【R语言环境搭建快速指南】:一键完成顶级分析环境配置!
发布时间: 2024-11-05 03:38:17 阅读量: 83 订阅数: 30 

# 1. R语言的简介与应用场景
## R语言简介
R语言是一种用于统计分析和图形表示的编程语言和环境,它于1993年由Ross Ihaka和Robert Gentleman开发,是S语言的一个实现版本。R语言拥有强大的数据处理能力、丰富的统计分析功能和高质量的图形输出,并且因为开源的特性,R语言社区十分活跃,贡献了数以千计的扩展包(packages),使得R语言的应用范围非常广泛。
## R语言的应用场景
R语言广泛应用于数据挖掘、金融分析、生物信息学、机器学习、数据分析和图形可视化等领域。由于R语言在统计计算方面的卓越表现,它在学术界和工业界均得到了广泛的认可。例如,它可以用于实现复杂的数据探索性分析,执行预测建模,并在生物医药领域分析临床试验数据。R语言因其灵活性和可扩展性,在处理和分析大数据集时也显示出其强大的优势。随着数据科学的兴起,R语言成为了数据分析师和统计学家手中的利器,不断推动数据科学领域的发展。
# 2. R语言环境的搭建准备
## 2.1 系统兼容性检查
### 2.1.1 检查操作系统版本
在安装R语言之前,首先需要确保你的操作系统兼容。R语言支持多种操作系统,包括Windows、macOS以及各类Linux发行版。可以使用命令行工具或系统信息工具来检查当前操作系统版本。以下是检查系统版本的通用步骤:
#### Windows系统
在命令提示符(cmd)中输入以下命令:
```cmd
ver
```
输出结果会显示Windows的版本号。
#### macOS系统
在终端中使用以下命令:
```bash
sw_vers
```
你会看到输出信息包含了操作系统版本。
#### Linux系统
在终端中输入以下命令:
```bash
lsb_release -a
```
或者,如果你的Linux发行版没有安装`lsb_release`,可以查看`/etc/os-release`文件:
```bash
cat /etc/os-release
```
### 2.1.2 确认硬件配置需求
R语言对硬件的要求并不高,基本的现代计算机硬件配置都可以满足运行需求。以下是一些基本的硬件配置建议:
- 处理器:至少双核处理器
- 内存:至少2GB RAM,推荐4GB或以上
- 硬盘空间:至少1GB的可用空间
对于运行复杂的数据分析任务和大型数据集,推荐使用更高配置的计算机以提升性能。
## 2.2 R语言安装前的准备工作
### 2.2.1 下载R语言安装包
R语言的官方下载网址是 *** 。访问该网站,根据你的操作系统,选择合适的安装包下载。
#### Windows系统
点击“Download R for Windows”链接,下载最新的R版本安装包。
#### macOS系统
点击“Download R for (Mac) OS X”,选择需要的R版本。
#### Linux系统
可以选择预编译的二进制包,也可以选择从源代码编译安装。预编译的包适用于大多数主流Linux发行版,如Ubuntu、Fedora等。
### 2.2.2 设置安装路径和环境变量
安装R语言时,你可以选择默认安装路径,也可以自定义路径。推荐使用默认路径或选择一个容易记忆的路径。
在安装过程中,安装程序会自动配置环境变量,这样你就可以在任何目录下使用R命令。如果你发现无法在命令行中直接使用R命令,可能需要手动设置环境变量。
#### Windows系统
在系统属性的高级设置中,找到环境变量设置,并添加R的安装路径到“Path”变量中。
#### macOS系统
打开终端,编辑`.bash_profile`(或`.zshrc`如果使用zsh shell),添加以下行:
```bash
export PATH=/path/to/R/bin:$PATH
```
#### Linux系统
使用文本编辑器编辑`~/.bashrc`或`~/.profile`文件,添加R的安装路径到环境变量`PATH`中。
```bash
export PATH=/path/to/R/bin:$PATH
```
完成编辑后,运行`source ~/.bashrc`(或`source ~/.profile`)使改动生效。现在你应该能够在终端中直接运行R命令了。
以上步骤完成后,你将为安装R语言打下了良好的基础。接下来,我们将继续探讨R语言基础环境的配置,以确保R语言能够在你的系统上运行得更加顺畅。
# 3. R语言基础环境配置
## 3.1 R语言的安装流程
### 3.1.1 Windows系统安装步骤
在Windows系统上安装R语言相对简单,遵循以下步骤:
1. 访问R语言官方网站(***)下载Windows版本的R语言安装包。
2. 双击下载的安装文件开始安装过程。
3. 在安装向导中选择“Install”选项以开始安装。
4. 在安装选项中,请确保选择了“32-bit R”或“64-bit R”,这取决于你的系统配置。
5. 一路点击“Next”(下一步)来接受默认的设置。
6. 确认安装完成,建议勾选“View Readme”(查看Readme)以阅读安装后说明。
7. 安装完成后,你会在开始菜单中看到R语言的快捷方式。
### 3.1.2 macOS/Linux系统安装步骤
对于macOS和Linux系统,R语言的安装过程略有不同。
#### macOS系统
1. 访问R语言官方网站(***)下载macOS版本的R语言安装包。
2. 双击下载的`.pkg`文件开始安装过程。
3. 在安装向导中跟随指引进行安装。
4. 安装完成后,打开终端并输入`R`,以确认R语言是否已正确安装。
#### Linux系统
1. 对于基于Debian的Linux发行版(如Ubuntu),可以使用以下命令安装R语言:
```bash
sudo apt-get update
sudo apt-get install r-base
```
2. 对于基于Red Hat的Linux发行版(如Fedora),可以使用以下命令安装R语言:
```bash
sudo yum install R
```
3. 安装完成后,通过在终端运行`R`命令来验证安装。
## 3.2 R语言包管理器的配置
### 3.2.1 配置CRAN镜像源
R语言包管理器从CRAN(Comprehensive R Archive Network)下载包。由于网络问题或其他原因,有时需要配置一个本地镜像源以加速下载过程。
```R
# R语言代码块,用于添加CRAN镜像源
chooseCRANmirror(graphics=FALSE)
local({r <- getOption("repos")
r["CRAN"] <- "***"
options(repos=r)})
```
执行上述R脚本后,R会弹出一个图形界面让你选择一个镜像源,或者你可以直接设置一个默认镜像源。
### 3.2.2 使用devtools安装开发版本包
当需要安装正在开发的包或版本时,可以使用devtools包来从GitHub等代码托管平台安装。
```R
# R语言代码块,使用devtools包从GitHub安装包
if (!requireNamespace("devtools", quietly = TRUE))
install.packages("devtools")
devtools::install_github("user/repo")
```
以上代码展示了如何先检查`devtools`是否已经安装,如果没有,则进行安装。接着通过`devtools::install_github`函数安装GitHub上的`user`用户下的`repo`仓库。
### 表格:CRAN镜像源与来源
| 镜像源名称 | URL地址 |
|-----------|------------------------------------|
| 清华大学 | ***
* 北京外国语大学 | ***
* 西安交通大学 | ***
* 中国科技大学 | ***
请注意,表格提供了几个在中国可访问性较好的镜像源。用户可以根据自己的网络环境选择适当的镜像源。
接下来的部分将探讨R语言环境问题的解决方法及性能优化策略,确保用户能够高效且稳定地使用R语言进行数据分析和统计计算。
# 4. ```
# 第四章:R语言开发环境的搭建
在本章节中,我们将深入了解如何搭建一个适合进行R语言开发的环境。我们将从选择和配置集成开发环境(IDE)开始,然后探讨如何通过版本控制系统来实现代码的管理与团队协作。这一章节将为读者提供搭建高效R语言开发环境的详细步骤。
## 4.1 IDE的选择与配置
集成开发环境(IDE)是进行R语言开发不可或缺的部分。它提供了一系列工具来帮助开发者编写、调试和运行R代码。
### 4.1.1 RStudio的安装与界面介绍
RStudio是最流行的R语言IDE之一,它支持跨平台使用,并提供免费的开源版本。为了更好地进行R语言的开发工作,我们需要首先安装RStudio。
#### 安装步骤
1. 访问RStudio官网下载页面:[***](***
** 根据您的操作系统选择合适的安装包下载。
3. 运行安装程序并遵循向导完成安装。
#### 界面介绍
安装完成后,启动RStudio。以下是对RStudio主要界面组成部分的介绍:
- **源代码编辑器**:左侧区域,用于编写和编辑R脚本。
- **控制台**:右下区域,可以输入R命令并看到执行结果。
- **环境/历史记录/连接**:右上区域,展示当前工作空间环境、历史命令和连接管理。
- **文件/绘图/包/帮助**:左下区域,提供文件管理、绘图查看、包管理以及帮助文档的访问。
### 4.1.2 插件的安装与配置优化
为了提升RStudio的功能,我们可以通过安装插件来扩展其功能。RStudio拥有一个强大的插件生态系统,可以安装插件来添加代码语法高亮、代码自动完成、项目管理等功能。
#### 插件安装步骤
1. 在RStudio中打开“Tools”菜单,选择“Install Packages...”。
2. 在“Packages”框中输入插件的名称,然后点击“Install”按钮。
#### 配置优化
为了优化RStudio的性能和工作流程,我们建议配置以下设置:
- **自动代码补全**:在“Tools”菜单中选择“Global Options...”,然后在“Code”选项卡中调整自动补全的设置。
- **快捷键设置**:在“Tools”菜单的“Modify Keyboard Shortcuts...”选项中自定义快捷键,以提高工作效率。
## 4.2 R语言的版本控制与协作
版本控制系统允许开发者追踪代码的变更历史,并简化团队协作过程。Git是最常用的版本控制系统之一,而GitHub、GitLab等平台提供了代码托管服务,方便代码的共享和协作。
### 4.2.1 配置Git与R语言项目整合
要将Git与R语言项目整合,我们需要在本地安装Git,并在RStudio中进行配置。
#### Git安装与配置步骤
1. 访问Git官方网站下载页面:[***](***
** 下载并安装适合您操作系统的Git版本。
3. 在RStudio中打开“Tools”菜单,选择“Global Options...”。
4. 在“Git/SVN”选项卡中,设置Git的安装路径。
#### RStudio与Git的整合
RStudio提供了一系列工具来与Git协作:
- 在RStudio中,通过“Tools”菜单选择“Version Control”下的选项来管理项目版本。
- 使用“New Project”向导时,可以选择“Version Control”选项来创建一个新的版本控制项目。
### 4.2.2 探索GitHub等平台的代码协作
GitHub是全球最大的代码托管平台之一,它与Git紧密集成,并提供了丰富的协作工具。
#### GitHub项目的创建与协作步骤
1. 在GitHub网站上创建一个新的仓库(Repository)。
2. 在本地初始化一个Git仓库,并将其推送到GitHub上创建的远程仓库。
3. 通过“Pull requests”来管理代码的合并,以及通过“Issues”来跟踪项目中的问题。
通过以上步骤,我们可以利用RStudio与GitHub等平台,实现R语言项目的版本控制与团队协作。
## 4.3 R语言开发环境的进阶设置
对于追求更高效率的开发者来说,以下的进阶设置可以让R语言的开发体验更上一层楼:
### 进阶IDE配置
- **代码片段(Snippets)**:在RStudio中定义常用的代码片段,提高编码效率。
- **项目模板**:设置项目模板可以加快新项目的启动速度,使其迅速进入开发状态。
### 集成开发环境的扩展
- **外部工具的集成**:比如使用LaTeX编写文档,或者利用R Markdown进行数据分析报告的生成。
### 性能优化
- **R包的及时更新**:保持R包的最新状态可以确保代码的兼容性和性能。
- **分析依赖关系**:使用工具如`packrat`来管理项目依赖,确保项目的可移植性。
以上介绍为R语言开发环境搭建的详尽指南,涵盖了从基础到进阶的各种配置方法,使R语言的开发流程更为高效和系统化。
```
```mermaid
graph LR
A[开始配置RStudio] --> B[安装RStudio]
B --> C[安装插件]
C --> D[配置Git]
D --> E[使用GitHub整合项目]
E --> F[完成环境配置]
```
```mermaid
sequenceDiagram
participant U as 用户
participant RStudio as RStudio IDE
participant Git as Git
participant GitHub as GitHub
U ->> RStudio: 下载并安装RStudio
RStudio ->> RStudio: 配置Git路径
RStudio ->> Git: 安装Git
Git -->> RStudio: 完成安装
RStudio ->> GitHub: 注册GitHub账户
GitHub -->> RStudio: 用户认证
RStudio ->> RStudio: 创建新项目
RStudio ->> GitHub: 创建仓库
GitHub -->> RStudio: 仓库信息
RStudio ->> RStudio: 推送本地仓库到GitHub
GitHub -->> RStudio: 同步完成
```
```markdown
| IDE | 功能支持 | 用户体验优化 |
|----------------|---------------------------------|-------------------------------|
| RStudio | 代码编辑、运行、调试 | 语法高亮、代码自动完成 |
| RStudio 插件 | 项目管理、扩展功能 | 定制快捷键、代码片段 |
| Git | 版本控制 | 本地与远程仓库管理 |
| GitHub | 代码托管、团队协作 | 问题追踪、文档协作 |
```
在上述章节内容中,我们通过明确的步骤和解释,以及表格、mermaid流程图和Markdown格式,详细介绍了R语言开发环境的搭建。包括了IDE的选择和配置,版本控制系统的整合,以及进阶开发环境的设置。这些内容将有助于R语言开发者建立高效、规范的开发流程。
# 5. R语言高级功能与实践
## 5.1 R语言与其他编程语言的交互
### 5.1.1 与Python的数据交互
在数据科学领域,R语言和Python都是重要的工具,它们各有千秋。R语言擅长统计分析和数据可视化,而Python在机器学习和网络爬虫方面更为突出。因此,将两种语言相结合可以发挥各自的优势,处理更加复杂的数据问题。
为了实现R和Python之间的数据交互,我们可以使用几个常用的包,如`reticulate`。这个包允许R用户访问Python对象和库,并可以无缝地在R和Python之间切换。
首先,安装`reticulate`包:
```R
install.packages("reticulate")
```
加载包后,可以配置想要使用的Python环境:
```R
library(reticulate)
use_python("/path/to/python/bin/python3")
```
接着,你可以使用`py_run_file()`函数运行Python代码,或者直接在R中调用Python函数,如:
```R
x <- py_eval("2 * 3")
print(x)
```
这里,`py_eval`函数执行Python表达式,并将结果返回到R会话中。
此外,使用`source_python()`函数,可以直接从R代码中调用Python脚本,允许在R中使用Python数据结构和函数。
交互示例:
```R
# 在Python中准备数据
source_python("prepare_data.py")
# 在R中处理并分析数据
df <- py_to_r(py_data)
r_result <- some_r_analysis(df)
# 将结果发送回Python进行进一步处理(如果需要)
py_run_string("import rpy2")
py_run_string("rpy2_result = rpy2.r.r_result")
```
在实际应用中,这种数据交互的方式可以用于机器学习模型的构建与预测,其中模型的训练和参数调整在Python中完成,而数据预处理和结果可视化则在R中进行。
### 5.1.2 与C++的性能优化
R语言虽然在数据分析方面表现出色,但在执行效率上,C++有着明显的优势,特别是在涉及到复杂算法和大数据量处理时。为了优化R代码的性能,可以将R与C++结合使用。
在R中,通过`Rcpp`包可以轻松地嵌入C++代码。首先安装`Rcpp`包:
```R
install.packages("Rcpp")
```
然后,创建一个C++的源文件,使用`sourceCpp()`函数将其编译并加载到R中。例如,下面的C++代码定义了一个计算阶乘的函数:
```C++
#include <Rcpp.h>
using namespace Rcpp;
// [[Rcpp::export]]
int factorial(int x) {
if (x == 0) return 1;
int result = 1;
for(int i = 1; i <= x; ++i) {
result *= i;
}
return result;
}
```
编译并加载到R会话中:
```R
sourceCpp("factorial.cpp")
```
这时,你可以在R中直接调用`factorial`函数了:
```R
factorial(5)
```
此外,可以使用Rcpp提供的ugar表达式,更方便地将R对象转换为C++对象,进行高效计算。
在Rcpp中编写代码时,需要注意数据类型转换和内存管理等问题。例如,R中的向量可以映射为C++中的`std::vector`,但是对这些数据结构的操作需要按照C++的规则来进行。
性能比较:
```R
# R语言的阶乘函数
factorialR <- function(x) {
if (x == 0) return(1)
fact <- 1
for(i in 1:x) {
fact <- fact * i
}
fact
}
# 性能测试
library(microbenchmark)
microbenchmark(
Rcpp = factorial(1000),
R = factorialR(1000),
times = 10
)
```
通常情况下,使用C++编写的函数在执行速度上会有显著提升。
## 5.2 R语言的并行计算与大数据分析
### 5.2.1 掌握foreach包的并行计算
并行计算是提高大规模数据分析效率的关键技术。在R中,`foreach`包提供了一种简单而强大的方式来实现并行计算。`foreach`允许你遍历数据集,并且可以轻松地并行化循环。
首先,安装并加载`foreach`和并行计算相关的包:
```R
install.packages("foreach")
install.packages("doParallel")
library(foreach)
library(doParallel)
```
接下来,创建一个并行后端,并注册到`foreach`:
```R
cl <- makeCluster(detectCores()) # 检测CPU核心数并创建集群
registerDoParallel(cl)
```
然后,可以使用`foreach`循环并加入`.combine`参数来控制输出结果的组合方式:
```R
foreach(i = 1:100) %dopar% {
sqrt(i)
}
```
在上面的例子中,100个开方计算任务被并行执行,这将显著减少整体计算时间。
### 5.2.2 使用Apache Spark进行大数据处理
R语言在处理大数据集时可能面临性能瓶颈,此时可以借助Apache Spark的分布式计算能力。`sparklyr`是连接R语言和Spark的桥梁,它为R用户提供了一系列便捷的函数来操作Spark数据框(DataFrames)。
首先,安装`sparklyr`包以及Apache Spark:
```R
install.packages("sparklyr")
library(sparklyr)
```
然后配置Spark连接:
```R
spark_install(version = "2.4.5") # 安装指定版本的Spark
sc <- spark_connect(master = "local", version = "2.4.5")
```
一旦连接上Spark,你就可以使用`dplyr`风格的语法来操作Spark的DataFrames:
```R
mtcars_spark <- copy_to(sc, mtcars)
result <- mtcars_spark %>%
filter(cyl == 8) %>%
select(mpg, wt)
```
最后,当完成计算后,记得关闭与Spark的连接:
```R
spark_disconnect(sc)
```
需要注意的是,与Spark的交互在初次设置时较为复杂,但一旦配置完成,就可以在R中处理大数据集,进行高效的数据分析工作。
在第五章中,我们深入探索了R语言与其他编程语言的交互方式以及如何利用并行计算提升R的性能。通过`reticulate`和`Rcpp`,我们可以将Python和C++的计算优势带入R语言,而`foreach`包的并行计算和`sparklyr`包的大数据分析,使得R在面对复杂和大规模数据集时依旧保持强劲的处理能力。这些高级功能不仅拓展了R的应用场景,而且大幅度提升了R语言在数据分析和处理中的效率和能力。
# 6. R语言环境问题解决与优化
## 6.1 常见R语言环境问题排查
在使用R语言进行数据分析和处理的过程中,我们可能会遇到各种环境问题,这些环境问题可能会导致程序无法运行、结果不准确甚至导致程序崩溃。因此,掌握一些常见的环境问题排查方法是非常有必要的。
### 6.1.1 R语言运行时错误的诊断与修复
运行时错误是R语言中最常见的问题之一。当遇到此类错误时,首先需要查看错误信息,通常错误信息会给出问题的线索。R语言的错误信息通常分为两类:语法错误和运行时错误。
- **语法错误**:这类错误通常在代码运行前就能被R语言解析器发现并给出错误提示,比如括号不匹配、变量未定义等。
- **运行时错误**:这类错误发生在代码执行过程中,可能涉及除零错误、文件不存在、数据类型不匹配等问题。
例如,当我们尝试在R语言中读取一个不存在的文件时,会遇到以下错误信息:
```r
read.table("nonexistent_file.txt")
# Error in file(file, "rt") : cannot open the connection
# In addition: Warning message:
# In file(file, "rt") : cannot open file 'nonexistent_file.txt': No such file or directory
```
从错误信息中可以看出,错误发生在打开文件连接时,提示没有这样的文件或目录。解决这个问题,需要检查文件路径是否正确,文件是否存在于该路径下。
### 6.1.2 包依赖问题的解决方法
R语言的强大之处在于其丰富的包生态系统。然而,包之间的依赖关系可能会引起一系列问题。例如,某个包可能依赖于其他包的特定版本,或者包之间的冲突可能会导致不可预期的行为。
解决包依赖问题,可以使用R语言的`install.packages`函数,确保所有依赖包都是最新的版本,或者使用专门的函数来安装特定版本的包。此外,有时候可能需要卸载并重新安装某些包来解决问题。
```r
# 安装特定版本的包
install.packages("package_name", version = "specific_version")
# 强制更新所有包
update.packages(ask = FALSE, checkBuilt = TRUE)
```
## 6.2 R语言性能优化策略
性能优化是数据科学实践中不可或缺的一部分。随着数据量的增加,优化R语言的性能变得尤为重要。性能优化可以从代码层面和环境配置两个层面进行。
### 6.2.1 代码层面的性能优化
在代码层面,我们可以通过以下策略来优化R语言的性能:
- **使用高效的数据结构**:例如,对于大型数据集,应优先使用`data.table`而不是`data.frame`。
- **避免不必要的复制**:在处理大数据时,尽量避免创建对象的复制,这可以通过引用传递或者使用函数式编程来实现。
- **向量化操作**:尽可能使用向量化操作代替循环,向量化操作可以显著提高代码的执行速度。
```r
# 使用向量化操作
x <- 1:1000000
y <- rnorm(1000000)
result <- x * y # 向量化乘法
# 避免使用循环的向量化替代方案
system.time({
result <- sapply(1:length(x), function(i) x[i] * y[i])
})
# 用户系统时间可能较长
system.time({
result <- x * y
})
# 用户系统时间较短,因为使用了向量化操作
```
### 6.2.2 环境配置对性能的影响分析
除了代码层面的优化,环境配置的调整也可以提升R语言的性能。例如,可以考虑以下几种方式:
- **内存管理**:增加R程序可用的内存,可以减少因内存不足导致的性能问题。
- **多核处理器的利用**:在现代操作系统中,可以配置R程序运行时使用多个CPU核心来并行处理任务。
R语言环境的优化是一个持续的过程,需要根据具体的应用场景和数据集大小来调整和优化。通过上述策略,我们可以显著提高R语言的执行效率,从而更好地服务于数据分析和数据科学项目。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0

专栏简介
欢迎来到 R 语言数据分析的全面指南!本专栏涵盖了从基础到高级的广泛主题,从环境搭建到数据可视化、统计分析、机器学习和文本挖掘。深入了解 R 语言数据包 PerformanceAnalytics 在金融分析中的应用,掌握数据清洗、数据类型和结构,以及数据操作的高级技巧。探索时间序列分析、聚类分析和线性回归的奥秘,提升您的数据处理效率和分析能力。本专栏旨在为初学者和经验丰富的用户提供丰富的知识和实用指南,帮助您充分利用 R 语言的强大功能,从数据中提取有价值的见解。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【状态机深度解析】:在Verilog中如何设计高效自动售货机
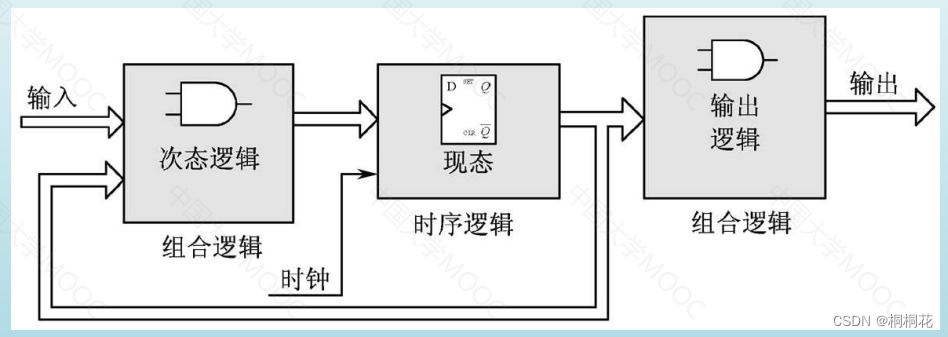
# 摘要
本文系统地探讨了状态机的设计与应用,首先介绍了状态机设计的基础知识,并详细阐述了在Verilog中实现状态机的设计原则,包括状态的分类、建模方法、状态编码及转换表的设计。接着,针对自动售货机的场景,本文详细描述了状态机的设计实现过程,包括用户界面交互、商品选择、货币处理和状态转换逻辑编写等。此外,还探讨了状态机的设计验证与测试,包括测试环境构建、仿真测试、调试和硬件实现验证。最后,本文提出了状态机优化的方法,并讨论了状态机在其他领域中的应
【MATLAB高级索引攻略】:解锁数据处理的隐藏技能

# 摘要
MATLAB作为一种高效的数据处理工具,其高级索引技术在数据科学领域发挥着重要作用。本文首先概述了MATLAB高级索引的基本概念与作用,随后深入探讨了索引操作的数学原理及数据结构。进一步,文章详细介绍了MATLAB高级索引实践技巧,包括复杂条件下的索引应用和高效数据提取与处理方法。在数据处理应用方面,本文阐述了处理大型数据集的索引策略、多维数据的可视化索引技术,以及M
C语言高级编程:子程序参数传递的全面解析
# 摘要
本文深入探讨了C语言中子程序参数传递的机制及其优化技术,首先概述了参数传递的基础知识,随后详细分析了按值传递和按引用传递的优缺点,以及在实现机制中的具体应用,包括内存中的参数布局、指针的作用和复合数据类型的传递。文章进一步探讨了高级参数传递技术,如指针的指针、const修饰符的使用以及可变参数列表的处理,并通过实践案例和最佳实践,讨论了在实际项目中应用这些技术的策略和技巧。本文旨在为C语言开发者提供系
【故障无忧】:西门子SINUMERIK 840D sl_828D测量循环问题全解析及解决之道

# 摘要
本文对西门子数控系统的核心组件SINUMERIK 840D sl/828D的测量循环功能进行了详尽的探讨。文章首先概述了测量循环的基本概念及其在制造业中的应用价值,然后详细介绍了测量循环的操作流程、编程指令以及高级应用技巧。通过故障分析章节,本文分类并识别了测量循环中常见的硬件和软件故障,提供了故障案例分析以及预防和监控策略。进一步地
数字签名机制全解析:RSA和ECDSA的工作原理及应用

# 摘要
本文全面概述了数字签名机制,详细介绍了公钥加密的理论基础,包括对称与非对称加密的原理和局限性、大数分解及椭圆曲线数学原理。通过深入探讨RSA和ECDSA算法的工作原理,本文揭示了两种算法在密钥生成、加密解密、签名验证等方面的运作机制,并分析了它们相对于传统加密方式
【CAD2002高级技巧】
# 摘要
本文对CAD2002软件进行全面的介绍和分析,从软件概述、界面布局、基础操作深入剖析,到绘图与编辑技巧实战,再到高级功能拓展以及优化与故障排除。文章详细阐述了CAD2002的工具与命令高级使用技巧、图层管理、块与外部参照应用等基础操作,深入探讨了精确绘图、高级编辑命令和综合绘图案例。此外,还介绍了CAD2002的参数化绘图、数据交换、自定义脚本编写等高级功能,以及性
Word 2016 Endnotes加载项疑难杂症:专家级解决方案
# 摘要
本文详细介绍了Word 2016中Endnotes功能的概述、工作原理、常见问题诊断以及应用实践,并展望了其发展。首先,对Endnotes功能进行了基础性的介绍,并探讨了其加载项的结构和作用。接着,分析了在使用Endnotes加载项时可能遇到的问题,包括不工作、冲突以及性能问题,并提
【搜索引擎查询优化】:提速与相关性提升的双重攻略

# 摘要
本文旨在综述搜索引擎查询优化的各个方面,从搜索引擎的工作原理、查询优化策略到实践案例分析,再到未来趋势。首先介绍了搜索引擎的基础工作流程,包括爬虫抓取、索引构建、查询处理和排名算法。随后,探讨了提升网页相关性、前端性能优化以及CDN和缓存机制的使用。案例分析部分深入研究了相关性改进、响应时间加
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )