【Python自动化脚本】:提升工作效率的5大实用技巧
发布时间: 2024-12-14 20:51:51 阅读量: 6 订阅数: 11 

参考资源链接:[《Python编程:给孩子玩的趣味指南》高清PDF电子书](https://wenku.csdn.net/doc/646dae11d12cbe7ec3eb21ff?spm=1055.2635.3001.10343)
# 1. Python自动化脚本简介
在如今的数字化时代,自动化已经成为IT行业持续发展的一个关键因素。Python自动化脚本作为提高工作效率和质量的重要工具,越来越受到专业人士的青睐。这一章将为大家提供一个关于Python自动化脚本的概览,包括它的基本概念、应用场景以及其对行业的深远影响。
首先,我们将探讨什么是Python自动化脚本以及它如何使复杂的工作变得简单。Python以其简洁的语法和强大的库支持,已经成为编写自动化脚本的首选语言。接下来,我们将了解Python脚本在不同行业中的应用,包括数据分析、网络管理、系统运维等,从而全面理解其适用性和灵活性。
Python自动化脚本不仅仅是重复工作的替代品,它还能够实现复杂的逻辑操作,提高任务执行的准确性和速度。为了最大化利用Python自动化脚本的潜力,下一章节将深入介绍如何搭建Python环境、掌握基础语法,并开始编写简单的脚本。
# 2. Python自动化脚本基础
## 2.1 Python自动化脚本的环境搭建
### 2.1.1 安装Python环境
Python是动态解释型语言,其安装过程简单且跨平台。在安装Python之前,我们首先需要从Python官方网站下载适合你操作系统的安装包。通常,Python的安装过程分为如下几个步骤:
1. 访问Python官方网站下载页面:https://www.python.org/downloads/
2. 选择合适的Python版本进行下载。建议选择最新版本,但需要确保与你所要操作的系统兼容。
3. 下载完成后,运行安装程序。在安装过程中,记得勾选“Add Python to PATH”选项,这样可以将Python添加到系统的环境变量中,便于在任何目录下调用Python。
例如,在Windows系统中,安装界面通常如下所示:
在Linux系统中,推荐通过包管理器进行安装,例如使用Ubuntu的命令:
```bash
sudo apt-get update
sudo apt-get install python3
```
### 2.1.2 配置Python环境变量
安装Python之后,为了在命令行中直接运行Python脚本,需要配置环境变量。环境变量使系统能够在特定路径下查找可执行文件。对于Python而言,主要是配置PATH环境变量,确保系统能找到Python解释器。
以下是在不同操作系统中配置环境变量的方法:
**在Windows系统中:**
1. 右键点击“此电脑”,选择“属性”。
2. 在弹出的系统窗口中,选择“高级系统设置”。
3. 在系统属性窗口中,点击“环境变量”按钮。
4. 在环境变量窗口中,找到“Path”变量,选择它,然后点击“编辑”。
5. 在编辑环境变量窗口中,点击“新建”,然后输入Python安装路径下的Scripts目录,例如 `C:\Python38\Scripts`。
**在Unix/Linux系统中:**
编辑 `.bashrc` 或 `.bash_profile` 文件来设置环境变量:
```bash
export PATH=$PATH:/usr/local/bin/python3
```
然后,运行以下命令使改动生效:
```bash
source ~/.bashrc
```
完成以上步骤后,可以在命令行中通过输入 `python` 或 `python3` 来启动Python解释器。
## 2.2 Python自动化脚本的基本语法
### 2.2.1 数据类型和变量
Python具备动态类型系统的特性,无需显式声明变量类型。变量在赋值时自动确定类型。Python中常见的数据类型包括:
- 整型(int)
- 浮点型(float)
- 字符串(str)
- 列表(list)
- 元组(tuple)
- 字典(dict)
- 集合(set)
以下是Python中变量和数据类型的简单示例代码:
```python
# 整型
age = 25
print(age, type(age))
# 浮点型
price = 19.99
print(price, type(price))
# 字符串
greeting = "Hello, World!"
print(greeting, type(greeting))
# 列表
fruits = ["apple", "banana", "cherry"]
print(fruits, type(fruits))
# 元组
colors = ("red", "green", "blue")
print(colors, type(colors))
# 字典
person = {"name": "Alice", "age": 30}
print(person, type(person))
# 集合
unique_numbers = {1, 2, 3, 4, 5}
print(unique_numbers, type(unique_numbers))
```
### 2.2.2 控制流语句
控制流语句允许Python根据条件执行不同的代码块,包括条件语句(if-elif-else)和循环语句(while和for)。
```python
# 条件语句示例
if age >= 18:
print("You are an adult.")
elif age >= 13:
print("You are a teenager.")
else:
print("You are a child.")
# 循环语句示例
# 使用while循环
count = 0
while count < 5:
print("Counting:", count)
count += 1
# 使用for循环
fruits = ["apple", "banana", "cherry"]
for fruit in fruits:
print(fruit)
```
### 2.2.3 函数的定义和使用
函数在Python中是通过关键字 `def` 定义的,用于封装可重复使用的代码块。函数可以有参数和返回值。
```python
# 定义函数
def greet(name):
return "Hello, " + name + "!"
# 调用函数
message = greet("Alice")
print(message)
```
## 2.3 Python自动化脚本的模块和包管理
### 2.3.1 模块的概念和导入
在Python中,模块是指一个包含Python代码的文件。使用模块可以让代码的组织更加模块化,易于维护和复用。Python的许多功能都是通过导入标准库中的模块来实现的。
导入模块的语法如下:
```python
import module_name
```
一个使用标准库 `math` 模块的例子:
```python
import math
# 使用math模块中的sqrt函数
result = math.sqrt(16)
print("The square root of 16 is:", result)
```
### 2.3.2 创建和使用包
包是一种结构化Python代码的方式,它允许一个有逻辑关系的模块集合打包在一起,并提供一个统一的命名空间。创建包通常需要一个 `__init__.py` 文件,这个文件可以为空,但是它表明了目录可以被视为一个Python包。
在创建和使用包的流程中,重要的是理解如何组织代码和如何在代码中正确地导入包。
创建包的基本结构:
```
my_package/
__init__.py
module1.py
module2.py
sub_package/
__init__.py
submodule1.py
```
使用包的示例:
```python
from my_package import module1
```
### 2.3.3 常用内置模块介绍
Python提供了一个丰富的内置模块集合,这些模块使得许多常规任务变得更加容易。以下是几个常用的内置模块:
- `sys`: 与Python解释器紧密相关的变量和函数。
- `os`: 提供了使用操作系统功能的接口。
- `datetime`: 提供日期和时间的处理功能。
- `json`: 提供了处理JSON数据的工具。
例如,使用`os`模块列出文件夹内容的代码:
```python
import os
# 获取当前工作目录
current_path = os.getcwd()
print("Current directory:", current_path)
# 列出目录内容
for entry in os.listdir(current_path):
print(entry)
```
通过以上对Python自动化脚本基础的介绍,读者将掌握如何搭建Python运行环境、理解基础语法、并利用内置模块进行简单的任务。这些基础知识为学习更高级的自动化技术打下了坚实的基础。
# 3. Python自动化脚本进阶技巧
## 3.1 数据处理与分析
### 3.1.1 使用Pandas进行数据清洗
在数据科学领域,Pandas库已经成为处理和分析数据的强大工具。Pandas提供了大量的数据结构和操作函数,使得数据清洗工作变得简单而高效。数据清洗是指发现并修正数据集中的不一致或错误的过程,这是任何数据处理任务的首要步骤。
```python
import pandas as pd
# 加载数据到DataFrame中
df = pd.read_csv('data.csv')
# 处理缺失值
df.dropna(inplace=True) # 删除所有含有缺失值的行
# 处理重复数据
df.drop_duplicates(inplace=True) # 删除重复行
# 数据类型转换
df['date'] = pd.to_datetime(df['date']) # 将日期列转换为日期时间格式
# 数据集切片
filtered_df = df[df['age'] > 30] # 选择年龄大于30的所有记录
# 数据归一化
df['age'] = (df['age'] - df['age'].min()) / (df['age'].max() - df['age'].min())
# 数据集分组聚合
summary = df.groupby('category').agg({'price': ['mean', 'sum']}) # 按分类聚合价格数据
```
在上述代码中,我们演示了数据清洗的几个基本步骤:删除缺失值、去除重复数据、类型转换、数据筛选、归一化和聚合计算。Pandas的`dropna`, `drop_duplicates`, `to_datetime`, `groupby`和`agg`方法极大地简化了这些操作。
### 3.1.2 利用NumPy进行数值计算
NumPy库为Python带来了科学计算的能力。NumPy的核心功能是支持多维数组对象和一系列用于处理这些数组的函数。它在数值计算方面广泛应用于数据分析、机器学习、信号处理等领域。
```python
import numpy as np
# 创建一个NumPy数组
arr = np.array([1, 2, 3, 4, 5])
# 多维数组的创建
matrix = np.array([[1, 2, 3], [4, 5, 6]])
# 数组的基本运算
arr_add = arr + 10 # 每个元素加10
arr_multiply = arr * arr # 每个元素平方
# 矩阵运算
matrix_dot = np.dot(matrix, matrix) # 矩阵乘法
# 统计函数使用
arr_mean = np.mean(arr) # 计算数组平均值
arr_sum = np.sum(arr) # 计算数组总和
```
在这段代码中,我们演示了如何创建NumPy数组、如何进行基本的算数运算以及矩阵运算。NumPy不仅能够处理基础的算术运算,还提供了强大的统计计算功能,如`mean`, `sum`等。
通过这些库和工具,数据科学家和工程师可以有效地进行数据预处理和基本的数值计算,为后续的数据分析和机器学习模型训练打下坚实的基础。
## 3.2 文本处理和文

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Python for Kids》专栏旨在为孩子们提供一个循序渐进的学习平台,从基础编程概念到高级技术。专栏涵盖了广泛的主题,包括:
* 编程入门:引导孩子了解 Python 的基本原理。
* 进阶技巧:帮助初学者提升编程能力。
* 爬虫技术:介绍数据提取和分析的基础知识。
* 数据分析:利用 Pandas 库探索和处理数据。
* 机器学习:使用 Scikit-learn 构建机器学习模型。
* 深度学习:应用 TensorFlow 和 Keras 进行深度学习。
* 物联网:学习使用 Python 构建智能硬件控制程序。
* GUI 开发:掌握 Tkinter 用于创建图形用户界面。
* 自动化脚本:提高工作效率。
* 网络安全:使用 Python 构建网络扫描器。
* 云计算:集成 Python 与 AWS 和 Azure。
* 虚拟环境管理:管理 Python 依赖项。
* 异步编程:深入了解 asyncio 及其应用。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Innovus命令行速成课】:跟着专家一步步精通Innovus使用
# 摘要
Innovus是一个广泛应用于集成电路设计领域的软件工具,本文提供了对Innovus命令行界面的全面概述,详细介绍了其基本操作、项目设置、设计流程实践、高级应用及调试,以及脚本自动化和定制。首先,本文概述了Innovus的命令行界面,为读者提供了项目初始化、导入和环境设置的基础知识。随后,深入探讨了Innovus的设计输入、验证、综合优化、时序分析和报告编制
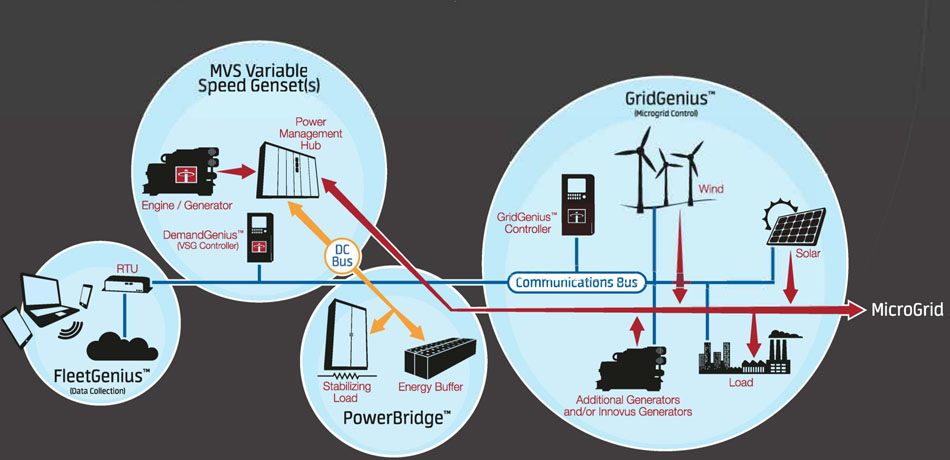
立即行动!PFC 5.0性能调优实战:案例分析与系统优化策略
# 摘要
随着企业级应用的复杂性不断增加,PFC 5.0性能调优变得尤为重要。本文首先阐述了性能调优的必要性和目标,随后深入分析了性能评估的基础知识,包括PFC 5.0的工作原理、关键性能指标以及性能评估工具的使用。接着,文章提出了针对不同系统资源和应用层面的优化策略,并通过案例研究展示了性能调优的实际应用。最后,本文对PFC 5.0的未来发展方向进行了展望,探讨了性能调优在云原
3GPP LTE物理层技术演进大揭秘:36.211标准背后的真相
# 摘要
本文全面介绍了LTE物理层的基础知识、关键技术与技术演进。首先概述了LTE物理层的基本概念,包括物理信道的分类和传输
【Pogene高级应用】:架构设计原理与框架高级使用技巧

# 摘要
Pogene框架是一个高性能的软件开发平台,以其灵活的架构设计、模块化设计思想和全面的配置管理机制而著称。该框架通过高效的数据流处理和优化的高并发控制机制,能够支持复杂系统的构建并实现性能的持续优化。本文详细介绍了Pogene的核心组件、数据处理策略、安全机制以及部署监控工具,并通过案例分析展示了其在实际开发中的应用和性能优化实践。文章最后探讨了Pogene的未来发展
KEA128时钟系统管理:掌握精确时序控制的六大技巧!

# 摘要
本文系统介绍了KEA128时钟系统的结构与特性,并深入探讨了精确时序控制的基础理论和技术。文中首先解析了KEA128时钟架构及其工作原理,并强调了时序控制的重要性。随后,介绍了静态与动态时序分析方法,以及相关分析工具和软件的应用。文章还探讨了硬件技巧,包括时钟信号生成与分配,时钟树布局优化,时钟域
【网络故障终结者】:Keyence PLC网络通信故障诊断与排错指南
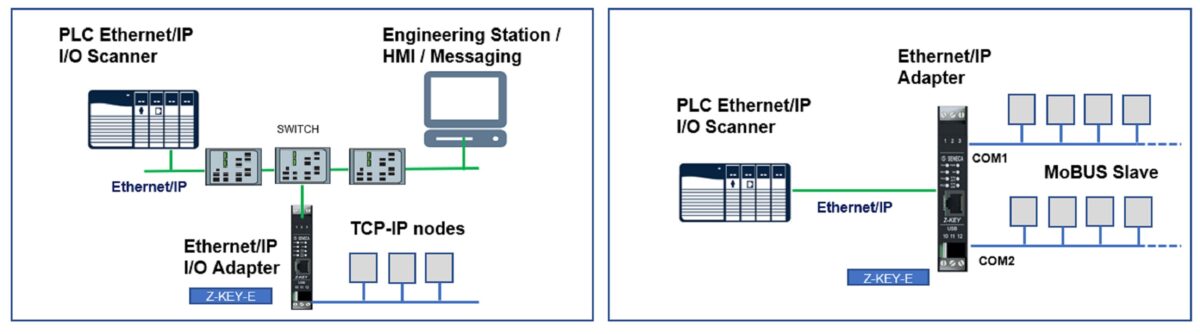
# 摘要
网络通信技术在自动化和智能制造系统中扮演着关键角色,其中,Keyence PLC作为核心设备之一,其网络架构的稳定性和故障处理能力尤为重要。本文首先概述了网络通信的基础知识和Keyence PLC的基本情况,随后深入解析了Keyence PLC的网络架构,并详细讨论了其网络通信的原理和特点。接着,针对网络故障的类型、影响以及诊断理论与方法进行了探讨,并通过实战案例分析,展示如何排查和解决硬
提升PCB设计效率与质量:自动布局布线的5大优化策略
# 摘要
自动布局布线技术在电子设计自动化(EDA)领域扮演着至关重要的角色,它通过优化电路板上的元件布局和布线来提升设计的效率和性能。本文系统地探讨了自动布局布线的基本原理及其重要性,并详细阐述了布局和布线优化的策略。本研究不仅深入解析了优化的理论基础,包括目标、意义、原则和方法,还通过工具和软件的介绍以及实际操作案例分析,展示了
LabVIEW新手福音:
# 摘要
本文系统介绍了LabVIEW编程环境的基础知识、图形化编程原理、实践应用基础、高级功能探索以及项目案例分析。LabVIEW作为一种图形化编程语言,广泛应用于数据采集、硬件接口配置、用户界面设计和文件I/O操作等领域。文章深入探讨了LabVIEW的VI结构、程序控制结构以及驱动程序和硬件通信方式。同时,针对LabVIEW的错误处理、调试技巧和网络功能进
【360安全卫士安装疑难杂症速查手册】:专家级故障诊断与快速处理

# 摘要
本文全面介绍了360安全卫士的安装与维护流程,涵盖了软件概述、系统准备、安装步骤、故障诊断以及高级应用和维护技巧。通过对操作系统兼容性检测、环境变量配置、驱动程序更新和安装过程中的问题处理进行详尽的讨论,确保了软件安装的顺利进行和系统的稳定性。同时,文章还提供了一系列故障处理方法和性能优化指导,帮助用户解决使用中遇到的问题,并通过高级应
【中文短信编码完全解析】:掌握AT指令中GB2312与UTF-8的应用技巧

# 摘要
随着移动通信技术的发展,AT指令在中文短信编码中的应用变得尤为重要。本文首先对AT指令和中文短信编码进行了概述,并深入解析了GB2312与UTF-8编码的基础知识、在AT指令中的应用实例及其实践操作。通过对GB2312和UTF-8性能对比、适用场景选择策略以及迁移和兼容性处理的详细分析,本文提供了关于两种编码方法在实际应用中的比较和选择指南。
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )