PHP数据库操作类调试技巧:快速定位并解决问题,提升开发效率
发布时间: 2024-08-01 09:47:37 阅读量: 26 订阅数: 24 

PHP实例开发源码—HisiPHP快速开发框架.zip

# 1. PHP数据库操作类概述
PHP数据库操作类是用于连接、操作和管理数据库的强大工具。它提供了丰富的API,使开发人员能够以高效且可扩展的方式与数据库交互。
这些类通常具有以下核心功能:
- 建立和管理数据库连接
- 执行SQL查询和更新语句
- 处理查询结果和数据操作
- 提供错误处理和调试机制
# 2. PHP数据库操作类调试基础
### 2.1 调试工具和方法
#### 2.1.1 使用PHP内置调试器
PHP内置调试器是一个强大的工具,用于调试PHP代码。它允许开发者在代码中设置断点,逐行执行代码,并检查变量的值。
**使用步骤:**
1. 在需要调试的代码行前添加`var_dump()`或`print_r()`函数。
2. 在命令行中运行`php -d display_errors=On`命令。
3. 运行脚本并观察输出。
**示例:**
```php
<?php
$name = 'John Doe';
var_dump($name);
?>
```
**输出:**
```
string(8) "John Doe"
```
#### 2.1.2 使用第三方调试工具
除了PHP内置调试器,还有许多第三方调试工具可供选择,例如:
- Xdebug:一个功能强大的调试器,提供高级功能,如代码覆盖率和内存分析。
- Kint:一个轻量级的调试器,提供交互式变量检查和格式化输出。
- Symfony Debug:一个与Symfony框架集成的调试工具,提供错误日志记录、异常处理和性能分析。
### 2.2 调试日志和异常处理
#### 2.2.1 日志记录机制
日志记录是调试数据库操作类问题的一种重要技术。它允许开发者记录事件、错误和警告信息,以便稍后进行分析。
PHP提供了`error_log()`函数来记录日志信息。它可以将消息写入文件、数据库或其他目标。
**示例:**
```php
<?php
error_log('Database connection failed');
?>
```
#### 2.2.2 异常处理机制
异常是运行时发生的错误或异常情况。PHP提供了`try-catch`结构来处理异常。
**使用步骤:**
1. 在可能发生异常的代码块中使用`try`块。
2. 在`try`块中捕获异常并使用`catch`块处理它们。
3. 使用`throw`语句显式抛出异常。
**示例:**
```php
<?php
try {
// 数据库操作代码
} catch (Exception $e) {
// 处理异常
}
```
# 3. PHP数据库操作类常见问题
### 3.1 连接和认证问题
#### 3.1.1 无法连接到数据库
**原因:**
* 数据库服务器未启动或不可访问。
* 数据库服务器地址或端口配置错误。
* 防火墙或网络问题阻止了连接。
* 数据库用户权限不足。
**解决方法:**
* 检查数据库服务器是否正在运行。
* 验证数据库服务器地址和端口是否正确。
* 检查防火墙或网络配置是否允许连接。
* 授予数据库用户适当的权限。
```php
<?php
try {
$conn = new PDO('mysql:host=localhost;dbname=test', 'root', 'password');
} catch (PDOException $e) {
echo '连接失败:' . $e->getMessage();
}
?>
```
**逻辑分析:**
此代码尝试连接到 MySQL 数据库,如果连接失败,将抛出 `PDOException` 异常并输出错误消息。
#### 3.1.2 认证失败
**原因:**
* 数据库用户名或密码错误。
* 数据库用户没有访问该数据库的权限。
**解决方法:**
* 检查数据库用户名和密码是否正确。
* 确保数据库用户具有访问该数据库的权限。
```php
<?php
try {
$conn = new PDO('mysql:host=localhost;dbname=test', 'invalid_username', 'invalid_password');
} catch (PDOException $e) {
echo '认证失败:' . $e->getMessage();
}
?>
```
**逻辑分析:**
此代码尝试使用无效的用户名和密码连接到 MySQL 数据库,因此将抛出 `PDOException` 异常并输出认证失败的消息。
### 3.2 查询和操作问题
#### 3.2.1 查询语句错误
**原因:**
* SQL 语句语法错误。
* 表或字段不存在。
* 数据类型不匹配。
**解决方法:**
* 检查 SQL 语句的语法是否正确。
* 确保表和字段存在。
* 确保数据类型与数据库中定义的类型匹配。
```php
<?php
$query = 'SELECT * FROM users WHERE name = "John"';
$result = $conn->query($query);
```
**逻辑分析:**
此代码执行一个 SQL 查询来获取名为 "John" 的用户,如果查询语句中存在语法错误,将返回 `false`。
#### 3.2.2 数据操作异常
**原因:**
* 违反数据库约束(例如,唯一性约束、外键约束)。
* 数据类型不匹配。
* 权限不足。
**解决方法:**
* 检查是否违反了任何数据库约束。
* 确保数据类型与数据库中定义的类型匹配。
* 授予用户适当的权限。
```php
<?php
$query = 'INSERT INTO users (name, email) VALUES ("John", "john@example.com")';
$result = $conn->exec($query);
```
**逻辑分析:**
此代码执行一个 SQL 插入语句,如果违反了任何数据库约束(例如,用户名已存在),将返回 `false`。
# 4. PHP数据库操作类高级调试技巧
### 4.1 SQL语句分析和优化
#### 4.1.1 使用EXPLAIN命令
EXPLAIN命令用于分析SQL语句的执行计划,它可以帮助我们了解SQL语句的执行过程,找出性能瓶颈。
**语法:**
```php
EXPLAIN [FORMAT {JSON | TREE | TRADITIONAL}] query_string
```
**参数:**
* FORMAT:指定输出格式,可选值为JSON、TREE或TRADITIONAL(默认)。
* query_string:要分析的SQL语句。
**示例:**
```php
$sql = "SELECT * FROM users WHERE age > 20";
$result = $mysqli->query("EXPLAIN $sql");
```
**输出:**
```
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | users | ALL | NULL | NULL | NULL | NULL | 1000 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
```
输出结果中包含以下信息:
* select_type:查询类型,如SIMPLE、PRIMARY等。
* table:涉及的表。
* type:访问类型,如ALL、INDEX、RANGE等。
* possible_keys:可能使用的索引。
* key:实际使用的索引。
* key_len:索引长度。
* ref:使用索引的列。
* rows:估计扫描的行数。
* Extra:其他信息,如Using where等。
通过分析EXPLAIN命令的输出结果,我们可以找出SQL语句中可能存在的性能问题,例如:
* **全表扫描(ALL):**表示SQL语句没有使用索引,需要扫描整个表。
* **索引覆盖(Using index):**表示SQL语句使用了索引,但查询结果只包含索引中的列。
* **索引未命中(Using where):**表示SQL语句使用了索引,但索引未命中,导致全表扫描。
#### 4.1.2 优化SQL语句性能
根据EXPLAIN命令的分析结果,我们可以采取以下措施优化SQL语句性能:
* **创建索引:**为经常查询的列创建索引。
* **使用合适的索引:**选择合适的索引类型,如B树索引、哈希索引等。
* **避免全表扫描:**使用索引覆盖查询或范围查询,避免全表扫描。
* **优化查询条件:**使用AND、OR、IN等条件优化查询条件。
* **使用临时表:**对于复杂查询,可以将中间结果存储在临时表中,提高查询性能。
### 4.2 代码覆盖率测试
#### 4.2.1 使用PHPUnit进行代码覆盖率测试
PHPUnit是一个PHP单元测试框架,它提供了代码覆盖率测试功能。
**安装:**
```php
composer require --dev phpunit/phpunit
```
**示例:**
```php
use PHPUnit\Framework\TestCase;
class DatabaseTest extends TestCase
{
public function testQuery()
{
$sql = "SELECT * FROM users WHERE age > 20";
$result = $mysqli->query($sql);
$this->assertNotEmpty($result);
}
}
```
**运行测试:**
```php
phpunit --coverage-html coverage
```
**输出:**
代码覆盖率报告将生成在coverage目录下。报告中包含以下信息:
* **覆盖率:**代码覆盖率的百分比。
* **覆盖率报告:**显示每个文件的覆盖率,以及哪些行被覆盖,哪些行未被覆盖。
#### 4.2.2 分析测试结果并改进代码
通过分析代码覆盖率报告,我们可以找出未被覆盖的代码,并采取措施改进代码。
* **增加测试用例:**编写更多的测试用例,覆盖未被覆盖的代码。
* **重构代码:**重构代码,使代码更容易测试。
* **删除冗余代码:**删除未被覆盖的冗余代码。
# 5. PHP数据库操作类最佳实践
### 5.1 代码规范和命名约定
#### 5.1.1 遵循PHP编码标准
PHP编码标准(PSR)是一套针对PHP代码编写的建议性指导原则。遵循PSR标准可以提高代码的可读性、可维护性和一致性。
**好处:**
- 提高代码可读性,便于其他开发人员理解和维护
- 确保代码风格的一致性,减少代码混乱和错误
- 促进团队协作,减少代码审查和合并冲突
**建议:**
- 使用PSR-12编码标准作为代码规范
- 使用自动代码格式化工具(如PHP-CS-Fixer)来强制执行编码标准
- 在代码库中建立代码审查流程,以确保代码符合标准
#### 5.1.2 采用统一的命名规范
统一的命名规范有助于提高代码的可读性、可维护性和可重用性。
**好处:**
- 提高代码的可读性,便于快速理解变量、函数和类的用途
- 促进代码重用,减少重复和错误
- 提高代码的可维护性,便于查找和修改特定代码元素
**建议:**
- 对于变量,使用驼峰命名法(小写开头,单词之间大写)
- 对于函数和类,使用帕斯卡命名法(所有单词大写)
- 对于常量,使用大写字母和下划线分隔单词
- 对于数据库表和列,使用复数形式和下划线分隔单词
### 5.2 安全和性能优化
#### 5.2.1 预防SQL注入攻击
SQL注入攻击是一种通过在用户输入中插入恶意SQL语句来攻击数据库的攻击。
**预防措施:**
- **使用预处理语句:**预处理语句可以防止SQL注入攻击,因为它将用户输入与SQL语句分开。
- **转义用户输入:**转义用户输入可以防止恶意字符被解释为SQL语句的一部分。
- **使用参数化查询:**参数化查询可以防止SQL注入攻击,因为它将用户输入作为参数传递给SQL语句。
#### 5.2.2 优化数据库连接池
数据库连接池可以提高数据库操作的性能,因为它减少了创建和销毁数据库连接的开销。
**好处:**
- 减少数据库连接的开销,提高性能
- 减少数据库服务器的负载,提高稳定性
- 简化数据库连接管理,提高可维护性
**建议:**
- 使用PDO或mysqli等支持连接池的PHP扩展
- 配置连接池的大小,以满足应用程序的需求
- 定期清理连接池,以防止连接泄漏
# 6. PHP数据库操作类案例分析
### 6.1 复杂查询和数据处理
**6.1.1 使用JOIN和子查询**
JOIN语句用于将来自不同表的记录组合在一起,子查询用于在查询中嵌套另一个查询。这两种技术可以帮助我们处理复杂的数据关系和提取特定信息。
```php
// 使用JOIN连接两个表
$sql = "SELECT * FROM users JOIN orders ON users.id = orders.user_id";
// 使用子查询查找特定订单
$sql = "SELECT * FROM orders WHERE order_id IN (SELECT order_id FROM order_items WHERE product_id = 1)";
```
### 6.1.2 处理大数据量和复杂数据结构
当处理大数据量或复杂数据结构时,需要优化查询性能和处理逻辑。可以使用分页、缓存和数据结构转换等技术。
```php
// 使用分页处理大数据量
$limit = 10;
$offset = ($page - 1) * $limit;
$sql = "SELECT * FROM orders LIMIT $limit OFFSET $offset";
// 使用缓存提高查询速度
$cache = new Cache();
$cacheKey = "orders_page_" . $page;
if ($cache->has($cacheKey)) {
$orders = $cache->get($cacheKey);
} else {
$sql = "SELECT * FROM orders LIMIT $limit OFFSET $offset";
$orders = $db->query($sql)->fetchAll();
$cache->set($cacheKey, $orders, 3600);
}
// 使用数据结构转换处理复杂数据
$orders = $db->query("SELECT * FROM orders")->fetchAll();
$ordersByCustomer = [];
foreach ($orders as $order) {
$ordersByCustomer[$order['customer_id']][] = $order;
}
```
### 6.2 数据库事务和并发控制
**6.2.1 使用事务机制保证数据一致性**
事务机制可以确保数据库操作的原子性和一致性。它将一系列操作作为一个整体执行,要么全部成功,要么全部失败。
```php
try {
$db->beginTransaction();
$db->query("UPDATE users SET balance = balance + 100 WHERE id = 1");
$db->query("UPDATE orders SET total_amount = total_amount + 100 WHERE user_id = 1");
$db->commit();
} catch (Exception $e) {
$db->rollback();
}
```
**6.2.2 处理并发访问和锁问题**
并发访问可能导致数据不一致和死锁问题。可以使用锁机制来控制对数据库资源的访问。
```php
// 使用悲观锁
$db->query("LOCK TABLE orders WRITE");
// 使用乐观锁
$order = $db->query("SELECT * FROM orders WHERE id = 1")->fetch();
$order['total_amount'] += 100;
$db->query("UPDATE orders SET total_amount = :total_amount WHERE id = 1 AND total_amount = :old_total_amount", [
':total_amount' => $order['total_amount'],
':old_total_amount' => $order['total_amount'] - 100
]);
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《PHP数据库操作类秘籍》专栏深入剖析PHP数据库操作类的方方面面,从基础概念到高级技术,全面提升开发者的数据库操作能力。专栏涵盖了数据库操作类的内部机制、性能优化、安全保障、事务处理、连接池技术、查询优化、数据类型转换、错误处理、面向对象设计模式、存储过程与触发器、数据备份与恢复、分布式数据库技术、NoSQL数据库简介、数据库设计原则、数据库迁移策略、数据库监控与性能分析等核心内容。通过深入浅出的讲解和丰富的实践案例,本专栏将帮助开发者全面掌握PHP数据库操作类,提升数据库操作效率,保障数据安全,构建可扩展且高性能的数据库系统。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Origin自动化操作】:一键批量导入ASCII文件数据,提高工作效率
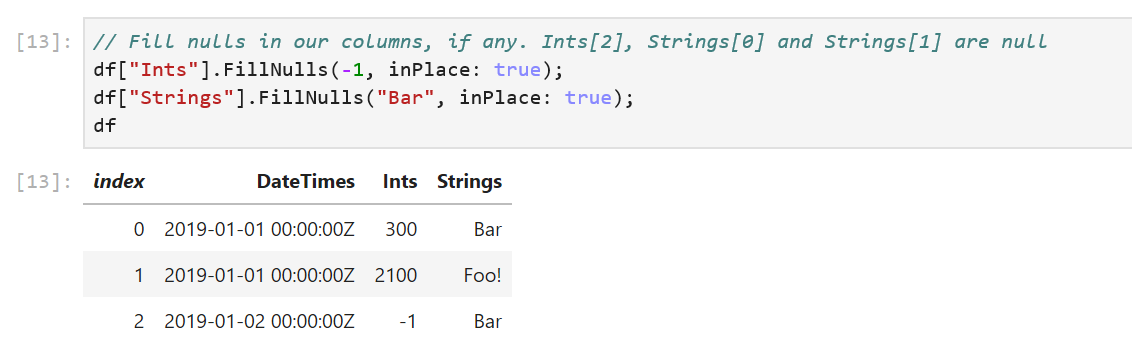
# 摘要
本文旨在介绍Origin软件在自动化数据处理方面的应用,通过详细解析ASCII文件格式以及Origin软件的功能,阐述了自动化操作的实现步骤和高级技巧。文中首先概述了Origin的自动化操作,紧接着探讨了自动化实现的理论基础和准备工作,包括环境配置和数据集准备。第三章详细介绍了Origin的基本操作流程、脚本编写、调试和测试方法
【揭秘CPU架构】:5大因素决定性能,你不可不知的优化技巧
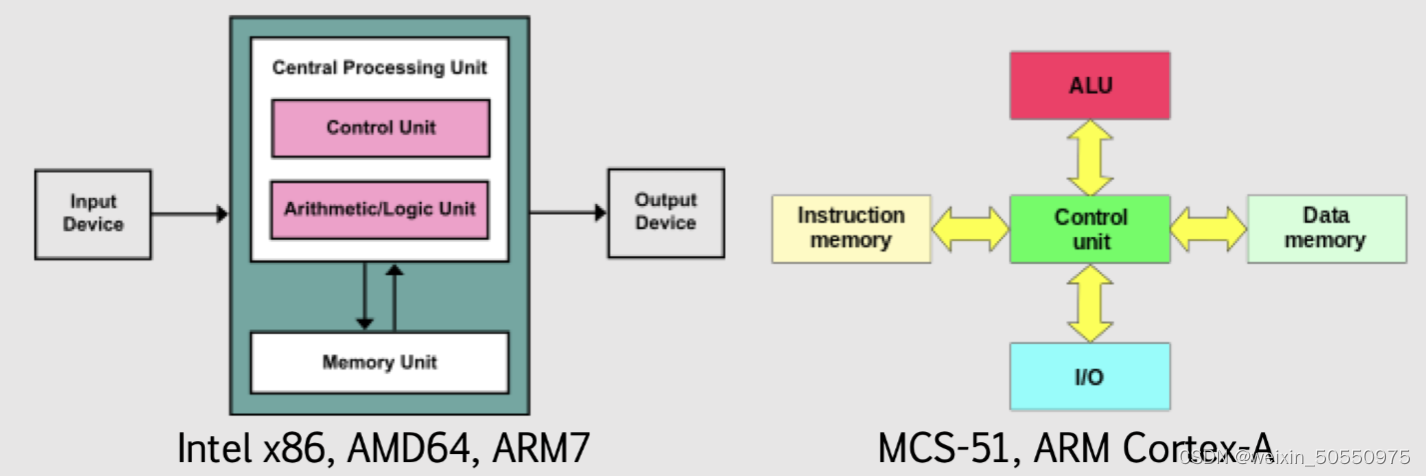
# 摘要
CPU作为计算机系统的核心部件,其架构的设计和性能优化一直是技术研究的重点。本文首先介绍了CPU架构的基本组成,然后深入探讨了影响CPU性能的关键因素,包括核心数量与线程、缓存结构以及前端总线与内存带宽等。接着,文章通过性能测试与评估的方法,提供了对CPU性能的量化分析,同时涉及了热设计功耗与能耗效率的考量。进一步,本文探讨了CPU优化的实践,包括超频技术及其风险预防,以及操作系统与硬件
AP6521固件升级后系统校验:确保一切正常运行的5大检查点

# 摘要
本文全面探讨了AP6521固件升级的全过程,从准备工作、关键步骤到升级后的系统校验以及问题诊断与解决。首先,分析了固件升级的意义和必要性,提出了系统兼容性和风险评估的策略,并详细说明了数据备份与恢复计划。随后,重点阐述了升级过程中的关键操作、监控与日志记录,确保升级顺利进行。升级完成后,介绍了系统的功能性检查、稳定性和兼容性测试以及安全漏洞扫描的重要性。最后,本研究总结
【金融时间序列分析】:揭秘同花顺公式中的数学奥秘

# 摘要
本文全面介绍时间序列分析在金融领域中的应用,从基础概念和数据处理到核心数学模型的应用,以及实际案例的深入剖析。首先概述时间序列分析的重要性,并探讨金融时间序列数据获取与预处理的方法。接着,深入解析移动平均模型、自回归模型(AR)及ARIMA模型及其扩展,及其在金融市场预测中的应用。文章进一步阐述同花顺公式中数学模型的应用实践,以及预测、交易策略开发和风险管理的优化。最后,通过案例研究,展现时间序列分析在个股和市场指数分析中
Muma包高级技巧揭秘:如何高效处理复杂数据集?

# 摘要
本文全面介绍Muma包在数据处理中的应用与实践,重点阐述了数据预处理、清洗、探索分析以及复杂数据集的高效处理方法。内容覆盖了数据类型
IT薪酬策略灵活性与标准化:要素等级点数公式的选择与应用

# 摘要
本文系统地探讨了IT行业的薪酬策略,从薪酬灵活性的理论基础和实践应用到标准化的理论框架与方法论,再到等级点数公式的应用与优化。文章不仅分析了薪酬结构类型和动态薪酬与员工激励的关联,还讨论了不同职级的薪酬设计要点和灵活福利计划的构建。同时,本文对薪酬标准化的目的、意义、设计原则以及实施步骤进行了详细阐述,并进一步探讨了等级点数公式的选取、计算及应用,以及优
社区与互动:快看漫画、腾讯动漫与哔哩哔哩漫画的社区建设与用户参与度深度对比
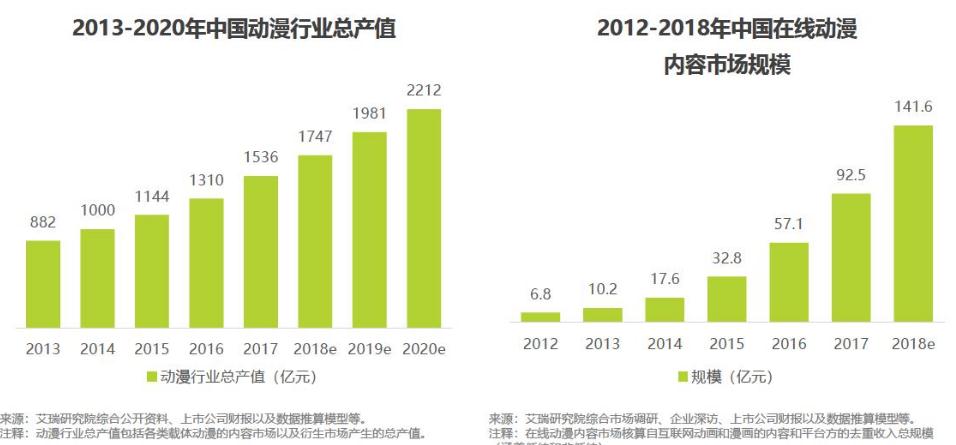
# 摘要
本文围绕现代漫画平台社区建设及其对用户参与度影响展开研究,分别对快看漫画、腾讯动漫和哔哩哔哩漫画三个平台的社区构建策略、用户互动机制以及社区文化进行了深入分析。通过评估各自社区功能设计理念、用户活跃度、社区运营实践、社区特点和社区互动文化等因素,揭示了不同平台在促进用户参与度和社区互动方面的策略与成效。此外,综合对比三平台的社区建设模式和用户参与度影响因素,本文提出了关于漫画平
【算法复杂度分析】:SVM算法性能剖析:时间与空间的平衡艺术

# 摘要
支持向量机(SVM)是一种广泛使用的机器学习算法,尤其在分类和回归任务中表现突出。本文首先概述了SVM的核心原理,并基于算法复杂度理论详细分析了SVM的时间和空间复杂度,包括核函数的作用、对偶问题的求解、SMO算法的复杂度以及线性核与非线性核的时间对比。接下来,本文探讨了SVM性能优化策略,涵盖算法和系统层面的改进,如内存管理和并行计算的应用。最后,本文展望了SV
【广和通4G模块硬件接口】:掌握AT指令与硬件通信的细节
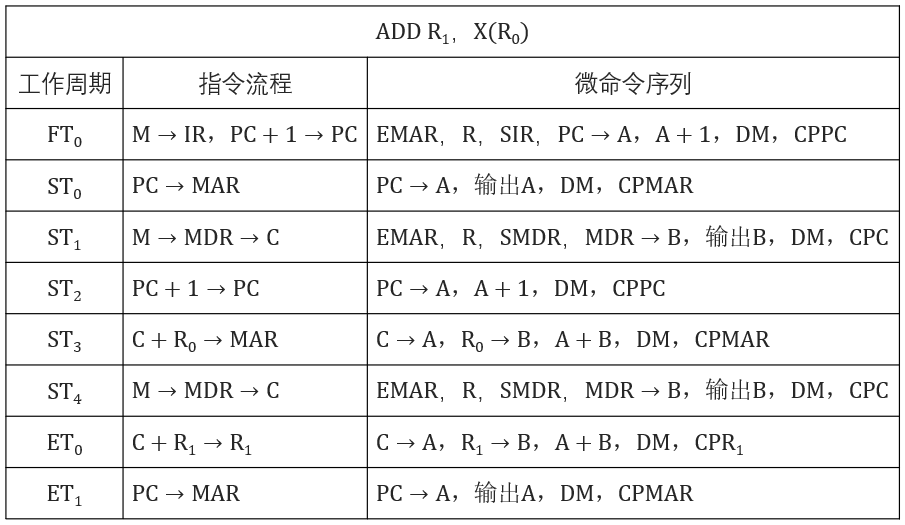
# 摘要
本文全面介绍了广和通4G模块的硬件接口,包括各类接口的类型、特性、配置与调试以及多模块之间的协作。首先概述了4G模块硬件接口的基本概念,接着深入探讨了AT指令的基础知识及其在通信原理中的作用。通过详细介绍AT指令的高级特性,文章展示了其在不同通信环境下的应用实例。文章还详细阐述了硬件接口的故障诊断与维护策略,并对4G模块硬件接口的未来技术发展趋势和挑战进行了展望,特别是在可穿戴设备、微型化接口设计以及云计算和大数据需求的背景下。
#
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )