




【JPA的NoSQL扩展实践】:Spring Data JPA与NoSQL案例研究

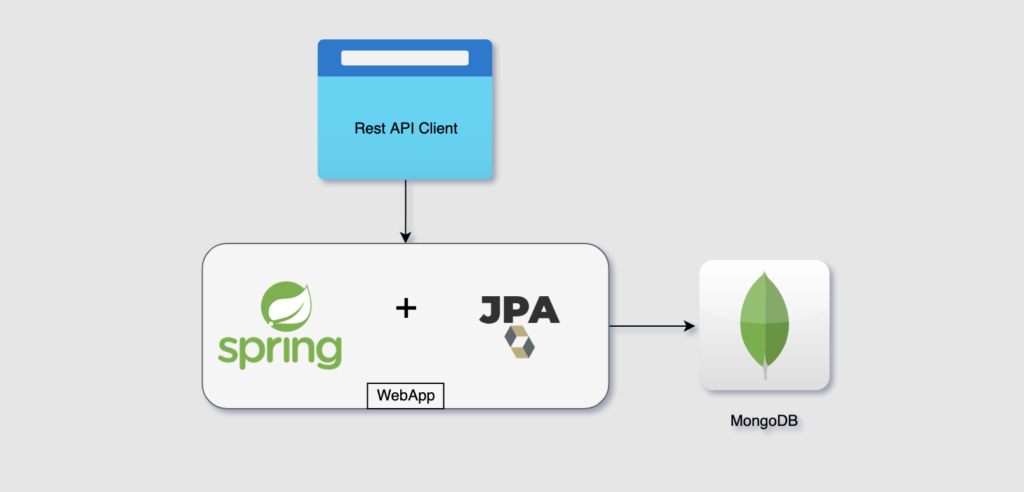
1. JPA与NoSQL的基础概念
1.1 JPA简介
Java持久层API(JPA)是Java EE规范之一,提供了对象/关系映射(ORM)功能,简化了Java应用程序中数据持久化的操作。通过JPA,开发者能够使用Java对象代表数据库表中的记录,利用其提供的接口和注解来管理这些对象的生命周期。
1.2 NoSQL数据库介绍
NoSQL数据库是非关系型的,不遵循传统关系模型的数据库,其设计用于处理大规模数据集,提高数据的扩展性和灵活性。它们支持多种数据模型,包括键值存储、文档存储、列存储和图数据库。NoSQL数据库常用于大数据、分布式系统和实时Web应用中。
1.3 JPA与NoSQL的集成意义
随着技术的发展,对于数据处理的需求也越来越高。JPA与NoSQL的结合为开发者提供了更多的选择,以适应各种应用场景。例如,文档型NoSQL数据库可以更自然地映射Java对象,而JPA则提供了标准化的ORM方法。这种集成不仅扩展了JPA的使用场景,也为NoSQL数据库提供了更为丰富的查询功能和事务支持。
本章的目标是为读者提供JPA和NoSQL的基础知识,为后续章节中深入探讨Spring Data JPA与NoSQL的集成、应用实践和挑战展望打下基础。在下一章,我们将详细分析Spring Data JPA的核心功能,并探讨如何利用这些功能来简化数据持久化的代码。
2. Spring Data JPA核心功能解析
2.1 JPA核心接口与注解
实体类和主键的映射
在Java持久化API(JPA)中,实体类映射是构建对象关系映射(ORM)的基础。每一个实体类通常对应数据库中的一个表,而实体的属性则映射到表中的列。为了标识一个类为JPA实体,需要使用@Entity注解,而每个实体的唯一标识符通常通过@Id注解来标注。
- import javax.persistence.*;
- @Entity
- @Table(name = "users")
- public class User {
- @Id
- @GeneratedValue(strategy = GenerationType.IDENTITY)
- private Long id;
- @Column(nullable = false)
- private String name;
- // Getters and Setters
- }
在上述代码示例中,User类被标注为JPA实体,与名为users的数据库表进行映射。id字段通过@Id注解标记为实体的主键,并且通过@GeneratedValue注解指定主键生成策略,这里是数据库自增。
主键可以使用多种策略生成,例如GenerationType.AUTO、GenerationType.TABLE等,具体的选择依赖于应用场景和数据库的特性。
实体关系映射(一对一、一对多)
在处理实体间关系时,JPA提供了一对一、一对多、多对一和多对多等多种映射方式。这些关系通过添加特定的注解来定义,例如:

在上述示例中,User和Profile通过一对一关系相连,User类通过@OneToOne注解引用了Profile类。CascadeType.ALL注解指明当User实体被持久化时,相关的Profile实体也应该被自动持久化。
而对于一对多的关系,可以使用@OneToMany和@ManyToOne注解。需要注意的是,一对一和一对多关系的处理中,通常涉及到外键约束以及级联操作的配置,这些配置对数据的一致性和完整性至关重要。
2.2 Spring Data JPA的仓库接口
CRUD操作的自动化
Spring Data JPA的仓库接口是其核心功能之一,这些接口极大简化了数据访问层的代码编写。开发者可以通过定义一些标准的方法,如findAll、findById、save等,就能自动实现基本的CRUD操作。
- public interface UserRepository extends JpaRepository<User, Long> {
- // 这里无需编写方法实现,因为JPA已经提供了默认实现
- }
上例展示了如何定义一个继承自JpaRepository的UserRepository接口。在这个接口中,我们没有编写任何方法实现,但是Spring Data JPA会自动提供这些方法的标准实现。开发者可以直接在业务逻辑中使用这些方法,进行实体的增删改查操作。
Spring Data JPA利用Java的泛型和反射机制来实现这一功能。它通过分析接口中定义的方法名称,自动创建该方法的实现。例如,save()方法可以用来保存或者更新一个实体,findAll()方法可以用来获取所有的实体。
自定义查询方法
虽然Spring Data JPA提供了一系列标准查询方法,但在实际应用中,我们往往需要根据特定的业务场景实现一些复杂的查询。为了处理这种情况,Spring Data JPA允许开发者自定义查询方法的名称,以实现复杂的查询逻辑。
- public interface UserRepository extends JpaRepository<User, Long> {
- List<User> findByName(String name);
- }
在这个例子中,findByName方法将根据name属性过滤用户实体。Spring Data JPA会分析方法名,并且生成相应的查询语句。如果方法名的解析无法匹配预定义的规则,则可以使用@Query注解直接编写JPQL或原生SQL语句。
开发者可以利用Spring Data JPA提供的命名规则来编写非常复杂的方法名称,并以此来实现复杂的查询逻辑。这大大简化了代码的编写,并提高了开发效率。
2.3 事务管理与并发控制
事务的配置与管理
在数据库操作中,事务管理是保证数据一致性的关键。Spring Data JPA提供了对声明式事务的全面支持,允许开发者通过简单的注解来配置和管理事务。
- import org.springframework.stereotype.Repository;
- import org.springframework.transaction.annotation.Transactional;
- import javax.persistence.EntityManager;
- import javax.persistence.PersistenceContext;
- @Repository
- @Transactional
- public class UserDAO {
- @PersistenceContext
- private EntityManager entityManager;
- public User saveUser(User user) {
- entityManager.persist(user);
- return user;
- }
- }
在上述代码中,UserDAO类被@Repository注解标记,表示它是一个数据访问对象。@Transactional注解用于方法上,表示该方法的执行是事务性的。任何在该方法内发生的数据库操作都将在同一个事务中执行,如果方法执行成功,所有的更改都会被提交到数据库,如果执行失败,则会回滚所有更改。
开发者可以通过@Transactional注解的属性来配置事务的行为,如隔离级别、传播行为和只读标志等。
并发控制的策略和实现
当多个应用程序或线程同时访问数据库时,确保数据的并发访问是正确无误的非常重要。JPA提供了一些机制来处理并发访问控制,例如乐观锁和悲观锁。
悲观锁通过在读取数据时锁定数据记录来避免并发问

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【3D IC互连技术:打破极限】:EDA工具的革新应用
【FPM383C_FPM383F自定义命令开发】:打造个性化指纹解决方案
掌握Zynq-7000 SoC双核架构:软件性能优化的终极武器
【云开发缓存策略】:提升小程序访问速度的数据缓存技术大揭秘!
U-Boot SPI通信协议:原理解析与实现(权威指南)
【功能增强秘籍】:PPT计时器Timer1.2扩展功能的实现
【航空领域的革命】:空气动力学的实践应用与未来趋势
跨平台部署无压力:组态王日历控件的解决方案
鸿蒙系统版网易云音乐国际化战略:多语言与本地化挑战应对之道
【运营流程优化】:HIS工作流管理的核心策略


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )





















