【XML命名空间处理】:xml.etree高级用法,专家级指南
发布时间: 2024-10-05 23:33:57 阅读量: 3 订阅数: 6 

# 1. XML命名空间基础
## XML命名空间简介
在处理XML文档时,命名空间是用来区分具有相同名称的元素或属性的一种机制。命名空间通过URI(统一资源标识符)进行唯一标识,这有助于在单一文档中混合来自不同源的数据。
## 命名空间的作用
命名空间不仅解决了元素和属性名称的冲突问题,而且还可以帮助开发者维护和扩展XML文档结构。使用命名空间,开发者可以清晰地识别每个元素或属性的归属。
## 命名空间的声明与使用
在XML文档中声明命名空间通常使用`xmlns`前缀,例如`xmlns:ns="***"`。使用时,只需在相关元素或属性前附加该前缀,例如`<ns:element>`。这种简洁的声明方式使得命名空间的管理变得简单高效。
通过本章的介绍,我们将为理解后续章节中的复杂操作和概念打下坚实的基础,掌握命名空间的运用将使你在处理XML文档时更加得心应手。
# 2. 深入理解xml.etree.ElementTree模块
### 2.1 xml.etree.ElementTree模块概览
#### 2.1.1 ElementTree的核心组件
`xml.etree.ElementTree` 是 Python 中用于解析和创建XML文档的模块,提供了简单而有效的方式来处理XML数据。该模块的核心组件包括 Element 对象和 ElementTree 对象。
Element 对象代表了 XML 树中的单个节点,拥有标签、文本和属性。它还包含子元素的列表。通过递归地访问子元素,可以遍历整个 XML 树。
ElementTree 对象则是一个完整的 XML 文档的根节点,并提供了多种方法来对整个文档进行操作,例如写入文件或进行字符串序列化。
下面是一个简单的代码示例,演示了如何创建一个 Element 对象并构建一个包含多个子元素的 ElementTree 对象:
```python
import xml.etree.ElementTree as ET
# 创建根节点
root = ET.Element('root')
# 添加子节点
child1 = ET.SubElement(root, 'child1', attrib={'id': 'c1'})
child1.text = 'This is a child element.'
child2 = ET.SubElement(root, 'child2')
child2.text = 'This is another child element.'
# 创建ElementTree对象
tree = ET.ElementTree(root)
# 输出XML数据
tree.write('example.xml')
```
在这个例子中,我们首先导入了 `xml.etree.ElementTree` 模块,并将其重命名为 `ET`。然后我们创建了一个名为 'root' 的根节点,并添加了两个子节点 'child1' 和 'child2',后者还具有一个属性。最后,我们创建了一个 ElementTree 对象,并将根节点传递给它,最后将整个 XML 写入到文件中。
#### 2.1.2 创建和解析XML文档
创建 XML 文档仅是 ElementTree 功能的一部分。解析 XML 文档并从中提取信息也是 ElementTree 所擅长的。我们可以使用 `ET.fromstring()` 函数直接从字符串创建 ElementTree 对象,或者使用 `ET.parse()` 函数从文件中解析 XML。
以下是一个使用 `ET.parse()` 解析 XML 文件的例子:
```python
import xml.etree.ElementTree as ET
# 加载并解析XML文件
tree = ET.parse('example.xml')
# 获取根节点
root = tree.getroot()
# 打印根节点
print(ET.tostring(root, encoding='utf8').decode('utf8'))
# 遍历所有子元素并打印它们的标签和文本
for child in root:
print(f'Tag: {child.tag}, Text: {child.text}')
```
在这个例子中,`ET.parse('example.xml')` 加载了一个 XML 文件,而 `tree.getroot()` 返回了该文档的根节点。我们使用 `ET.tostring(root)` 将根节点转换为一个字符串,并使用 `decode('utf8')` 将其解码成一个可读的字符串。最后,我们遍历根节点的直接子节点,并打印出每个子节点的标签和文本。
### 2.2 XML命名空间的工作原理
#### 2.2.1 命名空间声明与限定
XML 命名空间是为了解决在 XML 文档中的命名冲突问题。它通过声明一个 URI 来为元素和属性创建一个唯一的上下文,这样即使存在同名的元素或属性,它们也因为处于不同的命名空间而不冲突。
在 ElementTree 中,命名空间可以通过在元素的标签前添加一个前缀和 URI 来使用:
```python
from xml.etree.ElementTree import Element, SubElement, tostring
# 声明命名空间
namespace = {'ns': '***'}
root = Element('root')
# 使用命名空间创建子元素
child = SubElement(root, '{***}child')
child.text = 'This is a namespaced child element.'
# 序列化带有命名空间的 ElementTree
print(tostring(root, encoding='utf8', method='xml').decode('utf8'))
```
#### 2.2.2 命名空间在元素和属性上的应用
命名空间可以在元素标签和属性名上使用。当它们用在元素标签上时,它用于区分属于不同命名空间的元素。当用在属性上时,它用于指定属性属于哪个命名空间。
这里举例说明如何在 ElementTree 中创建带有命名空间的元素和属性:
```python
import xml.etree.ElementTree as ET
# 定义一个元素
root = ET.Element('{***}root')
# 定义一个带命名空间的子元素
child = ET.SubElement(root, '{***}child')
child.set('{***}attr', 'value')
# 使用ET.tostring()将元素转换为XML字符串并打印
print(ET.tostring(root, encoding='unicode'))
```
这段代码创建了一个命名空间,并将该命名空间应用到根元素和子元素上。通过使用 `set()` 方法来设置一个带命名空间的属性。
### 2.3 处理命名空间的高级技术
#### 2.3.1 使用命名空间字典
当处理包含多个命名空间的大型XML文档时,手动声明每个命名空间可能会非常繁琐。幸运的是,ElementTree 允许使用命名空间字典来简化这一过程。
命名空间字典是一个映射,它将命名空间前缀映射到URI。这样就可以在后续操作中使用这些前缀来引用相应的命名空间,而无需重复声明。
下面是一个使用命名空间字典的例子:
```python
import xml.etree.ElementTree as ET
# 命名空间字典
namespaces = {
'ns1': '***',
'ns2': '***'
}
# 解析XML文档
tree = ET.parse('example.xml')
# 遍历所有子元素,使用命名空间字典
for elem in tree.iter():
for key in namespaces:
# 使用命名空间字典来找到匹配的命名空间URI
ns_uri = namespaces[key]
if elem.tag.startswith(f'{{{ns_uri}}}'):
print(f'Namespace: {key}, Tag: {elem.tag}, Text: {elem.text}')
```
#### 2.3.2 命名空间的继承和冲突解决
命名空间是可以被子元素继承的,这意味着父元素的命名空间会被应用到它的所有子元素上,除非子元素明确指定了新的命名空间。
当处理继承的命名空间时,需要注意的是如何区分和解决潜在的命名冲突。使用命名空间字典是处理此类冲突的一种有效方式,因为它可以明确指定对特定命名空间的引用。
下面的代码展示了如何使用命名空间字典来处理继承的命名空间,并解决命名冲突:
```python
import xml.etree.ElementTree as ET
# 定义命名空间
namespaces = {
'ns1': '***',
'ns2': '***'
}
# 解析XML文档
tree = ET.parse('example.xml')
# 使用命名空间字典来遍历并打印元素
for elem in tree.iter():
ns = None
for key in namespaces:
ns_uri = namespaces[key]
if elem.tag.startswith(f'{{{ns_uri}}}'):
ns = key
break
if ns is None:
continue
print(f'Namespace: {ns}, Tag: {elem.tag}, Text: {elem.text}')
```
在这个例子中,我们创建了一个包含两个命名空间的字典,并遍历 XML 树中的所有元素。对于每个元素,我们检查其标签是否以这些命名空间之一的 URI 开头。如果是,我们将对应的前缀存储在 `ns` 变量中,并在输出时使用该前缀。
以上是对于 `xml.etree.ElementTree` 模块概览及其深入理解的介绍,接下来的章节将聚焦在 `xml.etree` 的高级查询技术。
#

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 的 xml.etree 库,提供了一系列全面的指南和最佳实践,帮助您掌握 XML 处理。从初学者入门到高级特性,您将学习如何构建、解析、操作和验证 XML 文档。本专栏涵盖了动态生成、性能调优、数据绑定、XSD 验证、XSLT 转换、JSON 解析、Web 服务集成、命名空间处理、数据库同步、数据校验、XPath 高级应用等主题。通过本专栏,您将掌握使用 xml.etree 提高 XML 处理效率和准确性的技巧,并成为 XML 处理方面的专家。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【App Engine微服务应用】:webapp.util模块在微服务架构中的角色
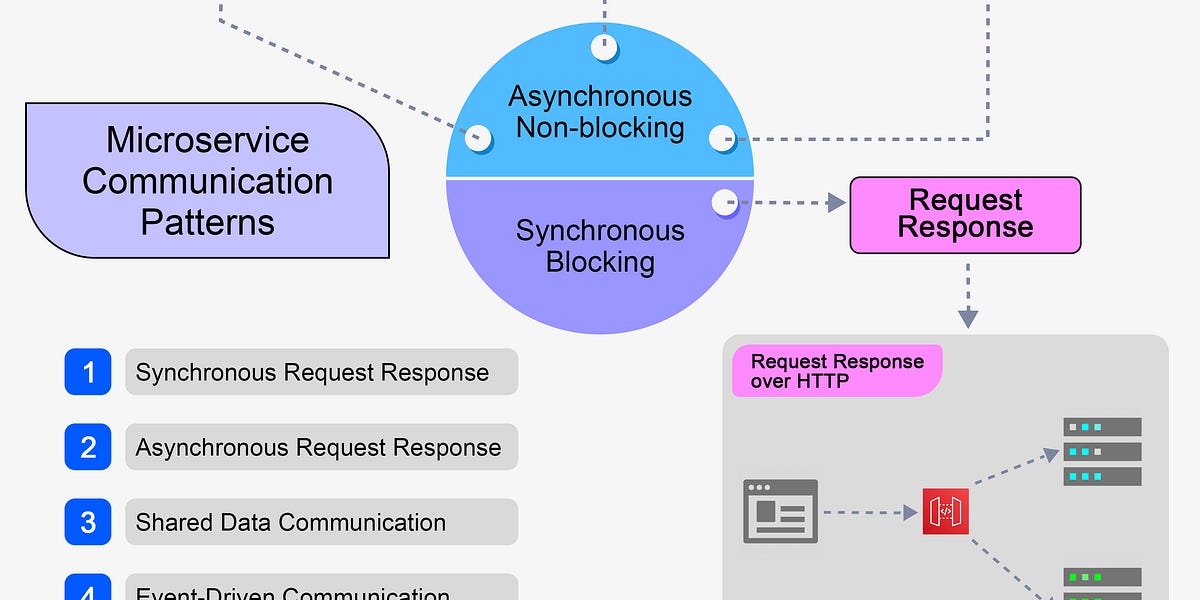
# 1. 微服务架构基础与App Engine概述
##
【数据模型同步】:Django URL配置与数据库关系的深入研究
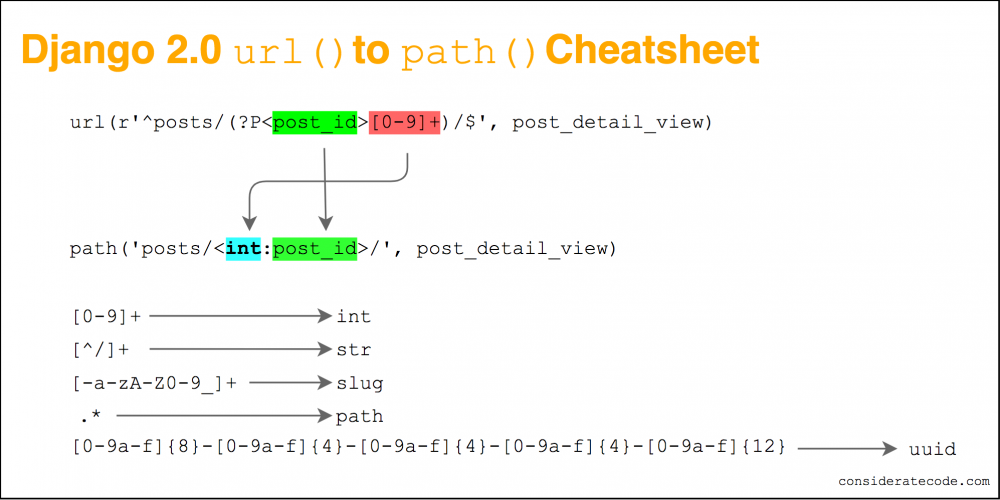
# 1. Django框架中的URL配置概述
Django框架中的URL配置是将Web请求映射到相应的视图处理函数的过程。这一机制使得开发者能够按照项目需求灵活地组织和管理Web应用的路由。本章将从基本概念入手,为读者提供一个Django URL配置的概述,进而为深入理解和应用打下坚实的基础。
## 1.1 URL配置的基本元素
在Django
【XPath高级应用】:在Python中用xml.etree实现高级查询

# 1. XPath与XML基础
XPath是一种在XML文档中查找信息的语言,它提供了一种灵活且强大的方式来选择XML文档中的节点或节点集。XML(Extensible Markup Language)是一种标记语言,用于存储和传输数据。为了在Python中有效地使用XPath,首先需要了解XML文档的结构和XPath的基本语法。
## 1
httpie在自动化测试框架中的应用:提升测试效率与覆盖率

# 1. HTTPie简介与安装配置
## 1.1 HTTPie简介
HTTPie是一个用于命令行的HTTP客户端工具,它提供了一种简洁而直观的方式来发送HTTP请求。与传统的`curl`工具相比,HTTPie更易于使用,其输出也更加友好,使得开发者和测试工程师可以更加高效地进行API测试和调试。
## 1.2 安装
【Django国际化经验交流】:资深开发者分享django.utils.translation使用心得
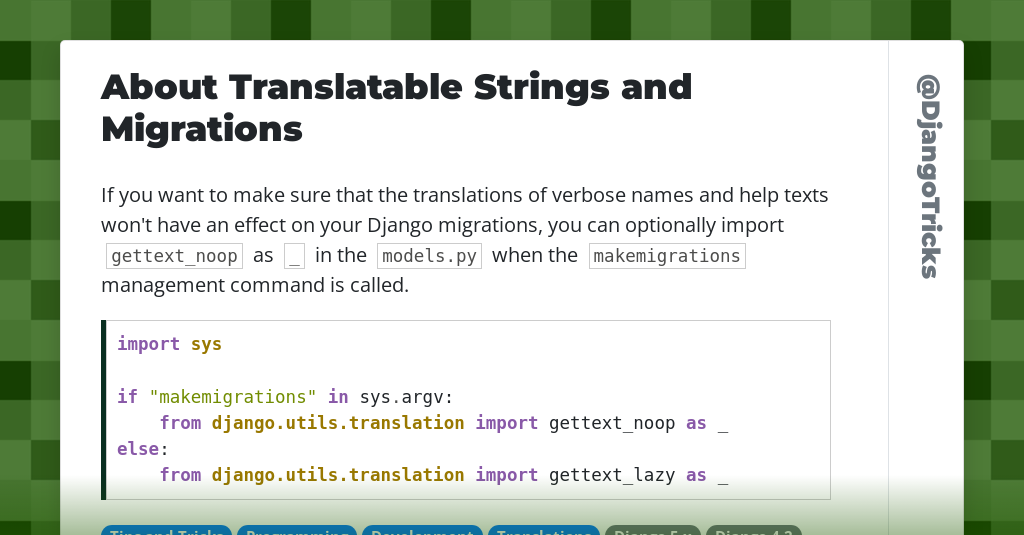
# 1. Django项目国际化概述
国际化(Internationalization),简称i18n,是指软件或网站等应用程序设计和实现过程中的支持多语言的过程。Django作为一个功能强大的Python Web框架,自然提供了一套完整的国际化解决方案,使得开发者能够轻松构建支持多种语言的Web应用。
## Django国际化的重要性
在
【pipenv与其他Python虚拟环境工具对比】:寻求最佳替代方案

# 1. Python虚拟环境概述
Python虚拟环境是程序员用来隔离项目依赖和Python解释器版本的工具。在不同项目间切换时,避免了依赖项冲突和版本不兼容的问题。**虚拟环境的创建**通常涉及指定一个隔离的目录,并在这个目录中安装所需的所有包。虚拟环境为开发者提供了一个整洁且一致的工作环境,确保项目在不同开发者的机器之间具有可移植性,提高了开发效率和减少
【lxml与数据库交互】:将XML数据无缝集成到数据库中

# 1. lxml库与XML数据解析基础
在当今的IT领域,数据处理是开发中的一个重要部分,尤其是在处理各种格式的数据文件时。XML(Extensible Markup Language)作为一种广泛使用的标记语言,其结构化数据在互联网上大量存在。对于数据科学家和开发人员来说,使用一种高效且功能强大的库来解析XML数据显得尤为重要。P
【数据探索的艺术】:Jupyter中的可视化分析与探索性处理技巧
# 1. 数据探索的艺术:Jupyter入门
## 1.1 数据探索的重要性
数据探索是数据分析过程中的核心环节,它涉及对数据集的初步调查,以识别数据集的模式、异常值、趋势以及数据之间的关联。良好的数据探索可以为后续的数据分析和建模工作打下坚实的基础,使分析人员能够更加高效地识别问题、验
【feedparser教育应用】:在教育中培养学生信息技术的先进方法
# 1. feedparser技术概览及教育应用背景
## 1.1 feedparser技术简介
Feedparser是一款用于解析RSS和Atom feeds的Python库,它能够处理不同来源的订阅内容,并将其统一格式化。其强大的解析功能不仅支持多种语言编码,还能够处理各种数据异
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )