WebMagic中PageProcessor的作用及使用方法
发布时间: 2024-02-23 00:41:37 阅读量: 62 订阅数: 34 
# 1. 什么是WebMagic框架
WebMagic框架是一个开源的Java网络爬虫框架,能够方便快捷地实现网络爬虫功能。它基于开放源码的全站数据采集工具,支持多线程,分布式,定时任务等功能,同时具有良好的扩展性和灵活性。
## 1.1 WebMagic框架的介绍
WebMagic框架的设计理念是面向接口开发,对于爬虫的各个模块都有相应的接口,用户可以根据自己的需求定制实现。该框架采用了基于Java的多线程技术,能够高效地并发爬取网页内容。
## 1.2 WebMagic框架的特点
- 支持多种网页内容格式的解析,如HTML、JSON、XML等。
- 提供了丰富的API,方便用户定制各种爬虫需求。
- 支持分布式爬虫,可以在集群环境下运行。
- 内置了一些常用的爬虫组件,如Downloader、Scheduler等。
- 易于使用,文档详尽,社区活跃。
## 1.3 WebMagic框架的优势
- 可扩展性强:用户可以根据自己的需求,定制各类爬虫组件。
- 易于使用:框架设计简洁,API清晰,上手门槛低。
- 高效性能:基于多线程设计,能够高效并发爬取网页内容。
- 社区支持:WebMagic拥有一个活跃的开源社区,用户可以分享经验、交流问题。
以上是关于WebMagic框架介绍的内容,接下来将深入探讨PageProcessor在WebMagic框架中的作用。
# 2. PageProcessor在WebMagic中的作用
在WebMagic框架中,PageProcessor是一个关键的组件,负责解析网页、抽取数据、以及发现新的链接。通过PageProcessor,我们可以定义如何爬取目标网站的数据,对数据进行加工处理,并将数据传递给其他组件进行存储或进一步处理。
### 2.1 PageProcessor的定义
PageProcessor是WebMagic中的一个接口,提供了处理网页的方法和规范,用户需要自定义实现PageProcessor接口,来定制爬取过程中的数据抽取和处理逻辑。
### 2.2 PageProcessor的主要功能
PageProcessor主要用于解析网页内容,提取目标数据,并将数据存储到Page对象中。通过PageProcessor,可以实现对网页内容的定制化处理,实现数据的精准抽取和清洗。
### 2.3 PageProcessor与其他模块的关系
PageProcessor通常与Downloader、Scheduler等模块配合使用,Downloader用于下载网页内容,Scheduler用于调度URL队列。PageProcessor负责处理下载的网页内容,提取数据并生成新的URL链接,将解析后的数据交给Pipeline模块进行存储等后续处理。
通过PageProcessor的定义和实现,我们可以更加灵活地控制爬取过程,实现定制化的数据抽取与处理逻辑。
# 3. PageProcessor的使用方法
在WebMagic框架中,PageProcessor是一个核心组件,负责解析页面的内容并提取需要的数据。在本章中,我们将详细介绍如何使用PageProcessor来实现网页内容的解析和数据提取。
#### 3.1 创建PageProcessor实现类
首先,我们需要创建一个实现了PageProcessor接口的类,这个类将负责定义我们需要的网页解析逻辑。我们可以通过继承抽象类AbstractPageProcessor来实现PageProcessor接口,也可以直接实现PageProcessor接口。
```java
public class MyPageProcessor implements PageProcessor {
// 实现PageProcessor接口的方法
}
```
#### 3.2 重写PageProcessor的方法
在PageProcessor实现类中,我们需要重写PageProcessor接口定义的方法,主要包括process方法、getSite方法等。在process方法中编写网页内容的解析逻辑,从页面中提取需要的数据。
```java
@Override
public void process(Page page) {
// 解析页面内容,提取数据
}
@Override
public Site getSite() {
return site;
}
```
#### 3.3 配置PageProcessor
最后,我们需要将PageProcessor实现类与Spider对象关联起来,通过Spider对象来启动爬虫任务,并指定要爬取的URL、PageProcessor对象等配置信息。
```java
Spider.create(new MyPageProcessor())
.addUrl("http://www.example.com")
.thread(5)
.run();
```
通过以上步骤,我们就可以使用PageProcessor来实现网页内容的解析和数据提取功能。在实际应用中,我们可以根据具体的需求定制PageProcessor实现类,以满足不同的爬虫任务要求。
# 4. PageProcessor中的主要方法
在WebMagic中,PageProcessor是一个非常重要的组件,它主要负责处理爬取到的页面信息,并提取需要的数据。在PageProcessor中,有一些主要的方法需要我们重点关注和使用,下面将详细介绍这些方法的作用和用法。
#### 4.1 process方法详解
process方法是PageProcessor中最核心的方法之一,它主要用于解析和处理爬取到的页面信息,提取目标数据。我们需要在这个方法中编写解析页面的逻辑,包括用正则表达式、XPath、CSS选择器等方法来提取页面中的数据。
```java
@Override
public void process(Page page) {
// 解析页面,提取需要的数据
List<String> dataList = page.getHtml().css("div.data-list").all();
// 处理提取出来的数据
for(String data : dataList) {
// TODO: 数据处理逻辑
}
// 将解析后的数据存储到Page中
page.putField("data", dataList);
}
```
在process方法中,我们首先通过page.getHtml()方法获取页面的HTML代码,然后利用css、xpath等方法提取出需要的数据,并对数据进行处理。最后,我们将处理后的数据存储到Page中的字段中,以便后续处理或存储。
总结:process方法是PageProcessor中最主要的方法,用于处理页面数据并提取目标内容。通过合理的编写和优化,可以有效提高爬取效率和准确性。
#### 4.2 addTargetRequests方法介绍
addTargetRequests方法用于向爬取队列中添加新的URL,以便继续爬取新的页面数据。我们可以在process方法中根据需要动态添加新的URL,实现页面间的跳转和数据的完整爬取。
```java
@Override
public void process(Page page) {
// 解析页面,提取需要的数据
List<String> links = page.getHtml().links().regex("https://www.example.com/list/.*").all();
// 将新的URL添加到爬取队列中
page.addTargetRequests(links);
}
```
在上面的例子中,我们通过links()方法获取页面中的所有链接,并筛选出符合条件的URL链接,然后通过addTargetRequests方法将这些链接添加到爬取队列中,实现页面间的跳转和数据的连续爬取。
总结:addTargetRequests方法用于向爬取队列中添加新的URL,实现页面间的跳转和数据的完整爬取,是PageProcessor中非常重要的方法之一。
#### 4.3 getPage方法的应用
getPage方法用于获取当前页面的信息,包括页面的URL、HTML代码、请求头信息等。通过getPage方法,我们可以在PageProcessor中获取和操作当前页面的信息,以便进行处理和数据提取。
```java
@Override
public void process(Page page) {
// 获取当前页面的URL
String url = page.getUrl().toString();
// 获取当前页面的HTML代码
String html = page.getHtml().toString();
// 获取当前页面的请求头信息
Map<String, String> headers = page.getRequest().getHeaders();
}
```
在上面的例子中,我们通过getPage方法分别获取当前页面的URL、HTML代码和请求头信息,这些信息可以帮助我们更好地处理页面数据,提取目标内容。
总结:getPage方法可以帮助我们获取当前页面的信息,包括URL、HTML代码等,是PageProcessor中常用的方法之一。通过合理使用getPage方法,可以更高效地进行页面处理和数据提取。
# 5. PageProcessor的实际案例分析
在本章节中,我们将通过实际案例来详细分析如何使用WebMagic中的PageProcessor进行网页数据的爬取和处理。
#### 5.1 爬取指定网站数据
首先,我们需要定义一个PageProcessor的实现类,然后重写其中的方法来实现对指定网站数据的爬取。具体代码如下:
```java
public class MyPageProcessor implements PageProcessor {
@Override
public void process(Page page) {
// 使用XPath或正则表达式提取需要的数据
List<String> dataList = page.getHtml().xpath("div[@class='data']").all();
// 处理数据并存储
for (String data : dataList) {
// 进行数据处理
// 存储数据到数据库或文件等
}
// 添加新的URL到待爬取队列
page.addTargetRequest("http://www.example.com/nextPage");
}
@Override
public Site getSite() {
// 配置爬虫参数
return Site.me()
.setCharset("utf-8")
.setRetryTimes(3)
.setSleepTime(1000)
.setUserAgent("Mozilla/5.0");
}
}
```
#### 5.2 数据处理与存储
在爬取到数据之后,我们可以通过PageProcessor中的process方法进行数据处理,然后将数据存储到数据库或文件中。这部分具体代码根据实际情况会有所不同,可以根据具体需求进行定制。
#### 5.3 异常处理与调试技巧
在实际应用中,经常会遇到一些异常情况,例如网络连接超时、页面结构变化等问题。在PageProcessor中,我们可以通过try-catch语句来捕获异常,并进行相应的处理,比如记录日志或重试等操作。另外,WebMagic提供了丰富的调试工具,如打印请求和响应信息、设置断点调试等方式来帮助我们定位和解决问题。
通过本章节的分析,我们可以清晰地了解PageProcessor在实际使用中的具体应用方法和注意事项。
# 6. PageProcessor使用注意事项与扩展
在使用WebMagic框架的PageProcessor时,需要注意一些使用注意事项以及可以进行的扩展和定制化操作。
### 6.1 避免被网站封锁的策略
在爬取数据时,为了避免被网站封锁,可以采取以下策略:
- 控制爬取频率,避免过于频繁的请求
- 设置合理的User-Agent,模拟真实用户访问
- 使用IP代理池,避免单一IP频繁请求
- 遵守Robots协议,避免爬取禁止访问的页面
### 6.2 PageProcessor的扩展与定制
PageProcessor可以根据具体需求进行扩展与定制:
- 定制特定网站的页面解析规则,实现更精准的数据提取
- 实现自定义的数据处理逻辑,比如数据清洗、去重、转换等
- 扩展新的功能,比如持久化存储、数据分析、邮件通知等
### 6.3 最佳实践与使用建议
在使用PageProcessor时,一些最佳实践与使用建议包括:
- 编写可扩展、易维护的PageProcessor代码
- 尽量使用变量和常量进行配置,便于后续调整与维护
- 结合其他模块(Downloader、Scheduler等)进行定制化,实现更灵活的爬取策略
通过注意遵守规则并合理定制PageProcessor,能够实现更高效、稳定的数据爬取与处理。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以Java爬虫框架WebMagic为主题,深入探讨了WebMagic框架的功能与应用。从WebMagic中PageProcessor的作用及使用方法、定制化爬取规则、模拟登录爬取数据等方面展开讨论,帮助读者全面了解WebMagic框架的实际操作与应用技巧。同时,还详细分析了利用WebMagic实现分布式爬虫的技术挑战与解决方案,以及数据解析中Selector的灵活运用和爬虫任务调度管理中Scheduler的功能与配置,为读者提供技术实现的参考与借鉴。此外,还通过特定情境下的动态页面爬取技巧与JavaScript渲染页面抓取实战,展示了WebMagic框架在动态网页处理方面的应用实践。通过本专栏的学习,读者将能够全面掌握WebMagic框架的使用方法,并具备在实际项目中应用WebMagic进行数据爬取与处理的能力。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
超级电容充电技术大揭秘:全面解析9大创新应用与优化策略
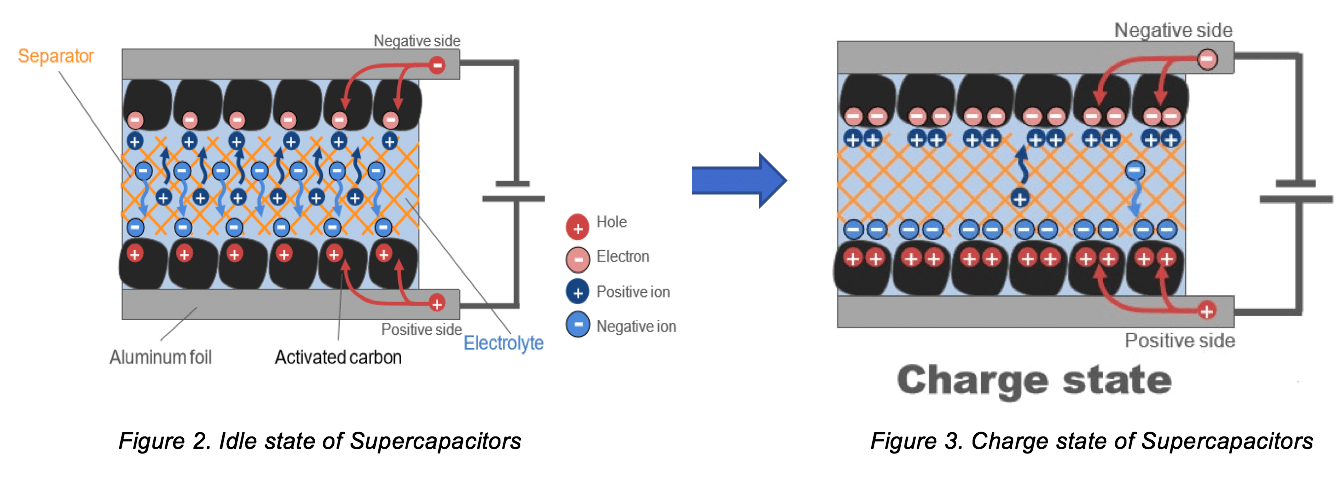
# 摘要
超级电容器作为能量存储与释放的前沿技术,近年来在快速充电及高功率密度方面显示出巨大潜力。本文系统回顾了超级电容器的充电技术,从其工作原理、理论基础、充电策略、创新应用、优化策略到实践案例进行了深入探讨。通过对能量回收系统、移动设备、大型储能系统中超级电容器应用的分析,文章揭示了充电技术在不同领域中的实际效益和优化方向。同时,本文还展望了固态超级电容器等新兴技术的发展前景以及超级电
【IAR嵌入式系统新手速成课程】:一步到位掌握关键入门技能!
# 摘要
本文介绍了IAR嵌入式系统的安装、配置及编程实践,详细阐述了ARM处理器架构和编程要点,并通过实战项目加深理解。文章首先提供了IAR Embedded Workbench的基础介绍,包括其功能特点和安装过程。随后深入讲解了ARM处理器的基础知识,实践编写汇编语言,并探讨了C语言与汇编的混合编程技巧。在编程实践章节中,回顾了C语言基础,使用IAR进行板级支持包的开发,并通过一个实战项目演示了嵌入式系统的开发流程。最后,本文探讨了高级功能,如内存管理和性能优化,调试技术,并通过实际案例来解决常见问题。整体而言,本文为嵌入式系统开发人员提供了一套完整的技术指南,旨在提升其开发效率和系统性能
DSP28335与SPWM结合秘籍:硬件和软件实现的完整指南
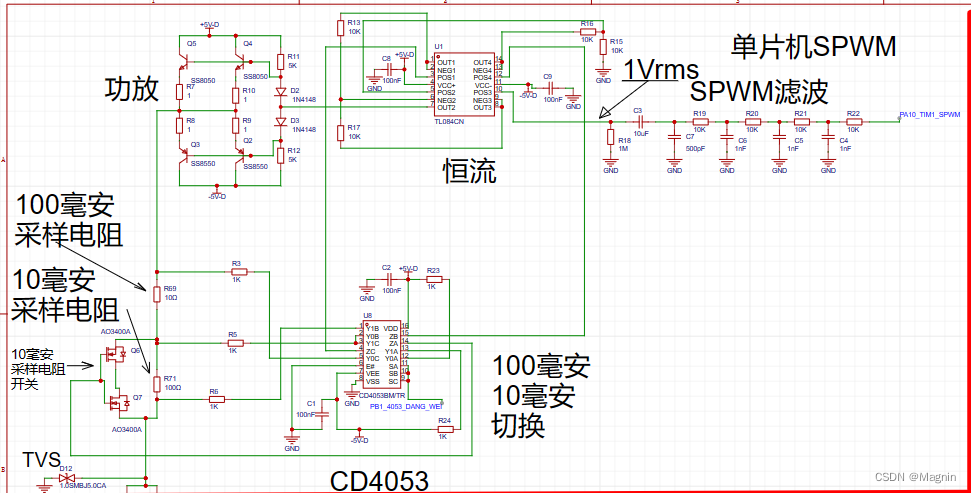
# 摘要
本文介绍了DSP28335微控制器的基础知识,并深入探讨了SPWM(正弦脉宽调制)技术的理论及其在电机控制中的应用。文章详细阐述了SPWM的基本原理、电机控制优势以及信号的生成方法,同时结合DSP28335微控制器的硬件架构,提出了SPWM信号输出电路设计的方案,并详细描述了硬件调试与测试过程。在软件实现方面,本文讨论了DSP28335的软件开发环境、SPWM控制算法编程
【C++二叉树算法精讲】:从实验报告看效率优化关键

# 摘要
本文详细探讨了C++中二叉树的概念、算法理论基础、效率分析、实践应用以及进阶技巧。首先,介绍了二叉树的基本概念和分类,包括完全二叉树、满二叉树、平衡二叉树和红黑树等。随后,对二叉树的遍历算法,如前序、中序、后序和层序遍历进行了讨论。本文还分析了二叉树构建和修改的操作,包括创建、删除和旋转。第三章专注于二叉树算法的效率,讨论了时间复杂度、空间复杂度和算法优化策略。第四章探讨了二叉树
Origin图表设计秘籍:这7种数据展示方式让你的报告更专业
# 摘要
本论文深入探讨了Origin图表设计的全面概述,从基础理论到高级技巧,再到在数据报告中的实际应用,以及未来的发展趋势。文章首先阐述了数据可视化的基本理论,强调了其在信息传达和决策支持方面的重要性,并介绍了不同图表类型及其设计原则。接着,通过七种专业图表的设计实践,详细解释了各种图表的特点、适用场景及其设计要点。文章还介绍了Origin图表的高级技巧,包括模板创建、数据处理和交互式图
【故障录波系统接线实战】:案例分析与故障诊断处理流程
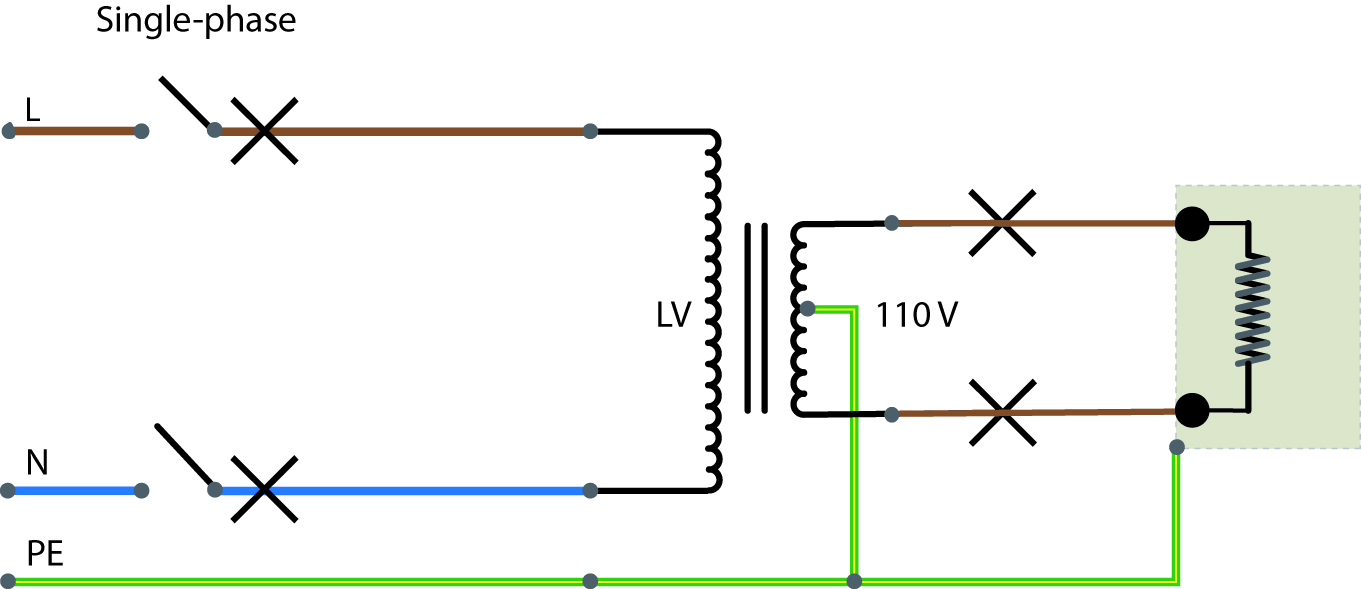
# 摘要
故障录波系统是一种用于电力系统故障检测和分析的关键技术,它对维护电网的稳定运行和提高故障诊断的效率具有重要意义。本文首先概述了故障录波系统及其应用背景,然后详细介绍了系统的硬件组成,包括数据采集、处理与存储单元,以及硬件故障的诊断与排查方法。接着,本文探讨了故障录波系统的软件架构,包括功能模块、操作流程和界面介绍,并且分析了软件故障的诊断与优化。实战案例分析部分通过具体案例,展示了故障录波数据的解读和故障处理流程。
PHY6222蓝牙芯片全攻略:性能优化与应用案例分析

# 摘要
本文对PHY6222蓝牙芯片进行了全面的概述,详细分析了其在硬件、软件以及系统层面的性能优化方法,并通过实际案例加以说明。同时,探讨了PHY6222蓝牙芯片在智能设备、医疗设备和智能家居等多种应用中的具体应用案例,以及其面临的市场趋势和未来发展的挑战与机遇。本文旨在为相关领域的研究者和开发者提供深入的技术洞察,并为PHY6222蓝牙芯片的进一步技术创新和市场应用提供参考。
大数据项目中的DP-Modeler应用:从理论到实战的全面剖析
# 摘要
本文深入探讨了大数据项目实施的关键环节,并着重介绍了DP-Modeler工具的基本原理、实践操作和高级应用。文章首先概述了大数据项目的重要性,并简要介绍了DP-Modeler的数据模型及其架构。随后,文章详细阐述了DP-Modeler的安装、配置、基础使用以及实践操作中的数据预处理、模型构建和部署监控方法。此外,高级应用章节涵盖了复杂数据处理、自动化流程及在分布
【AB-PLC中文指令集:高效编程指南】:编写优秀代码的关键技巧

# 摘要
本文全面介绍了AB-PLC中文指令集及其在PLC编程中的应用。首先概述了AB-PLC中文指令集的基础知识,随后深入探讨了PLC的工作原理和架构、数据类型与寻址模式,以及中文指令集的语法结构。在PLC程序开发流程章节中,本文详述了编写程序前的准备、中文指令集的编程实践以及程序测试与调试技巧。接着,本文进一步探索了高级编程技术,包括结构化编程方法、高级指令应用技巧以及PLC与
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )