




C++字符型数据高级运用

摘要
C++语言中字符型数据是处理文本信息的基础元素,本文全面介绍了C++中字符型数据的基本概念、内存表示、高级操作技术、高效算法应用及实际应用案例。首先,概述了字符类型和编码基础,然后深入探讨了字符串的内部存储结构和使用C++标准模板库(STL)中的std::string。接着,详细讲解了字符串的高级操作技术,包括字符串流的使用、格式化处理以及搜索与替换技术。此外,文章还介绍了高效字符串算法及其性能优化方法。最后,通过实际案例展示了字符型数据在文本处理、系统编程和Web开发中的应用。文章还展望了字符处理技术的前沿研究与未来发展趋势,包括新型编码技术和自然语言处理中的应用挑战。
关键字
C++;字符型数据;内存表示;字符串操作;算法优化;文本处理;自然语言处理
参考资源链接:C++字符型数据(char)详解与ASCII码
1. C++字符型数据概述
1.1 C++中字符型数据的作用
字符型数据在C++程序中扮演着基础而关键的角色。它不仅用于表示单个字符,还可以组成字符串,用于文本处理、文件操作、用户界面交互等多种场景。理解字符型数据的使用和处理对于构建高效、稳定的程序至关重要。
1.2 字符与字符串的区分
在C++中,字符(char)是存储单个字符信息的基本数据类型,而字符串则是字符数组的一种特殊形式,用来存储一系列字符。字符串通常以null(‘\0’)字符结尾,标识字符串的结束。
1.3 C++字符型数据的基本语法
字符型数据的声明和初始化十分简单。例如:
- char ch = 'A'; // 声明并初始化一个字符变量
- std::string str = "Hello"; // 声明并初始化一个字符串变量
在后续章节中,我们将深入探讨字符型数据的更多细节和高级操作技术。
2. 字符型数据在内存中的表示
2.1 C++中的字符类型
2.1.1 char类型详解
在C++编程语言中,char类型是用于存储字符的基础数据类型。每个char通常占用1字节(8位)的内存空间。char类型可以根据需要存储正数或负数,这取决于编译器如何实现char类型。当char用作字符常量或字符串时,它通常被视为无符号类型。
- char letter = 'A'; // 字符常量
- char text[] = "Hello"; // 字符串数组
尽管char类型可能被解释为有符号或无符号,但当涉及到数值比较时,开发者应谨慎处理。例如,当char被解释为有符号类型时,存储在其中的最大值为127,最小值为-128;而解释为无符号类型时,它的范围是0到255。
- #include <iostream>
- int main() {
- char ch = 128; // 这是一个超出char范围的值
- if (ch > 0) {
- std::cout << "char is unsigned: " << static_cast<int>(ch) << std::endl; // 可能输出256
- } else {
- std::cout << "char is signed: " << static_cast<int>(ch) << std::endl;
- }
- return 0;
- }
这段代码演示了当char超出其范围时的行为。为了避免潜在的问题,开发者通常会显式地使用signed char或unsigned char来声明字符变量。
2.1.2 wchar_t与宽字符处理
由于char类型只能处理基本的ASCII字符集(128个字符),为了支持更广泛的国际字符集(如Unicode),C++中引入了wchar_t类型,其目的是提供足够的存储空间来表示更宽的字符,特别是Unicode字符。
- #include <iostream>
- #include <cwchar>
- int main() {
- wchar_t wideChar = L'界'; // 宽字符常量
- std::wcout << L"Hello, World!" << std::endl; // 使用宽字符集的输出
- std::wcout << L"Number: " << 100 << std::endl; // 与整数的混合使用
- return 0;
- }
在上面的例子中,L前缀用于表示宽字符字面量。wchar_t的实际大小依赖于平台和编译器,通常是2字节(16位)或4字节(32位),足以包含一个Unicode代码点。
开发者在使用wchar_t时需要确保编译器和运行时库支持宽字符。宽字符的字符串存储通常使用wchar_t数组,且标准库中也有与宽字符相关的函数,如std::wcout、std::wcin等。
2.2 字符编码基础
2.2.1 ASCII编码原理
ASCII(美国信息交换标准代码)是最早的字符编码标准之一,主要目的是为了让计算机能够通过统一的标准来处理英文文本。它使用7位二进制数来表示128个不同的字符,包括英文字母(大小写)、数字、标点符号以及控制字符。
尽管ASCII标准只有7位,但其实际使用中的扩展ASCII码通常使用8位(1字节),从而使得可表示的字符数扩展到256个。这种扩展仍称为ASCII,但为了区分,有时称之为扩展ASCII码或高ASCII码。
在C++中,当一个字符字面量不使用任何前缀时,默认为char类型,通常意味着它按照ASCII编码进行解释。
2.2.2 Unicode编码简述
随着时间的发展,为了适应包括中文、日文、阿拉伯文及其他语言在内的更广泛的字符集,Unicode应运而生。Unicode提供了一个能够表示几乎世界上所有已知字符集的唯一编码系统。
Unicode采用多种不同的编码形式,其中最常用的是UTF-8、UTF-16和UTF-32。UTF-8兼容ASCII,并且通过使用1到4个字节来表示一个字符,能够处理从基本的ASCII字符到复杂的Unicode字符。UTF-16通常使用2个或4个字节表示一个字符,而UTF-32则使用固定4个字节。
在C++中,处理Unicode字符通常涉及到使用wchar_t、char16_t或char32_t类型,这些类型分别对应于不同的Unicode编码形式。C++11标准之后,还引入了能够直接处理Unicode字符的字面量前缀u和U。
- #include <iostream>
- int main() {
- char16_t char16 = u'界'; // UTF-16编码
- char32_t char32 = U'界'; // UTF-32编码
- std::cout << "char16: " << char16 << std::endl;
- std::cout << "char32: " << char32 << std::endl;
- return 0;
- }
2.3 字符串的内部存储结构
2.3.1 C风格字符串
在C语言和早期的C++中,字符串通常被表示为字符数组,以空字符’\0’结尾。这种以字符数组为基础的字符串表示法被称为C风格字符串。
- char cStr[] = "Hello, World!"; // C风格字符串
C风格字符串非常依赖于指针运算和字符串操作函数,如strcpy、strcat、strlen等,这些函数都定义在头文件<cstring>中。然而,这种方式缺乏类型安全性,并且容易出错,如越界写入、未初始化的读取等。
- #include <cstring>
- #include <iostream>
- int main() {
- char cStr[] = "Hello";
- char buffer[20];
- strcpy(buffer, cStr); // 将cStr复制到buffer
- strcat(buffer, " World!"); // 将" World!"附加到buffer的末尾
- std::cout << "C-Style String: " << buffer << std::endl;
- return 0;
- }
由于其简单性和与C语言的兼容性,C风格字符串在许多场合依然被广泛使用。然而,在现代C++编程中,推荐使用更安全、更高效的字符串处理方式。
2.3.2 C++ STL中的std::string
为了提高类型安全性和操作的便利性,C++标准模板库(STL)引入了std::string类。std::string是封装了字符数组的类,提供了丰富的成员函数用于字符串操作。这些操作包括但不限于字符串连接、赋值、复制、比较、查找和修改。

std::string内部通常使用动态数组实现,能够自动管理内存,因此避免了C风格字符串手动管理内存的诸多问题。此外,std::string支持直接使用C++标准库中的所有标准算法。
std::string在性能上略逊于C风格字符串,主要由于其需要额外的内存分配和管理开销。然而,其易用性和安全性往往被认为是这些额外开销的合理代价。
以上是字符型数据在内存中的表示方法,包括字符类型、字符编码基础以及字符串的内部存储结构。了解这些基础知识对于深入掌握C++中的字符处理至关重要,为接下来的高级操作技术和应用案例打下坚实的基础。
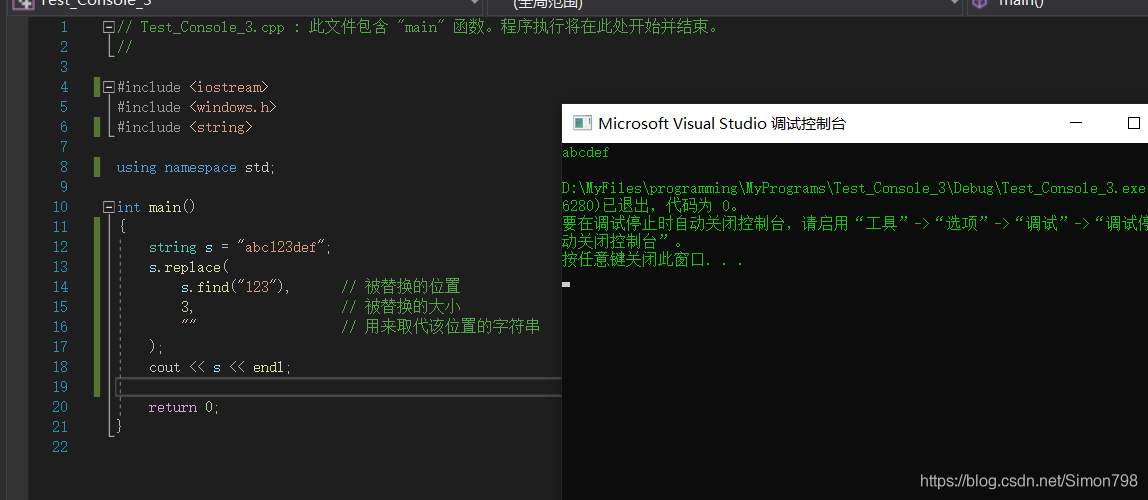
3. 字符型数据的高级操作技术
3.1 字符串流与输入输出操作
字符串流是C++标准库中处理字符串的一种高效方式,它们允许用户像使用文件流那样操作字符串。std::stringstream是其中的一个重要类,它使得字符串在内存中的操作变得灵活且方便。
3.1.1 使用std::stringstream处理字符串
std::stringstream 是一个非常强大的工具,用于执行字符串的解析和格式化。它可以将字符串当作输入输出流来处理。下面的示例展示了如何使用 std::stringstream 来合并字符串、分离字符串以及字符串与基本数据类型的转换。
在上述代码中,std::stringstream 对象 ss 被用来将两个字符串 str1 和 str2 连接起来。通过 ss.str() 方法可以获取当前流的内容转换成字符串。接下来,将整数 num 输入到 ss 中,并用 ss.str() 将其转换为字符串。最后,使用提取运算符 >> 将字符串流中的数字重新解析到整型变量 outNum 中。
3.1.2 字符串与iostream的交互
字符串流与标准输入输出流(iostream)之间的交互是通过插入(<<)和提取(>>)运算符来完成的。这种交互使得将数据写入字符串流,然后输出到标准输出变得十分简便。
- #include <iostream>
- #include <sstream>
- int main() {
- std::stringstream ss;
- std::st

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
 百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Oracle存储管理进阶】:掌握表空间不足的5大高级解决方案
【安全使用手册】:确保FLUKE_8845A_8846A操作安全的专家指南
递归VS迭代:快速排序的【优劣对比】与最佳实现方法
【兼容性测试报告】:确保你的U盘在各种主板上运行无忧
【RFID消费管理系统故障诊断】:专家分析与解决方案速递
LECP Server版本更新解读:新特性全面剖析与升级实践指南
SVG动画进阶必学:动态属性与关键帧的6大应用技巧
无线通信中的QoS保障机制:10大策略确保服务质量
【OpenResty新手必备】:一步到位部署你的首个应用
【数据安全守护者】:确保高德地图API数据安全的实践技巧


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )





















