【深入剖析Memcache】:Python开发者必备的缓存应用与实践技巧
发布时间: 2024-10-09 11:23:10 阅读量: 113 订阅数: 41 
# 1. Memcache概述与核心原理
Memcache是一种高性能的分布式内存对象缓存系统,用于加速动态web应用程序,减轻数据库负载。本章首先介绍Memcache的基本概念和核心原理,然后深入探讨其内部工作机制,为后续章节的集成、应用和优化打下坚实基础。
## 1.1 Memcache核心原理简介
Memcache通过在内存中缓存数据和对象来减少数据库查询的次数,从而提高数据访问速度和降低数据库的负载。它支持键值对存储,数据结构简单,存取效率高。
## 1.2 内存管理机制
Memcache分配固定大小的内存块来存储对象,这些内存块被称为“slabs”。每个slab被划分为更小的页(page),数据项根据大小存放在相应大小的页中。当一个slab填满时,Memcache会请求更多的内存来创建新的slab。
## 1.3 分布式缓存特性
Memcache以分布式的方式来实现,它允许在多台机器上共享内存数据。一个项目中的多个进程可以通过网络访问Memcache服务器,实现数据的共享与缓存,这使得它特别适用于大规模的web应用。
通过本章内容的学习,读者将对Memcache的工作原理有一个初步的了解,并对Memcache在实际应用中的价值有一个基本的认识。下一章将详细介绍Memcache与Python的集成与应用。
# 2. Memcache与Python的集成
## 2.1 Python操作Memcache的库与接口
在本章节中,我们深入了解如何使用Python与Memcache进行集成,首先我们将探讨Python客户端库的选择,然后逐步深入介绍如何进行基础的Memcache操作。
### 2.1.1 Python memcache客户端库的选择
Python与Memcache集成的首选库是`python-memcached`。它是一个成熟的客户端库,广泛用于Python应用中与Memcache服务进行交互。该库的安装非常简单,可以使用pip进行安装:
```bash
pip install python-memcached
```
`python-memcached`库遵循最新的协议,并支持多服务器配置,故障转移机制以及key-value存储。通过这个库,Python开发者可以轻松地进行缓存数据的读写操作。
### 2.1.2 基本的Memcache操作:设置和获取缓存
在Python程序中,集成Memcache并执行基本操作的代码示例如下:
```python
from memcache import Client
# 连接到Memcache服务器
memcache_server = Client(['***.*.*.*:11211'])
# 设置缓存值,key为'key1',value为'hello world'
memcache_server.set('key1', 'hello world')
# 获取之前设置的缓存值
value = memcache_server.get('key1')
print(value) # 输出: hello world
# 使用字典方式批量设置多个缓存项
memcache_server.set_multi({'key2': 'value2', 'key3': 'value3'})
# 批量获取多个缓存项
values = memcache_server.get_multi(['key2', 'key3'])
print(values) # 输出: {'key2': 'value2', 'key3': 'value3'}
```
在这个基本操作的代码块中,我们首先导入`memcache`模块,然后创建了一个Memcache客户端实例。我们通过`set`方法设置一个缓存项,并通过`get`方法读取这个缓存项。此外,`set_multi`和`get_multi`方法可以同时对多个键值对进行操作,这在实际应用中非常高效。
## 2.2 Memcache在Python项目中的应用模式
### 2.2.1 Memcache与Web框架的集成
当Memcache集成到基于Python的Web框架中,如Flask或Django时,通常会使用框架提供的缓存抽象层。以Flask为例,通过扩展Flask-Caching来集成Memcache:
```python
from flask import Flask
from flask_caching import Cache
app = Flask(__name__)
cache = Cache(app, config={'CACHE_TYPE': 'memcached'})
@app.route('/')
def index():
cache_key = 'index_html'
html = cache.get(cache_key)
if html is None:
html = render_template('index.html')
cache.set(cache_key, html, timeout=500)
return html
```
在这个Flask应用集成Memcache的例子中,首先创建了一个Flask应用对象,并初始化了cache对象,指定缓存类型为'memcached'。接着在路由函数中,我们检查缓存中是否存在页面的HTML,如果不存在则渲染模板并存储到缓存中。
### 2.2.2 Memcache缓存策略和使用场景
Memcache的使用策略非常多样,其中常见的缓存策略包括:
- **最近最少使用(LRU)**:适用于需要优先淘汰最近最少使用的数据。
- **固定时间过期**:根据时间来决定数据是否过期,适合那些数据变化不是特别频繁的场景。
- **基于空间的淘汰**:当缓存使用的内存达到一定限度时,开始逐出数据,确保不会影响服务器的正常运行。
使用场景通常包括:
- **数据库查询结果缓存**:减轻数据库的负载,加速数据检索。
- **会话存储**:对于需要会话保持的应用,可以将会话信息存储在缓存中。
- **内容分发网络(CDN)数据预取**:提前将内容加载到缓存中,以便快速交付给用户。
## 2.3 Memcache的高级特性与最佳实践
### 2.3.1 多服务器配置和故障转移
Memcache支持多服务器配置,这意味着可以指定多个服务器地址,从而实现故障转移和负载均衡。Python客户端库`python-memcached`提供了这种支持:
```python
from memcache import Client
# 使用多个Memcache服务器地址进行连接
memcache_servers = ['***.*.*.*:11211', '***.*.*.*:11212']
memcache_server = Client(memcache_servers)
# 现在写入和读取操作会在多个服务器之间进行故障转移
memcache_server.set('key', 'value')
value = memcache_server.get('key')
```
### 2.3.2 Memcache内存管理和淘汰策略
Memcache的内存管理涉及缓存项的自动过期、内存不足时的项淘汰等。用户可以通过设置参数来控制淘汰策略,例如:
```python
memcache_server.set('key', 'value', time=500) # 设置500秒后过期
memcache_server.set('key', 'value', min_compress_len=100) # 小于100字节的数据启用压缩
```
在这个例子中,我们通过设置`time`参数控制缓存项在指定秒数后自动过期。而`min_compress_len`参数则允许我们对小于给定长度的数据启用压缩功能,从而更有效地利用内存。
Memcache的淘汰策略决定了哪些数据应该被删除来为新数据腾出空间。默认情况下,Memcache使用LRU策略,即当缓存达到内存限制时,最先被访问的数据项将被保留,而最近最少被访问的数据项将被删除。
通过以上方式,Memcache的高级特性与最佳实践可为应用提供高效的缓存解决方案,并保证数据的可用性和性能。
# 3. Memcache的数据管理与优化
## 3.1 Memcache数据存储结构分析
### 3.1.1 键值存储和数据类型
Memcache采用了简单的键值存储模型,其中键(key)是一个字符串,用于唯一标识存储的数据,而值(value)可以是字符串、整数、浮点数等不同类型的数据。在Python中,可以使用`python-memcached`库来操作这些数据。
```python
import memcache
# 连接到本地Memcache服务器
mc = memcache.Client(['***.*.*.*:11211'], debug=0)
# 设置数据,键为'key1',值为字符串'hello world'
mc.set('key1', 'hello world')
# 获取数据
value = mc.get('key1')
print(value) # 输出: hello world
# 设置一个整数型值
mc.set('key2', 123)
# 获取一个整数型值
value = mc.get('key2')
print(value) # 输出: 123
```
在上述代码中,使用`set`方法存储数据,使用`get`方法检索数据。Memcache不仅支持简单的字符串,还支持复杂的数据结构,比如列表、集合等,这些都是通过序列化来实现的。
### 3.1.2 数据一致性与版本控制
数据一致性是缓存系统设计中需要考虑的重要因素。在多服务器环境中,多个客户端可能同时修改同一个键,而Memcache本身不具备原子性操作,因此需要在应用层实现一致性控制。一个常见的做法是引入版本号:
```python
def set_with_version(key, value):
version_key = key + ':version'
version = mc.get(version_key)
if version is None:
version = 0
else:
version = int(version) + 1
# 存储新的值和版本号
mc.set(key, value)
mc.set(version_key, str(version))
return version
# 使用版本号来存储数据
version = set_with_version('key3', 'updated value')
```
在这个例子中,我们引入了一个额外的键(key:version)来跟踪每次更新的版本号。每次更新缓存时,版本号递增,这样客户端就可以通过检查版本号来判断缓存值是否更新,从而确保数据一致性。
## 3.2 Memcache性能优化技巧
### 3.2.1 缓存热点数据和预加载
对于经常查询的数据,如网站的热门商品、用户信息等,使用Memcache缓存可以极大地提高性能。所谓缓存热点数据,就是将频繁读取的数据长期存储在内存中,避免重复的数据库查询操作。
预加载是一种在应用启动时或在低峰时段,主动加载可能被查询的热点数据到缓存的技术。这样可以确保在用户访问时数据已经处于缓存中,进一步减少响应时间。
### 3.2.2 Memcache监控与调优指标
Memcache的性能调优可以从多个方面入手。监控是性能优化的第一步,了解缓存的命中率、内存使用率、条目数量等指标对于调优至关重要。
- 命中率(Hit Ratio):表示缓存命中次数与总请求次数的比例。命中率高说明缓存效果好。
- 内存利用率(Memory Usage):Memcache使用的内存量。
- 条目数量(Item Count):存储在Memcache中的键值对数量。
在Python中,可以使用`stats`方法获取这些信息:
```python
stats = mc.stats()
print(stats)
```
通过分析这些监控指标,可以调整服务器配置、优化缓存策略,如调整过期时间、增加服务器资源等。
Memcache优化的其他关键点包括:
- **过期策略(Expiration)**:合理设置数据的过期时间,避免缓存垃圾的产生。
- **淘汰策略(Eviction Policy)**:决定当内存不足时,哪些数据将被移除。
- **内存分配(Memory Allocation)**:预分配足够的内存给Memcache,减少动态内存分配带来的性能开销。
为了深入了解和优化Memcache的性能,开发者还需要对服务器硬件、网络状况、客户端行为等多方面因素进行综合考量。
# 4. Memcache在Python项目中的实战应用
## 4.1 缓存数据模型与ORM集成
在Python Web项目中,使用Memcache可以大幅提高应用性能,尤其是在处理大量数据和高并发访问的场景中。数据库操作通常耗时长,且对资源消耗大,合理利用缓存可以避免重复的数据库查询,加速数据读取速度。在本节中,将重点讨论如何在Python项目中使用Memcache作为缓存解决方案,并探讨如何将其与对象关系映射(ORM)工具,如SQLAlchemy,集成,以及如何处理数据库查询的缓存策略。
### 4.1.1 针对数据库查询的缓存策略
缓存数据库查询是Memcache在Web应用中最为常见的使用方式。利用Memcache缓存数据库查询结果,可以显著减少数据库的压力并提升响应速度。在实现这一策略时,关键步骤如下:
1. **分析数据库查询模式:** 首先确定哪些数据库查询是高频的,且返回的数据量不大,适合缓存。
2. **设置缓存键值:** 根据查询的参数构建唯一的缓存键值。
3. **缓存过期策略:** 设置合理的过期时间,确保数据的及时更新。
以下是使用Python memcache客户端库实现数据库查询缓存的简单代码示例:
```python
import memcache
# 初始化Memcache客户端
mc = memcache.Client(['localhost:11211'], debug=0)
def get_data_from_database(key):
# 尝试从数据库获取数据
# ...
def get_data(key, db_query_function):
# 从Memcache中尝试获取数据
value = mc.get(key)
if value is None:
# 缓存未命中,从数据库查询
value = db_query_function()
# 将查询结果存入缓存,这里设置的过期时间为60秒
mc.set(key, value, 60)
return value
# 调用函数获取数据,传入的key为数据库查询的唯一标识
cached_value = get_data('unique_key_for_query', get_data_from_database)
```
### 4.1.2 缓存管理在ORM中的实践
在使用ORM工具进行数据库操作时,我们可以利用ORM框架提供的事件钩子和回调机制来管理缓存。这样可以更加精确地控制缓存的更新时机,避免缓存数据与数据库数据不一致的情况。主要操作步骤如下:
1. **创建ORM钩子或信号:** 根据ORM框架的特点,创建相应的钩子或信号监听器。
2. **缓存清理策略:** 根据ORM框架中的事件触发缓存的清理和更新。
下面是一个利用SQLAlchemy ORM框架与Memcache集成的示例代码:
```python
from sqlalchemy import create_engine, Column, Integer, String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
import memcache
engine = create_engine('sqlite:///test.db')
Session = sessionmaker(bind=engine)
session = Session()
Base = declarative_base()
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String)
# 初始化Memcache客户端
mc = memcache.Client(['localhost:11211'], debug=0)
@session.event.listens_for(session, "after_flush")
def clear_cache(session, flush_context):
# 清除缓存的逻辑代码,这里简单地删除相关缓存项
mc.delete('users_list') # 假设有一个缓存了所有用户列表的key
# 使用session进行ORM操作...
# 获取用户列表的示例函数
def get_users_list():
users_list = mc.get('users_list')
if users_list is None:
users_list = session.query(User.name).all()
mc.set('users_list', users_list, 600)
return users_list
```
以上示例展示了如何结合ORM框架的生命周期事件管理缓存的更新,从而确保缓存数据的一致性。需要注意的是,每个ORM框架可能有不同的集成方式和API,因此需要根据实际使用的ORM工具进行适当调整。
## 4.2 分布式缓存与Session共享
在分布式系统中,多个服务器实例之间共享数据是一个常见的需求。Memcache作为一个分布式缓存系统,可以支持多个服务器实例之间的数据共享。在Web应用中,尤其重要的是会话(Session)数据的共享。这对于用户登录状态的持续、购物车数据的同步等场景尤为重要。
### 4.2.1 分布式缓存环境的搭建与配置
要实现Memcache的分布式缓存环境,需要做以下几步:
1. **部署多个Memcache服务器实例:** 首先在不同的物理或虚拟机上启动多个Memcache实例。
2. **客户端配置:** 在使用Memcache的应用程序代码中,配置一个包含所有服务器地址的客户端实例。
以下是一个简单的Memcache客户端配置示例:
```python
import memcache
# 创建客户端连接池
servers = ['***.***.*.***:11211', '***.***.*.***:11211']
mc = memcache.Client(servers, debug=0)
```
### 4.2.2 Memcache在Web会话管理中的应用
在Web会话管理中,可以使用Memcache来存储会话数据。这样一来,无论用户请求被哪个服务器实例处理,都可以访问到相同的会话数据,实现会话的共享。以下是一个使用Flask框架和Memcache存储会话数据的示例:
```python
from flask import Flask, session
from flask_session_memcache import MemcacheSessionInterface
app = Flask(__name__)
app.config['SESSION_TYPE'] = 'memcached'
app.config['SESSION_MEMCACHED_SERVERS'] = ['localhost:11211']
app.config['SESSION_USE_SIGNER'] = True # 确保会话数据的完整性
app.secret_key = 'your_secret_key'
# 初始化Memcache会话接口
session_interface = MemcacheSessionInterface()
app.session_interface = session_interface
# 普通的路由和视图函数
@app.route('/')
def index():
session['count'] = session.get('count', 0) + 1
return f'You have viewed this page {session["count"]} times.'
if __name__ == '__main__':
app.run()
```
在这个示例中,我们配置了Flask使用Memcache来存储会话数据,并为会话键值设置了签名,以确保安全性。需要注意的是,`MemcacheSessionInterface`是一个扩展库,用于在Flask中集成Memcache作为会话数据的存储后端。
## 4.3 缓存失效与一致性问题处理
缓存的使用虽然能极大提升性能,但同时也带来了数据一致性的问题。当缓存数据失效后,需要有一套机制来确保数据的一致性。这包括如何处理缓存失效,以及如何设计缓存和数据库之间的同步策略。
### 4.3.1 缓存失效机制的实现
缓存失效指的是当数据发生变化时,及时使相关的缓存数据失效,以避免返回旧数据。实现缓存失效的机制通常有以下几种:
- **定时过期:** 设置缓存数据的生存时间,当时间到达后,自动使数据失效。
- **手动过期:** 当数据发生变化时,显式地调用缓存操作来使相关数据失效。
- **版本号机制:** 在缓存数据时附加一个版本号,每次数据更新时,版本号递增。数据读取时,先检查版本号,如果版本不一致,则更新缓存。
下面展示如何使用Python memcache库手动使特定缓存数据失效:
```python
def invalidate_cache(key):
mc.delete(key) # 删除指定的缓存项
# 假设某个数据库记录更新后,需要使相关的缓存失效
invalidate_cache('record_123')
```
### 4.3.2 缓存与数据库一致性保证策略
为了保证缓存和数据库之间的一致性,我们可以采取以下策略:
- **写入时更新(Write-through):** 在更新数据库的同时,也更新缓存。
- **写入后更新(Write-after-write):** 允许先更新数据库,然后异步更新缓存。
- **失效模式(Invalidate):** 当数据库更新后,使相关的缓存失效。
这里需要注意的是,在分布式系统中,更新操作可能会跨多个服务器实例发生。因此,实现缓存一致性策略时,应考虑分布式事务和同步机制,确保数据的一致性不会被破坏。
例如,假设一个用户更新了他的个人资料信息后,我们需要在缓存中清除或更新这些信息。在SQLAlchemy中,我们可以在提交会话后立即清理相关缓存:
```python
@session.event.listens_for(session, "after_commit")
def clear_user_cache(session):
# 在数据库提交后清除用户缓存
invalidate_cache(f'user_{***.get("user_id")}')
```
这个示例展示了在SQLAlchemy ORM框架中如何监听数据库提交事件,然后清除相关的缓存数据,以确保缓存与数据库数据的一致性。
在本章节中,我们详细探讨了Memcache在Python项目中实战应用的几个关键方面,包括缓存数据模型、分布式缓存的搭建与配置,以及缓存失效和一致性问题的处理策略。通过理解并应用这些方法,开发者可以在保证数据一致性的前提下,显著提高应用的性能和可扩展性。在后续章节中,我们将继续深入了解Memcache的安全性和扩展性考虑,以及它的未来发展趋势和企业级应用案例。
# 5. Memcache的安全性与扩展性考虑
## 5.1 Memcache的安全机制
Memcache作为一种广泛使用的内存缓存系统,其安全性是不可忽视的。它运行在网络中,如果缺乏必要的安全措施,可能会成为攻击者的目标,造成数据泄露或其他安全问题。本节将探讨Memcache的安全机制,包括认证机制、网络通信安全、缓存污染防护和隔离策略。
### 5.1.1 认证机制与网络通信安全
由于Memcache本身不提供复杂的认证机制,它默认是开放的。这在内部网络中可能是可接受的,但在互联网上直接暴露Memcache实例是不安全的。因此,为了提高安全性,建议采取以下措施:
1. **网络隔离**:将Memcache服务器置于私有子网内,只允许内部网络的可信机器访问。
2. **认证插件**:使用第三方认证插件来为Memcache添加认证机制。
3. **使用TLS/SSL**:在通信过程中使用安全传输层协议来保护数据在传输过程中的安全。
### 5.1.2 缓存污染防护和隔离策略
缓存污染是指不恰当或恶意的数据写入缓存系统,这可能会导致正常数据被覆盖或损坏。为了防止缓存污染,可以采取以下措施:
1. **键命名规则**:合理地设计键名命名规则,例如在键名中包含应用名称,以避免不同应用之间的键名冲突。
2. **访问控制**:在应用程序中实现严格的访问控制逻辑,确保只有授权用户可以对特定的数据进行读写操作。
3. **数据验证**:在将数据写入缓存之前进行数据验证,确保数据的正确性和合法性。
## 5.2 Memcache的扩展性与集群管理
在高流量的环境下,单个Memcache实例可能无法满足需求,这时就需要构建一个可扩展的缓存集群。本节将讨论如何构建和管理大型缓存集群,以及Memcache与其他缓存系统的比较。
### 5.2.1 大型缓存集群的构建与管理
构建一个可扩展的Memcache集群需要考虑以下因素:
1. **分布式架构设计**:设计合理的分布式架构来保证数据的均匀分布,避免数据倾斜。
2. **数据一致性**:选择合适的缓存策略来保持数据一致性,如一致性哈希。
3. **故障转移与高可用**:配置故障检测和自动转移机制,提高系统的可用性。
### 5.2.2 Memcache与其他缓存系统的比较
Memcache不是唯一的缓存系统选择,还有如Redis、Ehcache等其他备选方案。每个系统都有其特点和适用场景。在做选择时,需要考虑以下几个方面:
1. **性能**:对比各个系统的读写性能,根据实际需要做出选择。
2. **功能丰富性**:Memcache功能相对简单,如果需要更复杂的特性(如持久化、事务支持等),应考虑其他系统。
3. **社区支持与文档**:查看各个系统的社区活跃度和文档完整性,这些往往是后续维护和故障排查的关键。
接下来,我们将通过代码块、表格和mermaid流程图深入探讨这些内容。
# 6. Memcache未来发展趋势与案例分析
随着互联网技术的不断进步和大数据时代的到来,缓存技术也在不断地演进以满足新的业务需求。本章将探讨Memcache技术的最新发展趋势,并结合企业级应用案例进行深入分析。
## 6.1 Memcache技术演进和新特性
Memcache作为一种广泛使用的内存缓存系统,在不断优化其性能和稳定性的同时,也在积极引入新的特性和协议扩展,以适应现代化应用场景。
### 6.1.1 Memcache协议的扩展与新实现
Memcache协议的扩展为缓存系统提供了更多的灵活性和功能。新的协议实现支持了更多类型的数据结构,比如集合(sets)、有序集合(sorted sets)和哈希表(hashes)。这些结构的引入使得Memcache能够更好地应对复杂的业务场景,如排行榜、用户信息管理等。
```python
# Python 示例:使用哈希结构存储用户信息
import memcache
mc = memcache.Client(['localhost'], debug=0)
user_id = 123
user_data = {'username': 'johndoe', 'email': '***'}
mc.hmset('user:%s' % user_id, user_data)
```
在上述代码中,我们使用了Python的memcache客户端库来存储一个用户信息的哈希表。这样的数据结构支持了更复杂的数据管理需求。
### 6.1.2 现代应用对缓存的更高要求
现代应用要求缓存系统不仅要能处理大量的并发请求,还要具备高效的数据淘汰机制,以及对持久化存储的支持。为了满足这些要求,Memcache社区和开发者正在探索新的解决方案,例如将Memcache与磁盘存储相结合,从而在不牺牲性能的前提下增加数据的持久性。
## 6.2 企业级应用案例研究
企业级应用案例分析能提供实际应用中Memcache优化和问题解决的真实视角。
### 6.2.1 Memcache在大型网站中的应用
大型网站往往具有极高的访问量,Memcache在这样的场景下可以显著减轻数据库的压力并提升响应速度。以下是一个典型的网站架构中Memcache的应用案例。
```mermaid
graph LR
A[Web服务器] -->|查询请求| B[Memcache集群]
B -->|缓存命中| C[返回数据]
B -->|缓存未命中| D[数据库]
D -->|查询结果| B
B -->|更新缓存| A
```
在上图中,Web服务器的查询请求首先访问Memcache集群。如果缓存命中,则直接返回数据,否则查询数据库并将结果更新到缓存中。
### 6.2.2 Memcache性能优化的实际案例分析
在实际应用中,通过优化Memcache的使用策略,可以显著提升缓存效率和系统的整体性能。以下是一些常见的优化措施:
- **数据分片**:对缓存数据进行分片,可以提升缓存的并发处理能力。
- **键的命名规范**:合理的键命名可以简化缓存管理,并有助于避免冲突。
- **监控和调整**:通过监控工具定期检查缓存命中率和性能指标,并据此进行调整。
```python
# Python 示例:数据分片策略
# 假设使用用户ID进行分片
def get_memcache_key_for_user(user_id):
return 'user:%s' % (user_id % 100)
key = get_memcache_key_for_user(user_id)
mc.set(key, user_data)
```
以上代码展示了如何通过用户ID的取模操作来实现简单的数据分片。
通过对实际案例的分析,我们可以了解到在面对高并发、大数据量等挑战时,Memcache能够提供的解决方案,以及针对特定问题的最佳实践和优化方法。
企业应持续关注Memcache的发展,并结合自身的业务需求进行适当的调整和优化,以充分发挥Memcache在数据缓存管理中的潜力。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 中 Memcache 库的方方面面,为 Python 开发者提供了全面的指南。从 Memcache 的基础概念和用法,到其在 Python 项目中的实际应用和优化技巧,再到分布式缓存和数据持久化解决方案,该专栏涵盖了所有关键主题。通过深入剖析 Memcache 的缓存机制和一致性问题,以及提供实用案例和最佳实践,该专栏旨在帮助读者掌握 Memcache,并将其有效应用于 Python 应用程序中,以提升性能和效率。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【数据表结构革新】租车系统数据库设计实战:提升查询效率的专家级策略

# 1. 数据库设计基础与租车系统概述
## 1.1 数据库设计基础
数据库设计是信息系统的核心,它涉及到数据的组织、存储和管理。良好的数据库设计可以使系统运行更加高效和稳定。在开始数据库设计之前,我们需要理解基本的数据模型,如实体-关系模型(ER模型),它有助于我们从现实世界中抽象出数据结构。接下来,我们会探讨数据库的规范化理论,它是减少数据冗余和提高数据一致性的关键。规范化过程将引导我们分解数据表,确保每一部分数据都保持其独立性和
【模块化设计】S7-200PLC喷泉控制灵活应对变化之道

# 1. S7-200 PLC与喷泉控制基础
## 1.1 S7-200 PLC概述
S7-200 PLC(Programmable Logic Controller)是西门子公司生产的一款小型可编程逻辑控制器,广泛应用于自动化领域。其以稳定、高效、易用性著称,特别适合于小型自动化项目,如喷泉控制。喷泉控制系统通过PLC来实现水位控制、水泵启停以及灯光变化等功能,能大大提高喷泉的
【项目管理】:如何在项目中成功应用FBP模型进行代码重构
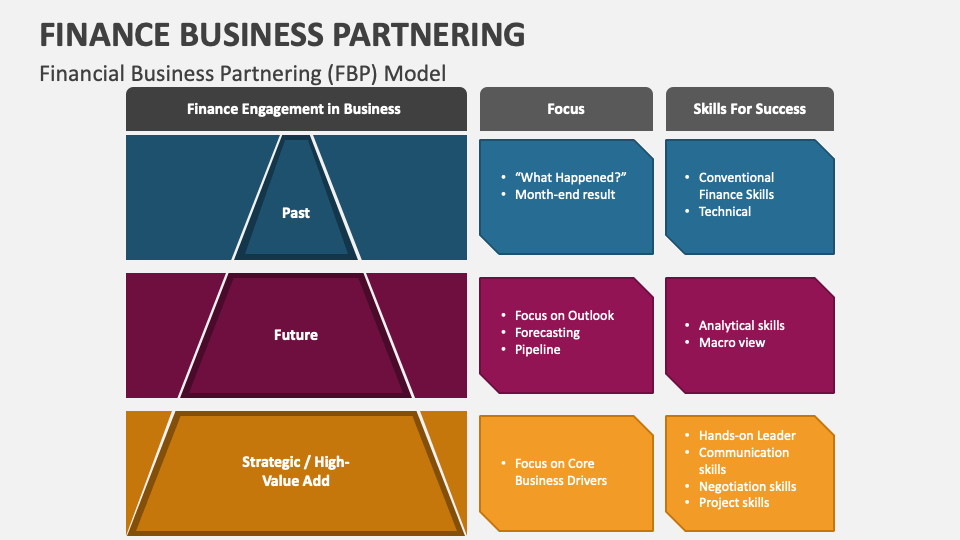
# 1. FBP模型在项目管理中的重要性
在当今IT行业中,项目管理的效率和质量直接关系到企业的成功与否。而FBP模型(Flow-Based Programming Model)作为一种先进的项目管理方法,为处理复杂
【高斯信道与Chirp信号实战】:5大策略优化噪声环境下的信号传输

# 1. 高斯信道与Chirp信号基础
在现代通信系统中,对信号进行有效地传输和处理是至关重要的。本章将介绍高斯信道的基本概念以及Chirp信号的基础知识,为理解后续章节中的信号分析与优化策略奠定基
【可持续发展】:绿色交通与信号灯仿真的结合

# 1. 绿色交通的可持续发展意义
## 1.1 绿色交通的全球趋势
随着全球气候变化问题日益严峻,世界各国对环境保护的呼声越来越高。绿色交通作为一种有效减少污染、降低能耗的交通方式,成为实现可持续发展目标的重要组成部分。其核心在于减少碳排放,提高交通效率,促进经济、社会和环境的协调发展。
## 1.2 绿色交通的节能减排效益
相较于传统交通方式,绿色交
【同轴线老化与维护策略】:退化分析与更换建议

# 1. 同轴线的基本概念和功能
同轴电缆(Coaxial Cable)是一种广泛应用的传输介质,它由两个导体构成,一个是位于中心的铜质导体,另一个是包围中心导体的网状编织导体。两导体之间填充着绝缘材料,并由外部的绝缘护套保护。同轴线的主要功能是传输射频信号,广泛应用于有线电视、计算机网络、卫星通信及模拟信号的长距离传输等领域。
在物理结构上,
【Android主题制作工具推荐】:提升设计和开发效率的10大神器
# 1. Android主题制作的重要性与应用概述
## 1.1 Android主题制作的重要性
在移动应用领域,优秀的用户体验往往始于令人愉悦的视觉设计。Android主题制作不仅增强了视觉吸引力,更重要的是它能够提供一致性的
视觉SLAM技术应用指南:移动机器人中的应用详解与未来展望

# 1. 视觉SLAM技术概述
## 1.1 SLAM技术的重要性
在机器人导航、增强现实(AR)和虚拟现实(VR)等领域,空间定位
产品认证与合规性教程:确保你的STM32项目符合行业标准

# 1. 产品认证与合规性基础知识
在当今数字化和互联的时代,产品认证与合规性变得日益重要。以下是关于这一主题的几个基本概念:
## 1.1 产品认证的概念
产品认证是确认一个产品符合特定标准或法规要求的过程,通常由第三方机构进行。它确保了产品在安全性、功能性和质量方面的可靠性。
## 1.2 产品合规性的意义
合规性不仅保护消费者利益,还帮
【PSO-SVM算法调优】:专家分享,提升算法效率与稳定性的秘诀
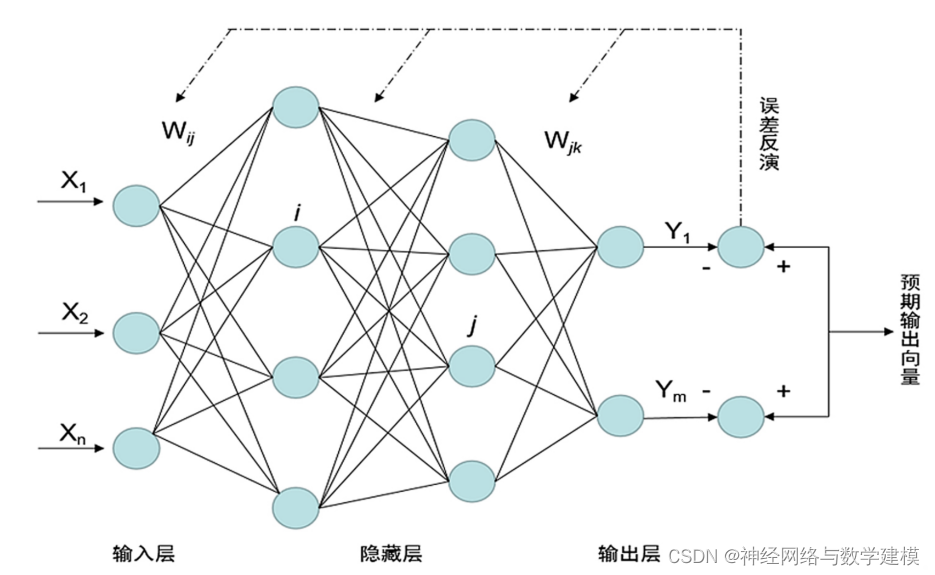
# 1. PSO-SVM算法概述
PSO-SVM算法结合了粒子群优化(PSO)和支持向量机(SVM)两种强大的机器学习技术,旨在提高分类和回归任务的性能。它通过PSO的全局优化能力来精细调节SVM的参数,优化后的SVM模型在保持高准确度的同时,展现出更好的泛化能力。本章将介绍PSO-SVM算法的来源、优势以及应用场景,为读者提供一个全面的理解框架。
## 1.1 算法来源与背景
PSO-SVM算法的来源基于两个领域:群体智能优化
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )