自定义MATLAB字体颜色:提升图表视觉冲击力,打造吸睛图表
发布时间: 2024-06-09 18:24:38 阅读量: 145 订阅数: 79 

美观且可以很方便自定义的MATLAB绘图颜色

# 1. MATLAB字体颜色的重要性
字体颜色是MATLAB图表中一个至关重要的元素,它可以有效传达信息,增强图表的可读性和美观性。精心选择的字体颜色可以:
- **突出关键信息:**通过使用醒目的颜色,可以将观众的注意力引导至图表中最重要的数据或趋势。
- **区分不同数据类别:**使用不同的字体颜色,可以轻松区分图表中不同的数据类别,使观众更容易理解和比较数据。
- **增强图表的可读性:**选择与图表背景形成鲜明对比的字体颜色,可以提高图表的可读性,使观众更容易阅读和理解图表中的信息。
# 2. 自定义MATLAB字体颜色的理论基础
### 2.1 色彩理论基础
色彩理论是理解和使用颜色的科学。它提供了一个框架,帮助我们了解颜色如何相互作用,以及如何使用它们来创建有效的视觉效果。
**色轮:**色轮是一个圆形图表,显示了所有颜色的排列方式。它分为三原色(红、黄、蓝)、三间色(橙、绿、紫)和六间色(红橙、黄橙、黄绿、蓝绿、蓝紫、红紫)。
**色相、饱和度和亮度:**每个颜色都有三个属性:色相(颜色的名称,如红色、蓝色)、饱和度(颜色的强度)和亮度(颜色的明暗程度)。
**对比色:**对比色是色轮上相距180度的颜色。它们创建强烈的对比度,可以吸引注意力。
**互补色:**互补色是色轮上相距120度的颜色。它们一起使用时可以创建和谐的效果。
### 2.2 字体颜色对图表的影响
字体颜色对图表的影响至关重要。它可以:
**吸引注意力:**使用对比色可以吸引注意力并突出关键信息。
**传达信息:**不同的颜色可以传达不同的信息。例如,红色表示危险,蓝色表示平静。
**提高可读性:**选择与图表背景形成对比的字体颜色可以提高可读性。
**创建视觉层次:**使用不同的字体颜色可以创建视觉层次,引导读者的视线。
**示例代码:**
```matlab
% 创建一个条形图
bar([1, 2, 3, 4, 5]);
% 设置字体颜色为红色
title('Bar Chart', 'Color', 'red');
xlabel('X-Axis');
ylabel('Y-Axis');
```
**代码逻辑分析:**
* `bar()` 函数创建了一个条形图。
* `title()` 函数设置图表标题并指定字体颜色为红色。
* `xlabel()` 和 `ylabel()` 函数设置 x 轴和 y 轴标签。
**参数说明:**
* `'Color'` 参数指定字体颜色。
* `'red'` 参数指定红色字体颜色。
# 3. 自定义MATLAB字体颜色的实践方法
### 3.1 使用文本属性函数
MATLAB提供了多种文本属性函数,允许用户自定义字体颜色。最常用的函数是`text`函数,它可以设置文本的字体、大小、颜色和对齐方式。
```matlab
% 设置文本颜色为红色
text(x, y, 'Hello World', 'Color', 'red');
% 设置文本颜色为RGB值
text(x, y, 'Hello World', 'Color', [1 0 0]);
% 设置文本颜色为十六进制值
text(x, y, 'Hello World', 'Color', '#FF0000');
```
### 3.2 使用颜色映射
MATLAB还提供了颜色映射,它是一组预定义的颜色值,可以应用于数据或文本。使用颜色映射可以轻松地为文本分配一致的颜色。
```matlab
% 创建一个颜色映射
colormap(jet(64));
% 使用颜色映射为文本着色
text(x, y, 'Hello World', 'Colormap', jet(64));
```
### 3.3 使用自定义调色板
如果预定义的颜色映射不满足需求,用户可以创建自己的自定义调色板。调色板是一个包含用户定义的颜色值数组。
```matlab
% 创建一个自定义调色板
myColormap = [
0 0 1; % 蓝色
0 1 0; % 绿色
1 0 0; % 红色
];
% 使用自定义调色板为文本着色
text(x, y, 'Hello World', 'Colormap', myColormap);
```
### 3.4 创建渐变字体颜色
渐变字体颜色是指字体颜色从一种颜色逐渐过渡到另一种颜色。MATLAB提供了`gradient`函数,可以创建渐变颜色。
```matlab
% 创建一个渐变颜色
gradientColors = gradient([0 0 1], [1 0 0], 64);
% 使用渐变颜色为文本着色
text(x, y, 'Hello World', 'Color', gradientColors);
```
# 4. 自定义MATLAB字体颜色的高级技巧
### 4.1 使用自定义调色板
MATLAB允许用户创建自定义调色板,用于指定字体颜色。自定义调色板提供了更大的灵活性,可以创建更复杂和特定的颜色方案。
```matlab
% 创建自定义调色板
myColormap = [
0 0 1; % 蓝色
0 1 0; % 绿色
1 0 0; % 红色
1 1 0; % 黄色
0 1 1; % 青色
1 0 1; % 品红色
];
% 将自定义调色板应用于文本
text(x, y, 'Custom Text', 'Colormap', myColormap);
```
**参数说明:**
* `myColormap`: 自定义调色板,是一个包含RGB颜色的矩阵,每一行代表一种颜色。
* `'Colormap'`: 指定要使用的调色板的属性名称。
### 4.2 创建渐变字体颜色
渐变字体颜色可以创建平滑的过渡,增强图表的美观性。MATLAB提供了几种函数来创建渐变字体颜色。
**使用`colormap`函数:**
```matlab
% 创建渐变字体颜色
colormap = colormap(parula(256));
% 将渐变字体颜色应用于文本
text(x, y, 'Gradient Text', 'Color', colormap(128));
```
**参数说明:**
* `colormap(parula(256))`: 创建一个256色的`parula`调色板。
* `'Color'`: 指定要使用的颜色的属性名称。
* `colormap(128)`: 从调色板中选择第128种颜色,它代表渐变的中间点。
**使用`gradient`函数:**
```matlab
% 创建渐变字体颜色
gradientColors = gradient([0 0 1], [1 0 0], 256);
% 将渐变字体颜色应用于文本
text(x, y, 'Gradient Text', 'Color', gradientColors(128, :));
```
**参数说明:**
* `gradient([0 0 1], [1 0 0], 256)`: 创建一个从蓝色到红色的256色渐变。
* `'Color'`: 指定要使用的颜色的属性名称。
* `gradientColors(128, :)`: 从渐变中选择第128行,它代表渐变的中间点。
# 5. 自定义MATLAB字体颜色的应用场景
### 5.1 强调关键信息
字体颜色是一种有效的方法,可以突出显示图表中的关键信息。例如,可以通过使用对比鲜明的颜色来突出显示数据点、趋势线或标签。这可以帮助观众快速识别图表中最重要的信息。
**代码块:**
```
% 创建条形图
bar(data);
% 设置特定条形的字体颜色
bar_color = 'red';
bar(2, data(2), 'FaceColor', bar_color);
% 添加标签
xlabel('类别');
ylabel('值');
title('条形图,突出显示特定条形');
```
**逻辑分析:**
* `bar(data)` 创建一个条形图,其中 `data` 是要绘制的数据。
* `bar_color` 变量存储要用于突出显示特定条形的颜色。
* `bar(2, data(2), 'FaceColor', bar_color)` 使用 `FaceColor` 属性设置第二个条形的颜色。
* `xlabel()`, `ylabel()` 和 `title()` 函数分别添加 x 轴标签、y 轴标签和图表标题。
### 5.2 区分不同数据类别
字体颜色还可以用来区分图表中的不同数据类别。例如,可以使用不同的颜色来表示不同的数据系列、数据点或数据组。这可以帮助观众轻松识别和比较不同类别的数据。
**代码块:**
```
% 创建散点图
scatter(data1, data2);
hold on;
% 根据数据类别设置不同的字体颜色
color_categories = {'blue', 'red', 'green'};
for i = 1:length(color_categories)
scatter(data1(i), data2(i), 'MarkerFaceColor', color_categories{i});
end
% 添加图例
legend('类别 1', '类别 2', '类别 3');
xlabel('x 轴');
ylabel('y 轴');
title('散点图,区分不同数据类别');
```
**逻辑分析:**
* `scatter(data1, data2)` 创建一个散点图,其中 `data1` 和 `data2` 是要绘制的数据。
* `hold on` 命令允许在同一图表中绘制多个图。
* `color_categories` 变量存储不同数据类别的颜色。
* 循环遍历 `color_categories` 数组,并使用 `MarkerFaceColor` 属性设置每个数据点的颜色。
* `legend()` 函数添加一个图例,标识不同的数据类别。
* `xlabel()`, `ylabel()` 和 `title()` 函数分别添加 x 轴标签、y 轴标签和图表标题。
# 6. MATLAB 字体颜色自定义的最佳实践
在自定义 MATLAB 字体颜色时,遵循以下最佳实践至关重要,以确保图表清晰有效:
### 6.1 遵循配色原则
* **使用对比色:**选择与图表背景形成鲜明对比的字体颜色,以提高可读性。
* **限制颜色数量:**使用 2-3 种颜色,避免图表过于杂乱。
* **考虑色盲:**使用色盲友好调色板,确保所有用户都能理解图表。
### 6.2 考虑图表背景
* **浅色背景:**使用深色字体颜色,以增强对比度。
* **深色背景:**使用浅色字体颜色,以提高可读性。
* **渐变背景:**使用与渐变背景互补的字体颜色。
### 6.3 确保可访问性
* **使用高对比度:**确保字体颜色与背景之间的对比度至少为 4.5:1。
* **避免使用纯白色或纯黑色:**这些颜色在某些背景下可能难以阅读。
* **提供替代文本:**为图表添加替代文本,以便屏幕阅读器能够为视障用户描述图表。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
该专栏深入探讨了 MATLAB 中字体的各个方面,旨在帮助用户打造专业且令人印象深刻的图表。从字体设置的秘籍到优化可读性的技巧,再到自定义颜色和字体样式,该专栏提供了全面的指南,涵盖了从字体显示异常的解决方案到字体选择策略的方方面面。此外,还提供了跨平台设置指南、字体性能优化策略以及可访问性方面的考虑因素,确保图表在不同环境和用户群体中都能清晰易读。通过掌握这些技巧,用户可以超越默认设置,创建个性化且具有视觉冲击力的图表,从而提升沟通效果和图表可读性。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
从停机到上线,EMC VNX5100控制器SP更换的实战演练
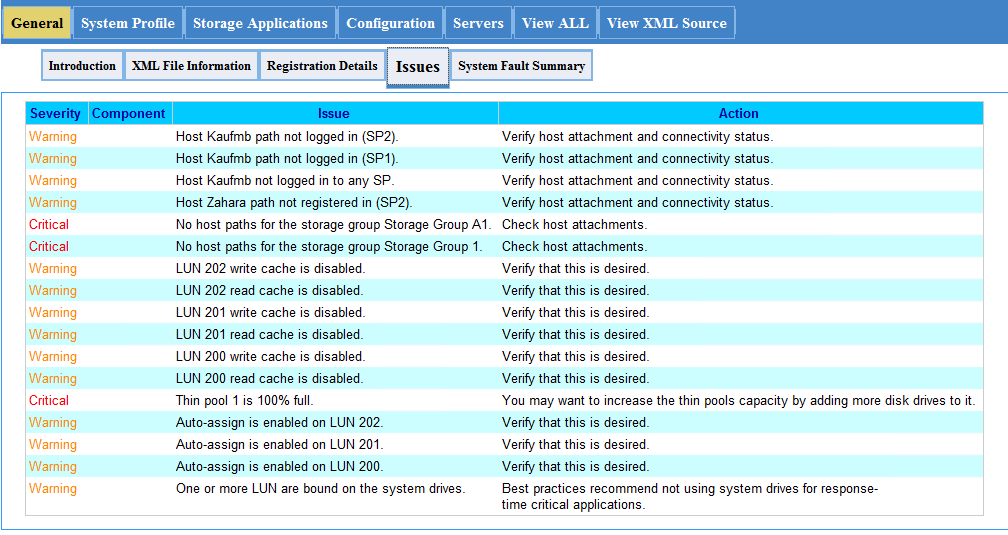
# 摘要
本文详细介绍了EMC VNX5100控制器的更换流程、故障诊断、停机保护、系统恢复以及长期监控与预防性维护策略。通过细致的准备工作、详尽的风险评估以及备份策略的制定,确保控制器更换过程的安全性与数据的完整性。文中还阐述了硬件故障诊断方法、系统停机计划的制定以及数据保护步骤。更换操作指南和系统重启初始化配置得到了详尽说明,以确保系统功能的正常恢复与性能优化。最后,文章强调了性能测试
【科大讯飞官方指南】:语音识别集成与优化的终极解决方案

# 摘要
本文综述了语音识别技术的当前发展概况,深入探讨了科大讯飞语音识别API的架构、功能及高级集成技术。文章详细分析了不同应用场景下语音识别的应用实践,包括智能家居、移动应用和企业级
彻底解决MySQL表锁问题:专家教你如何应对表锁困扰
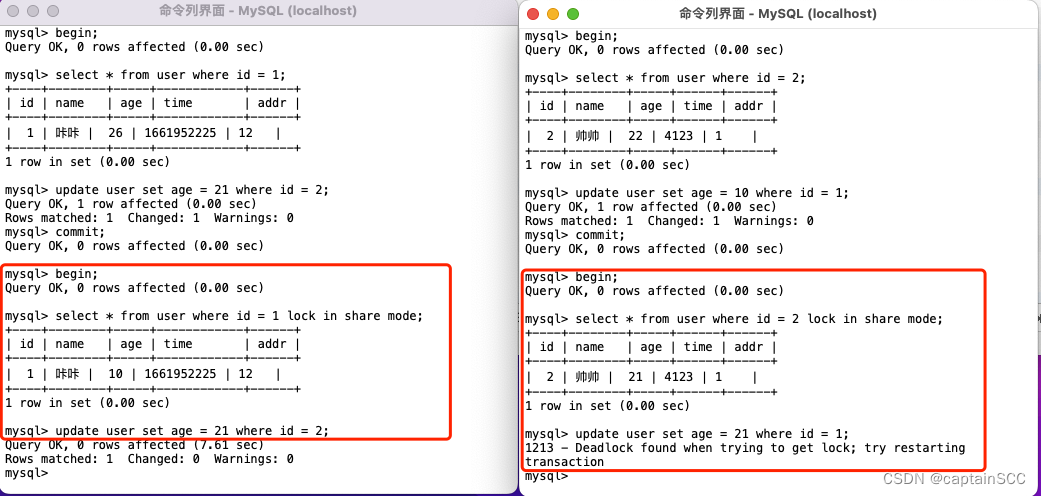
# 摘要
本文深入探讨了MySQL数据库中表锁的原理、问题及其影响。文章从基础知识开始,详细分析了表锁的定义、类型及其与行锁的区别。理论分析章节深入挖掘了表锁产生的原因,包括SQL编程习惯、数据库设计和事务处理,以及系统资源和并发控制问题。性能影响部分讨论了表锁对查询速度和事务处理的潜在负面效果。诊断与排查章节提供了表锁监控和分析工具的使用方法,以及实际监控和调试技巧。随后,本文介绍了避免和解决表锁问题
【双色球数据清洗】:掌握这3个步骤,数据准备不再是障碍
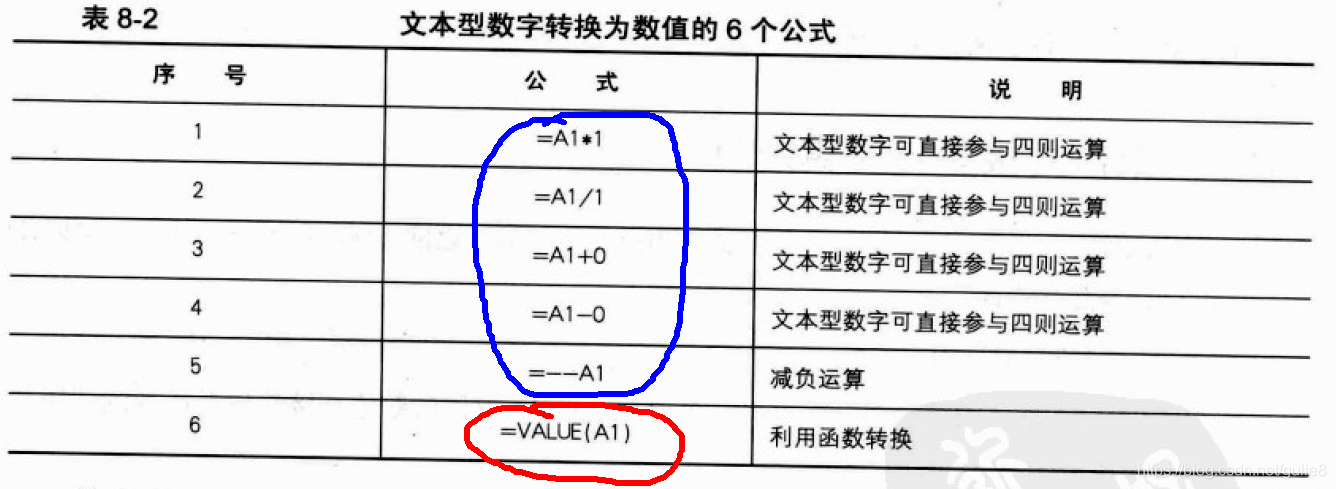
# 摘要
双色球数据清洗作为保证数据分析准确性的关键环节,涉及数据收集、预处理、实践应用及进阶技术等多方面内容。本文首先概述了双色球数据清洗的重要性,并详细解析
【SketchUp脚本编写】

# 摘要
随着三维建模需求的增长,SketchUp脚本编程因其自动化和高效性受到设计师的青睐。本文首先概述了SketchUp脚本编写的基础知识,包括脚本语言的基本概念、SketchUp API与命令操作、控制流与函数的使用。随后,深入探讨了脚本在建模自动化、材质与纹理处理、插件与扩展开发中的实际应用。文章还介绍了高级技巧,如数据交换、错误处理、性能优化
硬盘故障分析:西数硬盘检测工具在故障诊断中的应用(故障诊断的艺术与实践)

# 摘要
本文从硬盘故障的分析概述入手,系统地探讨了西数硬盘检测工具的选择、安装与配置,并深入分析了硬盘的工作原理及故障类型。在此基础上,本文详细阐述了故障诊断的理论基础和实践应用,包括常规状态检测、故障模拟与实战演练。此外,本文还提供了数据恢复与备份策略,以及硬盘故障处理的最佳实践和预防措施,旨在帮助读者全面理解和
关键参数设置大揭秘:DEH调节最佳实践与调优策略
# 摘要
本文系统地介绍了DEH调节技术的基本概念、理论基础、关键参数设置、实践应用、监测与分析工具,以及未来趋势和挑战。首先概述了DEH调节技术的含义和发展背景。随后深入探讨了DEH调节的原理、数学模型和性能指标,详细说明了DEH系统的工作机制以及控制理论在其中的应用。重点分析了DEH调节关键参数的配置、优化策略和异
【面向对象设计在软件管理中的应用】:原则与实践详解
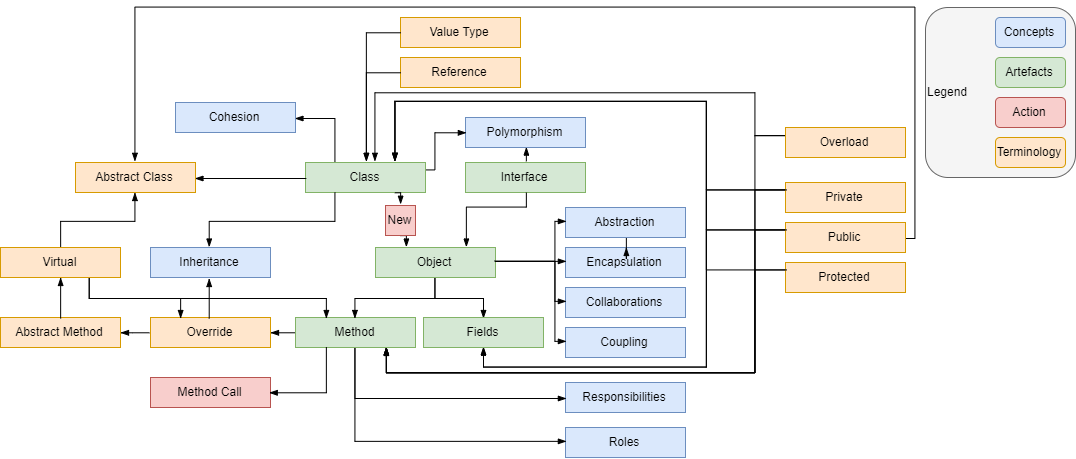
# 摘要
面向对象设计(OOD)是软件工程中的核心概念,它通过封装、继承和多态等特性,促进了代码的模块化和复用性,简化了系统维护,提高了软件质量。本文首先回顾了OOD的基本概念与原则,如单一职责原则(SRP)、开闭原则(OCP)、里氏替换原则(LSP)、依赖倒置原则(DIP)和接口隔离原则(ISP),并通过实际案例分析了这些原则的应用。接着,探讨了创建型、结构型和行为型设计模式在软件开发中的应用,以及面向对象设计
【AT32F435与AT32F437 GPIO应用】:深入理解与灵活运用

# 摘要
AT32F435/437微控制器作为一款广泛应用的高性能MCU,其GPIO(通用输入/输出端口)的功能对于嵌入式系统开发至关重要。本文旨在深入探讨GPIO的基础理论、配置方法、性能优化、实战技巧以及在特定功能中的应用,并提供故障诊断与排错的有效方法。通过详细的端口结构分析、寄存器操作指导和应用案例研究,
【sCMOS相机驱动电路信号同步处理技巧】:精确时间控制的高手方法
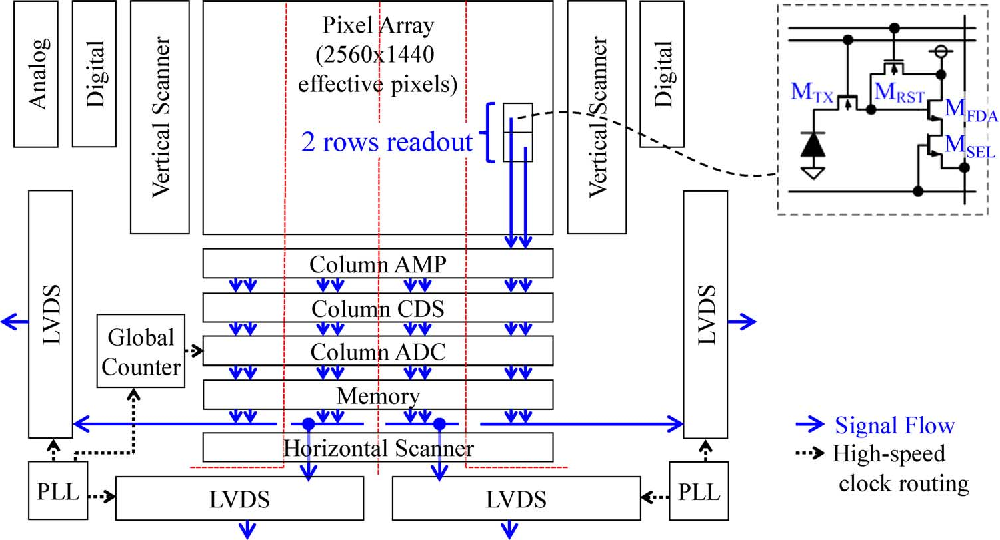
# 摘要
sCMOS相机作为高分辨率成像设备,在科学研究和工业领域中发挥着重要作用。本文首先概述了sCMOS相机驱动电路信号同步处理的基本概念与必要性,然后深入探讨了同步处理的理论基础,包括信号同步的定义、分类、精确时间控制理论以及时间延迟对信号完整性的影响。接着,文章进入技术实践部分,详细描述了驱动电路设计、同步信号生成控制以及
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )