CDO工具入门至精通:Climate Data Operators全面使用攻略
发布时间: 2024-12-14 14:52:31 阅读量: 10 订阅数: 8 

CDO相关文档(climate data operators)
参考资源链接:[CDO用户指南:处理NC格式气候数据](https://wenku.csdn.net/doc/1wmbk5hobf?spm=1055.2635.3001.10343)
# 1. CDO工具的简介与安装
## 1.1 CDO工具概述
CDO(Climate Data Operators)是一套用于处理和分析气候数据的命令行工具集,广泛应用于气候科学领域。它提供了一系列功能强大的命令,用于数据的统计、比较、插值和转换等多种数据处理操作。CDO工具支持多种数据格式,比如GRIB、NetCDF、HDF等,并能处理大规模数据集。
## 1.2 安装CDO
CDO的安装过程依操作系统不同而有所差异。对于大多数Linux发行版,可以通过包管理器安装。例如,在Ubuntu上,可以通过以下命令安装:
```bash
sudo apt-get install cdo
```
对于MacOS,可以通过Homebrew进行安装:
```bash
brew install cdo
```
对于Windows用户,推荐使用预编译的二进制文件进行安装。
## 1.3 验证安装
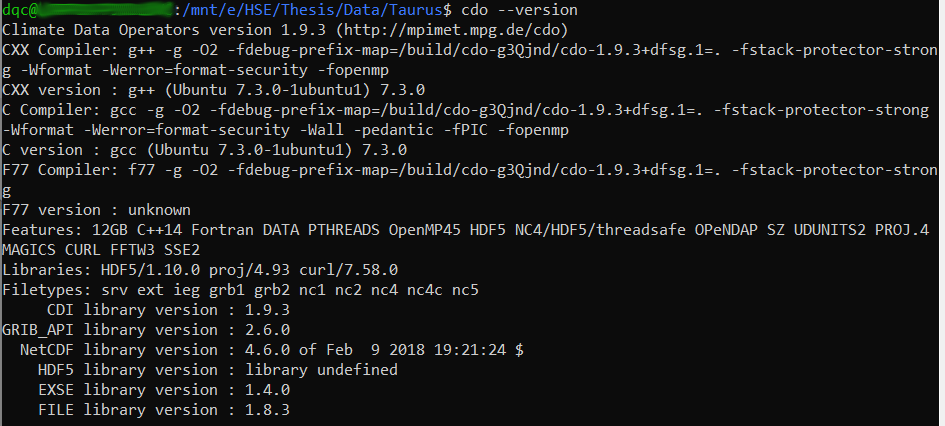
安装完成后,可以通过执行简单的命令来验证安装是否成功。运行以下命令,如果系统返回版本信息,则表明安装成功:
```bash
cdo -v
```
在接下来的章节中,我们将深入探讨CDO的基础操作和高级应用。
# 2. CDO基础操作
在深入探讨CDO(Climate Data Operators)工具的强大功能之前,了解其基础操作对于任何级别的用户来说都是至关重要的。本章节将详细介绍数据集的处理、变量操作以及时间操作等基础操作,使用户能够熟练地对数据进行操作和分析。
## 2.1 数据集的基本操作
数据是任何分析工作的基石,而CDO提供了一套强大的工具来导入、导出、查看和修改数据集属性。这些操作是后续复杂数据处理和分析工作的基础。
### 2.1.1 数据导入与导出
在数据处理之前,首先需要将数据导入CDO环境中进行操作,同样地,在处理完成后,也需要将数据导出。CDO支持多种数据格式,如NetCDF、GRIB和HDF等。
```sh
cdo -f nc import data.grb output.nc
```
上述命令中,`-f nc`指定了输出格式为NetCDF,`import`是导入数据的命令,`data.grb`是源数据文件,`output.nc`是导入后的文件名。
导出操作与导入类似,只需将导入命令中的`import`替换为`export`即可。
### 2.1.2 数据集属性的查看与修改
数据集导入后,接下来是查看和修改数据集的属性。查看数据集的属性信息是理解数据集结构的关键一步。
```sh
cdo -s info output.nc
```
在上述命令中,`-s`是静默模式,`info`用于显示数据集的详细信息。
如需修改数据集属性,比如变量名或单位,可以使用`setname`和`setmissval`命令。
```sh
cdo setname,Temperature output.nc Temperature.nc
cdo setmissval,9999 output.nc output_m.nc
```
第一个命令将变量名从默认的`tos`改为`Temperature`,第二个命令设置缺失值为9999。
## 2.2 变量操作
数据集中通常包含多个变量,CDO提供了对变量进行定义、重命名、单位转换等操作的工具。
### 2.2.1 变量的定义与重命名
在数据处理前,需要准确识别和定义数据集中的变量。CDO允许用户根据需要重命名变量,以便更清晰地表示数据内容。
### 2.2.2 变量单位的转换
数据集中变量的单位可能是多样的,如摄氏度、华氏度或开尔文。为了统一处理,需要将单位转换到一个标准单位。
```sh
cdo mulc,0.1 output.nc output_celsius.nc
```
该命令将数据集中的温度单位从开尔文转换为摄氏度。
## 2.3 时间操作
时间是气候数据分析中不可或缺的维度,CDO提供了多种时间操作选项,如时间范围的选择、时间单位的转换和平滑处理。
### 2.3.1 时间范围的选择与设置
分析数据时,通常只需要数据集中的某个时间段。CDO允许用户根据需要选择特定的时间范围。
```sh
cdo -s selname,2001-01-01,2010-12-31,times output.nc output_timeselect.nc
```
上述命令选择并导出了2001年至2010年期间的时间序列数据。
### 2.3.2 时间单位的转换与平滑
时间单位的转换和平滑处理可以提高数据的可用性和准确性。
```sh
cdo yearmean output.nc output_yearmean.nc
```
该命令将数据集中的时间单位从具体日期转换为年平均值,非常适合进行气候趋势分析。
以上章节详细介绍了CDO的基础操作,包括数据集的导入导出、查看修改属性,变量的定义重命名和单位转换,以及时间范围的选择设置和平滑处理。在掌握了这些基础操作之后,用户便能够针对具体的数据集执行更加复杂的数据分析任务,为后续深入探索CDO的强大功能打下坚实的基础。接下来的章节将介绍CDO在数据处理方面的技巧,以及如何应用这些技巧进行气候数据分析。
# 3. CDO数据处理技巧
在现代数据分析中,对于数据的预处理和整理是至关重要的步骤,这关系到最终分析结果的质量和准确性。CDO(Climate Data Operators)作为一个强大的工具,提供了一系列数据处理功能,它帮助用户在气候科学和环境研究等领域中,对复杂的数据集进行高效管理和分析。第三章节将深入介绍CDO在数据处理方面的常用技巧,包括数据操作函数的使用、空间插值与重投影技术,以及统计与比较操作。
## 3.1 常用的数据操作函数
CDO提供了一系列基本而强大的数据操作函数,这些函数对于数据预处理和初步分析至关重要。我们将探索这些操作函数的基本原理和实际应用。
### 3.1.1 基本数学运算
数据处理中最基础的步骤之一就是执行数学运算,例如加、减、乘、除等。CDO中提供了这样的功能,允许用户对数据集进行各类数学运算,从而实现数据的标准化、归一化或转换。
```bash
cdo -f nc -setregrid,gridfile operator file1 file2 outputfile
```
上述命令演示了如何使用CDO进行基本的数学运算,其中`-setregrid`选项用于设置重网格化操作,`operator`是操作符,可以是`add`、`sub`、`mul`、`div`等,分别表示加、减、乘、除。`gridfile`是用于重网格化的网格文件,`file1`和`file2`是要操作的数据文件,`outputfile`是运算后的输出文件。
### 3.1.2 数据的筛选与合并
在处理数据时,经常需要从大量数据集中筛选出有用的信息,或是将多个数据集合并成一个。CDO提供了一系列操作,允许用户轻松地执行这些任务。
```bash
cdo -seldate,YYYY-MM-DD,YYYY-MM-DD -setmisstoc,9999 file inputfile outputfile
```
此例展示了如何使用`-seldate`选项进行时间筛选,`YYYY-MM-DD,YYYY-MM-DD`是筛选的起止日期。使用`-setmisstoc,9999`设置缺失值为9999。
```bash
cdo -mergetime file1 file2 file3 file4 outputfile
```
在上述命令中,`-mergetime`选项用于将多个时间序列的数据合并为一个数据集。
### 3.1.3 数据的聚合与平均
某些数据分析任务要求对数据集按照时间或空间进行聚合,以减小数据量或提取关键信息。CDO中可用于实现这一目标的函数如下:
```bash
cdo -tim平均 operator file1 file2 ... fileN outputfile
```
其中,`operator`可以是`time平均`、`time最小`、`time最大`等,用于按时间维度对数据进行聚合操作。`file1`到`fileN`是输入文件,`outputfile`是输出文件。
## 3.2 空间插值与重投影
空间插值与地图投影的转换是数据分析中常见的需求,尤其是在处理气候和地理数据时,往往需要将数据从一个坐标系统转换到另一个系统中,或者根据需求进行插值处理。
### 3.2.1 空间插值方法及应用
空间插值能够对基于网格的数据进行空间扩展,这在地理信息系统(GIS)中非常有用。在CDO中,用户可以使用不同的插值方法来获取新位置的估计值。
```bash
cdo -remapbil,rubelbilmap file inputfile outputfile
```
`-remapbil`选项是进行双线性插值重映射的命令,`rubelbilmap`是重映射文件,用于定义新和旧网格之间的关系。
### 3.2.2 地图投影的转换
不同的地图投影具有不同的特点和适用范围。CDO可以方便地进行地图投影的转换,以满足不同的数据分析和可视化需求。
```bash
cdo -remapcon,rubelconmap file inputfile outputfile
```
`-remapcon`选项用于进行圆柱投影的转换,`rubelconmap`是转换文件,用于定义新和旧投影之间的映射关系。
## 3.3 统计与比较操作
CDO还提供了多种统计和比较操作,这些是数据分析中不可或缺的部分。统计操作可以帮助我们了解数据集的基本统计特征,而比较操作则允许我们将不同数据集进行对比分析。
### 3.3.1 数据集的统计分析
统计分析包括计算平均值、最大值、最小值、标准差等。这些操作可以帮助用户快速了解数据集的基本特征。
```bash
cdo -timmean -timstd file inputfile outputfile
```
`-timmean`和`-timstd`分别用于计算时间平均值和时间标准差。
### 3.3.2 不同数据集的比较与对比
CDO允许用户对不同的数据集进行直接比较和对比,从而找出它们之间的差异或相似之处。
```bash
cdo -sub file1 file2 outputfile
```
上述命令展示了如何使用`-sub`选项进行数据集的相减操作,从而得到两者之间的差异。
通过以上各种操作,CDO不仅能够帮助用户处理复杂的气候科学数据,还能在环境研究、气象分析等多个领域发挥作用。CDO的灵活性和功能性使其成为一个强大的数据处理工具,对于需要处理地理空间和时间序列数据的研究者来说,是一个不可或缺的助手。
# 4. CDO在气候数据分析中的应用
## 4.1 气候数据的预处理
### 4.1.1 数据清洗与异常值处理
在气候数据分析中,数据清洗是一个至关重要的步骤。由于气候数据常常来自于各种来源和长期的观测,数据质量往往参差不齐。因此,进行数据清洗和处理异常值是保证分析结果准确性的基础。
进行数据清洗时,可以遵循以下步骤:
1. **识别缺失值**:使用CDO查看数据集中的缺失值,并决定如何处理它们。可以采取填充、删除或插值等方法。
2. **识别异常值**:通过统计分析(如箱型图分析)识别数据中的异常值。
3. **异常值处理**:对于识别出的异常值,根据情况决定是删除、修正还是保留。
在CDO中,我们可以使用`cdo`命令来处理数据。例如,删除所有包含缺失值的记录可以使用以下命令:
```bash
cdo -selltype,none -f nc filname_in.nc filename_out.nc
```
该命令会将所有缺失值类型变量的数据记录删除,因为`-selltype,none`告诉CDO不要使用任何含缺失值的变量,`-f nc`指定输出文件格式为NetCDF。
### 4.1.2 数据标准化与归一化
气候数据通常包含不同量纲和数量级的变量。为了消除量纲影响,便于分析和比较,常常需要进行数据的标准化和归一化处理。
1. **标准化(Z-score normalization)**:标准化是将数据转换为均值为0、标准差为1的分布,公式为`(x_i - μ) / σ`。
2. **归一化(Min-Max normalization)**:归一化是将数据缩放到一个特定范围,通常是[0, 1],公式为`(x_i - min(x)) / (max(x) - min(x))`。
在CDO中,虽然没有直接提供标准化和归一化的命令,但我们可以结合脚本语言(如Python或Shell脚本)来实现。以下是一个简单的Python示例,展示如何对数据进行归一化处理:
```python
import xarray as xr
# 加载数据集
ds = xr.open_dataset('filename.nc')
# 进行归一化处理
normalized_ds = (ds - ds.min()) / (ds.max() - ds.min())
# 保存处理后的数据集
normalized_ds.to_netcdf('normalized_filename.nc')
```
## 4.2 气候模型数据的操作
### 4.2.1 模型数据的读取与处理
气候模型生成的数据通常非常复杂,需要特定的工具和知识才能正确读取和处理。CDO工具在处理这类数据时表现出色,可以轻松读取和转换模型输出的多种格式数据。
读取和处理模型数据通常包括以下几个步骤:
1. **加载数据集**:使用CDO的`cdo sellonlatbox`或`cdo mergetime`等命令来提取模型数据集的感兴趣区域和时间段。
2. **转换数据格式**:如果模型数据不是NetCDF格式,则需要转换。CDO提供了一系列转换工具,如`cdo ncdump`将其他格式转换为NetCDF。
3. **数据预处理**:包括数据插值、重投影等操作,以满足进一步分析的需要。
以下是使用CDO读取模型数据的一个简单示例:
```bash
cdo -seldate,2023-01-01 -selyears,2023/2023 model_output.nc preprocessed_model_data.nc
```
该命令选择了一个具体日期(2023年1月1日)和一年的模型数据,然后保存为预处理后的数据集。
### 4.2.2 模型与观测数据的对比分析
模型数据和实际观测数据的对比是验证模型准确性的重要步骤。CDO提供了多种工具来帮助进行此类对比分析。
1. **数据对齐**:首先需要确保模型数据和观测数据的时间和空间分辨率对齐。
2. **偏差分析**:计算两者之间的差异,比如使用`cdo`的`sub`命令来计算差异。
3. **统计分析**:使用`cdo`的统计功能来进行更深入的分析,比如相关性分析、趋势分析等。
例如,计算模型数据与观测数据的偏差可以使用以下命令:
```bash
cdo sub model_data.nc observed_data.nc deviation.nc
```
该命令将模型数据和观测数据做减法,结果存储于`deviation.nc`文件中,该文件中每个位置都是两者的偏差值。
## 4.3 气候数据的趋势分析
### 4.3.1 趋势检测的方法
在气候数据分析中,检测数据中长期趋势对于理解气候变化至关重要。常用的趋势检测方法包括线性回归、非参数检验(如Mann-Kendall检验)等。
使用CDO进行趋势分析,可能涉及到以下步骤:
1. **时间序列提取**:首先,从气候数据集中提取出感兴趣的时间序列数据。
2. **趋势分析**:采用CDO的统计函数,比如`cdo trend`,来计算趋势。
3. **趋势可视化**:通过图表可视化趋势,帮助解释结果。
以下是CDO中使用趋势分析功能的一个示例:
```bash
cdo trend -timmean -yearmonmean data_in.nc trend.nc
```
该命令计算数据集的时间序列平均趋势,并将结果保存在`trend.nc`文件中。
### 4.3.2 趋势分析案例研究
为了更好地理解如何应用CDO进行气候数据的趋势分析,我们可以详细探讨一个案例研究。例如,假设我们要分析过去50年的全球平均温度变化趋势。
首先,我们会使用CDO提取所需时间段内的全球平均温度数据。然后,我们将使用CDO的趋势分析功能来计算温度随时间的变化情况。
下面是一个简化的分析流程:
1. 使用CDO命令提取特定时间段的全球平均温度数据。
2. 利用`cdo`的统计功能进行趋势分析。
3. 利用图形工具(如Python的matplotlib或R语言的ggplot2)绘制温度趋势图。
结合以上流程,CDO不仅能够帮助我们执行数据分析,而且通过与其他分析工具的结合使用,我们可以更全面地理解气候数据中的趋势。
# 5. CDO高级功能与定制化
## 5.1 高级脚本编写与批处理
### 5.1.1 脚本化数据处理流程
CDO(Climate Data Operators)提供了强大的脚本功能,允许用户将一系列的数据处理步骤整合到一个脚本文件中,实现复杂的数据处理流程的自动化。通过编写CDO脚本,可以方便地重复执行相同的数据处理任务,或者对不同的数据集进行批量处理,极大提高了工作效率。
脚本化数据处理流程通常包括数据读取、预处理、计算分析、输出结果等步骤。例如,要对一系列气候数据文件进行处理,包括去异常值、标准化处理、求平均等操作,可以将这些操作封装在一个脚本中。
一个基本的CDO脚本结构如下:
```cdo
#!/usr/bin/env cdo
setname = "input_data.nc" # 输入数据集名称
resultname = "processed_data.nc" # 结果数据集名称
# 数据处理流程
cdo -setname,$setname input_data.nc temp.nc
cdo -remapbil,grid.nc temp.nc remapped.nc
cdo -select,name=Temperature remapped.nc selected.nc
cdo -timmean selected.nc mean.nc
cdo -sub mean.nc -select,name=Temperature input_data.nc anomaly.nc
cdo -mul 0.1 anomaly.nc scaled_anomaly.nc
cdo -mergetime scaled_anomaly.nc temp_anomaly.nc processed_data.nc
```
### 5.1.2 批量处理多个数据集
在处理多个数据集时,脚本化的好处是显而易见的。CDO提供了一些用于批量处理的命令,比如`-mergetime`,`-mergespace`等,可以实现对时间或空间维度的数据集进行合并操作。此外,CDO还支持使用shell脚本中的循环结构来处理文件列表。
下面是一个批量处理多个气候数据文件的CDO脚本示例:
```bash
#!/bin/bash
file_list=( dataset_*.nc ) # 定义数据文件列表
for file in "${file_list[@]}"
do
echo "Processing $file..."
# 使用CDO处理单个数据集
cdo -remapbil,grid.nc $file remapped_$file
cdo -timmean remapped_$file mean_$file
done
```
这段脚本遍历所有符合`dataset_*.nc`模式的文件,并对每个文件执行重映射和时间平均的操作,将结果输出到以`remapped_`和`mean_`为前缀的文件中。
## 5.2 插件与扩展功能
### 5.2.1 如何安装与使用CDO插件
CDO为了扩展其功能,支持通过插件的方式引入新的操作和功能。用户可以自行开发或安装第三方提供的CDO插件。安装插件通常涉及以下几个步骤:
1. 确保安装了CDO。
2. 下载相应的CDO插件源代码或预编译的插件包。
3. 解压或放置插件包到合适的目录,例如CDO的`lib`目录。
4. 如果需要编译源码安装插件,则执行相应的编译命令,如`make install`。
5. 重新启动CDO服务,使插件生效。
使用CDO插件与使用内置功能的方式类似。例如,如果有一个插件提供了名为`myoperation`的新操作,可以在CDO命令行中直接使用:
```bash
cdo myoperation inputfile outputfile
```
### 5.2.2 CDO插件的定制化开发
CDO插件通常用C或C++编写,以保证高效运行。定制化开发插件首先需要熟悉CDO插件的开发接口,包括如何在CDO中注册新的操作、传递参数以及返回数据等。下面是一个简单的示例,展示了如何创建一个简单的CDO插件:
```c
#include <cdi.h>
CDIагс_T* cdo_register(int argc, char **argv)
{
/* 注册操作的代码 */
return NULL;
}
void cdo_exit(CDIагс_T* handle)
{
/* 清理资源的代码 */
}
int cdo计算操作(CDIагс_T* handle, int nrec, double* data)
{
/* 执行计算的代码 */
return 0;
}
```
开发者需要实现必要的函数,包括注册操作(`cdo_register`)、清理资源(`cdo_exit`)和执行操作(`cdo计算操作`)。这只是一个框架示例,具体实现需要根据操作逻辑编写。
## 5.3 CDO的性能优化
### 5.3.1 性能分析与调优方法
随着气候数据集规模的增加,处理这些数据变得越来越具有挑战性。CDO提供了多种方法来优化性能,以处理大规模数据集。性能调优通常包括以下几个方面:
- **硬件优化**:使用更快的CPU、更多的内存、更快的磁盘(如SSD)。
- **软件优化**:使用CDO的并行处理功能,比如`-p n`参数,可以指定使用n个线程进行并行计算。
- **数据格式优化**:使用CDO支持的高效数据格式,如GRIB、NetCDF等,这些格式通常有压缩功能。
- **算法优化**:选择合适的数据处理算法,某些算法比其他算法效率更高。
- **内存使用优化**:调整数据块的大小,合理分配内存使用,避免内存溢出。
性能分析常用工具包括`top`、`htop`、`iotop`等,这些可以帮助监测系统资源的使用情况。此外,CDO自带的一些诊断信息也可以提供性能分析的线索。
### 5.3.2 高效处理大规模数据集的策略
处理大规模数据集时,一个关键的策略是尽量减少数据的读写次数,避免不必要的数据转换,并利用CDO的内置优化功能。下面是一些常用的策略:
- **分块处理**:将大型数据集分成小块,逐块进行处理。
- **批量操作**:将多个处理步骤合并,一次性完成,减少重复的读写操作。
- **利用缓存**:在内存中缓存常用的中间结果,减少磁盘I/O操作。
- **预计算**:对于可以预先计算的常量或因子,提前计算并存储起来,减少实时计算。
例如,下面的命令展示了如何使用CDO的并行处理功能来计算两个数据集之间的差异:
```bash
cdo -p 8 -sub dataset_1.nc dataset_2.nc difference.nc
```
在这里,`-p 8`指定了使用8个并行线程进行计算,这可以显著加快处理速度。性能优化是一个持续的过程,需要根据具体问题和数据特点不断调整策略。
以上为第五章的详尽章节内容,展示了如何通过高级脚本编写实现批处理,介绍CDO插件的安装与使用,以及如何进行性能优化。内容涵盖了从基础的脚本编写到复杂的性能分析和优化策略,旨在提供给有经验的IT从业者关于CDO更深层次的应用和定制化方案。
# 6. CDO的未来展望与社区资源
## 6.1 CDO的发展路线图
CDO (Climate Data Operators) 作为一个广泛使用的气候数据处理工具,其发展路线图是CDO用户和开发者社区关注的焦点。随着科学计算需求的增长和计算机技术的演进,CDO也在不断地更新和完善。
### 6.1.1 新版本功能更新
每次新版本发布,CDO都会增加一些新的功能以满足用户的需求。例如,最新的版本可能增加了对新数据格式的支持,提供了更高效的算法,或是对现有的插件系统进行了改进以提升用户自定义功能的能力。例如,在某个版本中引入了对NetCDF5文件格式的支持,这对处理大型气候数据集尤为重要,因为它可以提高数据的压缩率和访问速度。
### 6.1.2 预期的发展方向与目标
CDO的未来版本将可能聚焦于以下几个方向:性能优化、扩展数据处理功能、提升用户界面的友好度、增强并行计算能力、以及改善数据可视化工具。目标是使CDO成为一个更加强大、快速和用户友好的数据处理工具,以适应不断增长的数据处理需求和日益复杂的气候模型数据。
## 6.2 社区贡献与协作
CDO社区的协作和贡献对于工具的持续改进和成功至关重要。社区成员通过代码贡献、经验分享、文档完善和社区支持互相帮助。
### 6.2.1 如何参与CDO社区
参与CDO社区的方法包括但不限于提交代码修复、报告和解决bug、编写文档和教程、参与邮件列表讨论,以及组织和参加开发者会议或用户大会。通过这些方式,不仅有助于CDO的发展,还能促进个人技能的提升和在相关领域内的建立联系。
### 6.2.2 分享经验与案例研究
分享使用CDO的经验和具体的案例研究是促进社区交流与学习的重要途径。在官方论坛、会议或社交平台上发布文章、报告或演讲视频,可以帮助他人解决特定问题,激发新的想法,也可以带来反馈和批评,从而推动工具的改进和自我提升。
## 6.3 资源与学习路径
CDO的用户群体广泛,涵盖学术界、研究机构和气象预报部门,因此适合不同背景的用户学习和使用。
### 6.3.1 推荐的学习材料与课程
为了更好地掌握CDO,用户可以参考官方文档、用户手册、在线教程以及相关的学术论文。这些资源可以帮助用户深入理解CDO的功能以及如何在不同场景下应用这些工具。例如,官方提供的教程文档是学习CDO语法和功能的基础,而学术论文可以提供在特定领域内应用CDO的案例。
### 6.3.2 如何解决CDO使用中的问题
在使用CDO过程中遇到的问题,用户可以通过访问官方问答论坛、参与邮件列表交流、阅读社区讨论或者自行查阅相关资料来解决。此外,开发团队和社区成员也经常在各类学术会议和技术研讨会上分享CDO的使用技巧和解决方案。将遇到的问题详细描述并公开求解,不仅可以帮助自己快速找到解决方法,也能够丰富社区的知识库。
在本章的探讨中,我们了解了CDO工具的发展方向、社区协作的方式,以及学习和解决问题的途径。通过积极的社区参与和持续学习,每一位用户都可以成为CDO发展的重要推动者。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Climate Data Operators(CDO)指南》专栏为气候数据处理提供全面的指导。从入门到精通,专栏涵盖了 CDO 工具的各个方面,包括高级技巧、数据转换、插值、数据融合、时间序列分析、空间分析、数据质量控制、数据降尺度、数据立方体操作、数据管理策略、数据预处理、脚本调试和优化、并行计算技术以及气候数据异常检测。通过深入的教程和实用示例,专栏帮助用户充分利用 CDO 的强大功能,有效处理和分析气候数据,为气候研究和决策提供可靠的基础。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
软件开发评审深度解析:7个检查项——提升代码审查的专业性
参考资源链接:[软件开发评审检查表大全](https://wenku.csdn.net/doc/6412b6f4be7fbd1778d48922?spm=1055.2635.3001.10343)
# 1. 软件开发评审概论
在现代软件开发实践中,软件开发评审(Code Review)作为一种提高代码质量、确保团队协作和
LabVIEW高级字符串处理:正则表达式的进阶用法揭秘

参考资源链接:[LabVIEW中字符串操作详解:正则表达式与格式化实用汇总](https://wenku.csdn.net/doc/1iwwmnyn3u?spm=1055.2635.3001.10343)
# 1. LabVIEW字符串处理基础回顾
在深入探索LabVIEW中的字符串处理之前,首先让我们回顾一些基础概念。字符串在LabVIEW中是数组的一种特殊类型,由字符数组构
【DANFOSS MCT 10 数据管理】:有效数据收集与分析技巧
参考资源链接:[丹佛斯MCT10软件:变频器管理和调试指南](https://wenku.csdn.net/doc/6412b477be7fbd1778d3fb01?spm=1055.2635.3001.10343)
# 1. DANFOSS MCT 10 数据管理概述
【凸优化深度剖析】:分类、转化、案例全解析

参考资源链接:[《凸优化》完整学习资源:书、习题与考试解答](https://wenku.csdn.net/doc/3oa52o6c8k?s
TRDP协议深度解析:掌握核心数据包结构与传输机制
参考资源链接:[IEC61375-2-3列车以太网实时协议(TRDP)详解](https://wenku.csdn.net/doc/mcqyoae70y?spm=1055.2635.3001.10343)
# 1. TRDP协议概述
TRDP(Transport Protocol of Real-time and Distributed Systems)是一种专门设计用于实时和分布式系统的网络通信协议
STM32CubeMX与HAL库整合指南:构建高稳定性的应用
参考资源链接:[STM32CubeMX中文版:图形化配置与C代码生成指南](https://wenku.csdn.net/doc/6412b718be7fbd1778d4913c?spm=1055.2635.3001.10343)
# 1. STM32CubeMX简介与HAL库概述
STM32微控制器因其高性能和高集成度,广泛应用于嵌入式系统开发。为了简化硬件
【电动车辆技术革新】:UDS协议在电动汽车中的关键应用

参考资源链接:[UDS诊断协议ISO14229中文版:汽车总线诊断标准解析](https://wenku.csdn.net/doc/6401abcecce7214c316e992c?spm=1055.2635.3001.10343)
# 1. UDS协议概述与电动汽车行业背景
汽车行业的数字化转型不仅带动了电动汽车市场的快速发展,
项目实战:如何用九齐单片机从零构建第一个应用
参考资源链接:[九齐NYIDE开发工具详解及安装指南](https://wenku.csdn.net/doc/6drbfcnhd1?spm=1055.2635.3001.10343)
# 1. 通用单片机基础和开发环境搭建
在本章中,我们将开启通用单片机的学习之旅,从基础知识到开发环境的搭建,为后续的深入探讨打下坚实的基础。
## 1.1 通用单片机简介
通用单片机是微控制器的一种,集成了处理器核心、内存、多种外设接口于一体,广泛应用于智能设备和嵌入式系统中。了解单片机的类型和特点对于选择合适的硬件平台至关重要。
## 1.2 开发环境搭建
开发环境的搭建是单片机开发的第一步。这包括
【RTL8367网络设备全方位优化指南】:掌握从安装到故障排除的20个秘诀
参考资源链接:[RTL8367S-CG中文手册:二层交换机控制器](https://wenku.csdn.net/doc/71nbbubn6x?spm=1055.2635.3001.10343)
# 1. RTL8367网络设备基础介绍
## 网络设备概述
RTL8367是一款广泛应用于中小企业和大型企业的网络交换设备,以其实用性、可靠性和高
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )