集成的艺术:JPA_Hibernate与CollectionUtils的完美结合
发布时间: 2024-09-27 08:35:50 阅读量: 87 订阅数: 36 

Jpa_Basic:Jpa_Basic Inflearn Pracitce
# 1. JPA、Hibernate与CollectionUtils的简介
## 1.1 JPA、Hibernate与CollectionUtils的背景
Java持久化API(JPA)和Hibernate是Java开发者最常使用的技术之一。JPA是一个提供了操作持久化数据的标准化接口,而Hibernate则是JPA的一个实现。两者都是处理数据库操作的ORM框架,可以将对象和关系数据库中的表进行映射。Hibernate在JPA出现之前就已经存在,并且在JPA规范中占据了重要地位,很多JPA规范的实现都借鉴了Hibernate的设计思想。
## 1.2 JPA与Hibernate的集成
JPA与Hibernate的集成是一个复杂但非常实用的过程。开发者通过JPA规范可以对Hibernate进行操作,同时也可以利用Hibernate的扩展功能优化项目的性能。本章将深入介绍两者之间的关系、数据持久化基础以及集成的理论基础。
## 1.3 CollectionUtils的应用和优势
CollectionUtils是Apache Commons库中的一个工具类,它提供了很多实用的集合操作功能,如集合的合并、过滤等。在集成JPA/Hibernate的过程中,使用CollectionUtils可以极大地简化集合操作,提高开发效率。了解其核心功能和在Java集合框架中的应用将为后续的集成实践打下良好的基础。
本章的目的是让读者对JPA、Hibernate和CollectionUtils有一个初步的认识,并为后续章节中更深入的集成技术打下基础。
# 2. JPA与Hibernate的集成基础
## 2.1 JPA和Hibernate的关系
### 2.1.1 JPA规范和Hibernate实现
Java Persistence API (JPA) 是Java EE平台的标准部分,它提供了一种机制,允许开发者通过对象关系映射技术(ORM)将Java对象映射到关系型数据库中。JPA定义了一套标准,即开发者可以使用通用的API来操作持久化数据,而无需关心底层数据库的具体细节。这种抽象层的设计理念极大地提高了Java开发者的开发效率,因为它们可以编写数据库独立的代码。
Hibernate是一个成熟的开源ORM框架,它实现了JPA规范。Hibernate支持多种数据库操作,允许开发者以一种面向对象的方式来管理数据库。Hibernate不仅可以使用JPA规范进行编程,还可以提供一些额外的特性,比如HQL(Hibernate Query Language),这是一个类似于SQL但面向对象查询语言的查询工具。
从历史发展来看,Hibernate走在了JPA之前,它在很多地方推动了JPA规范的制定。在实际应用中,许多开发者选择Hibernate作为他们项目的主要ORM解决方案,即便他们使用的是JPA标准。尽管如此,Hibernate并不是JPA的唯一实现,其他实现还包括OpenJPA、EclipseLink等。
配置Hibernate来实现JPA规范是比较直接的,开发者需要在项目中添加JPA提供的API依赖,并配置持久化单元(persistence.xml)。然后,通过EntityManagerFactory和EntityManager接口来管理实体和执行持久化操作。
### 2.1.2 配置和环境搭建
要配置一个基于JPA和Hibernate集成的Java应用程序,首先需要添加必要的依赖到项目的构建配置文件中。例如,如果你使用Maven作为构建工具,可以在pom.xml中添加如下依赖:
```xml
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-entitymanager</artifactId>
<version>5.x.x</version> <!-- 替换为实际的版本号 -->
</dependency>
<dependency>
<groupId>javax.persistence</groupId>
<artifactId>javax.persistence-api</artifactId>
<version>2.x.x</version> <!-- 替换为实际的版本号 -->
</dependency>
```
接下来,需要创建一个持久化单元配置文件(persistence.xml),这个文件放在项目的META-INF目录下。在这个文件中,需要配置数据源、实体类的包路径以及其他持久化相关的参数。以下是一个基本的persistence.xml配置示例:
```xml
<?xml version="1.0" encoding="UTF-8"?>
<persistence xmlns="***"
xmlns:xsi="***"
xsi:schemaLocation="***
***"
version="2.0">
<persistence-unit name="example_pu" transaction-type="RESOURCE_LOCAL">
<provider>org.hibernate.jpa.HibernatePersistenceProvider</provider>
<class>com.example.model.MyEntity</class>
<properties>
<property name="javax.persistence.jdbc.driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="javax.persistence.jdbc.url" value="jdbc:mysql://localhost:3306/mydatabase"/>
<property name="javax.persistence.jdbc.user" value="username"/>
<property name="javax.persistence.jdbc.password" value="password"/>
<property name="hibernate.dialect" value="org.hibernate.dialect.MySQLDialect"/>
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<!-- 其他Hibernate特定配置 -->
</properties>
</persistence-unit>
</persistence>
```
通过这个配置文件,应用程序可以连接到数据库,并且能够识别和管理定义在`<class>`标签中的实体类。配置文件中的`<properties>`标签包含了Hibernate的一些配置选项,这些选项将控制如何与数据库进行交互,例如数据库方言、是否打印SQL语句等。
配置完成后,开发者可以通过JPA提供的API来进行实体的持久化操作。例如,创建一个EntityManagerFactory实例,然后通过它来创建EntityManager,用于执行实体的CRUD操作。
```java
EntityManagerFactory emf = Persistence.createEntityManagerFactory("example_pu");
EntityManager em = emf.createEntityManager();
// 使用EntityManager执行持久化操作...
```
以上部分为JPA和Hibernate集成的环境搭建概述。在实际项目中,开发者还需要根据具体需求进行更详细的配置,比如设置事务管理、连接池等。这些配置将有助于确保应用程序的性能和稳定性。
## 2.2 数据持久化基础
### 2.2.1 实体和实体管理器
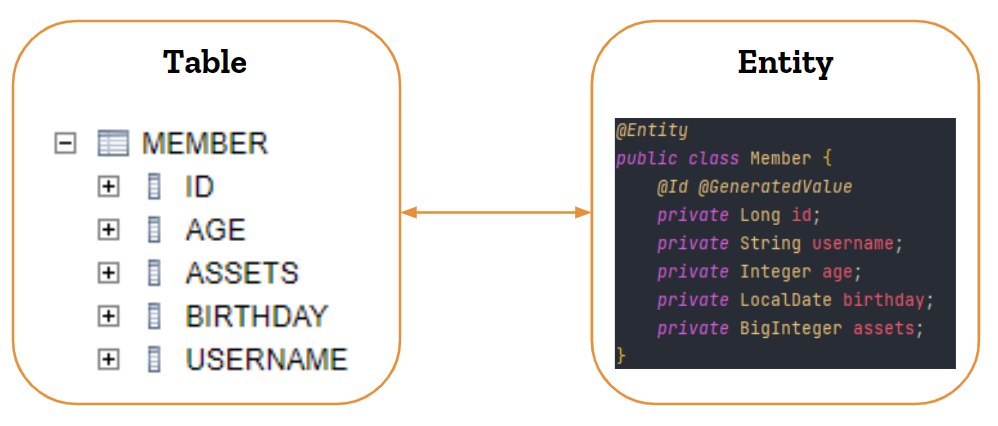
在JPA中,实体(Entity)是映射到数据库表的Java类。每个实体都对应于数据库中的一个表,实体的属性映射到表的列。为了让JPA知道哪些类应该被视为实体,需要在类定义上使用@Entity注解。实体通常还包含一个主键字段,用于唯一标识数据库中的行。为了标识主键字段,需要使用@Id注解。
下面是一个简单的实体类示例:
```java
import javax.persistence.*;
@Entity
@Table(name = "users")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false, unique = true)
private String username;
@Column(nullable = false)
private String password;
// Getters and setters
}
```
在这个例子中,`User`类是一个实体,它映射到名为`users`的数据库表。`id`字段是一个主键,并使用`GenerationType.IDENTITY`策略来自动增长。
要管理这些实体的数据持久化,需要使用实体管理器(EntityManager)。EntityManager是JPA中非常核心的一个接口,提供了创建、查找、更新和删除实体等功能。在应用程序中,通常通过EntityManagerFactory来获取EntityManager实例。EntityManagerFactory是在应用启动时配置好的,负责管理一系列EntityManager。
```java
EntityManager entityManager = entityManagerFactory.createEntityManager();
```
### 2.2.2 CRUD操作和事务管理
CRUD操作是基本的数据操作,代表创建(Create)、读取(Read)、更新(Update)、删除(Delete)。在JPA中,可以通过EntityManager执行这些操作。
创建一个新的实体并将其保存到数据库的代码如下:
```java
User newUser = new User();
newUser.setUsername("newuser");
newUser.setPassword("password");
entityManager.getTransaction().begin();
entityManager.persist(newUser); // persist方法表示保存实体
entityManager.getTransaction().commit();
```
读取数据通常是通过查询来完成的。在JPA中,可以使用EntityManager的find()方法或者JPQL(Java Persistence Query Language)来读取实体。例如,读取一个用户实体:
```java
User foundUser = entityManager.find(User.class, 1L);
```
更新实体时,只需要修改实体对象的属性值,并使用flush()方法确保更改被写入数据库:
```java
foundUser.setPassword("newpassword");
entityManager.getTransaction().begin();
entityManager.flush();
entityManager.getTransaction().commit();
```
删除实体时,首先需要通过find()方法获取实体的引用,然后调用remove()方法:
```java
entityManager.getTransaction().begin();
entityManager.remove(foundUser);
entityManager.getTransaction().commit();
```
事务管理确保了数据库操作的原子性、一致性、隔离性和持久性(ACID属性)。在JPA中,可以通过获取EntityManager时开启的Transaction对象来管理事务。默认情况下,如果没有显式开启事务,则对数据库的更改不会立即持久化。
在实际的应用程序中,开发者需要根据业务逻辑手动管理事务的边界。例如,上面创建、更新和删除实体的操作中,我们手动开启了事务,并在操作完成后提交了事务。这是一种显式事务管理,适用于需要精细控制事务边界的场景。
除了显式事务管理,JPA还支持声明式事务管理,这通常是通过在方法上使用@Transactional注解来实现的。使用这种注解,可以简化事务的管理,让容器或框架在方法调用前后自动开启和提交事务。
以上章节展示了JPA中实体和实体管理器的基础知识,以及CRUD操作和事务管理的基本用法。在日常的开发实践中,开发者需要深入理解和掌握这些基本概念和操作,以便高效地使用JPA进行数据持久化。
## 2.3 集成的理论基础
### 2.3.1 集成的技术要点
JPA与Hibernate集成时,有几个关键的技术点需要开发者重点关注:
- **依赖管理**:Hibernate作为JPA的实现,需要添加对应的依赖到项目中。通常情况下,除了Hibernate的依赖,还需要JPA规范的依赖(如javax.persistence-api),以及用于数据库连接的数据源和驱动程序的依赖。
- **持久化单元配置**:在JPA规范中,通过persistence.xml文件定义持久化单元,而Hibernate需要相应的配置来适配JPA。这包括指定实体类的包路径、数据库连接信息、Hibernate特有配置等。
- **实体映射**:使用@Entity、@Table、@Column等注解映射实体类到数据库表。这些注解与JPA规范保持一致,但Hibernate提供了额外的注解(如@Formula)来进行更复杂的映射操作。
- **API使用**:Hibernate实现的EntityManager和Session API是集成的关键,开发者需要熟悉如何使用这些API来执行查询、事务管理等操作。
- **性能优化**:JPA与Hibernate集成时,需要考虑查询优化、缓存使用等性能相关的配置。Hibernate提供了大量的性能优化选项,如二级缓存、查询缓存等。
在进行集成时,开发者需要处理这些要点,确保JPA和Hibernate能够协同工作,而不会引起配置冲突或性能问题。通常,最好的做法是遵循最佳实践,如使用Hibernate特定的注解来扩展JPA功能,同时遵循JPA规范以保持代码的可移植性。
### 2.3.2 集成的潜在好处
将JPA与Hibernate集成可以带来许多潜在好处:
- **可维护性提升**:通过遵循JPA规范,开发者可以编写数据库独立的代码,这使得应用程序更加易于维护。当需要更换数据库时,仅需更改配置即可,而无需修改大量的数据库操作代码。
- **灵活性增强**:Hibernate作为JPA的实现,提供了大量的扩展功能,比如HQL语言、延迟加载、缓存机制等。这些功能使得开发者在处理复杂业务逻辑时拥有更大的灵活性。
- **性能优化**:Hibernate在性能方面进行了大量优化,包括对SQL语句的优化、二级缓存等。在集成JPA和Hibernate之后,开发者可

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Spring 框架中强大的 CollectionUtils 工具类,提供了全面的指南,帮助开发者充分利用其功能。从基本用法到高级特性,专栏涵盖了各种主题,包括集合操作的优化技巧、源码分析、性能调优、与其他工具的比较以及在各种场景中的应用。通过深入了解 CollectionUtils,开发者可以提高代码质量、提升集合处理效率,并充分利用 Spring 框架的强大功能。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【面试杀手锏】:清华数据结构题,提炼面试必杀技

# 摘要
本文系统地探讨了数据结构在软件工程面试中的重要性和应用技巧。首先介绍了数据结构的理论基础及其在面试中的关键性,然后深入分析了线性结构、树结构和图论算法的具体概念、特点及其在解决实际问题中的应用。文章详细阐述了各种排序和搜索算法的原理、优化策略,并提供了解题技巧。最
WMS系统集成:ERP和CRM协同工作的智慧(无缝对接,高效整合)

# 摘要
随着信息技术的发展,企业资源规划(ERP)和客户关系管理(CRM)系统的集成变得日益重要。本文首先概述了ERP系统与仓库管理系统(WMS)的集成,并分析了CRM系统与WMS集成的协同工作原理。接着,详细探讨了ERP与CRM系统集成的技术实现,包括集成方案设计、技术挑战
HiGale数据压缩秘籍:如何节省存储成本并提高效率
# 摘要
随着数据量的激增,数据压缩技术显得日益重要。HiGale数据压缩技术通过深入探讨数据压缩的理论基础和实践操作,提供了优化数据存储和传输的方法。本论文概述了数据冗余、压缩算法原理、压缩比和存储成本的关系,以及HiGale平台压缩工具的使用和压缩效果评估。文中还分析了数据压缩技术在
温度传感器校准大师课:一步到位解决校准难题

# 摘要
温度传感器校准对于确保测量数据的准确性和可靠性至关重要。本文从温度传感器的基础概念入手,详细介绍了校准的分类、工作原理以及校准过程中的基本术语和标准。随后,本文探讨了校准工具和环境的要求,包括实验室条件、所需仪器设备以及辅助软件和工具。文章第三章深入解析了校准步骤,涉及准备工作、测量记录以及数据
CPCI规范中文版深度解析:掌握从入门到精通的实用技巧
# 摘要
CPCI规范作为一种在特定行业内广泛采用的技术标准,对工业自动化和电子制造等应用领域具有重要影响。本文首先对CPCI规范的历史和发展进行了概述,阐述了其起源、发展历程以及当前的应用现状。接着,深入探讨了CPCI的核心原理,包括其工作流程和技术机制。本文还分析了CPCI规范在实际工作中的应用,包括项目管理和产品开发,并通过案例分析展示了CPCI规范的成功应用与经验教训。此外,文章对CPCI规范的高级应用技
【UML用户体验优化】:交互图在BBS论坛系统中的应用技巧
# 摘要
UML交互图作为软件开发中重要的建模工具,不仅有助于理解和设计复杂的用户交互流程,还是优化用户体验的关键方法。本文首先对UML交互图的基础理论进行了全面介绍,包括其定义、分类以及在软件开发中的作用。随后,文章深入探讨了如何在论坛系统设计中实践应用UML交互图,并通过案例分析展示了其在优化用户体验方面的具体应用。接着,本文详细讨论了UML交互图的高级应用技巧,包括与其他UML图的协同工作、自动化工具的运用以及在敏捷开发中的应用。最后,文章对UML交互图在论坛系统中的深入优化策略进行了研究,并展望了其未来的发展方向。
# 关键字
UML交互图;用户体验;论坛系统;软件开发;自动化工具;
【CRYSTAL BALL软件全攻略】:从安装到高级功能的进阶教程
# 摘要
CRYSTAL BALL软件是一套先进的预测与模拟工具,广泛应用于金融、供应链、企业规划等多个领域。本文首先介绍了CRYSTAL BALL的安装和基本操作,包括界面布局、工具栏、菜单项及预测模型的创建和管理。接着深入探讨了其数据模拟技术,涵盖概率分布的设定、模拟结果的分析以及风险评估和决策制定的方法。本文还解析了CRYSTAL BALL的
【复杂设计的公差技术】:ASME Y14.5-2018高级分析应用实例
# 摘要
公差技术是确保机械组件及装配精度的关键工程方法。本文首先
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )