Anaconda中Jupyter Notebook的优化与调优
发布时间: 2024-04-16 14:43:19 阅读量: 115 订阅数: 60 

Pandas库的一些补充,以及数据的载入与预处理,anaconda里面的jupyter notebook运行

# 1. Anaconda与Jupyter Notebook的基本介绍
Anaconda是一个开源的Python发行版,集成了大量常用的科学计算和数据分析库,可以方便地进行环境管理和包管理。通过Anaconda,用户可以快速搭建Python开发环境,提高工作效率。
Jupyter Notebook是一个基于Web的交互式计算工具,支持多种编程语言,最常用于Python。它的特点包括可以在浏览器中编写和分享代码、文本、数学方程式和可视化的笔记。Jupyter Notebook的安装简便,只需几个命令即可完成,启动后会在浏览器中打开一个本地服务器,用户可以通过浏览器进行交互操作。其功能强大,支持快速原型开发、数据可视化和教育等多种应用场景。
# 2. 提升Jupyter Notebook使用体验的基本技巧
## 2.1 Jupyter Notebook界面优化
### 2.1.1 更改Jupyter Notebook主题和字体
Jupyter Notebook的默认主题可能无法满足所有用户的审美需求,因此可以通过安装主题插件来进行主题更改。首先,使用以下命令安装主题插件:
```bash
pip install jupyterthemes
```
### 2.1.2 自定义Jupyter Notebook界面风格
通过Jupyter Themes插件,可以自定义Jupyter Notebook的界面风格。例如,要设置主题为'onedork'并增大文本字号,可以执行以下命令:
```bash
jt -t onedork -fs 95
```
### 2.1.3 使用Jupyter Notebook扩展插件提升交互体验
在Jupyter Notebook中安装扩展插件可以大大提升交互体验。使用以下命令安装Jupyter_contrib_nbextensions:
```bash
pip install jupyter_contrib_nbextensions
jupyter contrib nbextension install --user
```
## 2.2 Jupyter Notebook代码优化
### 2.2.1 使用Markdown注释、标题和分割线美化笔记
在Jupyter Notebook中,通过使用Markdown语法,可以为代码增加注释、标题和分割线,使笔记更加清晰易读。例如,使用以下Markdown语法:
```markdown
# 标题
这是一个段落
## 小标题
这是另一个段落
```
### 2.2.2 合理使用快捷键和魔术命令提高效率
Jupyter Notebook提供了丰富的快捷键和魔术命令,能够帮助用户高效地编写和执行代码。例如,使用快捷键`Shift + Enter`执行单元格,使用`%timeit`进行代码执行时间分析等。
### 2.2.3 优化Jupyter Notebook代码格式与布局
合理的代码格式和布局能够提高代码的可读性和维护性。在Jupyter Notebook中,可以使用工具如`autopep8`和`jupyterlab_code_formatter`对代码进行格式化。例如,使用以下命令安装`autopep8`:
```bash
pip install autopep8
```
通过以上方法,可以提升Jupyter Notebook的使用体验,使得编程更加高效和愉悦。
# 3.1 Jupyter Notebook内核调优
在 Jupyter Notebook 中,内核是与后端计算引擎通信的关键组件,直接影响到代码的执行速度和效率。通过适当调优 Jupyter Notebook 的内核设置,可以提升代码运行的效率,

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Anaconda安装Python故障排除与优化》专栏深入探讨了使用Anaconda安装和管理Python时可能遇到的常见问题和最佳实践。它提供了分步指南,涵盖了从安装问题到环境配置、版本切换、虚拟环境管理、依赖冲突解决和性能优化等广泛主题。该专栏还详细介绍了Jupyter Notebook的优化、包管理技巧、环境备份和恢复技术,以及与系统环境变量的关系。通过关注故障排除和优化,该专栏旨在帮助用户充分利用Anaconda,以高效和无缝的方式管理其Python环境。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【DEH调节逻辑图解】:掌握基础知识,精通应用

# 摘要
本文系统地介绍了DEH(Digital Electro-Hydraulic)调节系统的理论基础与实践应用。首先解释了DEH系统的工作原理,阐述了其组成和基本流程。接着,文章深入分析了DEH调节中的关键参数,包括压力、温度设定点,流量控制和功率调节,以及PID(比例、积分、微分)控制的解析。此外,本文还探讨了DEH调节系统与其他系统的协同
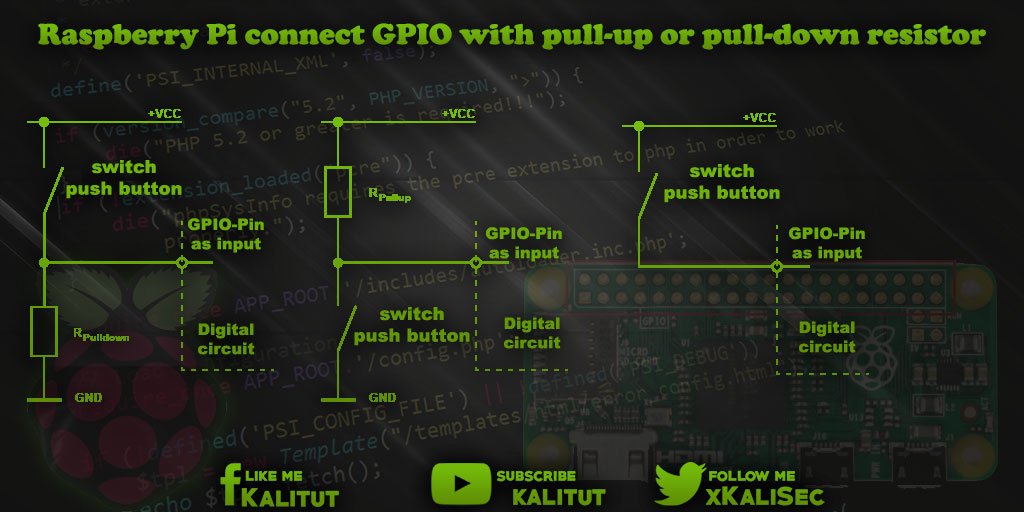
【AT32F435手册深度解读】:揭秘隐藏性能参数与应用技巧
# 摘要
本文全面介绍了AT32F435微控制器,从其概述开始,深入分析了硬件架构和内存存储配置,探讨了高性能的ARM Cortex-M4内核特性及其性能参数。详细讨论了编程与开发环境,强调了IDE配置、调试技巧以及编程接口的优化。文章进一步探索了AT32F435的高级功能,包括电源管理、安全特性、实时时钟等,并分析了在工业自动化控制、消费电子产品和无线通信应用中的
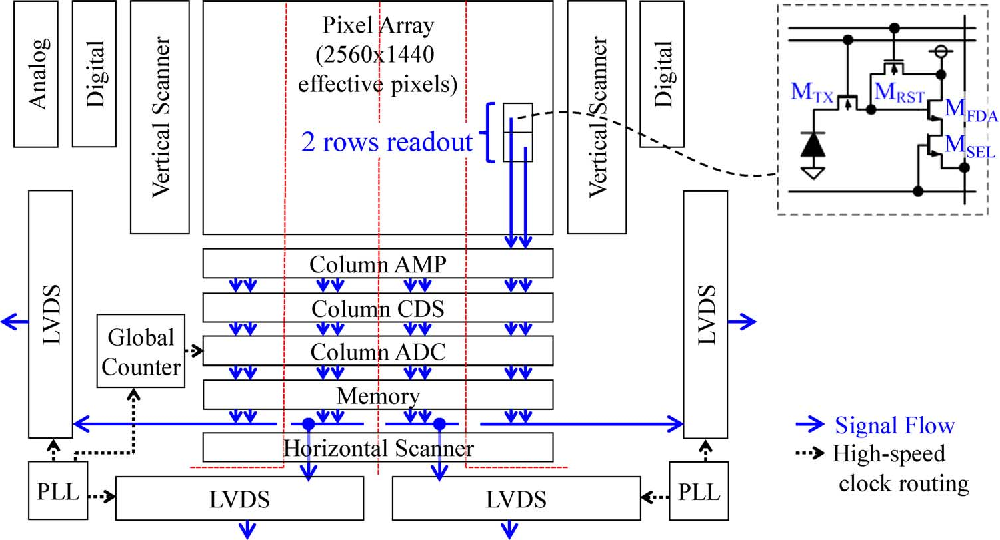
【sCMOS相机驱动电路全攻略】:20年经验大师带你破解设计与故障处理的神秘面纱
# 摘要
本论文全面介绍了sCMOS相机驱动电路的设计原理、实践与高级应用,并对故障处理技巧和未来发展趋势进行了深入探讨。首先概述了sCMOS相机驱动电路的基本概念及其重要性,接着从理论基础入手,详尽分析了sCMOS相机的工作原理、关键参数和信号完整性。在设计实践章节中,讨论了电路设计前期准备、布局布线以及调试测试的
【自动售货机界面设计】:交互逻辑实现的秘诀

# 摘要
自动售货机界面设计是提升用户体验、增强交互效率及实现技术革新的关键要素。本文详细探讨了自动售货机界面设计的理论基础,如用户体验的重要性、界面设计的交互原则及布局视觉层次。接着,文章深入分析了界面交互逻辑,包括导航、交易流程和错误处理的设计。在实践层面,本文阐述了用户研究、原型设计、用户测试以及迭代优化的过程。技术实现部分则讨论了界面开发工具、功能模块编码和测试方法。最后
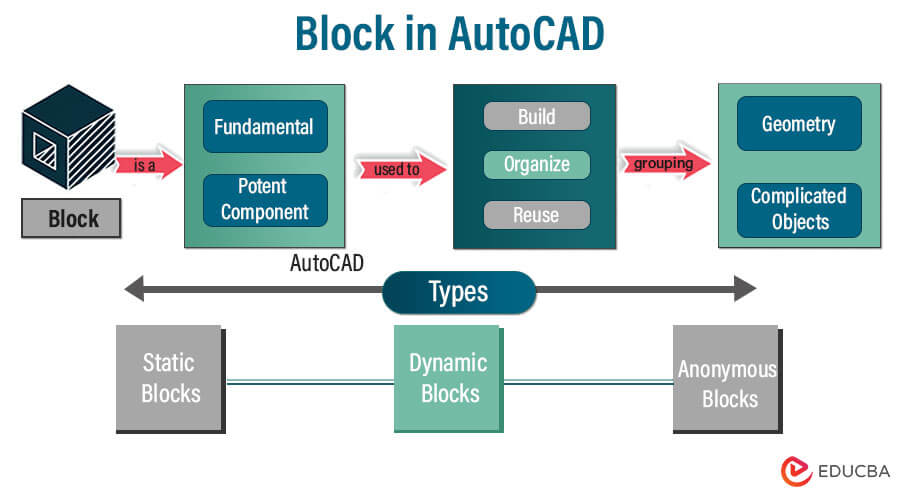
【CAD2002块操作全攻略】
# 摘要
CAD块操作是提高CAD绘图效率和标准化的关键技术。本文旨在介绍CAD块操作的基本知识,包括块的创建、编辑、命名及属性管理。进一步探讨高级技巧,如动态块的创建和使用,以及块与外部数据库的交互。文章还涵盖了块操作在实际应用中的案例分析,例如工程图纸中的块应用,协作设计中块操作的应用,以及自动化工具的开发。最后,本文针对块操作中可能遇到的常见问题,提出相应的诊断方法和性能优化策略,并通过案例
【MATLAB内存布局精通】:数组方向性对性能影响的深入剖析

# 摘要
本文综合探讨了MATLAB中数组方向性对性能的影响,并提出了相应的性能优化策略。首先,从理论层面分析了数组方向性的重要性以及其如何影响缓存效率,并构建了相应的数学模型。其次,本文深入到MATLAB的实践操作,探讨了方向性在性能优化中的具体应用,并通过案例研究展示了方向性优化的实际效果。文章还详细阐述了优化算法的设计原则,研究了MATLAB内置函数及自定义函
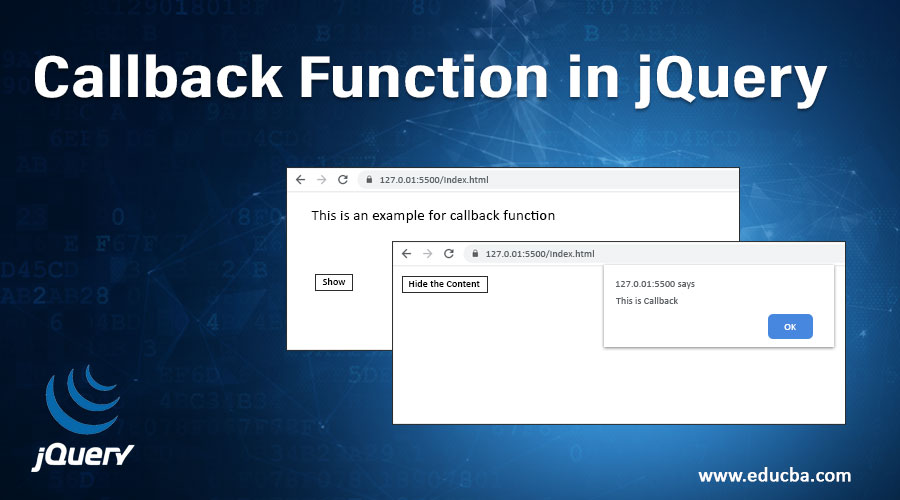
C语言回调函数:使用技巧与实现细节详解
# 摘要
回调函数是软件开发中广泛应用的一种编程技术,它允许在程序执行的某个点调用一个预先定义的函数,从而实现模块化和事件驱动的程序设计。本文详细探讨了回调函数的基本概念和在C语言中使用函数指针实现回调的技巧。通过分析典型的使用场景,如事件处理和算法设计模式,本文提供了如何在C语言中高效且安全地使用回调函数的深入指导。此外,文中还介绍了性能优化和安全注意事项,包括减少开销、防止内存泄漏、回调注入攻
【监控大师】:掌握西门子SINUMERIK测量循环,实现生产过程全面监控
# 摘要
本文全面探讨了SINUMERIK测量循环的理论基础、实践应用以及监控大师系统在其中所扮演的角色。首先介绍了测量循环的基本概念、分类、特点和参数设置,其次解析了监控大师系统的架构和功能模块,并说明了如何利用该系统实现对生产过程的全面监控。文章重点通过实际案例分析,展示了测量循环在生产中的应用,并探讨了监控大师在实时监控和故障预测中的作用,以及如何通过这些技术提升生产效率和质量。最后,文章讨论了系统优化的策略,面临的挑战和未来发展趋势,并分享了成功的案例研究与经验。
# 关键字
SINUMERIK测量循环;系统架构;实时监控;生产效率;故障预测;案例研究
参考资源链接:[西门子SIN
Word 2016 Endnotes加载项:提升工作流的十个技巧

# 摘要
本文系统地介绍了Word 2016中Endnotes加载项的使用方法和技巧,阐述了Endnotes的基本概念、作用以及其在提升文档质量和优化工作流中的重要性。文章详细描述了Endnotes加载项的安装、配置和个性化设置,同时提供了管理尾注的策略和与文献管理软件整合的方法。此外,文章还探讨了在Word中快速插入和编辑Endnotes的技巧,分享了提高文档一致性和工作效率的高
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )