CUDA基本概念与架构解析
发布时间: 2024-02-25 15:20:16 阅读量: 23 订阅数: 17 
# 1. CUDA简介
## 1.1 CUDA是什么
在这一节中,我们将介绍CUDA的定义,以及它在GPU计算中的作用和意义。
## 1.2 CUDA的起源和发展历程
这一节将详细介绍CUDA的起源,以及它在GPU计算领域的发展历程,包括重要的里程碑事件。
## 1.3 CUDA的优势及应用领域
在本节中,我们将探讨CUDA相对于传统CPU计算的优势,并且介绍CUDA在不同领域的应用案例,包括科学计算、深度学习、图像处理等方面的应用实践。
# 2. GPU计算基础
在本章中,我们将介绍GPU计算的基础知识,包括GPU与CPU的区别、并行计算概念与原理以及CUDA编程模型概述。
### 2.1 GPU与CPU的区别
传统的CPU是为了顺序串行处理任务而设计的,而GPU则是为了并行处理大规模数据而设计的。CPU通常拥有少量核心(通常为几核至数十核),而GPU拥有数百甚至上千个小核心,可以同时处理大量数据。
### 2.2 并行计算概念与原理
并行计算是指同时处理多个计算任务,由于GPU拥有大量核心,可以同时处理数千个线程,从而极大地提高了计算效率。并行计算的原理是将计算任务分解成多个子任务,分配给不同的核心并行执行。
### 2.3 CUDA编程模型概述
CUDA(Compute Unified Device Architecture)是NVIDIA推出的一种并行计算平台和编程模型。它允许开发人员利用GPU的并行性进行通用目的的计算。CUDA编程模型包括主机(CPU)和设备(GPU)之间的数据传输、核函数的定义和调用,以及并行计算任务的组织和执行。
# 3. CUDA基本概念
在本章中,我们将深入探讨CUDA的基本概念,包括设备与设备内存、核函数与线程、以及块与网格等重要内容。
#### 3.1 设备与设备内存
CUDA程序在GPU设备上执行,每个设备都包含自己的显存,称为设备内存。设备内存具有与主机内存不同的特性和操作方式。在CUDA编程中,需要了解如何管理设备内存,包括内存的分配、释放和数据传输等操作。
#### 3.2 核函数(Kernel)与线程
核函数是在GPU上执行的函数,由大量的线程并行执行。CUDA程序员编写核函数来利用GPU的并行计算能力。每个线程都会执行相同的核函数代码,但是每个线程可以通过自己的ID来识别自己的任务。线程的组织方式会影响到核函数的执行效率和并行度。
#### 3.3 块(Block)与网格(Grid)
在CUDA中,线程被组织成线程块和网格。线程块是一组线程的集合,这些线程可以协同工作并共享共享内存。网格是线程块的集合,它们构成了完整的核函数执行范围。了解如何合理划分线程块和网格对于利用GPU并行计算能力至关重要,也是CUDA编程中的重要技巧之一。
通过深入理解这些基本概念,我们可以更好地理解CUDA程序的执行机制,进而设计和优化CUDA程序,充分发挥GPU的并行计算性能。
# 4. CUDA架构解析
在本章中,我们将深入探讨CUDA的架构和工作原理,理解CUDA如何实现并行计算以及其内部组成结构。
### 4.1 SM(Streaming Multiprocessor)架构
CUDA的核心运算单元是SM(Streaming Multiprocessor),每个SM包含多个CUDA核心,用于执行并行计算任务。SM可以同时处理多个线程块(blocks),并利用线程调度器在等待时刻自动切换线程执行,从而实现并行计算。
### 4.2 CUDA核心组成与工作流程
CUDA在执行计算任务时,按照线程块(blocks)和网格(grid)的结构进行组织,将任务分配给GPU的多个SM并行处理。每个线程块包含多个线程,这些线程共享相同的指令,但有不同的数据。CUDA通过调度器将线程块分发给SM,实现并行计算。
### 4.3 Thread Block与Warps的关系
线程块在执行时会被划分为更小的线程束(Warps),一个线程束包含32个线程,这些线程将被同时加载到SM中执行。线程束内的线程共享相同的指令,同时执行,称为SIMD(Single Instruction, Multiple Data)模式,以提高计算效率。
通过深入理解CUDA的架构解析,可以更好地优化CUDA程序设计,充分利用GPU的并行计算能力,提升程序性能和效率。
# 5. CUDA优化技巧
在第四章中,我们深入了解了CUDA的基本架构和工作原理。本章将重点讨论如何通过优化技巧提高CUDA程序的性能和效率。
#### 5.1 内存访问优化
在CUDA编程中,内存访问通常是性能优化的关键点之一。合理的内存访问模式可以极大地提高程序的运行速度。以下是一些常见的内存访问优化技巧:
- **利用共享内存(Shared Memory):** 共享内存是同一个线程块内的线程可以共享访问的内存,利用共享内存可以减少对全局内存的访问,从而提高访存效率。
- **使用全局内存的连续存储:** 保持内存的连续性可以改善数据访问的效率,尤其是对于全局内存的访问。
- **避免存储器冲突(Memory Bank Conflict):** 当多个线程同时访问同一个内存块的不同地址时,可能会导致存储器冲突,进而影响性能。可以通过调整访问模式来避免存储器冲突。
#### 5.2 Kernel设计与优化
- **精简Kernel函数:** 合理设计Kernel函数,避免冗余计算和逻辑,提高计算效率。
- **减少分支预测错误:** 避免在Kernel函数中使用过多的分支语句,因为分支预测错误可能会导致线程的执行效率降低。
- **利用向量化:** 在CUDA中,可以利用SIMD(Single Instruction Multiple Data)指令集对向量运算进行优化。
#### 5.3 并行化与流水线技术
- **合理并行化任务:** 在GPU中,合理地将任务分配给不同的线程块和线程,以充分利用GPU的并行计算能力。
- **流水线技术:** 通过合理的流水线设计,可以使得不同阶段的计算任务能够流畅地进行,进而提高整体的计算效率。
通过本章的学习,读者将能够掌握一些常用的CUDA优化技巧,从而在实际应用中更好地发挥GPU计算的性能优势。
# 6. 应用实例解析
在本章中,我们将深入探讨CUDA在不同领域的应用实例,包括深度学习、科学计算以及图形图像处理。通过这些实例,读者可以更好地了解CUDA在各种场景下的应用价值和优势。
#### 6.1 CUDA在深度学习中的应用
在深度学习领域,CUDA发挥着重要作用,可以加速神经网络的训练和推断过程。借助CUDA的并行计算能力,大规模的神经网络可以在GPU上高效地进行计算,加快模型的收敛速度,提高训练效率。
以下是一个简单的使用CUDA加速深度学习训练的Python代码示例:
```python
import torch
# 检测当前环境是否支持CUDA
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 定义神经网络模型
model = MyModel().to(device)
# 定义损失函数和优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)
# 加载数据集
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
# 模型训练
for epoch in range(num_epochs):
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 训练完成
```
通过在代码中使用CUDA,我们可以轻松利用GPU的计算能力加速深度学习模型的训练过程,提高算法的效率和性能。
#### 6.2 CUDA在科学计算中的实践
在科学计算领域,CUDA也被广泛应用于加速复杂的计算任务,包括数值模拟、物理建模、数据分析等。通过利用GPU的并行计算能力,科学家们可以更快速地进行大规模数据的处理和计算。
以下是一个使用CUDA加速科学计算的示例代码(假设实现了一个复杂的数值计算函数 `complex_computation`):
```python
import numpy as np
import cupy as cp
# 生成随机数据
data = np.random.randn(1000, 1000)
# 将数据传输到GPU内存
data_gpu = cp.asarray(data)
# 调用复杂计算函数进行计算
result_gpu = complex_computation(data_gpu)
# 将计算结果从GPU内存传输回CPU内存
result = cp.asnumpy(result_gpu)
```
通过将数据传输到GPU上进行并行计算,科学家们可以加速复杂计算任务的执行,节省计算时间,提高科学研究的效率。
#### 6.3 CUDA在图形图像处理中的应用案例
CUDA在图形图像处理领域同样发挥着重要作用,许多图形图像处理软件和库都利用了CUDA的并行计算能力来加速图像处理算法的执行,提高图像处理的效率和质量。
以图像模糊处理为例,以下是一个简单的使用CUDA加速图像模糊处理的Python代码示例:
```python
import cv2
import numpy as np
import cupy as cp
# 读取图像
image = cv2.imread('input.jpg')
# 将图像数据传输到GPU内存
image_gpu = cp.asarray(image)
# 定义模糊处理核函数
kernel = np.ones((5, 5)) / 25
kernel_gpu = cp.asarray(kernel)
# 在GPU上进行卷积运算
blurred_image_gpu = cp.fft.fft2(image_gpu, axes=(0, 1)) * cp.fft.fft2(kernel_gpu, s=image_gpu.shape[:2], axes=(0, 1))
blurred_image = cp.asnumpy(cp.fft.ifft2(blurred_image_gpu, axes=(0, 1)))
# 将处理后的图像数据传输回CPU内存
blurred_image = blurred_image.astype(np.uint8)
```
通过在代码中利用CUDA进行图像处理算法的加速,我们可以更快地对图像进行处理,实现更高效的图像处理应用。
通过以上示例,我们可以看到CUDA在不同领域的应用实例,体现了其在加速计算和提高效率方面的重要作用。希木本章内容对读者有所启发,能够更深入地了解CUDA在实际应用中的价值和作用。
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏致力于探索NVIDIA CUDA编程,以帮助开发者深入了解并熟练运用CUDA编程框架。从初探NVIDIA CUDA编程框架开始,逐步深入探讨CUDA的基本概念与架构解析,以及核心编程模型的详细讲解。同时,专栏还涵盖了CUDA线程层次与块级并行、线程同步与互斥、并行算法与数据结构等内容,帮助读者掌握CUDA编程的关键技术和原理。此外,专栏还探讨了在CUDA中的优化技巧与性能调优策略,以及CUDA在深度学习加速计算、图像处理与计算机视觉应用、大规模数据并行计算等方面的应用。无论是初学者还是有一定经验的开发者,都可以从本专栏中找到对CUDA编程更深入的认识和实践指导。
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Python index与sum:数据求和的便捷方式,快速计算数据总和
# 1. Python中的数据求和基础
在Python中,数据求和是一个常见且重要的操作。为了对数据进行求和,Python提供了多种方法,每种方法都有其独特的语法和应用场景。本章将介绍Python中数据求和的基础知识,为后续章节中更高级的求和技术奠定基础。
首先,Python中求和最简单的方法是使用内置的`+`运算符。该运算符可以对数字、字符串或列表等可迭代对象进行求和。例如:
`
KMeans聚类算法的并行化:利用多核计算加速数据聚类

# 1. KMeans聚类算法概述**
KMeans聚类算法是一种无监督机器学习算法,用于将数据点分组到称为簇的相似组中。它通过迭代地分配数据点到最近的簇中心并更新簇中心来工作。KMeans算法的目的是最小化簇内数据点的平方误差,从而形成紧凑且分离的簇。
KMeans算法的步骤如下:
1. **初始化:**选择K个数据点作为初始簇中心。
2. **分配:**将每个数据点分配到最近的簇中心。
3. **更新:**计算每个簇中数据点的平均值,并
Python break语句的开源项目:深入研究代码实现和最佳实践,解锁程序流程控制的奥秘

# 1. Python break 语句概述
break 语句是 Python 中一个强大的控制流语句,用于在循环或条件语句中提前终止执行。它允许程序员在特定条件满足时退出循环或条件块,从而实现更灵活的程序控制。break 语句的语法简单明了,仅需一个 break 关键字,即可在当前执行的循环或条件语句中终止执行,并继续执行后续代码。
# 2. br
Python字符串与数据分析:利用字符串处理数据,提升数据分析效率,从海量数据中挖掘价值,辅助决策制定
# 1. Python字符串基础
Python字符串是表示文本数据的不可变序列。它们提供了丰富的操作,使我们能够轻松处理和操作文本数据。本节将介绍Python字符串的基础知识,
Python append函数在金融科技中的应用:高效处理金融数据
-Method.webp)
# 1. Python append 函数概述**
Python append 函数是一个内置函数,用于在列表末尾追加一个或多个元素。它接受一个列表和要追加的元素作为参数。append 函数返回 None,但会修改原始列表。
append 函数的语法如下:
```python
list.append(element)
```
其中,list 是要追加元
numpy安装与系统环境变量:配置环境变量,方便使用numpy
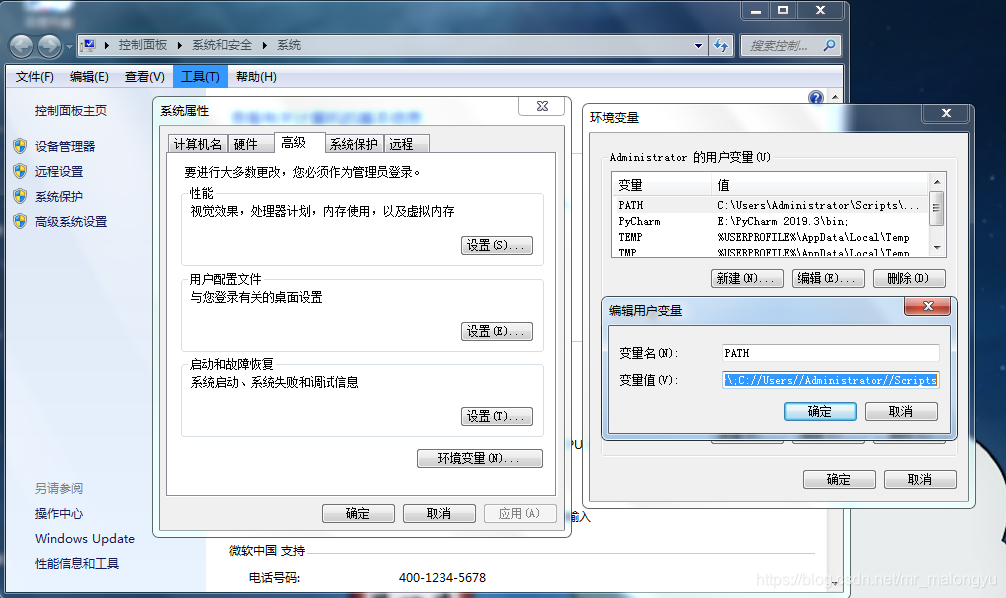
# 1. NumPy 简介**
NumPy(Numerical Python)是一个用于科学计算的 Python 库,它提供了高效的数组处理、数
Python字符串字母个数统计与医疗保健:文本处理在医疗领域的价值

# 1. Python字符串处理基础**
Python字符串处理基础是医疗保健文本处理的基础。字符串是Python中表示文本数据的基本数据类型,了解如何有效地处理字符串对于从医疗保健文本中提取有意
【基础】Python函数与模块:构建可复用代码

# 1. Python函数基础**
Python函数是将一组代码块封装成一个独立单元,以便在程序中重复使用。函数定义使用`def`关键字,后跟函数名称和参数列表
Python求和与信息安全:求和在信息安全中的应用与实践
# 1. Python求和基础**
Python求和是一种强大的工具,用于将一系列数字相加。它可以通过使用内置的`sum()`函数或使用循环显式地求和来实现。
```python
# 使用 sum() 函数
numbers = [1, 2, 3, 4, 5]
total = sum(numbers) # total = 15
# 使用循环显式求和
total = 0
for n
【实战演练】用wxPython制作一个简单的网络摄像头监控应用

# 2.1 网络摄像头的工作原理
网络摄像头是一种将光学图像转换为数字信号的电子设备。其工作原理大致如下:
1. **图像采集:**网络摄像头内部有一个图像传感器(通常为CMOS或CCD),负责将光线转换为电信号。
2. **模拟-数字转换(ADC):**图像传感器产生的模拟电信号通过ADC转换为数字信号,形成图像数据。
3. *
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )