文本预处理技术及其重要性
发布时间: 2024-03-24 05:14:13 阅读量: 105 订阅数: 21 
# 1. 导论
- 背景介绍
- 目的和意义
- 研究现状
# 2. 文本预处理概述
- **什么是文本预处理**
文本预处理是指在进行自然语言处理或文本分析之前,对文本数据进行清洗、处理和转换的过程。通过文本预处理,可以使文本数据更加规范、准确,为后续的文本分析任务提供高质量的数据支持。
- **主要内容和方法**
文本预处理的主要内容包括文本数据清洗、文本分词与词性标注、停用词过滤与特征提取等环节。在具体实施中,常用的方法包括正则表达式、分词工具库、词性标注算法等。
- **相关技术和工具**
在文本预处理中,常用的技术和工具有NLTK、Spacy、Jieba等自然语言处理工具库。这些工具提供了丰富的函数和算法,可以帮助开发者高效地完成各种文本预处理任务。
# 3. **文本数据清洗**
文本数据清洗是文本预处理过程中至关重要的一步,它包括去除噪声数据、处理缺失值以及标准化文本格式。下面我们将详细介绍文本数据清洗的具体操作和实现方法。
#### 3.1 去除噪声数据
在文本数据中,经常会包含一些无关紧要的信息,例如特殊字符、标点符号、HTML标签等,这些数据会对后续的文本处理和分析造成干扰。因此,去除噪声数据是清洗文本的第一步。
```python
import re
def remove_noise(text):
clean_text = re.sub(r'[^\w\s]', '', text) # 去除标点符号
clean_text = re.sub(r'\d+', '', clean_text) # 去除数字
clean_text = clean_text.strip() # 去除首尾空格
return clean_text
```
**代码总结:** 上述代码使用正则表达式去除文本中的标点符号和数字,并去除首尾空格,以保持文本的纯净性。
**结果说明:** 经过去除噪声数据的处理后,文本更干净、更易于分析。
#### 3.2 处理缺失值
在文本数据中,有时会存在缺失值,即某些文本内容为空或缺失。针对这种情况,我们需要进行适当的处理,以免影响文本数据的整体质量。
```python
def handle_missing_values(text):
if text is None:
text = "暂无内容"
return text
```
**代码总结:** 上述代码通过判断文本是否为空,若为空则用指定的文本内容填充,以处理缺失值情况。
**结果说明:** 处理缺失值后,文本数据更加完整和可靠。
#### 3.3 标准化文本格式
标准化文本格式是为了使文本数据的结构一致,便于后续的文本处理和分析。标准化包括统一字符大小写、处理缩写词汇等操作。
```python
def standardize_text(text):
standardized_text = text.lower() # 统一为小写
# 其他标准化操作,如处理缩写词汇
return standardized_text
```
**代码总结:** 以上代码将文本统一转换为小写形式,以保持文本数据的一致性。
**结果说明:** 标准化文本格式后,文本数据更易于进行后续的文本处理和分析操作。
# 4. 文本分词与词性标注
文本分词与词性标注是文本预处理中重要的环节,可以帮助将文本数据分割成有意义的单词,并为这些单词赋予对应的词性信息,为后续处理和分析提供基础。下面将详细介绍文本分词与词性标注相关的内容。
#### 分词技术原理
文本分词是将连续的文本序列分割成有意义的词语的过程。其原理主要基于词语的频率、上下文关系以及语言学规则,常见的算法包括正向最大匹配、逆向最大匹配和双向最大匹配等。
#### 常用分词工具和库
在Python中,常用的中文分词工具包括结巴分词(jieba)、THULAC、SnowNLP等;在Java中,有HanLP、Ansj等开源工具库可供选择。这些工具提供了高效的分词功能,并支持用户自定义词典和词性标注。
#### 词性标注的作用和意义
词性标注是在分词基础上为每个分割出的词语标注词性,如名词、动词、形容词等。词性标注有助于理解句子的结构和含义,为语义分析和文本分类等任务提供重要参考。
在实际应用中,文本分词与词性标注常常结合使用,可以提高文本处理的准确性和效率,为自然语言处理任务带来更好的结果。
# 5. **停用词过滤与特征提取**
在自然语言处理中,文本数据通常包含很多停用词,这些词对于文本分析而言并没有太大的帮助,甚至可能会干扰模型的训练和准确性。因此,在文本预处理阶段,我们需要进行停用词的过滤,并提取出有用的特征来。
#### 5.1 **停用词的定义与作用**
停用词是指在处理自然语言数据时,可以忽略不加以处理的常用词,例如“的”、“是”、“和”等。这些词在文本分析中往往出现频率很高,但却没有太多实际意义,因此需要将其过滤掉。
#### 5.2 **如何识别和过滤停用词**
在Python中,我们可以利用NLTK库提供的停用词列表,或者根据具体文本数据自定义停用词列表,然后通过简单的代码实现停用词的过滤。
```python
import nltk
from nltk.corpus import stopwords
nltk.download('stopwords')
# 加载停用词列表
stop_words = set(stopwords.words('english'))
# 文本数据
text = "This is an example sentence demonstrating stop words removal."
# 过滤停用词
filtered_text = ' '.join(word for word in text.split() if word.lower() not in stop_words)
print(filtered_text)
```
**代码说明:**
- 首先使用NLTK库加载英语停用词列表。
- 然后定义一个文本数据。
- 最后根据停用词列表过滤文本数据中的停用词。
**结果说明:**
过滤前的文本数据是:"This is an example sentence demonstrating stop words removal."
过滤后的文本数据是:"example sentence demonstrating stop words removal."
#### 5.3 **特征提取方法及其应用**
特征提取是文本预处理中非常重要的一部分,通过合适的特征提取方法,能够将文本数据转换为计算机可以理解和处理的形式,为后续的自然语言处理任务提供有用的信息。
常用的特征提取方法包括词袋模型、TF-IDF(词频-逆文档频率)等,这些方法都可以帮助我们从文本数据中提取出有用的特征信息,用于文本分类、情感分析等任务中。
通过停用词的过滤和特征提取,我们可以更加精确地理解和分析文本数据,为后续的自然语言处理任务奠定基础。
# 6. 文本预处理在自然语言处理中的应用
文本预处理在自然语言处理中发挥着至关重要的作用,能够有效提升文本处理任务的准确性和效率。下面我们将详细介绍文本预处理技术在自然语言处理领域的具体应用:
### 情感分析
情感分析是指通过对文本的分析和挖掘,识别和确定文本中所包含的情感色彩,如积极、消极、中性等,从而帮助人们更好地理解和处理大量的文本信息。文本预处理技术在情感分析中通常用于文本清洗、分词、特征提取等环节,以提高情感分析模型的准确度和鲁棒性。
```python
# 代码示例:情感分析中的文本预处理
import nltk
from nltk.sentiment.vader import SentimentIntensityAnalyzer
# 示例文本
text = "The movie was amazing and I loved it!"
# 文本分词
tokens = nltk.word_tokenize(text)
# 情感分析
sid = SentimentIntensityAnalyzer()
score = sid.polarity_scores(text)
print(tokens)
print("情感分析得分:", score['compound'])
```
**代码总结:** 以上代码使用NLTK库进行文本分词,并利用VADER情感分析器对文本进行情感分析,输出文本的情感分析得分。
**结果说明:** 经过文本预处理后,对示例文本进行情感分析得分为正值,表明文本传达了积极情感。
### 文本分类
文本分类是自然语言处理中重要的任务之一,其目的是将文本数据划分到预定义的类别中。在文本分类任务中,文本预处理技术可以帮助降低特征维度、过滤噪声数据、提取有效特征等,从而提升分类算法的准确性和泛化能力。
```python
# 代码示例:文本分类中的文本预处理
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import train_test_split
# 示例文本数据
texts = ["I love coding in Python",
"Java programming is interesting",
"Machine learning is cool"]
# 目标类别
labels = [1, 0, 1]
# 文本特征提取与分类
model = make_pipeline(TfidfVectorizer(), MultinomialNB())
model.fit(texts, labels)
# 预测示例文本类别
test_text = "Python is versatile"
predicted_label = model.predict([test_text])
print("预测结果:", predicted_label)
```
**代码总结:** 以上代码使用TF-IDF向量化文本特征,结合朴素贝叶斯分类器进行文本分类,并对示例文本进行分类预测。
**结果说明:** 经过文本预处理和分类模型训练后,对示例文本进行分类预测为类别1,即积极情感。
### 实体识别
实体识别是指从文本中识别出命名实体(如人名、地名、组织机构名等)的任务。文本预处理在实体识别中扮演着重要角色,可以提升实体识别模型对文本的理解和识别能力。
```python
# 代码示例:实体识别中的文本预处理
from nltk import ne_chunk, pos_tag, word_tokenize
from nltk.tree import Tree
# 示例文本
text = "Apple is located in Cupertino, California."
# 词性标注
tokens = pos_tag(word_tokenize(text))
# 实体识别
tree = ne_chunk(tokens)
# 提取命名实体
for subtree in tree:
if isinstance(subtree, Tree):
entity = " ".join([word for word, tag in subtree.leaves()])
print("命名实体:", entity)
```
**代码总结:** 以上代码使用NLTK库进行词性标注和命名实体识别,从示例文本中提取出命名实体。
**结果说明:** 经过文本预处理和实体识别后,成功提取出文本中的命名实体“Apple”、“Cupertino, California”。
### 信息检索
信息检索是自然语言处理领域的重要应用之一,其目的是从大规模文本数据中找到相关的信息。文本预处理在信息检索中可以帮助提取关键词、降低噪声干扰、优化检索效率等,提升信息检索系统的性能。
```python
# 代码示例:信息检索中的文本预处理
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.metrics.pairwise import cosine_similarity
# 示例文本数据
corpus = [
"Machine learning is the future of technology",
"Python programming is widely used in data analysis",
"Natural language processing helps understand human language"
]
# 文本向量化
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
# 计算文本相似度
similarities = cosine_similarity(X)
print("文本相似度矩阵:")
print(similarities)
```
**代码总结:** 以上代码使用词袋模型将文本向量化,并计算文本之间的余弦相似度,输出文本相似度矩阵。
**结果说明:** 经过文本预处理和文本向量化后,成功计算出示例文本之间的相似度矩阵。
通过以上示例,我们可以看到文本预处理在自然语言处理中的广泛应用,为构建高效、准确的文本处理系统提供了重要支持。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏名为NLP-文本理解与推理,涵盖了广泛的自然语言处理主题。从“自然语言处理入门指南”到“情感分析的基本概念与方法”,再到“支持向量机在文本分类中的应用”和“BERT模型原理与实践”,本专栏系统性地介绍了现代NLP工具与技术。读者将深入了解文本预处理技术、词袋模型、Word2Vec算法、神经网络如RNN和LSTM,以及注意力机制、Transformer等技术在NLP中的重要应用。此外,还探讨了序列到序列模型和文本生成技术。无论是对NLP初学者还是专业人士来说,这个专栏将为他们提供全面而深入的知识体系,帮助他们更好地理解和应用文本处理技术。
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【深度学习在卫星数据对比中的应用】:HY-2与Jason-2数据处理的未来展望

# 1. 深度学习与卫星数据对比概述
## 深度学习技术的兴起
随着人工智能领域的快速发展,深度学习技术以其强大的特征学习能力,在各个领域中展现出了革命性的应用前景。在卫星数据处理领域,深度学习不仅可以自动
面向对象编程:继承机制的终极解读,如何高效运用继承提升代码质量

# 1. 面向对象编程中的继承机制
面向对象编程(OOP)是一种编程范式,它使用“对象”来设计软件。这些对象可以包含数据,以字段(通常称为属性或变量)的形式表示,以及代码,以方法的形式表示。继承机制是OOP的核心概念之一,它允许新创建的对象继承现有对象的特性。
## 1.1 继承的概念
继承是面向对象编程中的一个机制,允许一个类(子类)继承另一个类(父类)的属性和方法。通过继承
拷贝构造函数的陷阱:防止错误的浅拷贝
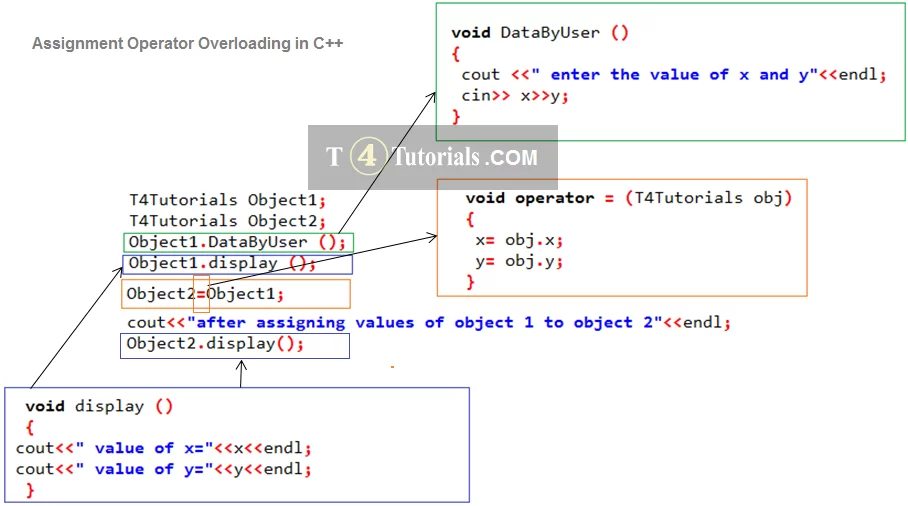
# 1. 拷贝构造函数概念解析
在C++编程中,拷贝构造函数是一种特殊的构造函数,用于创建一个新对象作为现有对象的副本。它以相同类类型的单一引用参数为参数,通常用于函数参数传递和返回值场景。拷贝构造函数的基本定义形式如下:
```cpp
class ClassName {
public:
ClassName(const ClassName& other); // 拷贝构造函数
【MATLAB在Pixhawk定位系统中的应用】:从GPS数据到精确定位的高级分析

# 1. Pixhawk定位系统概览
Pixhawk作为一款广泛应用于无人机及无人车辆的开源飞控系统,它在提供稳定飞行控制的同时,也支持一系列高精度的定位服务。本章节首先简要介绍Pixhawk的基本架构和功能,然后着重讲解其定位系统的组成,包括GPS模块、惯性测量单元(IMU)、磁力计、以及_barometer_等传感器如何协同工作,实现对飞行器位置的精确测量。
我们还将概述定位技术的发展历程,包括
MATLAB时域分析:模型预测控制,基于模型的优化策略
# 1. MATLAB时域分析概述
MATLAB,作为一款高性能的数值计算和可视化软件,广泛应用于工程计算、控制设计、信号处理、图像分析
【用户体验设计】:创建易于理解的Java API文档指南
# 1. Java API文档的重要性与作用
## 1.1 API文档的定义及其在开发中的角色
Java API文档是软件开发生命周期中的核心部分,它详细记录了类库、接口、方法、属性等元素的用途、行为和使用方式。文档作为开发者之间的“沟通桥梁”,确保了代码的可维护性和可重用性。
## 1.2 文档对于提高代码质量的重要性
良好的文档
Python讯飞星火LLM数据增强术:轻松提升数据质量的3大法宝
# 1. 数据增强技术概述
数据增强技术是机器学习和深度学习领域的一个重要分支,它通过创造新的训练样本或改变现有样本的方式来提升模型的泛化能力和鲁棒性。数据增强不仅可以解决数据量不足的问题,还能通过对数据施加各种变化,增强模型对变化的适应性,最终提高模型在现实世界中的表现。在接下来的章节中,我们将深入探讨数据增强的基础理论、技术分类、工具应用以及高级应用,最后展望数据增强技术的
消息队列在SSM论坛的应用:深度实践与案例分析

# 1. 消息队列技术概述
消息队列技术是现代软件架构中广泛使用的组件,它允许应用程序的不同部分以异步方式通信,从而提高系统的可扩展性和弹性。本章节将对消息队列的基本概念进行介绍,并探讨其核心工作原理。此外,我们会概述消息队列的不同类型和它们的主要特性,以及它们在不同业务场景中的应用。最后,将简要提及消息队列
【大数据处理利器】:MySQL分区表使用技巧与实践
# 1. MySQL分区表概述与优势
## 1.1 MySQL分区表简介
MySQL分区表是一种优化存储和管理大型数据集的技术,它允许将表的不同行存储在不同的物理分区中。这不仅可以提高查询性能,还能更有效地管理数据和提升数据库维护的便捷性。
## 1.2 分区表的主要优势
分区表的优势主要体现在以下几个方面:
- **查询性能提升**:通过分区,可以减少查询时需要扫描的数据量
【集成学习提高目标检测】:在YOLO抽烟数据集上提升识别准确率的方法

# 1. 目标检测与YOLO算法简介
目标检测是计算机视觉中的核心任务,它旨在识别和定位图像中的所有感兴趣对象。对于目标检测来说,准确快速地确定物体的位置和类别至关重要。YOLO(You Only Look Once)算法是一种流行的端到端目标检测算法,以其速度和准确性在多个领域得到广泛应用。
## YOLO算法简介
YOLO算法将目标检测问题转化为一个单一的回归
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )