中文显示效果,推荐使用如思源黑体等专业的中文字体。
### 2.2.2 段落、列表及表格中的中文排版技巧
在中文排版中,段落、列表和表格是常见的元素。由于中文字符与英文字符的字宽不同,需要特别注意排版的细节。
```java
Paragraph paragraph = new Paragraph("这是一个段落示例。")
.setFont(font)
.setFontSize(12)
.setFixedLeading(16);
```
上述代码段展示了创建段落并应用字体样式的方法。在iText中,还可以通过设置段落的对齐方式、缩进等参数来进一步优化排版。
### 2.2.3 多语言文档的处理
当需要在同一个PDF文档中处理多语言文本时,可能会遇到字体和布局的复杂性问题。iText允许为不同语言内容指定不同的字体样式,从而保持各自语言的排版传统。
```java
Chunk chunkEnglish = new Chunk("English text", englishFont);
Chunk chunkChinese = new Chunk("中文文本", chineseFont);
PdfCanvas pdfCanvas = new PdfCanvas(writer.getDirectContent());
pdfCanvas.beginText()
.setFontAndSize(chineseFont, 12)
.moveText(36, 750)
.showText(chunkChinese)
.endText();
pdfCanvas.beginText()
.setFontAndSize(englishFont, 12)
.moveText(36, 730)
.showText(chunkEnglish)
.endText();
```
上述代码段通过`Chunk`和`PdfCanvas`对象展示了如何在同一页面上分别绘制英文和中文内容,同时保持语言特定的排版要求。
## 2.3 iText中中文图像和表格的处理
### 2.3.1 图像的加载与中文标注
在PDF文档中添加图像并进行中文标注是常见需求,iText支持图像的加载和中文文字的覆盖。
```java
Image image = Image.getInstance("path/to/your/image.png");
image.scaleToFit(500, 500);
document.add(new Paragraph("图像中文标注示例:")
.add(image)
.add(new Chunk("示例文字").setFont(font))
);
```
上述代码展示了如何加载图像文件并添加中文标注。注意,图像尺寸通过`scaleToFit`方法进行调整,以适应页面布局。
### 2.3.2 表格制作与中文内容兼容
在制作表格时,确保中文内容正确显示是一个关键点。这通常涉及到表格单元格宽度的调整和字体的正确设置。
```java
Table table = new Table(3);
for (int i = 0; i < 10; i++) {
table.addCell(new Cell().add(new Paragraph("中文行 " + i)).setFont(font));
}
document.add(table);
```
上述代码创建了一个具有三列的表格,并添加了包含中文内容的行。通过设置字体,我们可以确保中文在表格中正确显示。表格的布局和样式可以根据需要进一步进行优化调整。
在下一节中,我们将探讨如何使用iText在PDF自动化生成实践中制作个性化文档模板,以及如何处理批量生成PDF报告时遇到的异常情况和日志记录。
# 3. iText PDF自动化生成实践
在企业环境中,自动化生成文档是一项常见的需求,尤其是对于需要定期生成报告、发票等标准化文档的场景。利用iText库,开发者可以轻松地实现PDF文档的自动化生成,极大地提升工作效率。本章将深入探讨如何通过iText实现PDF模板的应用、批量报告生成、以及PDF加密与权限设置。
## 3.1 从模板生成个性化PDF文档
### 3.1.1 模板制作与变量替换
在许多实际应用场景中,PDF模板的设计与制作是一个重要的步骤。模板可以预先设计好样式和布局,仅保留需要动态填充的部分作为变量。这样,在生成最终的PDF文档时,只需替换这些变量即可。
```java
// 创建一个模板PDF文档对象
PdfReader reader = new PdfReader("template.pdf");
// 创建一个文档对象,用于将模板应用到新的PDF中
PdfStamper stamper = new PdfStamper(reader, new FileOutputStream("output.pdf"));
// 要替换的文本变量
HashMap<String, String> variables = new HashMap<>();
variables.put("name", "张三");
variables.put("date", "2023-04-01");
// 使用变量替换模板中的占位符
AcroFields fields = stamper.getAcroFields();
for (Map.Entry<String, String> entry : variables.entrySet()) {
fields.setField(entry.getKey(), entry.getValue());
}
// 关闭stamper
stamper.close();
reader.close();
```
在上述代码中,首先创建了一个`PdfReader`对象来读取模板PDF文件。然后,创建了一个`PdfStamper`对象来将变量应用到模板中。通过`AcroFields`类,我们能够访问并替换PDF模板中的表单字段。变量替换完成后,关闭`stamper`和`reader`对象以释放资源。
### 3.1.2 模板动态数据填充与个性化
在模板的变量被替换后,下一步是实现动态数据的填充。这通常涉及到从外部数据源(如数据库、API或文件)读取数据,并将其填充到PDF模板中的适当位置。以下是一个简单的例子,展示如何将数据库查询结果填充到PDF模板中。
```java
// 假设有一个方法从数据库中获取用户数据列表
List<User> users = getUserDataFromDatabase();
// 遍历用户数据列表,为每个用户生成PDF文档
for (User user : users) {
// ...模板制作与变量替换的代码...
// 为当前用户填充数据
fields.setField("username", user.getUsername());
fields.setField("email", user.getEmail());
// 可能还有其他字段填充
// 保存当前用户的PDF文档
stamper.setFullCompression();
stamper.close();
reader.close();
// 将每个用户对应的PDF发送到指定位置或进行下一步处理
}
```
在这个例子中,我们假设从数据库中获取了一个用户列表,并为每个用户生成了一个PDF文档。通过循环遍历用户数据列表,我们可以实现批量生成个性化PDF文档的目的。代码逻辑清晰,展示了从数据获取、模板填充到文档生成的完整流程。
## 3.2 批量生成PDF报告
### 3.2.1 数据源整合与循环生成
批量生成报告首先需要处理数据源的整合。这可能包括对数据的预处理,以确保其格式正确并且适合填充到PDF模板中。一旦数据准备好,就可以使用循环结构来遍历数据并生成报告。
```java
// 假设已经有一个整合好的数据源List<Map<String, String>> reportsData
PdfReader reader = new PdfReader("template.pdf");
PdfStamper stamper = new PdfStamper(reader, new FileOutputStream("output.pdf"));
AcroFields fields = stamper.getAcroFields();
for (Map<String, String> data : reportsData) {
// 清除上一次填充的内容
fields.setField("report_id", "");
// 填充当前报告的数据
fields.setField("report_id", data.get("report_id"));
fields.setField("report_date", data.get("report_date"));
// ...可能还有其他字段填充
// 将报告写入到输出流中
stamper.setFullCompression();
stamper.setFormFlattening(true); // 如果需要,可以将表单数据嵌入到PDF中
stamper.writeOut(new FileOutputStream("output_" + data.get("report_id") + ".pdf"));
}
stamper.close();
reader.close();
```
在这个代码片段中,我们处理了一个报告数据列表,每个报告数据包括报告ID和报告日期等字段。通过循环为每个报告实例化PDF模板,并填充相应的数据,最后将生成的PDF文档输出到文件系统中。
### 3.2.2 生成过程中的异常处理与日志记录
在批量生成PDF报告的过程中,可能会遇到各种异常情况,例如文件访问问题、内存不足等。因此,良好的异常处理机制和日志记录是必不可少的。这不仅有助于调试和维护代码,也确保了在出现问题时能够追踪和解决问题。
```java
try {
// ...数据源整合与循环生成的代码...
} catch (IOException e) {
// 处理文件访问问题
System.err.println("文件访问错误: " + e.getMessage());
} catch (DocumentException e) {
// 处理PDF文档生成错误
System.err.println("PDF文档生成错误: " + e.getMessage());
} catch (Exception e) {
// 处理其他未预期异常
System.err.println("未知错误: " + e.getMessage());
} finally {
// 清理资源,确保文件流关闭
if (stamper != null) {
stamper.close();
}
if (reader != null) {
reader.close();
}
}
```
在上述异常处理代码中,我们对可能出现的几种不同类型的异常进行了捕获,并根据异常类型给出了相应的处理措施。同时,无论在何种情况下,都会在`finally`块中确保所有资源被正确清理。
## 3.3 PDF文档的加密与权限设置
### 3.3.1 加密技术与安全策略
PDF文档的加密是保证文档安全的重要手段,它能够防止未经授权的用户打开或修改PDF文件。iText库提供了强大的加密功能,允许开发者设置密码来控制文件的打开权限和编辑权限。
```java
// 创建一个密码保护的PDF文档
PdfReader reader = new PdfReader("source.pdf");
PdfStamper stamper = new PdfStamper(reader, new FileOutputStream("protected.pdf"));
// 设置打开密码和允许的权限
stamper.setEncryption(
new byte[] { (byte) 0x47 }, // 打开密码(加密算法标识)
null, // 所有者密码为空,即不设置
PdfWriter.ALLOW_PRINTING,
PdfWriter.STANDARD_ENCRYPTION_128);
stamper.close();
reader.close();
```
在上述代码中,通过`setEncryption`方法,我们设置了文档的加密算法和权限。这里使用的是128位加密算法,并允许打印文档。密码保护的PDF文档在被打开时会提示输入密码,并且只有知道密码的用户才能访问和修改内容。
### 3.3.2 阅读、编辑和打印权限的控制
在某些情况下,我们需要更细致地控制对PDF文档的访问权限,例如限制复制和打印功能。这可以通过调整`setEncryption`方法中的权限参数来实现。以下是一个设置权限的例子。
```java
// ...之前代码的省略...
// 设置权限,允许阅读、打印,但不允许编辑和复制内容
stamper.setEncryption(
null, // 所有者密码为空,即不设置
"openpassword".getBytes(), // 打开密码设置为"openpassword"
PdfWriter.ALLOW_PRINTING + PdfWriter.ALLOW_COPY // 允许打印和复制
& ~PdfWriter.ALLOW_MODIFY_CONTENTS, // 不允许修改内容
PdfWriter.STANDARD_ENCRYPTION_128);
// ...之后代码的省略...
```
在这个例子中,我们在设置加密时明确指定了允许的权限,这包括允许打印(`PdfWriter.ALLOW_PRINTING`)和复制(`PdfWriter.ALLOW_COPY`)。同时,通过位运算符`&`和`~`来取消其他不需要的权限。这种细粒度的权限控制使我们能够定制出符合特定需求的安全策略。
以上为第三章“iText PDF自动化生成实践”中3.1到3.3节的内容,通过结合代码示例、异常处理策略和权限控制讨论,展示了如何利用iText在实际项目中实现PDF文档的自动化生成和安全设置。本章内容深入到了模板应用、数据动态填充、批量报告生成、加密保护等方面,为希望进一步探索iText功能的开发者提供了有价值的参考。
# 4. iText高级应用技巧
## 4.1 PDF元数据的管理与应用
PDF元数据是PDF文档中不直接显示的信息,用于描述文档的属性,如标题、作者、主题、创建和修改日期等。这些信息在文档管理和搜索中扮演着关键角色。
### 4.1.1 元数据的添加与修改
iText 提供了丰富的API用于管理PDF文档的元数据。通过使用 `PdfDocument` 和 `PdfDocumentInfo` 类,开发者可以轻松地添加和修改元数据。
```java
PdfDocument pdfDoc = new PdfDocument(new PdfWriter("metadataDemo.pdf"));
pdfDoc.setTagged();
PdfDocumentInfo info = pdfDoc.getDocumentInfo();
info.setAuthor("Author Name");
info.setTitle("Demo PDF");
info.setSubject("iText PDF metadata example");
info.set_keywords("iText,Java,Pdf,Metadata");
pdfDoc.close();
```
上面的代码段创建了一个PDF文档,并设置了作者、标题、主题和关键词元数据。确保在修改元数据后关闭文档以确保更改被正确保存。
### 4.1.2 元数据在文档管理中的作用
元数据可以用于多种文档管理任务,包括但不限于:
- **搜索与索引**:元数据中的标题、作者、关键词等可以被用来搜索和索引PDF文档。
- **版本控制**:通过修改时间戳和版本号可以管理文档的版本。
- **内容管理**:元数据可以帮助区分不同文档,比如按照主题或创建者进行分类。
元数据是PDF文件中不可见但非常重要的部分,正确使用元数据可以极大地方便文档的管理与维护。
## 4.2 PDF表单的创建与处理
PDF表单是收集用户输入信息的有效方式,可以包含文本字段、按钮、单选按钮、复选框等。iText允许创建和处理这些表单。
### 4.2.1 表单字段的定义与类型
在iText中创建表单字段需要使用 `PdfAcroForm` 类。下面的代码示例展示了如何创建不同类型的表单字段:
```java
PdfReader reader = new PdfReader("template.pdf");
PdfWriter writer = new PdfWriter("form.pdf");
PdfDocument pdfDoc = new PdfDocument(reader, writer);
PdfAcroForm form = PdfAcroForm.getAcroForm(pdfDoc, true);
form.addField(new TextFormFieldBuilder(pdfDoc, "name").setWidgetRectangle(new Rectangle(400, 780, 100, 20)).createText());
form.addField(new ListBoxFormFieldBuilder(pdfDoc, "dropdown").setWidgetRectangle(new Rectangle(400, 750, 100, 20)).createList().setOptions(new String[] { "Option 1", "Option 2", "Option 3" }));
form.addField(new PushButtonFormFieldBuilder(pdfDoc, "button", PdfFormAnnotation.PRINT).setWidgetRectangle(new Rectangle(400, 720, 100, 40)).createButton());
form.setNeedAppearances(true);
form.flattenFields();
form.writeAcroForm(pdfDoc);
pdfDoc.close();
```
这段代码创建了一个文本输入框、一个下拉列表和一个按钮。`flattenFields` 方法将表单字段“平铺”到PDF页面上,这有助于防止表单字段被进一步修改。
### 4.2.2 表单数据的收集与验证
收集表单数据通常涉及将表单呈现给用户,让他们填写后提交。验证数据则是确保用户输入的数据符合预设的要求。以下是如何使用iText来收集和验证表单数据:
```java
PdfReader reader = new PdfReader("form.pdf");
PdfAcroForm form = PdfAcroForm.getAcroForm(reader, true);
form.flattenFields();
HashMap<String, String> data = new HashMap<>();
data.put("name", "John Doe");
data.put("dropdown", "Option 2");
data.put("button", "Submit"); // 按钮名作为字段名,值为Submit, Reset等。
form.fillForm(data, writer);
form.flattenFields();
form.writeAcroForm(writer);
```
在这个示例中,我们通过 `fillForm` 方法使用了存储在 `data` 哈希表中的数据来填充表单。通过 `flattenFields` 方法和 `writeAcroForm` 方法,我们可以将填写好的表单转换为不可编辑的PDF文档。
## 4.3 PDF文档内容的高级编辑
高级编辑涉及到PDF文档内容的动态添加、删除、合并、拆分与重组。iText库提供了强大的API来执行这些任务。
### 4.3.1 文档内容的动态添加与删除
在iText中,`PdfDocument` 提供了 `addNewPage()` 和 `deletePage()` 方法来添加和删除页面。以下是如何使用这些方法的示例:
```java
PdfDocument pdfDoc = new PdfDocument(new PdfWriter("dynamicEdit.pdf"));
// 添加新页面
pdfDoc.addNewPage();
// 删除第一页
pdfDoc.removePage(1);
pdfDoc.close();
```
添加新页面相对简单,但删除页面需要注意,iText不会自动重新编号剩余的页面。因此,如果需要连续的页码,还需要处理页码的更新。
### 4.3.2 PDF合并、拆分与重组技巧
iText可以通过合并现有的PDF文件来创建新的文档,或者将一个文档拆分成多个文件。这里展示一个合并两个PDF文档的示例:
```java
PdfWriter writer = new PdfWriter("mergedDocument.pdf");
PdfDocument pdfDoc = new PdfDocument(writer);
PdfMerger merger = new PdfMerger(pdfDoc);
PdfReader reader1 = new PdfReader("firstDocument.pdf");
PdfDocument sourceDoc1 = new PdfDocument(reader1);
merger.merge(sourceDoc1, 1, sourceDoc1.getNumberOfPages());
PdfReader reader2 = new PdfReader("secondDocument.pdf");
PdfDocument sourceDoc2 = new PdfDocument(reader2);
merger.merge(sourceDoc2, 1, sourceDoc2.getNumberOfPages());
pdfDoc.close();
sourceDoc1.close();
sourceDoc2.close();
```
在拆分PDF文档时,我们需要创建 `PdfReader` 实例,并使用 `PdfWriter` 对象写入特定页面来创建新的PDF文档。
iText通过提供这些高级功能,使得PDF文档的内容管理和编辑变得灵活和强大。
# 5. 项目案例分析与总结
## 5.1 综合案例分析:中文PDF文档生成项目
### 5.1.1 项目需求与技术选型
在本案例中,我们将深入分析一个典型的中文PDF文档生成项目。该需求来自一家教育出版社,旨在为不同年级的学生提供个性化的教学辅导材料。项目的核心在于利用iText库自动化生成包含个性信息的中文PDF文档。
在技术选型上,考虑到以下几点因素:
- **中文处理能力**:iText库支持中文字符的处理,适合于复杂的中文排版和布局需求。
- **自动化水平**:通过编程方式实现自动化生成PDF,可扩展性强,便于后期维护和升级。
- **灵活性和定制性**:能够满足不同年级材料内容的个性化需求。
### 5.1.2 实现过程中的关键问题与解决方案
在实施过程中,遇到几个关键的技术挑战:
1. **中文字符编码问题**:由于iText底层使用Java,其默认字符编码可能与中文环境不兼容。通过设置正确的字符编码(如`UTF-8`)来保证中文显示的正确性。
2. **中文排版与样式设计**:中文排版需要注意字符间距,以及与英文字符的混排。通过精细调整`PdfFont`的字距和行距属性来实现最佳显示效果。
3. **性能瓶颈**:大量文档生成过程中出现性能瓶颈。采用多线程和批处理技术进行优化,显著提高了生成效率。
以下是关键问题的解决方案的代码示例:
```java
// 设置字体和字符编码
PdfFont font = PdfFontFactory.createFont(StandardFonts.HELVETICA, "UTF-8");
Paragraph paragraph = new Paragraph("这是一段中文文本。", font);
```
## 5.2 iText应用中的最佳实践与性能优化
### 5.2.1 iText应用中的常见错误与规避
在使用iText的过程中,开发者可能会遇到一些常见的错误,以下是一些规避建议:
- **内存溢出**:在处理大量数据或复杂文档时,很容易遇到内存溢出问题。合理使用iText的写入模式(例如使用`PdfWriter`的`setUseBigFiveCodepage`方法),并及时关闭文档对象。
- **乱码问题**:确保在文档创建时设置正确的编码,否则可能会出现乱码。在写入中文字符前,可以通过` writer.setInitialLeading(20);`设置合适的行间距来改善排版。
### 5.2.2 性能优化与资源管理技巧
为了优化性能,可以采取以下措施:
- **使用缓冲输出流**:利用缓冲输出流可以减少磁盘I/O操作,提高处理速度。
- **关闭不需要的PDF对象**:在操作完成后,确保所有的PDF对象都被适当关闭,以释放资源。
```java
// 使用缓冲输出流进行PDF写入
ByteArrayOutputStream buffer = new ByteArrayOutputStream();
PdfWriter writer = new PdfWriter(buffer);
PdfDocument pdf = new PdfDocument(writer);
// ... 进行文档操作
pdf.close();
buffer.close();
```
## 5.3 未来iText技术趋势与展望
### 5.3.1 新版本功能更新与适应
iText库持续更新,每个新版本都带来一些功能改进和性能优化。开发者需要持续关注新版本,并根据更新内容调整现有代码以适应新的功能。
- **新版本的API调整**:新版本可能会对某些API进行调整,需要开发者及时适应并更新代码。
- **增加的高级特性**:如高级表格处理、更灵活的文档合并拆分功能等,可以提高开发效率。
### 5.3.2 iText在中文文档处理中的发展趋势
随着中文文档处理需求的增长,iText在该领域的功能也逐渐丰富。未来可能的趋势包括:
- **更深入的本地化支持**:比如增强的中文字符处理和排版支持。
- **云端文档处理**:将iText功能扩展到云端,支持在线PDF文档的生成和编辑。
通过这些技术趋势,iText有望在中文文档处理领域扮演更重要的角色。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏全面探讨了使用 iText 将 HTML 转换为 PDF 时中文显示和排版遇到的难题。从解决换行和字体问题到优化中文显示效果和排版布局,该专栏提供了深入的指南和技巧。通过涵盖字符编码处理、换行机制、布局艺术、扩展功能和最佳实践,该专栏旨在帮助开发人员掌握中文内容在 PDF 中的完美呈现。此外,它还分享了从失败到成功的转换经验,并提供了自动化工具和个性化设置的结合,以实现高效的中文排版。无论您是 iText 初学者还是经验丰富的用户,本专栏都将为您提供所需的知识和技巧,以创建具有专业外观和准确性的中文 PDF 文档。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Qt环境搭建终极指南】:5分钟内解决Qt Creator版本检测噩梦
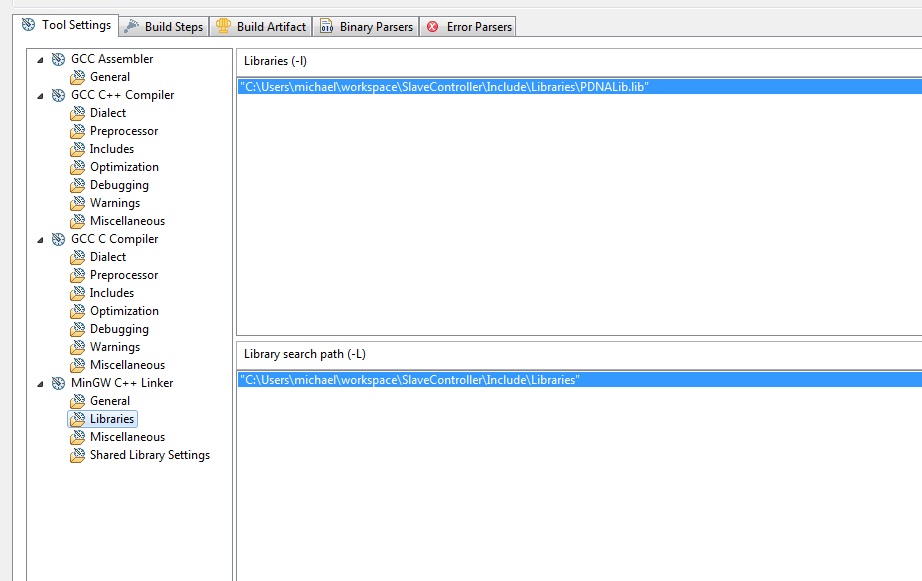
参考资源链接:[解决qt-creator创建工程说“没有有效的qt版本问题”](https://wenku.csdn.net/doc/6412b6f3be7fbd1778d48903?spm=1055.2635.3001.10343)
# 1. Qt环境搭建快速入门
## 开启Qt旅程:基础搭建
在开始我们的Qt编程之旅前,了解并安装一个适合的开发环境是必要的。本章会引导你通过几个简单的步骤快速搭建起Qt的
网络数据分析:综合实验中的数据驱动方法:数据分析师必备技能

参考资源链接:[通达学院:网络前沿SSH实验——远程管理路由器](https://wenku.csdn.net/doc/1w5jjs3s54?spm=1055.2635.3001.10343)
# 1. 网络数据分析概述
## 1.1 网络数据分析的重要性
在当今这个数据爆炸的时代,网络数据分析不仅对企业的市场战略和运营决策起到了关键作用,而且对网络安全和流量管理等领域也有着不可替代的重要性。有效的网络数据分析可以帮助企业发现潜在的市场
【高效优化】ST-FOC4.2电机控制:中文社区分享的调整秘诀

参考资源链接:[STM32PMSM FOC SDK V4.2全中文详解:高性能电机驱动与API应用](https
【FreeRTOS监控与可视化】:Tracealyzer实时数据监控技巧
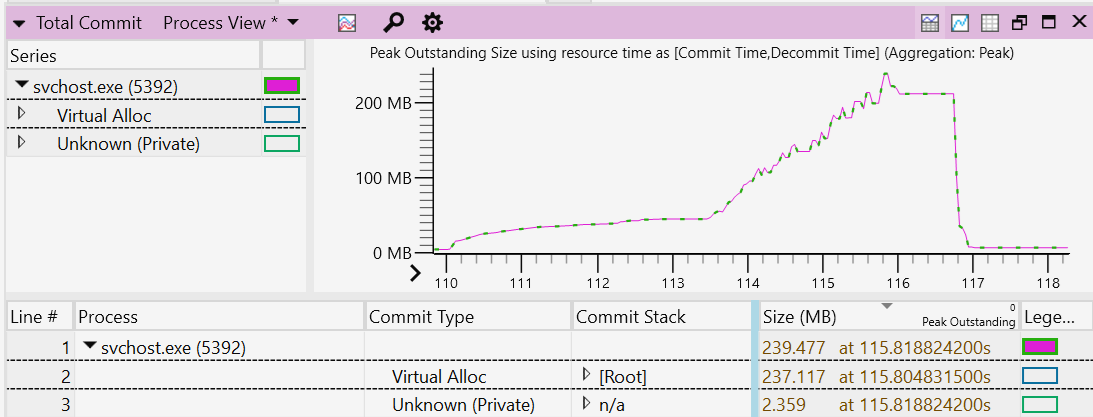
参考资源链接:[Tracealyzer配置指南:FreeRTOS实时分析与调试](https://wenku.csdn.net/doc/6412b547be7fbd1778d4293d?spm=1055.2635.3001.10343)
# 1. FreeRTOS监控与可视化的基础概念
在现代嵌入式系统的开发与维
C语言内存分配全解析:malloc、calloc、realloc和free的精准用法

参考资源链接:[C语言入门资源:清晰PDF版,亲测可用](https://wenku.csdn.net/doc/6412b6d0be7fbd1778d48122?spm=1055.2635.3001.10343)
# 1. C语言内存管理基础
在计算机科学中,内存管理是软件开发的核心组成部分之一,特别是在系统编程语言如C语言中。正确理解并有效管理内存是编写高效、稳定且安
【动态规划速成课】:从算法导论到实战,一步到位
参考资源链接:[《算法导论》中文版各章习题答案汇总](https://wenku.csdn.net/doc/3rfigz4s5s?spm=1055.2635.3001.10343)
# 1. 动态规划的核心概念和算法原理
动态规划是计算机科学中一种解决问题的方法论,特别是在优化问题和决策过程中非常有用。动态规划的核心在于将一个复杂问题分解为更小的子问题,并通过解决子问题来构
VBS与IE的协同工作:自动化测试与网页导航的终极结合!

参考资源链接:[VBScript中开启IE的两种方法:Application与WScript.Shell示例](https://wenku.csdn.net/doc/64533e54ea0840391e778de9?spm=1055.2635.3001.10343)
# 1. VBS与IE协同工作简介
在当前的软件开发和测试环境中,自动化测试已成为提高效率和质量的关
HTML学习宝典:利用MDN从入门到精通
参考资源链接:[MDN离线文档:中文API镜像及注意事项](https://wenku.csdn.net/doc/68x0ofhfub?spm=1055.2635.3001.10343)
# 1. HTML基础与结构
HTML(HyperText Markup Language)是构建网页的基础。任何网站都离不开HTML,它通过使用各种标记(tags)来定义网页上的内容和结构。本章将介绍HTML的基
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )