Linux操作系统终极指南
发布时间: 2024-12-09 14:54:00 阅读量: 6 订阅数: 14 

《Linux操作系统命令全攻略》图解手册

# 1. Linux操作系统的起源与发展
Linux操作系统的历史始于1991年,由芬兰大学生林纳斯·托瓦兹(Linus Torvalds)创建。当时,托瓦兹为了在个人电脑上运行类Unix系统,启动了一个小项目,该系统的代码通过互联网共享,随后逐渐吸引了全球的程序员和爱好者加入开发。
Linux的名称来自于其创始人Linus Torvalds和Unix的命名方式,操作系统内核被命名为Linux内核。随着时间的发展,Linux逐渐演变成一个完整的操作系统,成为开源软件的标志性项目。它的核心设计理念是自由和开源,鼓励用户可以自由地使用、复制、修改、分发。
Linux操作系统的发展分为两个阶段:早期的Linux系统主要用于服务器和嵌入式设备,随着技术的演进,Linux系统逐渐进入个人桌面领域。今天,Linux系统在服务器端、云计算、移动设备(Android系统)、嵌入式设备等众多领域扮演着重要角色。
Linux的普及也与众多的社区和组织的工作密不可分,如GNU项目,为Linux提供了丰富的软件和工具,使得Linux系统成为功能全面的桌面操作系统。此外,各种发行版的出现,比如Red Hat、Ubuntu、Fedora等,都极大地促进了Linux在企业和个人用户中的广泛采用。
# 2. Linux系统核心组件分析
### 2.1 Linux内核架构
#### 2.1.1 内核的功能与作用
Linux内核是Linux操作系统的核心组件,它在操作系统中承担着至关重要的角色。内核负责管理计算机硬件资源,并提供程序运行的环境。从文件系统的访问到网络通信,再到进程的调度,内核提供了所有这些操作的底层支持。
内核作为硬件和软件之间的桥梁,可以执行以下功能:
1. **进程管理**:内核负责进程的创建、执行、调度和销毁。它决定了哪个进程拥有CPU的控制权,以及哪个进程应当获得执行。
2. **内存管理**:内核管理着内存分配,确保程序运行时有足够的空间,同时对内存使用进行优化和保护,避免不同进程的内存区域发生冲突。
3. **文件系统**:内核提供了对各种文件系统的支持,允许用户和程序访问存储设备上的数据。
4. **设备驱动**:内核包含了对硬件设备支持的代码,即驱动程序,使得操作系统能够与硬件设备通信。
5. **网络通信**:内核管理网络连接,允许计算机之间进行数据交换。
#### 2.1.2 内核版本与发行版关系
Linux内核版本分为稳定版和开发版,其中稳定版适用于生产环境,而开发版则用于新功能的实验和测试。Linux发行版通常会根据自己的需求选择相应的稳定内核版本,并加入特定的补丁、驱动程序和定制功能。
内核版本更新通常遵循以下格式:主版本号.次版本号.修订号-后缀。
- **主版本号**:表示重大变更或者新体系架构的支持。
- **次版本号**:偶数表示稳定版,奇数表示开发版。
- **修订号**:每次更新都会增加。
- **后缀**:表示补丁级别的更新,例如rc表示候选发布版本。
发行版基于内核版本,但通常会有自己的命名方式。例如,Ubuntu的LTS(长期支持)版本在稳定版的基础上增加了额外的长期支持。
### 2.2 文件系统与目录结构
#### 2.2.1 标准文件系统的结构
Linux文件系统遵循统一的标准,这个标准定义了文件系统的层级结构和目录命名规范。这些规范在文件系统设计中非常关键,它们确保了不同Linux发行版之间的兼容性和可预测性。
Linux系统通常采用树状结构组织文件和目录,最顶层的目录表示为根目录("/")。根目录下包含了各种子目录,每个目录都有其特定的用途,例如:
- **/bin**:基本命令的二进制文件,如`ls`, `cp`, `mv`等。
- **/etc**:配置文件存放目录。
- **/home**:用户主目录。
- **/proc**:系统运行时的进程信息和内核配置。
- **/var**:经常变化的文件,如日志文件等。
- **/dev**:设备文件。
- **/lib**:系统库文件。
- **/boot**:启动加载程序和内核。
- **/opt**:可选的应用软件包。
- **/usr**:用户程序和数据。
- **/tmp**:临时文件存储。
#### 2.2.2 目录层次标准(FHS)
为了促进不同Linux发行版之间的兼容性和一致性,FHS(Filesystem Hierarchy Standard)标准被制定出来。它详细描述了文件系统应该如何组织,尤其是根目录和主要子目录的结构和内容。
- **必须包含的目录**:/bin, /sbin, /etc, /lib, /dev, /proc, /sys, /var, /tmp, /usr, 和 /boot。
- **推荐包含的目录**:/home, /root, /media, /mnt, /opt, 和 /srv。
- **可选的目录**:/selinux。
#### 2.2.3 文件系统的挂载与管理
在Linux中,文件系统可以通过挂载点(mount point)挂载到目录树的某个点上。通过`mount`命令可以将不同的存储设备挂载到指定的目录,使用户可以访问存储在其中的文件。
例如,挂载一个USB设备可以使用以下命令:
```bash
sudo mount /dev/sdb1 /mnt/usb
```
这里`/dev/sdb1`代表USB设备的分区,`/mnt/usb`是挂载点。一旦挂载,USB设备上的文件系统就可以通过`/mnt/usb`访问。
挂载点可以是系统中存在的任何空目录,或者可以临时创建一个目录来挂载新设备。
卸载文件系统,可以使用`umount`命令:
```bash
sudo umount /mnt/usb
```
如果遇到卸载失败的情况,可能是因为目录正在被使用。确保没有用户或进程在使用挂载点,然后再执行卸载操作。
### 2.3 进程管理
#### 2.3.1 进程的概念和分类
在Linux系统中,进程是执行中的程序实例。系统进程可以分为几个主要类别:
- **系统进程**:由系统启动时自动运行的程序,通常包括系统服务和守护进程。
- **用户进程**:由用户登录系统后启动的程序。
- **孤儿进程**:父进程结束,但子进程继续运行的进程。
- **守护进程**:后台运行的进程,通常用于提供系统服务。
进程可以在不同的状态之间切换,常见的状态包括:
- **运行态**:进程正在CPU上执行。
- **等待态**:进程等待分配给它的CPU时间。
- **停止态**:进程被挂起,停止执行。
- **僵尸态**:进程已完成执行但其父进程尚未获取其退出状态。
#### 2.3.2 进程调度与优先级
Linux内核中的进程调度器负责管理进程的执行。调度器的目的是决定哪个进程获得CPU资源以及何时获得。
调度器会根据进程的优先级来分配CPU时间。在Linux中,优先级可以手动设置或由系统动态调整。优先级较高的进程将更有可能获得执行。
可以通过`nice`和`renice`命令来调整进程的优先级:
```bash
nice -n 10 command
```
这个命令将以10的增量运行`command`,这意味着进程的优先级较低。
如果已经运行了进程,可以使用`renice`来改变它:
```bash
renice -n 10 -p <pid>
```
这里`<pid>`是进程ID,这将把该进程的优先级调整为10。
#### 2.3.3 进程监控与控制工具
有多个工具可以在Linux系统中用来监控和控制进程,包括`ps`, `top`, `htop`等。
`ps`命令可以显示当前运行的进程快照:
```bash
ps aux
```
这个命令将列出所有进程和它们的状态、CPU和内存使用等信息。
`top`命令以动态更新的方式显示进程信息:
```bash
top
```
运行`top`后,可以使用交互命令来排序或杀死进程,例如按`k`来杀死一个进程。
`htop`是一个更高级的进程查看器,提供了图形界面,并允许用户交互操作:
```bash
sudo apt install htop
htop
```
安装后,用户可以通过上下键选择进程,按`F9`来发送信号,比如`kill`。
监控和管理进程对于维护系统的健康和性能至关重要。通过这些工具,系统管理员可以确保系统平稳运行,及时响应任何问题。
# 3. Linux系统命令行深度使用
## 3.1 基本命令与Shell特性
### 3.1.1 常用命令的深入讲解
Linux命令行是IT专业人员的强大工具,它提供了无数的命令来执行各种各样的任务。深入理解这些命令对于有效地使用Linux至关重要。这一部分将深入讲解一些常用命令,并提供实用的例子来阐述其用法。
以`ls`命令为例,它被用来列出目录内容。`ls`的基本用法是:
```bash
ls [选项] [文件或目录]
```
- `-l`:列出详细信息,包括权限、所有者、文件大小等。
- `-a`:列出所有文件,包括隐藏文件。
- `-h`:与`-l`结合,以人类可读的格式(例如 KB、MB)显示文件大小。
一个示例命令:
```bash
ls -lha /var/log
```
这个命令将详细列出`/var/log`目录下的所有文件,包括那些隐藏文件,并以易读的格式显示文件大小。
使用`grep`命令可以在文件中搜索特定的字符串。基本语法是:
```bash
grep [选项] "搜索模式" 文件名
```
- `-r`:递归搜索子目录。
- `-i`:忽略大小写。
- `-n`:显示匹配行的行号。
例如,要搜索`/etc`目录下所有文件中的"error"文本,可以使用:
```bash
grep -rni "error" /etc
```
`grep`是一个非常强大的文本搜索工具,不仅限于静态文本文件,还可以与管道配合在动态输出中搜索。
另一个重要的命令是`find`,用于查找文件。其基本用法是:
```bash
find [起始目录] [选项] [搜索条件]
```
- `-name`:按文件名搜索。
- `-type`:指定搜索的文件类型,例如`-type f`搜索文件。
- `-mtime`:按最后修改时间搜索。
例如,要查找所有最近24小时内修改过的`.log`文件,可以使用:
```bash
find /var/log -name "*.log" -mtime 0
```
这些命令是Linux环境下数据管理与检索的核心工具,掌握它们会大幅提高处理文件和目录的效率。
### 3.1.2 Shell脚本编程基础
Shell脚本是组合和自动化Linux命令的重要工具。一个简单的Shell脚本通常以`#!/bin/bash`开头,这称为shebang行,指定了脚本应该用哪个解释器来执行。
以下是一个简单的Shell脚本示例:
```bash
#!/bin/bash
echo "Hello, World!"
```
脚本的第一行指定了使用Bash作为解释器。`echo`是Bash中用于输出文本到终端的命令。
变量是脚本编程中的另一个重要概念。在Bash中,变量声明不需要指定类型,赋值使用等号,例如:
```bash
name="John"
echo "Hello, $name!"
```
Bash还提供了条件语句和循环控制结构,这对于编写复杂的脚本至关重要。
条件语句可以使用`if`、`elif`、`else`来实现:
```bash
if [ -f "$file" ]; then
echo "$file exists."
elif [ -d "$file" ]; then
echo "$file is a directory."
else
echo "$file does not exist."
fi
```
循环控制结构包括`for`、`while`和`until`。例如,使用`for`循环遍历文件:
```bash
for file in ./*; do
echo "Processing $file"
# 在这里处理文件...
done
```
Shell脚本是一个非常强大的工具,通过实践可以掌握更多的细节和高级特性。
## 3.2 高级Shell技巧
### 3.2.1 管道与重定向深入
在Linux命令行中,管道(`|`)和重定向(`>` 和 `>>`)是常用的技巧,它们使得复杂的数据处理变得可能。管道允许将一个命令的输出作为另一个命令的输入,而重定向则允许将输出保存到文件或从文件读取输入。
管道的使用示例如下:
```bash
ls -l / | grep "^d"
```
在这个命令中,`ls -l /`命令的输出被`grep "^d"`命令用来搜索以'd'开头的行,这通常用于找出目录。
对于重定向,简单地使用`>`可以将命令的输出写入到文件中,而`>>`则会将输出追加到文件的末尾。例如,将错误信息重定向到一个日志文件:
```bash
command 2> errors.log
```
或者,追加输出到一个日志文件:
```bash
echo "This is a log entry." >> access.log
```
重定向不仅可以应用于文件,还可以应用于设备。例如,`/dev/null`是一个特殊的设备,它丢弃所有发送到它的数据。这可以用于"过滤掉"不需要的输出:
```bash
command 2> /dev/null
```
这个命令将标准错误输出丢弃,而不显示任何错误信息。
另一个有趣的重定向技巧是使用`tee`命令,它可以同时读取标准输入,并将其内容输出到标准输出和一个或多个文件:
```bash
ls | tee files.txt
```
这个命令会列出当前目录下的文件,并且显示在终端上,同时也将文件名保存到`files.txt`中。
通过这些高级技巧的组合使用,可以对数据流进行复杂的处理,这也是Linux命令行强大的原因之一。
### 3.2.2 文本处理工具(grep, awk, sed)
文本处理是Linux命令行中的一个重要领域,其中`grep`、`awk`和`sed`是三大利器。这些工具能够处理文本数据,并执行复杂的模式匹配和数据转换。
**grep**
`grep`是最常用的文本搜索工具之一,它能够搜索文件中的字符串,并返回匹配的行。如前所述,`grep`支持正则表达式,这使得它能够进行复杂的模式匹配。
```bash
grep -i "error" /var/log/syslog
```
这个命令会搜索`/var/log/syslog`文件中的所有包含"error"的行,`-i`选项忽略大小写。
**awk**
`awk`是一个强大的文本分析工具,它允许对输入的文本文件进行复杂的模式扫描和处理。`awk`的基本语法是:
```bash
awk '模式 {操作}' 文件名
```
例如,以下命令会打印出`/etc/passwd`文件中属于用户"root"的行:
```bash
awk -F':' '$1=="root" {print $0}' /etc/passwd
```
这里`-F':'`设置字段分隔符为冒号,`$1=="root"`是一个模式,检查每行的第一个字段是否为"root",如果是,`{print $0}`则打印整行。
**sed**
`sed`是"流编辑器",可以执行基本的文本转换。它对输入的文本进行读取,并将输出到标准输出。`sed`的基本用法是:
```bash
sed 's/原字符串/新字符串/' 文件名
```
例如,以下命令将`/var/log/syslog`文件中所有的"error"替换为"ERROR":
```bash
sed -i 's/error/ERROR/g' /var/log/syslog
```
这里`-i`选项表示直接修改文件内容,`s/原字符串/新字符串/g`表示将所有出现的原字符串替换为新字符串。
这三个工具都是命令行文本处理的强大武器,熟练使用它们可以大幅提高数据处理的效率。
## 3.3 系统安全与权限控制
### 3.3.1 用户和组管理
在Linux系统中,用户和组管理是保证系统安全的核心组成部分。通过管理用户账户和组,可以控制对文件、目录和其他资源的访问权限。
**用户管理**
管理用户账户的基本命令包括`useradd`、`usermod`和`userdel`。`useradd`用于添加新用户,`usermod`用于修改现有用户账户的信息,`userdel`用于删除用户账户。
例如,创建一个新用户"newuser":
```bash
sudo useradd newuser
```
这将创建一个新用户,并分配一个默认的用户ID和组ID。为了给新用户设置初始密码,可以使用:
```bash
sudo passwd newuser
```
**组管理**
组管理用于将多个用户分组,以简化权限管理。`groupadd`、`groupmod`和`groupdel`命令分别用于添加、修改和删除组。
例如,创建一个名为"newgroup"的组:
```bash
sudo groupadd newgroup
```
将用户添加到组可以通过`usermod`命令实现:
```bash
sudo usermod -aG newgroup newuser
```
这里`-aG`选项表示将用户添加到附加的组中。
用户和组管理工具对于维护系统的用户环境至关重要,它们确保了良好的访问控制,有助于防止未授权访问和其他安全问题。
### 3.3.2 权限设置与安全策略
在Linux中,每个文件和目录都有所有者、所属组和其他用户三种不同类型的用户。系统使用权限位来定义这三类用户对文件或目录可以执行的操作。权限位包括读(r)、写(w)和执行(x),分别用数字4、2和1表示。
权限的设置可以通过`chmod`命令来修改:
```bash
chmod 755 file
```
这个命令将`file`的权限设置为所有者可以读、写和执行,所属组和其他用户可以读和执行。
除了`chmod`,`chown`命令用于改变文件的所有者:
```bash
sudo chown newuser:file
```
这将把`file`的所有权改为用户`newuser`。
`setfacl`命令用于设置文件的访问控制列表(ACL),这为更细致的权限控制提供了可能:
```bash
setfacl -m u:newuser:rw file
```
这个命令为用户`newuser`授予了对`file`的读写权限,即使该文件的权限默认不允许该用户访问。
综合使用这些权限设置工具,可以构建一个安全可靠的Linux系统环境,保证数据安全和访问控制的需要。
总结来说,本章涵盖了Linux系统命令行的高级使用技巧,包括基本命令与Shell编程、文本处理工具的深入应用以及系统安全与权限控制策略。通过学习这些知识,用户可以更有效地利用Linux系统,提高工作效率,保证数据安全。
# 4. Linux系统网络与服务配置
## 4.1 基础网络配置与故障排除
### 4.1.1 网络接口的配置
Linux 系统中,网络接口的配置通常是通过配置文件来完成的,位于 `/etc/network/` 目录下,最常见的配置文件是 `interfaces`。配置文件中的每个网络接口可以定义多个参数,例如 IP 地址、子网掩码、默认网关以及使用的 DNS 服务器地址。
例如,一个典型的以太网接口配置可能如下所示:
```shell
auto eth0
iface eth0 inet static
address 192.168.1.100
netmask 255.255.255.0
gateway 192.168.1.1
```
- `auto eth0`:表示在系统启动时自动配置接口。
- `iface eth0 inet static`:定义了接口(eth0)使用静态 IP 地址配置。
- `address`:分配给接口的 IP 地址。
- `netmask`:子网掩码。
- `gateway`:默认网关地址。
编辑完配置文件后,需要重启网络服务以应用更改。这可以通过执行如下命令完成:
```shell
sudo systemctl restart networking
```
### 4.1.2 网络诊断工具
网络的诊断是保证网络服务可用性的重要步骤。Linux 提供了大量的诊断工具,如 `ping`、`ifconfig`、`netstat`、`ss` 和 `traceroute` 等。这些工具在不同的层面帮助诊断网络问题。
- `ping`:用于测试网络的连通性。例如,检查与 Google 的 DNS 服务器(8.8.8.8)的连通性:
```shell
ping -c 4 8.8.8.8
```
- `ifconfig` 或 `ip`:用于显示或配置网络接口的信息。
```shell
# 使用 ifconfig 查看 eth0 网络接口的状态
ifconfig eth0
# 使用 ip 命令查看
ip addr show eth0
```
- `netstat`/`ss`:用于查看网络连接、路由表、接口统计等信息。
```shell
# 显示所有 TCP 连接
netstat -tulnp
# 使用 ss 替代 netstat,显示所有 TCP 连接
ss -tulnp
```
- `traceroute`:用于追踪数据包到达目的主机所经过的路由路径。
```shell
traceroute google.com
```
## 4.2 服务器服务与应用
### 4.2.1 Web服务器(Apache, Nginx)部署
在 Linux 系统上部署一个 Web 服务器是实现在线服务的基础。Apache 和 Nginx 是两种流行的 Web 服务器软件。
#### Apache HTTP 服务器
Apache 是一种广泛使用的开源 Web 服务器。在 Linux 系统上部署 Apache 可以通过包管理器来完成:
```shell
sudo apt-get update
sudo apt-get install apache2
```
安装完成后,Apache 通常会启动并自动配置为在系统启动时运行。可以通过以下命令控制 Apache 服务:
```shell
# 启动 Apache 服务
sudo systemctl start apache2
# 停止 Apache 服务
sudo systemctl stop apache2
# 重启 Apache 服务
sudo systemctl restart apache2
# 设置 Apache 服务开机自启
sudo systemctl enable apache2
```
Apache 的配置文件位于 `/etc/apache2/` 目录下,主要的配置文件是 `apache2.conf`,而针对虚拟主机的配置通常在 `/etc/apache2/sites-available/` 目录中。
#### Nginx 服务器
Nginx 是另一种高性能的 Web 服务器和反向代理服务器。其安装过程与 Apache 类似,但配置文件结构有所不同。
```shell
sudo apt-get update
sudo apt-get install nginx
```
Nginx 的配置文件通常位于 `/etc/nginx/nginx.conf`,以及 `/etc/nginx/sites-available/` 目录下。Nginx 启动、停止和重启的命令与 Apache 类似,使用 `systemctl` 控制。
### 4.2.2 数据库服务(MySQL, PostgreSQL)配置
数据库服务是 Web 应用的基础。MySQL 和 PostgreSQL 是两种流行的开源数据库管理系统。
#### MySQL 数据库服务器
在 Linux 上安装和配置 MySQL 可以使用以下命令:
```shell
sudo apt-get update
sudo apt-get install mysql-server
sudo mysql_secure_installation
```
安装过程中,`mysql_secure_installation` 脚本会提示你设置 root 密码、删除匿名用户、禁止 root 用户远程登录等。
配置 MySQL 的配置文件通常位于 `/etc/mysql/my.cnf` 或 `/etc/mysql/mysql.conf.d/` 目录下。在配置文件中,你可以定义各种服务器设置,比如最大连接数、表缓存大小等。
启动 MySQL 服务:
```shell
sudo systemctl start mysql
sudo systemctl enable mysql
```
#### PostgreSQL 数据库服务器
安装 PostgreSQL 通常使用以下命令:
```shell
sudo apt-get update
sudo apt-get install postgresql postgresql-contrib
```
PostgreSQL 默认创建一个名为 postgres 的操作系统用户作为数据库管理员。你可以使用它来登录并进行进一步的配置:
```shell
sudo -u postgres psql
```
PostgreSQL 的主要配置文件位于 `/etc/postgresql/<version>/main/` 目录下,其中 `<version>` 表示 PostgreSQL 的版本号。
启动 PostgreSQL 服务:
```shell
sudo systemctl start postgresql
sudo systemctl enable postgresql
```
### 4.2.3 文件共享服务(Samba, NFS)实施
Linux 系统中文件共享服务是必不可少的组件,尤其是 Samba 和 NFS 两种网络文件共享协议。
#### Samba 文件共享
Samba 是在 Linux 和 Windows 系统间实现共享的一种方式,允许用户在 Linux 服务器和 Windows 客户端之间共享文件和打印服务。
安装 Samba:
```shell
sudo apt-get install samba
```
配置 Samba 的主要配置文件是 `/etc/samba/smb.conf`。你需要定义共享部分,例如:
```shell
[Share]
path = /home/share
writable = yes
guest ok = yes
read only = no
```
然后重启 Samba 服务来应用更改:
```shell
sudo systemctl restart smbd
```
#### NFS 文件共享
网络文件系统(NFS)是另一种在多个系统之间共享文件的方法。NFS 的安装和配置可以通过以下步骤完成:
安装 NFS 服务器:
```shell
sudo apt-get install nfs-kernel-server
```
配置 NFS 的主要文件是 `/etc/exports`。定义共享目录:
```shell
/home/nfs 192.168.1.0/24(rw,sync,no_subtree_check)
```
表示允许来自子网 192.168.1.0/24 的机器访问 `/home/nfs` 目录,并拥有读写权限。
最后,重新加载 NFS 配置以应用更改:
```shell
sudo exportfs -a
sudo systemctl restart nfs-kernel-server
```
## 4.3 系统监控与性能调优
### 4.3.1 系统监控工具(top, htop, vmstat)
系统监控是管理服务器健康的关键部分。Linux 提供了多种监控工具来帮助管理员观察系统状态。
#### top 命令
`top` 命令提供了一个实时的系统状态视图,包括 CPU、内存使用情况,以及运行中的进程等信息。
```shell
top
```
输出信息会定期刷新,你可以通过按 `k` 键来杀掉某个进程,或者按 `f` 键进入筛选模式等。
#### htop 命令
`htop` 是 `top` 命令的一个增强版本,它提供了更多的功能和更友好的用户界面。
```shell
sudo apt-get install htop
htop
```
`htop` 包括颜色编码的输出,可以显示进程树,允许通过鼠标或快捷键进行操作。
#### vmstat 命令
`vmstat` 提供了一个有关系统内存、交换区、I/O、系统进程、CPU 等的报告。
```shell
vmstat 1 5
```
上面的命令会每秒显示一次报告,共显示 5 次。
### 4.3.2 性能调优的基本方法和实践
性能调优是确保系统资源得到最佳利用的过程。以下是一些基本的性能调优实践:
#### 调整内核参数
修改 `/etc/sysctl.conf` 文件以调整内核参数:
```shell
net.ipv4.tcp_tw_recycle = 1
```
以上参数可以优化 TCP 连接,减少 TIME_WAIT 状态的连接数量。
#### 使用性能分析工具
使用如 `perf` 或 `perf_events` 这样的工具来分析系统的性能瓶颈:
```shell
sudo perf top
```
#### 调整文件系统参数
例如,调整 ext4 文件系统的挂载参数:
```shell
/dev/sda1 /home ext4 defaults,noatime 0 0
```
在这里 `noatime` 参数可以提高文件系统的性能,因为它会禁止更新文件的最后访问时间。
#### 使用 cgroups 进行资源分配
cgroups(控制组)可以限制、记录和隔离进程组所使用的物理资源(如 CPU、内存、磁盘 I/O 等)。
```shell
# 创建一个名为 mygroup 的新 cgroup
sudo cgcreate -g cpu,memory:mygroup
# 将一个进程添加到 mygroup
sudo cgclassify -g cpu,memory:mygroup <pid>
```
通过上述调整,可以针对特定应用程序的需要,优化资源使用,并确保系统平稳运行。
# 5. Linux系统自动化与虚拟化技术
随着企业对于系统管理效率和资源利用率的持续追求,自动化和虚拟化成为了Linux系统管理中的重要课题。通过这些技术,IT团队能够以更少的精力管理更多的资源,提高系统的灵活性和可靠性。
## 5.1 自动化部署工具
自动化部署工具可以显著降低重复性工作负担,提高工作效率。我们将重点介绍两种流行的自动化部署工具:Ansible和Puppet,以及基于Python的自动化工具Fabric和SaltStack。
### 5.1.1 配置管理工具(Ansible, Puppet)
**Ansible**
Ansible是一种自动化运维工具,使用Python编写,其最大的特点是无需在目标主机上安装客户端,直接使用SSH进行控制,非常适合快速部署。
```yaml
# Ansible Playbook 示例
- name: 配置Web服务器
hosts: web_servers
become: yes
tasks:
- name: 安装Apache
apt:
name: apache2
state: present
- name: 启动Apache服务
service:
name: apache2
state: started
enabled: yes
```
**Puppet**
Puppet采用声明式语言编写配置文件,通过客户端-服务器模型管理配置。Puppet Master推送配置到Puppet Agent。
```puppet
# Puppet Manifest 示例
file { '/var/www/html':
ensure => directory,
}
package { 'apache2':
ensure => present,
}
service { 'apache2':
ensure => running,
enable => true,
}
```
### 5.1.2 自动化脚本(Fabric, SaltStack)
**Fabric**
Fabric是一个Python库,主要用于简化SSH使用。它用于执行本地或远程shell命令,适合部署和维护任务。
```python
# 使用Fabric执行远程命令
from fabric.api import run
def deploy_app():
run('git pull') # 拉取最新代码
run('sudo ./deploy.sh') # 运行部署脚本
```
**SaltStack**
SaltStack采用事件驱动架构,支持快速、可扩展的远程执行命令和配置管理。
```yaml
# SaltStack State 示例
apache-install:
pkg.installed:
- name: apache2
apache-service:
service.running:
- name: apache2
- enable: True
- require:
- pkg: apache-install
```
## 5.2 虚拟化基础
虚拟化技术允许多个操作系统在单个物理机上并行运行,提高硬件利用率和灵活性。
### 5.2.1 虚拟化技术概览
目前主要的虚拟化技术包括全虚拟化、半虚拟化和操作系统级虚拟化。每种技术都有其适用场景和优缺点。
- **全虚拟化(例如VMware, VirtualBox)**:在没有修改客户操作系统的情况下提供完全隔离的虚拟机。
- **半虚拟化(例如Xen)**:需要修改客户操作系统以提高性能。
- **操作系统级虚拟化(例如Docker, LXC)**:共享宿主机的操作系统内核,适用于应用程序隔离。
### 5.2.2 KVM与QEMU的使用
**KVM (Kernel-based Virtual Machine)**
KVM是Linux内核的一个模块,它使用硬件虚拟化扩展(如Intel VT或AMD-V)来实现虚拟化。
安装KVM:
```bash
sudo apt-get install qemu-kvm libvirt-daemon-system libvirt-clients bridge-utils
```
使用virsh进行管理:
```bash
virsh list --all # 列出所有虚拟机
virsh start vm_name # 启动虚拟机
virsh destroy vm_name # 强制关闭虚拟机
```
**QEMU (Quick Emulator)**
QEMU是一个通用的开源机器模拟器和虚拟化器,可以模拟CPU、虚拟磁盘等设备。
创建虚拟机镜像:
```bash
qemu-img create -f qcow2 /var/lib/libvirt/images/debian.img 10G
```
启动QEMU虚拟机:
```bash
qemu-system-x86_64 -hda /var/lib/libvirt/images/debian.img
```
## 5.3 容器技术与Docker
容器技术是现代化应用分发、部署和管理的关键技术之一,它与虚拟机相比,具有更低的资源开销和更快的启动时间。
### 5.3.1 容器与虚拟机的比较
容器和虚拟机都提供了隔离的环境以运行应用程序,但它们在隔离级别和性能方面有所不同。
- **资源开销**:容器共享宿主机的内核,而虚拟机需要完整的操作系统。
- **性能**:容器的性能更接近宿主机,而虚拟机由于模拟硬件会有性能损耗。
- **启动时间**:容器可以几乎瞬间启动,而虚拟机需要更长时间。
### 5.3.2 Docker基础与应用案例
**Docker**
Docker是最流行的容器化平台,它使用容器来部署应用程序。Dockerfile定义应用程序的环境和依赖,而Docker Hub提供丰富的基础镜像。
构建Docker镜像:
```Dockerfile
# Dockerfile 示例
FROM ubuntu:18.04
RUN apt-get update && apt-get install -y \
curl \
&& rm -rf /var/lib/apt/lists/*
CMD [ "curl", "-s", "https://ipinfo.io/json" ]
```
运行Docker镜像:
```bash
docker build -t my-curl-image . # 构建镜像
docker run my-curl-image # 运行容器
```
在企业中,Docker可以用于简化开发环境的搭建,加快微服务架构的部署。例如,构建可部署的Java Web应用:
```bash
FROM openjdk:8-jdk-alpine
VOLUME /tmp
COPY target/my-web-app.jar app.jar
ENTRYPOINT ["java","-Djava.security.egd=file:/dev/./urandom","-jar","/app.jar"]
```
通过上述内容,我们深入探讨了Linux系统自动化和虚拟化技术的各个方面。从自动化部署工具到容器技术的实践,这些建立在强大Linux内核基础之上的技术,正在重塑现代IT基础设施的管理与运维。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了Linux操作系统中常见的难题,并提供了切实可行的解决方案。从内存管理的奥秘到故障诊断和恢复的技巧,再到内核编译和定制的指南,本专栏涵盖了广泛的主题。此外,它还提供了编写自动化脚本、开发内核模块和选择和配置Linux桌面环境的实用建议。通过深入浅出的讲解和实用的示例,本专栏旨在帮助Linux用户解决问题、优化系统性能并充分利用这一强大的操作系统。
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
PSS_E高级应用:专家揭秘模型构建与仿真流程优化
参考资源链接:[PSS/E程序操作手册(中文)](https://wenku.csdn.net/doc/6401acfbcce7214c316eddb5?spm=1055.2635.3001.10343)
# 1. PSS_E模型构建的理论基础
在探讨PSS_E模型构建的理论基础之前,首先需要理解其在电力系统仿真中的核心作用。PSS_E模型不仅是一个分析工具,它还是一种将理论与实践相结合、指导电力系统设计与优化的方法论。构建PSS_E模型的理论基础涉及多领域的知识,包括控制理论、电力系统工程、电磁学以及计算机科学。
## 1.1 PSS_E模型的定义和作用
PSS_E(Power Sys
【BCH译码算法深度解析】:从原理到实践的3步骤精通之路

参考资源链接:[BCH码编解码原理详解:线性循环码构造与多项式表示](https://wenku.csdn.net/doc/832aeg621s?spm=1055.2635.3001.10343)
# 1. BCH译码算法的基础理论
## 1.1
DisplayPort 1.4线缆和适配器选择秘籍:专家建议与最佳实践
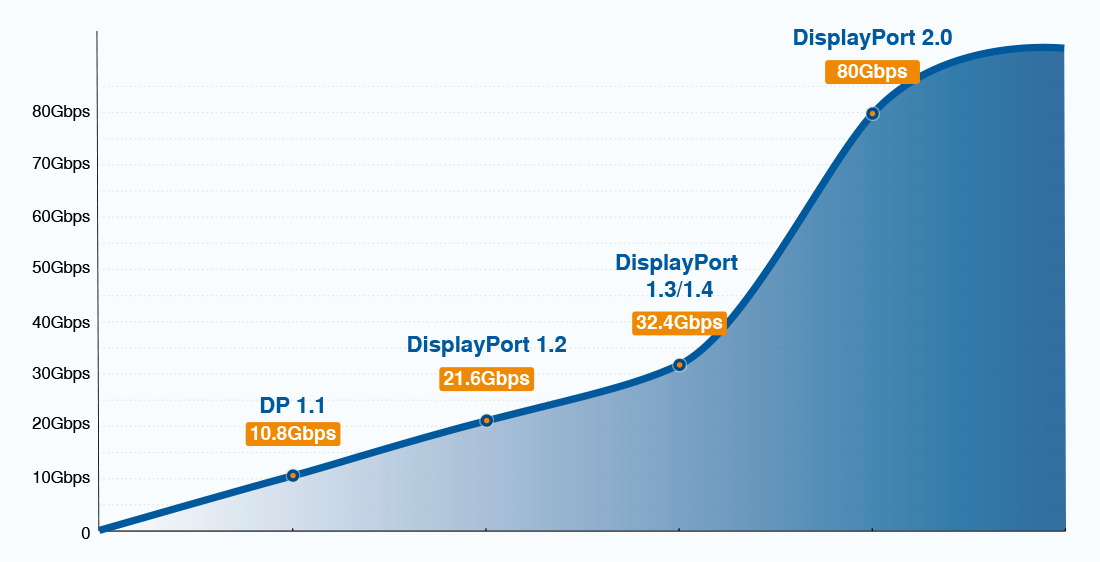
参考资源链接:[display_port_1.4_spec.pdf](https://wenku.csdn.net/doc/6412b76bbe7fbd1778d4a3a1?spm=1055.2635.3001.10343)
# 1. DisplayPort 1.4技术概述
随着显示技术的不断进步,DisplayPort 1.4作为一项重要的接
全志F133+JD9365液晶屏驱动配置入门指南:新手必读
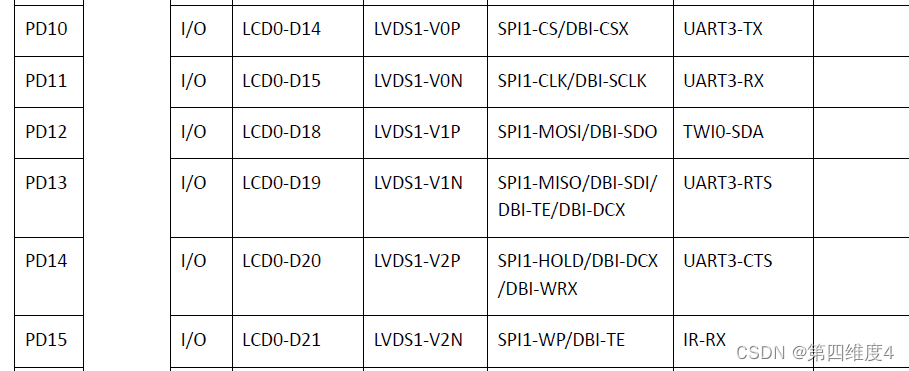
参考资源链接:[全志F133+JD9365液晶屏驱动配置操作流程](https://wenku.csdn.net/doc/1fev68987w?spm=1055.2635.3001.10343)
# 1. 全志F133与JD9365液晶屏驱动概览
液晶屏作为现代显示设备的重要组成部分,其驱动程序的开发与优化直接影响到设备的显示效果和用户交互体验。全志F133处理器与JD9365液晶屏的组合,是工
【C语言输入输出高效实践】:提升用户体验的技巧大公开
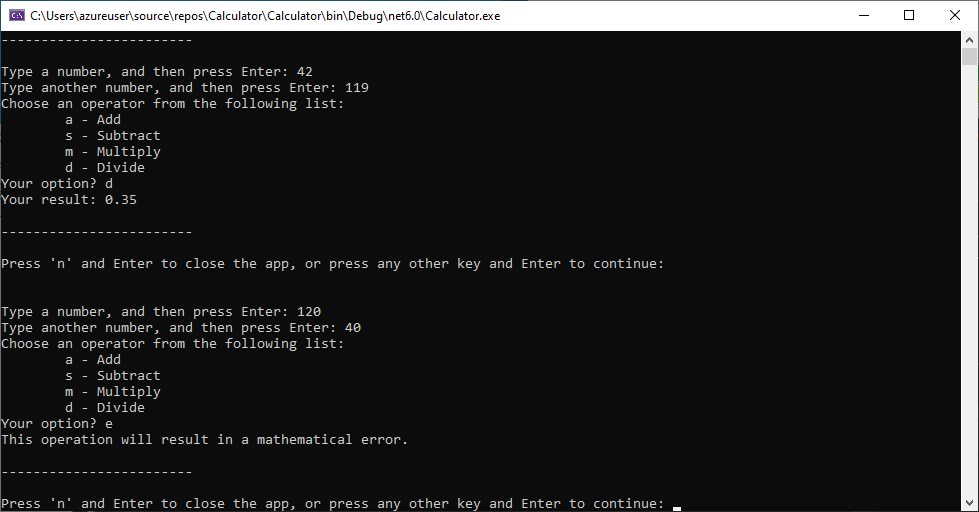
参考资源链接:[编写一个支持基本运算的简单计算器C程序](https://wenku.csdn.net/doc/4d7dvec7kx?spm=1055.2635.3001.10343)
# 1. C语言输入输出基础与原理
## 1.1 C语言输入输出概述
PowerBuilder性能优化全攻略:6.0_6.5版本性能飙升秘籍

参考资源链接:[PowerBuilder6.0/6.5基础教程:入门到精通](https://wenku.csdn.net/doc/6401abbfcce7214c316e959e?spm=1055.2635.3001.10343)
# 1. PowerBuilder基础与性能挑战
## 简介
PowerBuilder,一个由Sybase公司开发的应用程序开发工具,以其快速应用开发(RAD)的特性,成为了许多开发者的首选。然而
【体系结构与编程协同】:系统软件与硬件协同工作第六版指南
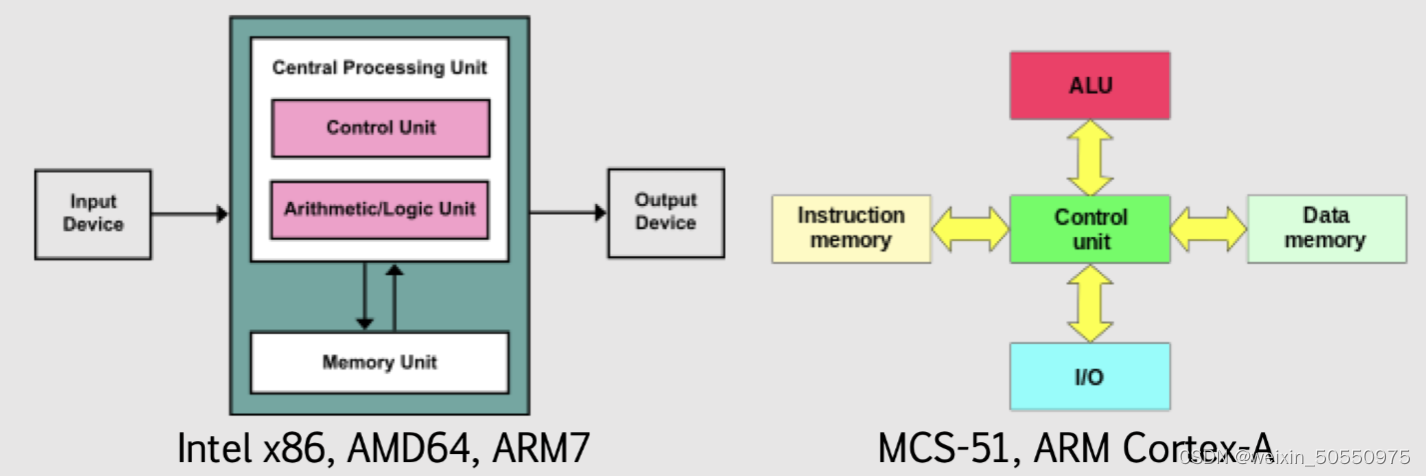
参考资源链接:[量化分析:计算机体系结构第六版课后习题解答](https://wenku.csdn.net/doc/644b82f6fcc5391368e5ef6b?spm=1055.2635.3001.10343)
# 1. 系统软件与硬件协同的基本概念
## 1.1 系统软件与硬件协同的重要性
在现代计算机系统中,系统软件与硬件的协同工作是提高计算机性能和效率的关键。系统软件包括操作系统、驱动
【故障排查大师】:FatFS错误代码全解析与解决指南

参考资源链接:[FatFS文件系统模块详解及函数用法](https://wenku.csdn.net/doc/79f2wogvkj?spm=1055.263
从零开始:构建ANSYS Fluent UDF环境的最佳实践
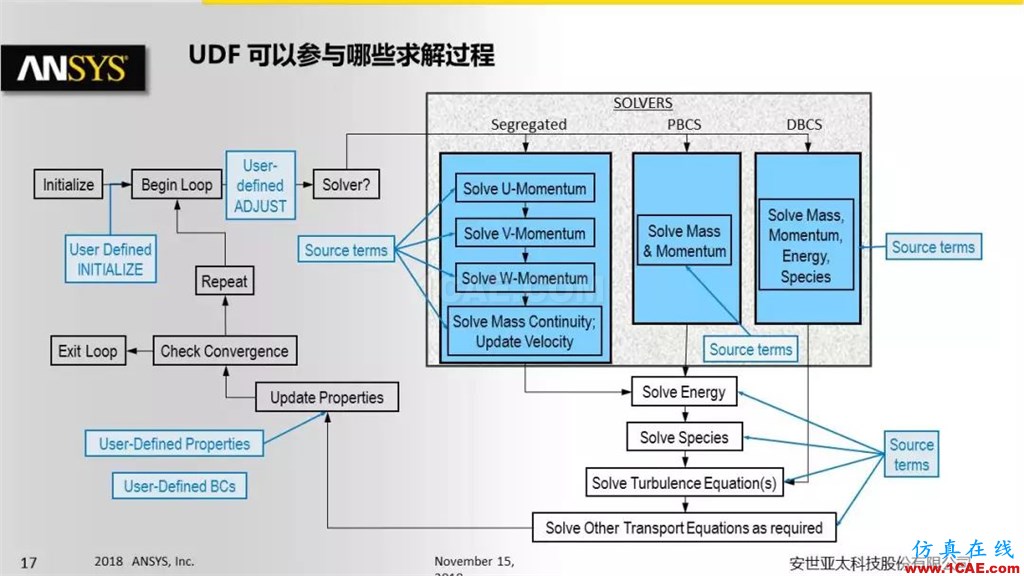
参考资源链接:[2020 ANSYS Fluent UDF定制手册(R2版)](https://wenku.csdn.net/doc/50fpnuzvks?spm=1055.2635.3001.10343)
# 1. ANSYS Fluent UDF基础知识概述
## 1.1 UDF的定义与用途
ANSYS Fluent UDF(User-Defined Functions)是一种允许用户通
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )