bs4与其他Python库的集成:requests和lxml的高效结合
发布时间: 2024-10-14 20:21:10 阅读量: 2 订阅数: 6 
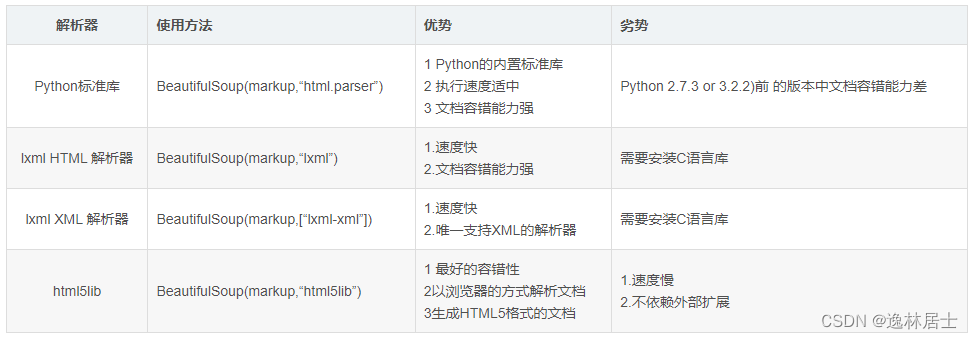
# 1. bs4库的基本使用和功能概述
Python的BeautifulSoup库,简称bs4,是一个强大的库,用于解析HTML和XML文档。它提供简单的方法来导航、搜索和修改解析树。这使得它在数据抓取和文本分析等任务中非常有用。在本章中,我们将介绍bs4库的基本概念,包括它的安装、基本使用方法以及如何与Python其他库协同工作。
## 1.1 安装bs4库
首先,我们需要安装bs4库,它可以通过pip包管理器轻松安装。打开命令行工具,输入以下命令:
```shell
pip install beautifulsoup4
```
此命令将从Python包索引(PyPI)下载并安装最新版本的bs4及其依赖。
## 1.2 解析HTML/XML文档
一旦安装完成,我们可以开始解析HTML或XML文档。以下是一个简单的例子,展示如何使用bs4来解析HTML文档:
```python
from bs4 import BeautifulSoup
# 假设我们有一个简单的HTML文档
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="***" class="sister" id="link1">Elsie</a>,
<a href="***" class="sister" id="link2">Lacie</a> and
<a href="***" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
# 创建BeautifulSoup对象
soup = BeautifulSoup(html_doc, 'html.parser')
# 访问文档的title标签
print(soup.title)
```
在上面的代码中,我们首先导入了BeautifulSoup类,并创建了一个实例来解析我们的HTML文档。我们可以通过标签名称访问特定元素,并打印出它的内容。
## 1.3 生成HTML/XML文档
除了解析文档,bs4还可以用来生成新的HTML或XML文档。下面是一个示例,展示了如何创建一个简单的HTML文档:
```python
from bs4 import BeautifulSoup
# 创建一个BeautifulSoup对象
soup = BeautifulSoup()
# 添加一个基础HTML结构
soup.append("<p>这是一个段落。</p>")
soup.append("<p>这是另一个段落。</p>")
# 输出生成的HTML文档
print(soup.prettify())
```
在这段代码中,我们没有预先提供HTML文档,而是让BeautifulSoup自己创建了一个新的HTML结构,然后添加了两个段落元素。最后,我们使用`prettify()`方法输出格式化的HTML文档。
通过本章的学习,我们将掌握bs4库的基本使用方法,为进一步学习其高级功能打下坚实的基础。
# 2. requests库的深入理解和实践
requests库是Python中最流行的HTTP库之一,它提供了一种简单而直接的方式来处理HTTP请求。它的设计灵感来源于Python标准库urllib,但它更加人性化和易用。在本章节中,我们将深入探讨requests库的基本使用和高级功能,并介绍如何处理错误和记录日志。
## 2.1 requests库的基本使用
### 2.1.1 发起基本的HTTP请求
requests库的基本使用非常直观,我们可以通过简单的函数调用来发起各种HTTP请求。以下是发起GET请求的一个基本示例:
```python
import requests
url = '***'
response = requests.get(url)
print(response.text)
```
在这个示例中,我们首先导入了requests模块,然后定义了我们想要请求的URL。使用`requests.get()`函数发起一个GET请求,并将返回的响应对象存储在`response`变量中。最后,我们打印出了响应的文本内容。
### 2.1.2 请求头和请求参数的设置
除了基本的GET请求,我们还可以设置请求头和请求参数。以下是如何设置请求头和请求参数的示例:
```python
import requests
url = '***'
headers = {'User-Agent': 'Mozilla/5.0'}
params = {'key1': 'value1', 'key2': 'value2'}
response = requests.get(url, headers=headers, params=params)
print(response.text)
```
在这个示例中,我们通过`headers`参数传递了一个字典来设置请求头,通过`params`参数传递了一个字典来设置请求参数。这样,我们就可以在不改变URL结构的情况下,向服务器传递额外的信息。
#### 代码逻辑分析
在上面的代码中,我们使用了`requests.get()`函数来发送GET请求。函数的第一个参数是目标URL,第二个参数是可选的headers字典,用于设置HTTP请求头。第三个参数是params字典,用于添加URL查询字符串参数。
- `headers`参数允许我们模拟不同的浏览器或设备,这对于那些检查请求头来提供内容或服务的服务器非常有用。
- `params`参数用于将字典转换为URL的查询字符串,并添加到URL中。
### 2.2 requests库的高级功能
#### 2.2.1 会话维持和cookie处理
requests库提供了一个`Session`对象,它允许我们跨请求保持某些参数,比如cookies和headers。这对于处理需要登录认证的网站特别有用。
```python
import requests
# 创建一个Session对象
session = requests.Session()
# 发起登录请求
session.post('***', data={'username': 'user', 'password': 'pass'})
# 发起另一个请求,此时会自动携带登录后的cookies
response = session.get('***')
print(response.json())
```
在这个示例中,我们首先创建了一个Session对象,并使用它来发送一个POST请求进行登录。登录成功后,我们再次使用同一个Session对象发送一个GET请求,此时Session对象会自动携带之前登录请求中服务器设置的cookies。
#### 代码逻辑分析
在上面的代码中,我们首先创建了一个`Session`对象,然后使用`Session`对象的`post()`方法发送了一个POST请求进行登录。在这个请求中,我们将用户名和密码作为数据提交。接着,我们使用同一个`Session`对象的`get()`方法发送了一个GET请求。由于我们使用的是同一个`Session`对象,它会自动携带之前POST请求中服务器设置的cookies。
#### 2.2.2 异步请求和流式下载
requests库支持异步请求和流式下载,这可以显著提高处理大型文件或大量请求时的效率。
```python
import requests
from requests.adapters import HTTPAdapter
from requests.packages.urllib3.util.retry import Retry
# 创建一个Session对象,并设置重试策略
session = requests.Session()
retry = Retry(connect=3, backoff_factor=0.5)
adapter = HTTPAdapter(max_retries=retry)
session.mount('***', adapter)
session.mount('***', adapter)
# 发起异步请求
def fetch_url(url):
with session.get(url, stream=True) as response:
for chunk in response.iter_content(chunk_size=1024):
if chunk: # 过滤掉保持连接的chunk
process_chunk(chunk)
def process_chunk(chunk):
# 处理下载的内容块
pass
url = '***'
fetch_url(url)
```
在这个示例中,我们首先创建了一个Session对象,并设置了一个重试策略,这样如果请求失败,它会自动重试。然后我们定义了一个异步请求的函数`fetch_url`,它使用Session对象的`get()`方法以流式方式下载内容。在`process_chunk`函数中,我们可以处理每个内容块。
#### 代码逻辑分析
在上面的代码中,我们首先创建了一个`Session`对象,并配置了一个重试策略,这样如果请求失败,它会自动重试。然后我们定义了一个异步请求的函数`fetch_url`,它使用`Session`对象的`get()`方法以流式方式下载内容。在`process_chunk`函数中,我们可以处理每个内容块。
### 2.3 requests库的错误处理和日志记录
#### 2.3.1 错误处理机制
requests库提供了内置的错误处理机制,我们可以捕获特定的异常来处理HTTP请求中可能出现的错误。
```python
import requests
url = '***'
try:
response = requests.get(url)
response.raise_for_status() # 如果响应状态码不是2xx,将抛出异常
except requests.exceptions.HTTPError as errh:
print ("Http Error:",errh)
except requests.exceptions.ConnectionError as errc:
print ("Error Connecting:",errc)
except requests.exceptions.Timeout as errt:
print ("Timeout Error:",errt)
except requests.exceptions.Reques
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python bs4 库,旨在提升数据抓取和解析的效率。专栏涵盖了 14 个标题,包括实用指南、实战技巧、案例分析、性能优化、安全指南、框架集成、机器学习应用、项目管理、CSS 选择器、移动端数据抓取和学习曲线。通过这些文章,读者将掌握 bs4 库的各个方面,包括 HTML 数据处理、表格解析、嵌套元素处理、数据可视化、性能优化、安全措施、Scrapy 集成、机器学习预处理、代码复用、CSS 选择器、移动端数据抓取和学习策略。本专栏旨在帮助数据分析师、爬虫开发者和机器学习从业者充分利用 bs4 库,提升其数据处理和分析能力。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
PycURL与REST API构建:构建和调用RESTful服务的实践指南

# 1. PycURL简介与安装
## PycURL简介
PycURL是一款强大的Python库,它是libcurl的Python接口,允许开发者通过Python代码发送网络请求。与标准的urllib库相比,PycURL在性能上有着显著的优势
Werkzeug.exceptions库的异常监控:实时监控异常的发生和处理的秘诀
# 1. Werkzeug.exceptions库概述
在现代Web开发中,异常处理是保障应用稳定性和用户体验的关键环节。Werkzeug库提供了一个强大的异常处理模块,它为Python的WSGI标准提供了丰富的异常处理工具。Werkzeug.exceptions库不仅支持标准的异常类型,还允许开发者自定义异常,使得错误处理更加灵活和强
Twisted.web.http与WebSocket:实现实时通信的关键技术

# 1. Twisted.web.http与WebSocket的基本概念
## 1.1 Twisted.web.http与WebSocket的定义和应用场景
Twisted.web.http是一个基于Python的事件驱动网络框架Twisted的组件,用于构建HTTP服务器。它支持HTTP/1.0和HTTP/1.1协议,允许开发者以异步方式处理HTTP请求,适合于
Django multipartparser的缓存策略:提高响应速度与减少资源消耗的6大方法

# 1. Django multipartparser简介
## Django multipartparser的概念
Django作为一个强大的Python Web框架,为开发者提供了一系列工具来处理表单数据。其中,`multipa
Numpy.linalg在量子计算中的应用:量子态的表示与操作
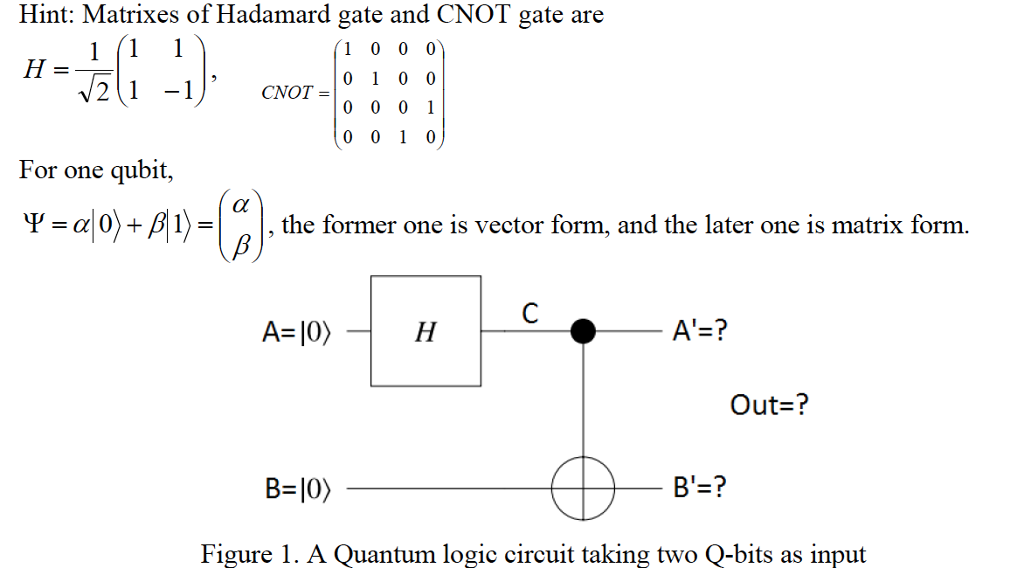
# 1. 量子计算基础与Numpy简介
## 1.1 量子计算简介
量子计算是基于量子力学原理的计算方式,与传统的经典计算有着根本的不同。在经典计算中,信息以二进制的形式存储和处理,即每一位数据只能表示为0或1。而在量子计算中,信息是通过量子比特(qubit)来表达的,一个量子比特可以同时表示0和1的叠加状态,这种特性被称为
Twisted.web.client的SSL_TLS支持:安全处理HTTPS连接的必知技巧
# 1. Twisted.web.client与SSL_TLS基础
在本章中,我们将首先介绍Twisted.web.client库的基础知识,以及SSL和TLS协议的基本概念。Twisted是一个事件驱动的Python网络框架,它提供了一个强大的异步HTTP客户端接口,而SSL/TLS是网络安全通信中不可或缺的加密协议,它们共同确保了数据传输的安全性和完整性。
##
【Django admin自定义视图】:扩展功能,创建专属视图的高级教程
# 1. Django admin自定义视图基础
## Django admin自定义视图概述
Django admin是Django框架提供的一个强大的后台管理系统,它默认提供了很多方便的功能,如数据的增删改查等。然而,有时候我们需要根据自己的需求对admin进行一些定制化的修改,这就需要用到自定义视图的概念。自定义视图不仅可以提高我们
【意大利本地化处理】:django.contrib.localflavor.it.util模块的字符串处理与货币格式化详解

# 1. 意大利本地化处理概述
## 1.1 意大利本地化的必要性
在全球化的今天,本地化处理是IT行业中不可或缺的一环。对于意大利这样一个拥有独特文化和语言的国家,本地化处理尤为重要。它不仅涉及到语言的翻译,还包括货币、日期、地址等格式的本地特定处理。
## 1.2 意大利本地化处理的关键要
【WebOb与WSGI标准】:打造Python Web应用的5大基石
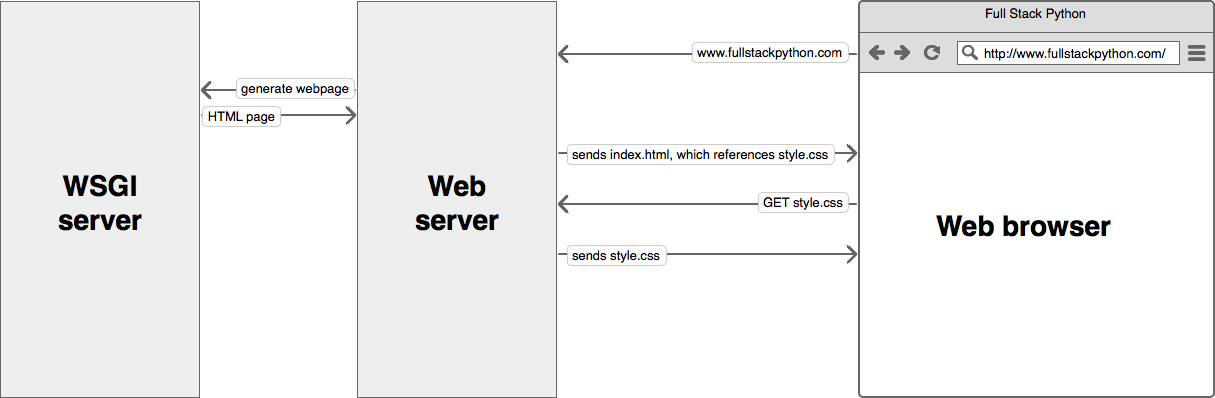
# 1. WebOb与WSGI标准概述
## WebOb与WSGI标准的起源
WebOb和WSGI是Python Web开发中两个核心的概念。WebOb是一个库,用于创建和操作HTTP消息,提供了对Web请求和响应的封装,使得开发者能够以更贴近HTTP协议的方式处理Web交互。WSGI(Web Server Gateway Interface)则是一个规范,定义了Web服
Zope Component与测试驱动开发(TDD):编写可测试组件代码的10大技巧

# 1. Zope Component基础和测试驱动开发(TDD)简介
## 1.1 Zope Component基础
Zope Component(简称ZC)是一种用于构建Python应用程序的组件架构,它提供了一种灵活的方式来组装和重用代码。ZC的核心是基于接口的编程,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )