BERT模型Fine-tuning技巧与调优策略
发布时间: 2023-12-26 17:15:16 阅读量: 57 订阅数: 24 
# 一、 BERT模型简介与原理概述
BERT(Bidirectional Encoder Representations from Transformers)是一种基于Transformer架构的预训练语言表示模型,由Google在2018年提出,取得了在自然语言处理领域多项任务上的state-of-the-art成绩。本章将对BERT模型的背景与发展、基本原理解析以及优势与应用场景进行概述。
### 二、BERT模型Fine-tuning的基本步骤
在本章中,我们将详细介绍BERT模型Fine-tuning的基本步骤,包括数据准备与预处理、模型输入与输出设置,以及Fine-tuning过程与方法。通过本章的学习,读者将了解如何对BERT模型进行Fine-tuning,并应用于特定任务中。
#### 2.1 数据准备与预处理
在进行BERT模型的Fine-tuning之前,首先需要对待处理的数据进行准备和预处理。数据准备的主要步骤包括数据收集、数据清洗、数据标记等。接下来是数据预处理的主要步骤,包括分词处理、填充与截断、构建输入样本等。
以下是一个Python示例代码,演示了如何使用Hugging Face的transformers库对文本数据进行BERT模型的预处理:
```python
from transformers import BertTokenizer
# 初始化BERT tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
# 文本数据预处理
def preprocess_text(text, max_length):
# 分词处理
tokenized_text = tokenizer.encode_plus(
text,
max_length=max_length,
truncation=True,
padding='max_length',
return_attention_mask=True,
return_token_type_ids=False,
return_tensors='pt'
)
return tokenized_text
# 示例文本
text = "BERT (Bidirectional Encoder Representations from Transformers) is a NLP model developed by Google."
max_length = 128
# 对文本进行预处理
input_data = preprocess_text(text, max_length)
print(input_data)
```
在上述代码中,我们使用了transformers库中的BertTokenizer对文本数据进行了预处理,包括分词处理、填充与截断。最终得到了适用于BERT模型输入的格式化数据。
#### 2.2 模型输入与输出设置
完成数据的准备与预处理后,接下来需要设置模型的输入与输出。对于BERT模型,输入通常包括token ids、attention mask和token type ids等。输出则根据具体的Fine-tuning任务而定,可以是分类结果、回归结果等。
以下是一个Python示例代码,演示了如何使用Hugging Face的transformers库设置BERT模型的输入与输出格式:
```python
import torch
from transformers import BertForSequenceClassification, BertConfig
# 初始化BERT模型
model_name = 'bert-base-uncased'
num_labels = 2 # 分类类别数
config = BertConfig.from_pretrained(model_name)
model = BertForSequenceClassification.from_pretrained(model_name, config=config)
# 示例输入数据
input_ids = torch.tensor([[1, 2, 3, 0, 0]])
attention_mask = torch.tensor([[1, 1, 1, 0, 0]])
# 模型前向推理
outputs = model(input_ids=input_ids, attention_mask=attention_mask)
# 输出格式设置
logits = outputs.logits # 分类结果
print(logits)
```
在上述代码中,我们首先使用transformers库中的BertForSequenceClassification模型初始化了一个BERT分类模型。然后设置了示例输入数据的input_ids和attention_mask,并进行了模型的前向推理,得到了分类结果logits。
#### 2.3 Fine-tuning过程与方法
最后,我们将介绍BERT模型Fine-tuning的具体过程与方法。这包括如何设置Fine-tuning的超参数、选择合适的优化器和学习率调度器、定义损失函数,以及进行Fine-tuning训练与评估等步骤。
### 三、 Fine-tuning中的关键技巧

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏主要介绍BERT(Bidirectional Encoder Representations from Transformers)模型及其在自然语言处理领域的应用。专栏中的文章围绕BERT展开,涵盖了多个方面,包括BERT的原理解析与模型架构深入分析、文本分类任务、文本生成、情感分析、命名实体识别、序列标注、语义相似度计算、问答系统、跨语言应用等。文章还讨论了BERT与注意力机制的关系和与其他预训练模型的比较评估。同时,专栏还涵盖了BERT模型在解决长文本处理、语音识别和低资源语种的适应性方面的研究。通过这些文章的阅读,读者可以深入了解BERT模型的原理、应用和技巧,并掌握使用BERT进行自然语言处理任务的方法。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【JMeter 性能优化全攻略】:9个不传之秘提高你的测试效率
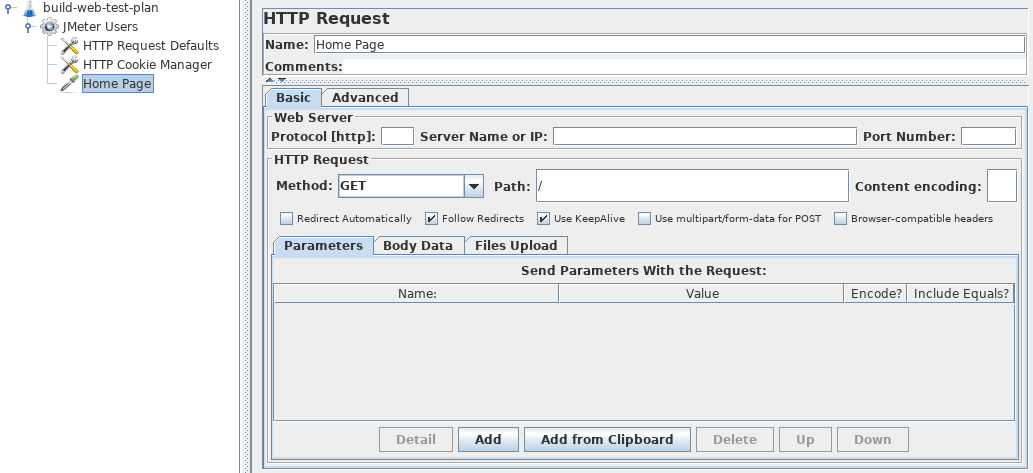
# 摘要
本文全面介绍了JMeter这一开源性能测试工具的基础知识、工作原理、实践技巧及性能优化高级技术。首先,通过解析JMeter的基本架构、线程组和采样器的功能,阐述了其在性能测试中的核心作用。随后,作者分享了设计和优化测试计划的技巧,探讨了高级组件的应用,负载生成与结果分析的方法。此外,文章深入探讨了性能优化技术,包括插件使用、故障排查、调优策略和测试数据管理。最后,本文介绍
【提升文档专业度】:掌握在Word中代码高亮行号的三种专业方法
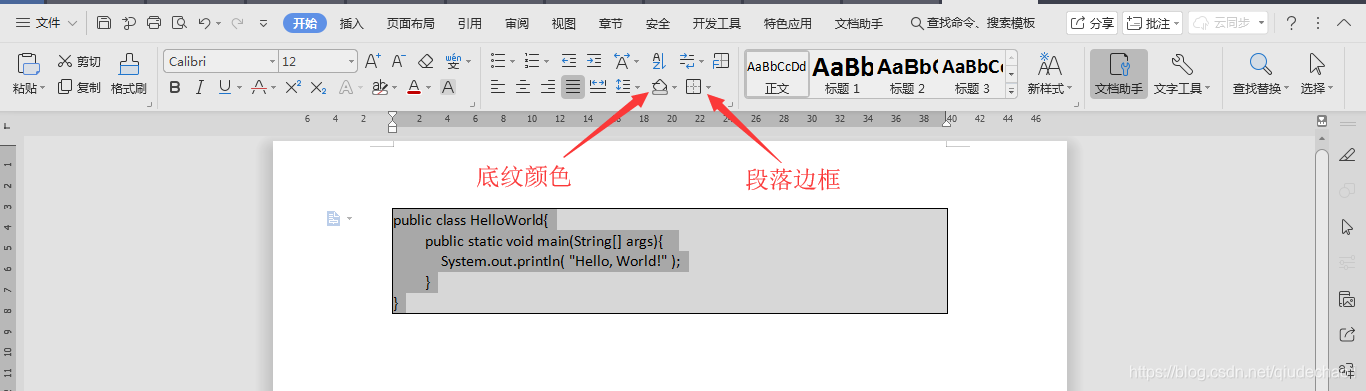
# 摘要
本文详细探讨了在文档处理软件Word中代码高亮与行号的重要性及其实现技巧。首先介绍了代码高亮和行号在文档中的重要性,紧接着讨论了Word基础操作和代码高亮技巧,包
【PHY62系列SDK实战全攻略】:内存管理、多线程编程与AI技术融合
# 摘要
本文综合探讨了PHY62系列SDK的内存管理、多线程编程以及AI技术的融合应用。文章首先介绍了SDK的基本环境搭建,随后深入分析了内存管理策略、内存泄漏及碎片问题,并提供了内存池和垃圾回收的优化实践。在多线程编程方面,本文探讨了核心概念、SDK支持以及在项目中的实际应用。此外,文章还探讨了AI技术如何融入SDK,并通过
【Matlab代理建模实战】:复杂系统案例一步到位

# 摘要
代理建模作为一种数学和计算工具,广泛应用于复杂系统的仿真和预测,其中Matlab提供了强大的代理建模工具和环境配
LabVIEW进阶必看:动态图片按钮的5大构建技巧
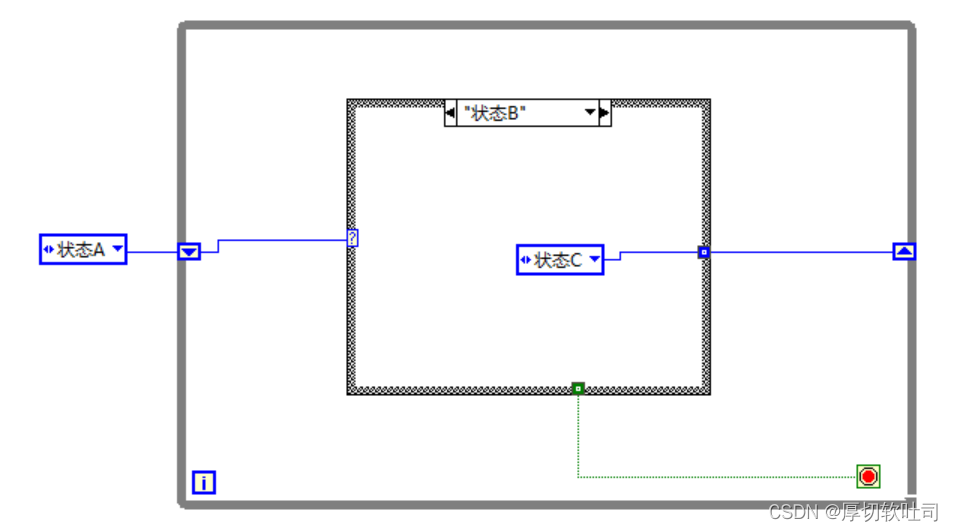
# 摘要
LabVIEW作为一种图形化编程语言,广泛应用于数据采集、仪器控制等领域,其动态图片按钮的开发对于提升交互性和用户体验具有重要意义。本文从动态图片按钮的概述出发,深入探讨了其理论基础、设计技巧、实战开发以及高级应用。文章详细阐述了图形用户界面的设计原则、图片按钮的功能要求、实现技术和优化策略。实战开发章节通过具体案例分析,提供了从创建基础按钮到实现复杂交互逻辑的详细步骤。最后,探讨了动态图片按钮
AXI-APB桥系统集成:掌握核心要点,避免常见故障
# 摘要
本文全面介绍了AXI-APB桥在系统集成中的应用,包括其理论基础、工作原理和实践应用。首先,介绍了AXI和APB协议的主要特性和在SoC中的作用,以及AXI-APB桥的数据转换、传输机制和桥接信号处理方法。其次,详细阐述了将AXI-APB桥集成到SoC设计中的步骤,包括选择合适的实现、连接处理器与外设,并介绍了调试、验证及兼容性问题的处理。最后,文中针对AXI-APB桥的常见故障
【SMAIL命令行秘籍】:24小时掌握邮件系统操作精髓

# 摘要
本文旨在全面介绍SMAIL命令行工具的基础使用方法、邮件发送与接收的理论基础、邮件系统架构、网络安全措施,以及通过实战操作提高工作效率的技巧。文章深入探讨了SMTP、POP3与IMAP协议的工作原理,以及MTA和MUA在邮件系统中的角色。此外,文章还涵盖了SMAIL命令行的高级使用技巧、自动化脚本编写和集成,以及性能优化与故障排除方
CCU6编程大师课:提升系统性能的高级技巧

# 摘要
CCU6系统性能优化是一个复杂而关键的课题,涉及对系统架构的深入理解、性能监控、调优策略以及安全性能提升等多个方面。本文首先概述了CCU6系统性能优化的重要性,并详细探讨了系统架构组件及其工作原理、性能监控与分析工具以及系统调优的策略,包括硬件资源和软件配置的优化。接着,本文介绍了高级性能提升技巧
【CListCtrl行高调整全攻略】:打造极致用户体验的10个技巧

# 摘要
本文深入探讨了CListCtrl控件在软件开发中的应用,特别是其行高调整的相关技术细节和实践技巧。首先,我们介绍了CListCtrl的基础知识及其行高的基本概念,然后分析了行高特性、绘制机制和技术方法。接着,本文重点讲解了如何根据内容、用户交互和自定义绘制来动态调整
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )