实时搜索与更新:Lucene Near-Real-Time技术解析
发布时间: 2023-12-15 12:09:30 阅读量: 46 订阅数: 22 

实时搜索引擎源码LUCENE
# 第一章:Lucene Near-Real-Time技术概述
## 1.1 什么是Lucene Near-Real-Time技术
Lucene Near-Real-Time技术是基于Lucene的一种实时搜索与更新的解决方案。它能够在索引更新后几乎立即反映在搜索结果中,实现了近乎实时的搜索体验。
## 1.2 Lucene Near-Real-Time对实时搜索与更新的重要性
实时搜索与更新是许多应用领域的关键需求,例如监控系统、金融交易系统和电子商务平台等。传统的搜索引擎需要较长时间的索引构建和搜索刷新过程,无法满足这些实时性需求。而Lucene Near-Real-Time技术通过将索引和搜索过程的相关步骤进行优化,实现了接近实时的搜索和更新能力,极大地提升了系统的实时性。
## 1.3 Lucene Near-Real-Time与实时搜索的关系
虽然Lucene Near-Real-Time技术能够实现接近实时的搜索和更新,但它并非真正的实时搜索引擎。实时搜索引擎通常涉及更复杂的架构和算法,能够实时处理大规模、高并发的查询请求。而Lucene Near-Real-Time技术更适用于中小规模数据实时搜索和更新的场景,具备较低的延迟和较高的吞吐量。
## 第二章:Lucene基础知识回顾
Lucene作为一款优秀的全文检索引擎,其基础知识是我们学习Lucene Near-Real-Time技术的基础。在本章中,我们将回顾Lucene索引和搜索的基本原理,了解Lucene中的数据结构和算法,并探讨Lucene近实时搜索与标准搜索的区别。
### 2.1 Lucene索引和搜索的基本原理
Lucene的核心是基于倒排索引的检索机制。在倒排索引中,文档中的每个词都被映射到包含该词的文档列表。这使得Lucene能够高效地进行关键词搜索,并且支持丰富的复杂查询操作。
```java
// Java示例代码
// 创建索引
Analyzer analyzer = new StandardAnalyzer();
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer);
Directory directory = FSDirectory.open(Paths.get("index"));
IndexWriter indexWriter = new IndexWriter(directory, indexWriterConfig);
Document doc = new Document();
doc.add(new TextField("content", "Lucene is a powerful full-text search engine", Field.Store.YES));
indexWriter.addDocument(doc);
indexWriter.close();
// 搜索
IndexReader indexReader = DirectoryReader.open(directory);
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
QueryParser queryParser = new QueryParser("content", analyzer);
Query query = queryParser.parse("Lucene");
TopDocs topDocs = indexSearcher.search(query, 10);
for (ScoreDoc scoreDoc : topDocs.scoreDocs) {
System.out.println("Document ID: " + scoreDoc.doc + ", Score: " + scoreDoc.score);
}
indexReader.close();
```
上面是一个简单的Java示例代码,展示了如何使用Lucene进行索引和搜索操作。
### 2.2 Lucene中的数据结构和算法
Lucene使用了一些重要的数据结构和算法来实现高效的索引和搜索功能。比如倒排索引结构、Trie树、布隆过滤器等。这些数据结构和算法的选择和优化对于Lucene的性能和稳定性至关重要。
```python
# Python示例代码
# 创建索引
from whoosh.index import create_in
from whoosh.fields import *
schema = Schema(content=TEXT)
index = create_in("indexdir", schema)
writer = index.writer()
writer.add_document(content="Lucene is a powerful full-text search engine")
writer.commit()
# 搜索
from whoosh.qparser import QueryParser
from whoosh import scoring
searcher = index.searcher()
query = QueryParser("content", index.schema).parse("Lucene")
results = searcher.search(query, limit=10, terms=True, scored=True, sortedby=scoring.BM25F())
for hit in results:
print("Document ID:", hit.docnum, ", Score:", hit.score)
```
这段Python示例代码展示了使用Whoosh库进行索引和搜索操作,Whoosh是一个基于Lucene的全文搜索引擎库。
### 2.

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了Lucene搜索引擎的核心原理和高级技术,涵盖了从索引构建到搜索优化的方方面面。首先介绍了Lucene索引与搜索原理,讲解了如何实现准确搜索和文本分析与查询解析。随后深入探讨了高级查询与索引优化的技术,包括搜索与过滤、国际化与全文检索、排序与分组技术,以及分页与搜索结果优化等。此外,还深入解析了实时搜索与更新、文本相似度计算、基于权重的评分算法等高级技术,并探讨了关键词高亮技术、多字段查询优化、模糊查询应用等实用技术。最后,还涉及了字段存储原理、分布式搜索与扩展、文档分类与语义分析、时间范围查询等领域的内容,并介绍了相关性算法与自定义搜索逻辑的实现。通过本专栏的学习,读者将全面掌握Lucene搜索引擎的核心技术和应用,为构建高效的搜索系统提供全面的指导和参考。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【软件技术方案书中的核心要素】:揭示你的竞争优势,赢得市场
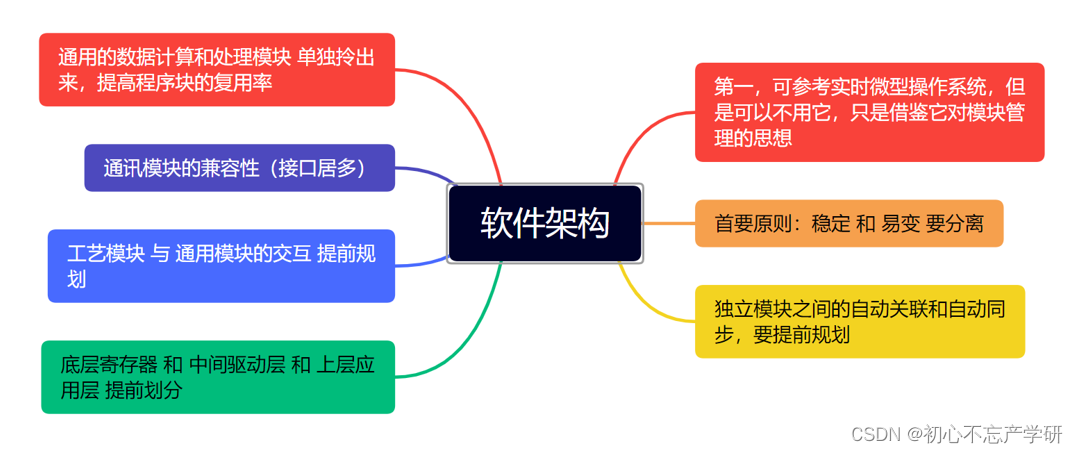
# 摘要
本文旨在全面阐述软件技术方案书的编写与应用,从理论框架到实践指南,再到市场竞争力分析和呈现技巧。首先介绍了软件架构设计原则,如高内聚低耦合和设计模式的应用,然后分析了技术选型的考量因素,包括性能、成熟度、开源与商业软件的选择,以及安全策略和合规性要求。在实践指南部分,探讨了需求分析、技术实施计划、产品开发与迭代等关键步骤。接着,文章对技术方案书的市场竞争力进行了分析,包括竞
【cuDNN安装常见问题及解决方案】:扫清深度学习开发障碍
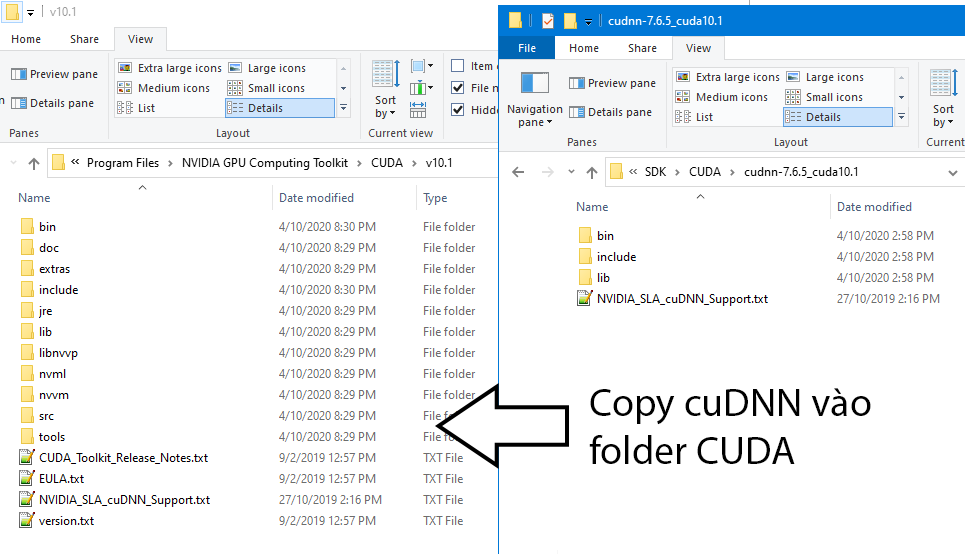
# 摘要
cuDNN作为深度学习库的重要组件,为加速GPU计算提供了基础支持。本文首先介绍了cuDNN的基本概念及其与CUDA的关系,并指导读者完成安装前的准备工作。接着,详细说明了cuDNN的官方安装过程,包括系统兼容性考虑、安装步骤及安装后的验证。针对容器化环境,本文还提供了Docker集成cuDNN的方法。针对安装后可能出现的问题,本文探讨了常见的错误诊断及性能优化策略。进一步地,本
【OpenADR 2.0b 与可再生能源】:挖掘集成潜力,应对挑战
# 摘要
本文系统地介绍了OpenADR 2.0b 标准,并探讨了其在可再生能源和智能电网融合中的关键作用。首先概述了OpenADR 2.0b 标准的基本内容,分析了可再生能源在现代能源结构中的重要性以及需求响应(DR)的基本原理。随后,文章深入探讨了OpenADR 2.0b 如何与智能电网技术相融合,以及在实践中如何促进可再生能源的优化管理。通过具体案例分析,本文揭示了OpenADR 2.0b 应用的成功因素和面临的挑战,并对未来面临的挑战与机遇进行了展望,特别指出了物联网(IoT)和人工智能(AI)技术的应用前景,提出了相应的政策建议。本文的研究为推动可再生能源与需求响应的结合提供了有价值
【UDS故障诊断实战秘籍】:快速定位车辆故障的终极指南

# 摘要
统一诊断服务(UDS)诊断协议是汽车电子领域内标准化的故障诊断和程序更新协议。本文首先介绍了UDS协议的基础知识、核心概念以及诊断消息格式,之后深入探讨了故障诊断的理论知识和实战中常见的UDS命令。文中对不同UDS诊断工具及其使用环境搭建进行了对比和分析,并且提供了实战案例,包括典型故障诊断实例和高级技术应用。此外,本文还
【HMI触摸屏通信指南】:自由口协议的入门与实践

# 摘要
自由口协议作为一种广泛应用于嵌入式系统的串行通信协议,提供了一种灵活的设备间通信方式。本文首先概述了自由口协议的基本概念及其理论基础,包括工作原理、通信模式以及
日志数据质量提升:日志易V2.0清洗与预处理指南
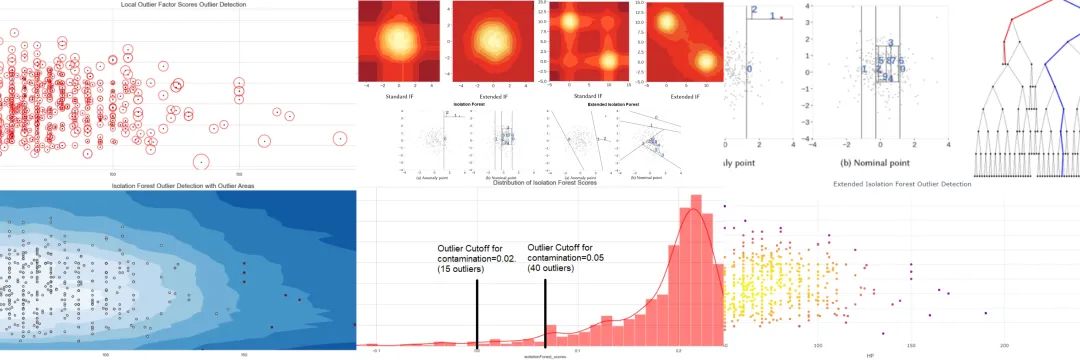
# 摘要
日志数据在系统监控、故障诊断及安全分析中扮演着至关重要的角色,其质量和处理方式直接影响到数据分析的准确性和效率。本文重点探讨了日志数据的重要性及其质量影响,详细阐述了日志数据清洗的基本原理和方法,涵盖不一致性、缺失值、噪声和异常值的处理技术。本文还详细解析了日志预处理技术,包括数据格式化、标准化、转换与集成及其质量评估。通过介绍
案例剖析:ABB机器人项目实施的最佳实践指南

# 摘要
本论文针对ABB机器人技术的应用,提供了一套系统的项目需求分析、硬件选型、软件开发、系统集成到部署和维护的全面解决方案。从项目需求的识别和分析到目标设定和风险管理,再到硬件选型时载荷、
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )