【PyTorch模型评估】:损失函数在模型验证中的关键角色
发布时间: 2024-12-11 23:26:25 阅读量: 15 订阅数: 12 

细说PyTorch深度学习:理论、算法、模型与编程实现 03
# 1. PyTorch模型评估概述
在构建和训练深度学习模型的过程中,模型评估是不可或缺的一步。它帮助我们理解模型的性能,验证其预测能力,以及决定模型是否能够推广到未知数据上。本章将简要介绍模型评估的目的、重要性以及如何在PyTorch中实现模型评估的基本方法。
## 模型评估的目的和重要性
模型评估的核心目的,是检验模型在处理独立数据集时的泛化能力。通过使用验证集和测试集来评估模型,我们可以获得关于模型实际表现的客观反馈。这个过程不仅有助于模型的微调,还能指导我们在面对不同问题时选择适当的模型结构和参数。
## PyTorch中的模型评估实践
在PyTorch中,模型评估通常涉及到以下几个步骤:
1. 将模型设置为评估模式(`model.eval()`)。
2. 在验证集或测试集上进行前向传播,获取预测结果。
3. 计算性能指标,如准确率、召回率、F1分数等。
4. 分析结果,根据需求进行模型优化。
### 示例代码
```python
import torch
from torch import nn
# 假设我们有一个训练好的模型model和数据加载器val_loader
model.eval() # 将模型设置为评估模式
all_preds = []
all_labels = []
with torch.no_grad(): # 在评估时不计算梯度
for inputs, labels in val_loader: # val_loader是验证集数据加载器
outputs = model(inputs) # 获取模型输出
_, preds = torch.max(outputs, 1) # 获取预测结果
all_preds.extend(preds.numpy()) # 将预测结果添加到列表
all_labels.extend(labels.numpy()) # 将真实标签添加到列表
# 计算性能指标
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(all_labels, all_preds)
print(f'Validation Accuracy: {accuracy:.4f}')
```
本章内容为模型评估的基础部分,为后续深入探讨如何优化损失函数和提高模型性能打下基础。在接下来的章节中,我们将详细介绍损失函数的作用、不同类型的损失函数以及它们在模型验证和优化中的应用。
# 2. 损失函数的理论基础
### 2.1 损失函数的定义和目的
损失函数,也称为代价函数或误差函数,是衡量模型预测值与真实值差异的数学表达式。它在机器学习和深度学习中扮演着至关重要的角色,因为它们为优化算法提供了训练过程中改进模型性能的依据。
#### 2.1.1 损失函数在机器学习中的作用
在机器学习中,损失函数衡量的是模型预测值与实际观测值之间的差异。这个函数的值越低,表示模型的预测越接近实际值。训练一个机器学习模型的过程,本质上是在寻找一组模型参数,使得损失函数的值最小。常见的优化算法,如梯度下降法,正是通过最小化损失函数来更新参数,以求达到最优解。
#### 2.1.2 损失函数与模型性能的关系
损失函数与模型的性能紧密相关。在实际应用中,我们希望模型在未见数据上的表现尽可能好,因此需要一个能够反映模型泛化能力的损失函数。损失函数的值不仅取决于模型对训练数据的拟合程度,也反映了模型在新数据上的预测能力。因此,选择合适的损失函数对于提升模型的泛化性能至关重要。
### 2.2 常见损失函数类型解析
在机器学习中,根据不同的问题类型,我们有不同类型的损失函数。每种损失函数都有其特定的数学表达式和应用场景。
#### 2.2.1 回归问题的损失函数
对于回归问题,目标是预测一个连续值,因此损失函数通常基于预测值和实际值之间的差的某种度量。
- 均方误差(MSE)是最常用的回归损失函数,它计算预测值与实际值之间差的平方的平均值。数学表达式为:\( MSE = \frac{1}{N}\sum_{i=1}^{N}(y_i - \hat{y}_i)^2 \),其中 \( y_i \) 是实际值,\( \hat{y}_i \) 是预测值,N是样本数量。
#### 2.2.2 分类问题的损失函数
分类问题的目标是预测一个离散标签或类。常见的分类损失函数包括:
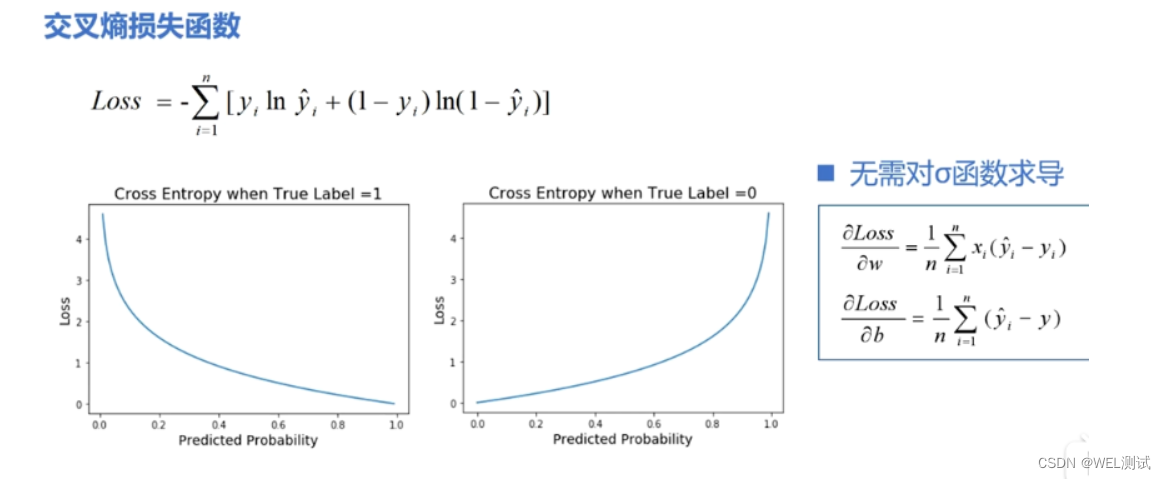
- 交叉熵损失(Cross-Entropy Loss)是分类问题中广泛使用的损失函数。对于二分类问题,交叉熵损失函数可以表示为:\( L = -[y \cdot \log(\hat{y}) + (1 - y) \cdot \log(1 - \hat{y})] \),其中 \( y \) 是真实标签,\( \hat{y} \) 是预测的标签概率。
#### 2.2.3 其它特殊问题的损失函数
对于一些特殊问题,如排序问题或强化学习中的目标,有特定设计的损失函数:
- 对于排序问题,经常使用的是排名损失(Ranking Loss),例如Hinge Loss或者LambdaRank等。
### 2.3 损失函数的选择依据
在实际应用中,选择合适的损失函数对于模型的训练和泛化性能至关重要。
#### 2.3.1 损失函数与数据分布的匹配
选择损失函数需要考虑数据的分布。例如,如果数据具有长尾分布,可能需要采用鲁棒性更强的损失函数,如Huber损失函数,以减少异常值的影响。
#### 2.3.2 损失函数与模型复杂度的平衡
损失函数需要与模型的复杂度相平衡。简单的模型可能需要更简单的损失函数来避免过拟合,而复杂的模型可能需要更复杂的损失函数来充分捕捉数据的特性。
在下一章中,我们将探讨如何将损失函数应用于模型验证中,并通过具体的案例展示损失函数如何影响模型的性能和调优。
# 3. 损失函数在模型验证中的实践应用
## 3.1 模型验证的基本流程
### 3.1.1 训练集、验证集和测试集的划分
在机器学习中,数据集通常分为三部分:训练集、验证集和测试集。训练集用于训练模型,验证集用于评估模型的性能并进行超参数的调整,而测试集则用于最终评估模型泛化能力。合理地划分数据集是保证模型评估有效性的关键。
```python
from sklearn.model_selection import train_test_split
# 假设 X 是特征数据集,y 是标签数据集
X_train, X_temp, y_train, y_temp = train_test_split(X, y, test_size=0.3, random_state=42)
X_val, X_test, y_val, y_test = train_test_split(X_temp, y_temp, test_size=0.5, rand
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏全面介绍了 PyTorch 中损失函数在模型优化中的应用。从新手必备的技巧到自定义损失函数和优化策略的进阶技术,再到损失函数背后的工作原理和调参策略,以及在模型验证、自动微分、微调和诊断中的关键作用,本专栏提供了全面的指导。此外,还对各种损失函数进行了比较分析,帮助读者选择最适合其模型需求的损失函数。通过深入浅出的讲解和丰富的代码示例,本专栏旨在帮助读者掌握损失函数的应用,从而优化 PyTorch 模型的性能。
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
音频分析无界限:Sonic Visualiser与其他软件的对比及选择指南
参考资源链接:[Sonic Visualiser新手指南:详尽功能解析与实用技巧](https://wenku.csdn.net/doc/r1addgbr7h?spm=1055.2635.3001.10343)
# 1. 音频分析软件概述与Sonic Visualiser简介
## 1.1 音频分析软件的作用
音频分析软件在数字音频处理领域扮演着至关重要的角色。它们不仅为
多GPU协同新纪元:NVIDIA Ampere架构的最佳实践与案例研究
参考资源链接:[NVIDIA Ampere架构白皮书:A100 Tensor Core GPU详解与优势](https://wenku.csdn.net/doc/1viyeruo73?spm=1055.2635.3001.10343)
# 1. NVIDIA Ampere架构概览
在本章中,我们将深入探究NVIDIA Ampere架构的核心特
【HFSS栅球建模终极指南】:一步到位掌握建模到仿真优化的全流程
参考资源链接:[2015年ANSYS HFSS BGA封装建模教程:3D仿真与分析](https://wenku.csdn.net/doc/840stuyum7?spm=1055.2635.3001.10343)
# 1. HFSS栅球建模入门
## 1.1 栅球建模的必要性与应用
在现代电子设计中,准确模拟电磁场的行为至关重要,特别是在高频应用领域。栅
【MediaKit的跨平台摄像头调用】:实现一次编码,全平台运行的秘诀

参考资源链接:[WPF使用MediaKit调用摄像头](https://wenku.csdn.net/doc/647d456b543f84448829bbfc?spm=1055.2635.3001.10343)
# 1. MediaKit跨
【机器学习优化高频CTA策略入门】:掌握数据预处理、回测与风险管理
参考资源链接:[基于机器学习的高频CTA策略研究:模型构建与策略回测](https://wenku.csdn.net/doc/4ej0nwiyra?spm=1055.2635.3001.10343)
# 1. 机器学习与高频CTA策略概述
## 机器学习与高频交易的交叉
在金融领域,尤其是高频交易(CTA)策略中,机器学习技术已成为一种创新力量,它使交易者能够从历史数据中发现复杂的模
ST-Link V2 原理图解读:从入门到精通的6大技巧
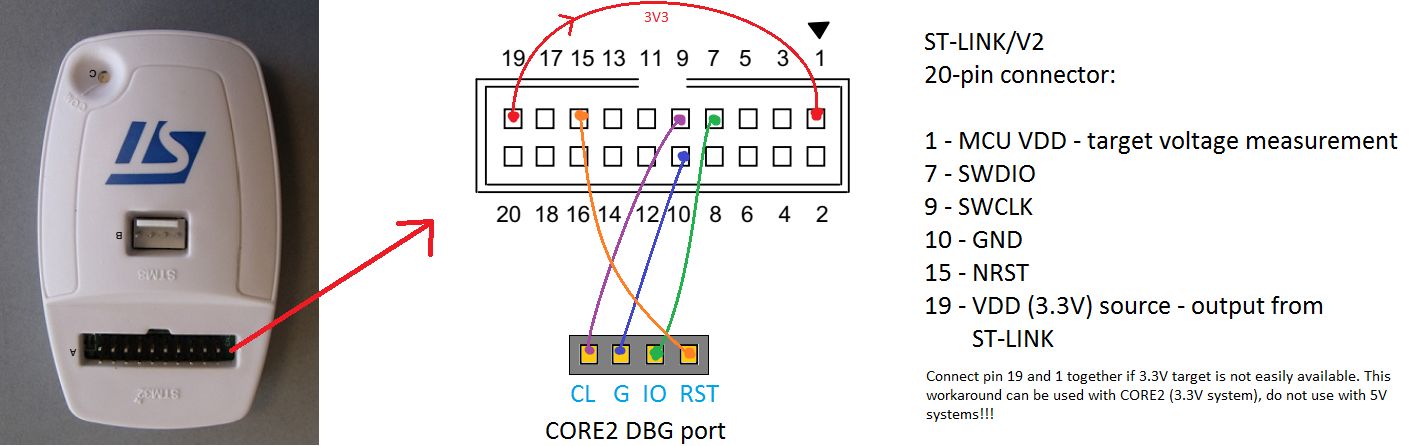
参考资源链接:[STLink V2原理图详解:构建STM32调试下载器](https://wenku.csdn.net/doc/646c5fd5d12cbe7ec3e52906?spm=1055.2635.3001.10343)
# 1. ST-Link V2简介与基础应用
ST-Link V2是一种广泛使用的调试器/编
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )