MATLAB求标准差的终极指南:从基础到实战,掌握标准差计算技巧
发布时间: 2024-06-07 13:56:38 阅读量: 163 订阅数: 51 
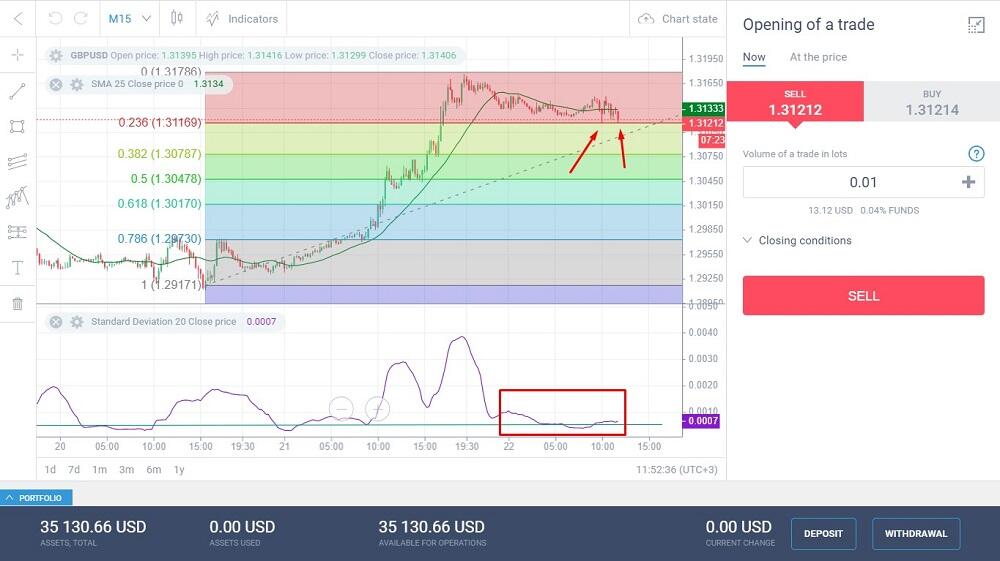
# 1. 标准差的基础**
标准差是衡量数据分散程度的重要统计指标,它反映了数据点与均值的偏离程度。在MATLAB中,标准差的计算方法有多种,包括使用`std()`和`var()`函数。
对于样本数据,标准差的计算公式为:
```
std_dev = sqrt(var(x))
```
其中,`x`是数据样本,`std_dev`是样本标准差。
# 2. MATLAB中的标准差计算
### 2.1 MATLAB中的标准差函数
MATLAB提供了两个内置函数来计算标准差:`std()`和`var()`。
**2.1.1 std()函数**
`std()`函数计算样本标准差,即对给定数据集中所有值的偏差平方和的平方根除以自由度。语法如下:
```matlab
std(x)
```
其中:
* `x`:输入数据向量或矩阵。
**参数说明:**
`std()`函数具有以下参数:
* `'biased'`:指定是否计算有偏标准差。默认值为`'unbiased'`,表示计算无偏标准差。
* `'nanflag'`:指定如何处理NaN值。默认值为`'omitnan'`,表示忽略NaN值。
**代码块:**
```matlab
% 计算样本标准差
data = [10, 12, 15, 18, 20];
sample_std = std(data);
% 计算有偏标准差
biased_std = std(data, 'biased');
% 计算忽略NaN值的标准差
data_with_nan = [10, 12, 15, 18, 20, NaN];
nan_std = std(data_with_nan, 'nanflag', 'omitnan');
% 输出结果
disp(['Sample Standard Deviation: ', num2str(sample_std)]);
disp(['Biased Standard Deviation: ', num2str(biased_std)]);
disp(['Standard Deviation (omitting NaN): ', num2str(nan_std)]);
```
**逻辑分析:**
此代码块演示了`std()`函数的用法。它计算了给定数据向量的样本标准差、有偏标准差和忽略NaN值的标准差。结果显示在控制台中。
### 2.2 标准差的计算方法
**2.2.1 样本标准差**
样本标准差是基于样本数据的标准差估计值。它使用以下公式计算:
```
σ = √(Σ(x - μ)² / (n - 1))
```
其中:
* σ:样本标准差
* x:数据值
* μ:样本均值
* n:样本大小
**2.2.2 总体标准差**
总体标准差是基于总体数据的真实标准差。它使用以下公式计算:
```
σ = √(Σ(x - μ)² / n)
```
其中:
* σ:总体标准差
* x:数据值
* μ:总体均值
* n:总体大小
**表格:样本标准差和总体标准差**
| 特征 | 样本标准差 | 总体标准差 |
|---|---|---|
| 公式 | √(Σ(x - μ)² / (n - 1)) | √(Σ(x - μ)² / n) |
| 分母 | 自由度 (n - 1) | 总体大小 (n) |
| 目的 | 估计总体标准差 | 计算真实总体标准差 |
# 3. MATLAB中的标准差应用
标准差在MATLAB中有着广泛的应用,从数据分布分析到假设检验,它都是一个重要的统计指标。本章将深入探讨MATLAB中标准差的应用,包括数据分布分析、假设检验和更高级的应用。
### 3.1 数据分布分析
标准差是描述数据分布的重要指标。它可以帮助我们了解数据的集中程度和离散程度。
#### 3.1.1 正态分布
正态分布是统计学中最重要的分布之一。它的概率密度函数呈钟形曲线,中心为均值,两侧对称。标准差衡量了数据点偏离均值的程度。较小的标准差表示数据点更集中在均值附近,而较大的标准差表示数据点更分散。
```
% 生成正态分布数据
data = randn(1000, 1);
% 计算标准差
std_dev = std(data);
% 绘制直方图
figure;
histogram(data);
title('正态分布数据直方图');
xlabel('数据值');
ylabel('频率');
% 在直方图上叠加正态分布曲线
hold on;
x = linspace(min(data), max(data), 100);
y = normpdf(x, mean(data), std_dev);
plot(x, y, 'r', 'LineWidth', 2);
legend('直方图', '正态分布曲线');
```
#### 3.1.2 偏态分布
偏态分布是指数据点分布不对称的分布。它可以向左偏态(负偏态)或向右偏态(正偏态)。标准差仍然可以衡量数据的离散程度,但它不能完全描述偏态分布的形状。
```
% 生成偏态分布数据
data = exprnd(1, 1000, 1);
% 计算标准差
std_dev = std(data);
% 绘制直方图
figure;
histogram(data);
title('偏态分布数据直方图');
xlabel('数据值');
ylabel('频率');
% 在直方图上叠加偏态分布曲线
hold on;
x = linspace(min(data), max(data), 100);
y = exppdf(x, 1);
plot(x, y, 'r', 'LineWidth', 2);
legend('直方图', '偏态分布曲线');
```
### 3.2 假设检验
假设检验是统计学中用于评估假设是否成立的一种方法。标准差在假设检验中扮演着重要角色,因为它可以帮助我们确定数据的差异是否具有统计意义。
#### 3.2.1 t检验
t检验是一种用于比较两个独立样本均值的假设检验。它假设两个样本来自具有相同标准差的正态分布。
```
% 生成两个独立样本
sample1 = randn(100, 1);
sample2 = randn(100, 1) + 1;
% 计算样本标准差
std_dev1 = std(sample1);
std_dev2 = std(sample2);
% 执行 t检验
[h, p, ci, stats] = ttest2(sample1, sample2);
% 解释结果
if h == 0
disp('两个样本均值没有显著差异');
else
disp('两个样本均值存在显著差异');
end
```
#### 3.2.2 方差分析
方差分析(ANOVA)是一种用于比较多个样本均值的假设检验。它假设所有样本来自具有相同标准差的正态分布。
```
% 生成三个独立样本
sample1 = randn(100, 1);
sample2 = randn(100, 1) + 1;
sample3 = randn(100, 1) + 2;
% 计算样本标准差
std_dev1 = std(sample1);
std_dev2 = std(sample2);
std_dev3 = std(sample3);
% 执行方差分析
[p, table, stats] = anova1([sample1, sample2, sample3], {'Group 1', 'Group 2', 'Group 3'});
% 解释结果
if p < 0.05
disp('至少两个样本均值存在显著差异');
else
disp('所有样本均值没有显著差异');
end
```
# 4. 标准差计算的进阶技巧
### 4.1 加权标准差
#### 4.1.1 加权平均值
加权平均值是一种考虑每个数据点权重的平均值计算方法。权重是一个非负值,表示数据点的重要性或可靠性。加权平均值计算公式如下:
```
加权平均值 = (w1 * x1 + w2 * x2 + ... + wn * xn) / (w1 + w2 + ... + wn)
```
其中:
* w1、w2、...、wn 是每个数据点的权重
* x1、x2、...、xn 是每个数据点的值
#### 4.1.2 加权标准差的计算
加权标准差是考虑每个数据点权重的标准差计算方法。其计算公式如下:
```
加权标准差 = sqrt(∑(wi * (xi - 加权平均值)^2) / ∑wi)
```
其中:
* wi 是每个数据点的权重
* xi 是每个数据点的值
* 加权平均值是使用上述加权平均值公式计算的
### 4.2 标准差的置信区间
#### 4.2.1 置信区间的概念
置信区间是估计总体参数(如标准差)的范围。它表示在给定的置信水平下,参数的真实值落入该范围内的概率。
#### 4.2.2 标准差置信区间的计算
标准差的置信区间可以使用以下公式计算:
```
置信区间 = 样本标准差 * t(α/2, n-1) * sqrt(n)
```
其中:
* α 是置信水平(通常为 0.05 或 0.01)
* n 是样本大小
* t(α/2, n-1) 是 t 分布的临界值,可以在 t 分布表中查到
**示例:**
假设我们有一个样本,其标准差为 10,样本大小为 100,置信水平为 95%。则标准差的 95% 置信区间为:
```
置信区间 = 10 * t(0.025, 99) * sqrt(100) = 9.75 - 10.25
```
这意味着我们有 95% 的把握,总体标准差落在 9.75 到 10.25 之间。
# 5. MATLAB中的标准差实战
### 5.1 实验数据分析
**5.1.1 测量数据的标准差**
在实验研究中,标准差是评估测量数据可靠性的重要指标。它衡量了测量值与平均值之间的差异程度。
**步骤:**
1. 加载实验数据:使用`load`命令加载实验数据文件。
2. 计算标准差:使用`std`函数计算测量数据的标准差。
```matlab
% 加载实验数据
data = load('experiment_data.mat');
% 计算标准差
std_dev = std(data.measurements);
% 打印标准差
disp(['标准差:' num2str(std_dev)]);
```
**5.1.2 实验结果的比较**
标准差可以用来比较不同实验条件下的实验结果。它可以帮助确定实验结果是否具有统计学意义。
**步骤:**
1. 计算不同条件下的标准差:使用`std`函数计算不同实验条件下的测量数据的标准差。
2. 进行t检验:使用`ttest2`函数进行t检验,比较不同条件下的标准差是否具有统计学意义。
```matlab
% 计算不同条件下的标准差
std_dev_condition1 = std(data.measurements_condition1);
std_dev_condition2 = std(data.measurements_condition2);
% 进行t检验
[h, p] = ttest2(data.measurements_condition1, data.measurements_condition2);
% 打印结果
if h
disp('实验结果具有统计学意义');
else
disp('实验结果不具有统计学意义');
end
```
### 5.2 金融数据分析
**5.2.1 股票收益率的标准差**
在金融分析中,标准差是衡量股票收益率波动性的关键指标。它可以帮助投资者评估股票的风险水平。
**步骤:**
1. 加载股票收益率数据:使用`load`命令加载股票收益率数据文件。
2. 计算标准差:使用`std`函数计算股票收益率的标准差。
```matlab
% 加载股票收益率数据
data = load('stock_returns.mat');
% 计算标准差
std_dev = std(data.returns);
% 打印标准差
disp(['股票收益率标准差:' num2str(std_dev)]);
```
**5.2.2 投资组合的风险评估**
标准差可以用来评估投资组合的风险水平。它衡量了投资组合中不同资产的收益率波动性。
**步骤:**
1. 计算投资组合中每个资产的标准差:使用`std`函数计算投资组合中每个资产的收益率的标准差。
2. 计算投资组合的标准差:使用加权平均值公式计算投资组合的标准差,其中权重为每个资产在投资组合中的比例。
```matlab
% 计算每个资产的标准差
std_dev_asset1 = std(data.returns_asset1);
std_dev_asset2 = std(data.returns_asset2);
% 计算投资组合的标准差
weights = [0.6, 0.4]; % 资产权重
std_dev_portfolio = sqrt(weights(1)^2 * std_dev_asset1^2 + weights(2)^2 * std_dev_asset2^2);
% 打印投资组合的标准差
disp(['投资组合标准差:' num2str(std_dev_portfolio)]);
```
# 6. MATLAB中的标准差扩展
### 6.1 标准差的图形化表示
标准差的图形化表示可以帮助我们直观地了解数据的分布情况。MATLAB中提供了多种绘制图形的方法,可以用于标准差的表示。
#### 6.1.1 直方图
直方图是一种柱状图,它显示了数据在不同区间内的分布情况。对于标准差,直方图可以显示数据在不同标准差范围内的分布。
```matlab
% 生成数据
data = randn(1000, 1);
% 计算标准差
std_dev = std(data);
% 绘制直方图
histogram(data, 'Normalization', 'probability');
xlabel('数据值');
ylabel('概率密度');
title(['直方图(标准差 = ', num2str(std_dev), ')']);
```
#### 6.1.2 箱线图
箱线图是一种显示数据分布和离散程度的图形。对于标准差,箱线图可以显示数据的四分位数范围、中位数和异常值。
```matlab
% 生成数据
data = randn(1000, 1);
% 计算标准差
std_dev = std(data);
% 绘制箱线图
boxplot(data);
xlabel('数据组');
ylabel('数据值');
title(['箱线图(标准差 = ', num2str(std_dev), ')']);
```
### 6.2 标准差的机器学习应用
标准差在机器学习中有着广泛的应用,包括特征缩放和模型评估。
#### 6.2.1 特征缩放
特征缩放是将数据中的不同特征缩放到相同范围内的过程。标准差可以用于特征缩放,因为它可以衡量数据的离散程度。
```matlab
% 生成数据
data = randn(1000, 2);
% 计算标准差
std_dev = std(data);
% 特征缩放
scaled_data = data ./ std_dev;
```
#### 6.2.2 模型评估
标准差可以用于评估机器学习模型的性能。例如,在回归模型中,标准差可以衡量模型预测值与真实值之间的差异。
```matlab
% 生成数据
data = randn(1000, 2);
% 训练模型
model = fitlm(data(:, 1), data(:, 2));
% 预测值
predictions = predict(model, data(:, 1));
% 计算标准差
std_dev = std(predictions - data(:, 2));
% 输出标准差
disp(['标准差:', num2str(std_dev)]);
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 MATLAB 中标准差计算的方方面面。从基础概念到高级技巧,涵盖了 10 个必知技巧,掌握标准差计算精髓。揭秘了 MATLAB 求标准差的幕后机制,帮助读者深入理解算法原理,提升计算效率。专栏还提供了常见陷阱的避坑指南,确保精准计算标准差。此外,还展示了实战案例,深入分析数据,洞悉标准差奥秘。性能优化技巧提升了计算效率,应对海量数据。扩展应用探索了标准差在数据分析中的强大作用。进阶技巧掌握高级函数,探索标准差的更多可能。自动化处理利用脚本和函数,提升工作效率。专栏还强调了标准差在机器学习、医学、自然科学、工程和数据可视化等领域的应用,阐明其重要意义。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【数据同步秘籍】:跨平台EQSL通联卡片操作的最佳实践
# 摘要
本文全面探讨了跨平台EQSL通联卡片同步技术,详细阐述了同步的理论基础、实践操作方法以及面临的问题和解决策略。文章首先介绍了EQSL通联卡片同步的概念,分析了数据结构及其重要性,然后深入探讨了同步机制的理论模型和解决同步冲突的理论。此外,文章还探讨了跨平台数据一致性的保证方法,并通过案例分析详细说明了常见同步场景的解决方案、错误处理以及性能优化。最后,文章预测了未来同步技术的发展趋势,包括新技术的应用前景和同步技术面临的挑战。本文为实现高效、安全的
【DevOps快速指南】:提升软件交付速度的黄金策略
# 摘要
DevOps作为一种将软件开发(Dev)与信息技术运维(Ops)整合的实践方法论,源于对传统软件交付流程的优化需求。本文从DevOps的起源和核心理念出发,详细探讨了其实践基础,包括工具链概览、自动化流程、以及文化与协作的重要性。进一步深入讨论了持续集成(CI)和持续部署(CD)的实践细节,挑战及其解决对策,以及在DevOps实施过程中的高级策略,如安全性强化和云原生应用的容器化。
【行业标杆案例】:ISO_IEC 29147标准下的漏洞披露剖析
# 摘要
本文系统地探讨了ISO/IEC 29147标准在漏洞披露领域的应用及其理论基础,详细分析了漏洞的生命周期、分类分级、披露原则与流程,以及标准框架下的关键要求。通过案例分析,本文深入解析了标准在实际漏洞处理中的应用,并讨论了最佳实践,包括漏洞分析、验证技术、协调披露响应计划和文档编写指南。同时,本文也提出了在现有标准指导下的漏洞披露流程优化策略,以及行业标杆的
智能小车控制系统安全分析与防护:权威揭秘
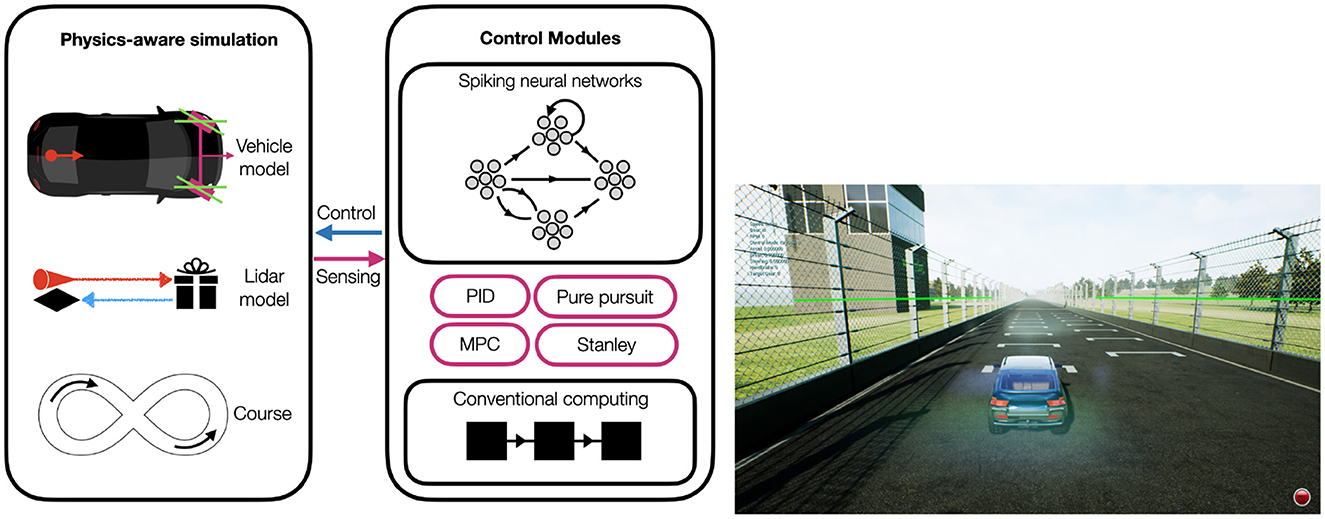
# 摘要
随着智能小车控制系统的广泛应用,其安全问题日益凸显。本文首先概述了智能小车控制系统的基本架构和功能特点,随后深入分析了该系统的安全隐患,包括硬件和软件的安全威胁、潜在的攻击手段及安全风险评估方法。针对这些风险,文章提出了一整套安全防护措施,涵盖了物理安全、网络安全与通信以及软件与固件的保护策略。此外,本文还讨论了安全测试与
【编程进阶】:探索matplotlib中文显示最佳实践

# 摘要
matplotlib作为一个流行的Python绘图库,其在中文显示方面存在一些挑战,本论文针对这些挑战进行了深入探讨。首先回顾了matplotlib的基础知识和中文显示的基本原理,接着详细分析了中文显示问题的根本原因,包括字体兼容性和字符编码映射。随后,提出了多种解决方案,涵盖了配置方法、第三方库的使用和针对不同操作系统的策略。论文进一步探讨了中
非线性控制算法破解:面对挑战的创新对策

# 摘要
非线性控制算法在现代控制系统中扮演着关键角色,它们的理论基础及其在复杂环境中的应用是当前研究的热点。本文首先探讨了非线性控制系统的理论基础,包括数学模型的复杂性和系统稳定性的判定方法。随后,分析了非线性控制系统面临的挑战,包括高维系统建模、系统不确定性和控制策略的局限性。在理论创新方面,本文提出新型建模方法和自适应控制策略,并通过实践案例分析了这些理论的实际应用。仿
Turbo Debugger与版本控制:6个最佳实践提升集成效率
# 摘要
本文旨在介绍Turbo Debugger及其在版本控制系统中的应用。首先概述了Turbo Debugger的基本功能及其在代码版本追踪中的角色。随后,详细探讨了版本控制的基础知识,包括不同类型的版本控制系统和日常操作。文章进一步深入分析了Turbo Debugger与版本控制集成的最佳实践,包括调试与
流量控制专家:Linux双网卡网关选择与网络优化技巧

# 摘要
本文对Linux双网卡网关的设计与实施进行了全面的探讨,从理论基础到实践操作,再到高级配置和故障排除,详细阐述了双网卡网关的设置过程和优化方法。首先介绍了双网卡网关的概述和理论知识,包括网络流量控制的基础知识和Linux网络栈的工作原理。随后,实践篇详细说明了如何设置和优化双网卡网关,以及在设置过程中应采用的网络优化技巧。深入篇则讨论了高级网络流量控制技术、安全策略和故障诊断与修复方法。最后,通
GrblGru控制器终极入门:数控新手必看的完整指南

# 摘要
GrblGru控制器作为先进的数控系统,在机床操作和自动化领域发挥着重要作用。本文概述了GrblGru控制器的基本理论、编程语言、配置设置、操作实践、故障排除方法以及进阶应用技术。通过对控制器硬件组成、软件功能框架和G代码编程语言的深入分析,文章详细介绍了控制器的操作流程、故障诊断以及维护技巧。此外,通过具体的项目案例分析,如木工作品和金属雕刻等,本文进一步展示了GrblGr
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )