【MySQL与NoSQL混合架构】:最佳实践与应用场景解析
发布时间: 2024-12-07 04:33:52 阅读量: 9 订阅数: 18 

canal 的 mysql 与 redis/memcached/mongodb 的 nosql 数据实时同步方案
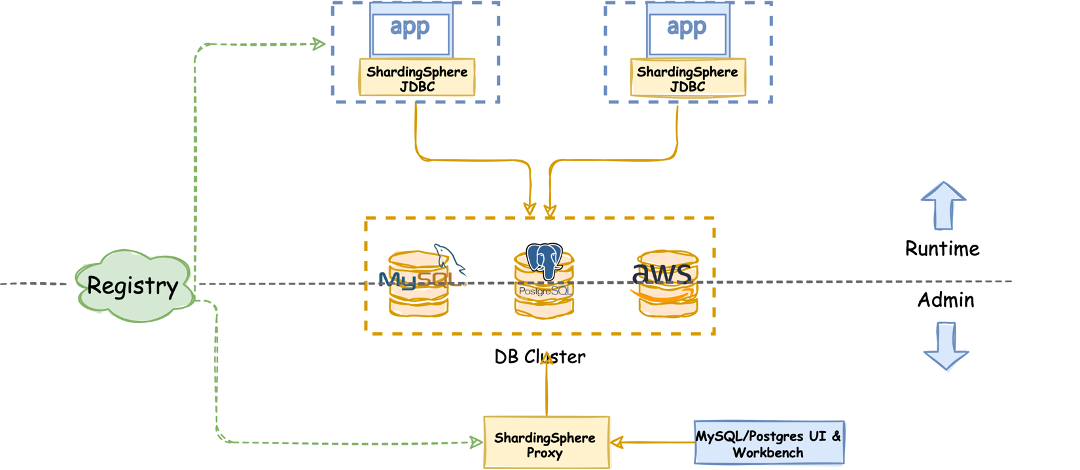
# 1. MySQL与NoSQL简介
## 1.1 关系型数据库MySQL
MySQL是世界上最流行的开源关系型数据库管理系统之一,以它的高性能、高可靠性和易用性得到了广泛的应用。作为企业级应用中的佼佼者,MySQL特别擅长处理高度结构化的数据,并提供了强大的事务处理能力和成熟的SQL查询语言支持。
## 1.2 非关系型数据库NoSQL
NoSQL(Not Only SQL)是为应对大规模数据集的存储和查询需求而出现的数据库技术。它突破了关系型数据库的结构限制,提供了多样化的数据模型,如键值存储、文档型数据库、列族存储和图形数据库等。NoSQL通常具有良好的水平扩展能力和灵活的数据模型,非常适合快速迭代和应对大规模数据的场景。
## 1.3 MySQL与NoSQL的选择
选择MySQL还是NoSQL,主要取决于应用场景。在需要复杂事务处理和强一致性的场景中,MySQL往往是首选。而在需要快速读写和处理大量非结构化数据的场景中,NoSQL展现出了它的优势。随着技术的发展,MySQL也在不断进化,引入了如JSON支持等NoSQL特性,而NoSQL数据库也在加强对事务和一致性支持。
以上章节为第一章的内容概览,旨在为读者提供一个关于MySQL和NoSQL基础知识的简要介绍,并引导读者思考在不同应用场景下如何选择合适的数据库技术。接下来的章节将深入比较MySQL和NoSQL的技术差异,为构建混合数据架构奠定基础。
# 2. MySQL与NoSQL的技术对比
## 2.1 数据模型差异
### 2.1.1 关系型数据库的表结构设计
关系型数据库如MySQL采用结构化查询语言(SQL),以表的形式组织数据,表之间通过外键实现关联。表结构设计是关系型数据库中的核心环节,其设计质量直接影响数据库的性能和可维护性。
#### 表结构设计的考量
在设计表结构时,首先需要确定表的字段和类型,如整型、字符型、日期时间型等。需要考虑字段的数据范围和精度,确保能存储所需的数据。对于关联关系,一般通过设置外键(FOREIGN KEY)实现不同表之间的连接。
#### 数据完整性约束
为保证数据的准确性,需要设置数据完整性约束。常用的约束包括主键约束(PRIMARY KEY),唯一约束(UNIQUE),非空约束(NOT NULL)以及检查约束(CHECK)。这些约束保证了数据在插入、更新和删除操作时的数据准确性。
#### 示例代码
```sql
CREATE TABLE users (
user_id INT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(255) NOT NULL,
password VARCHAR(255) NOT NULL,
email VARCHAR(255) UNIQUE,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
) ENGINE=InnoDB;
```
### 2.1.2 非关系型数据库的数据模型
非关系型数据库(NoSQL)采用了更加灵活的数据模型,主要包括键值存储、文档存储、列存储和图数据库等类型。这些模型放弃了关系型数据库严格的表结构和数据一致性的要求,提高了数据存储的灵活性和水平扩展的能力。
#### 键值存储模型
键值存储模型通过键来存取数据,数据结构简单,主要用于缓存和会话管理。如Redis、Amazon DynamoDB等。
```json
{
"user:1001": {
"username": "Alice",
"password": "123456",
"email": "alice@example.com"
},
"user:1002": {
"username": "Bob",
"password": "abcdef",
"email": "bob@example.com"
}
}
```
#### 文档存储模型
文档存储模型以文档为数据单位,文档通常采用JSON或XML格式存储。这种模型易于操作和管理,适用于内容管理、日志处理等场景。如MongoDB。
```json
[
{
"_id": ObjectId("5099803df3f4948bd2f98391"),
"name": "Alice",
"age": 30,
"email": "alice@example.com"
},
{
"_id": ObjectId("5099803df3f4948bd2f98392"),
"name": "Bob",
"age": 25,
"email": "bob@example.com"
}
]
```
#### 列存储模型
列存储模型按列而非行来存储数据,适合于数据仓库、大数据分析等场景。如Apache Cassandra、HBase。
#### 图数据库模型
图数据库专注于存储实体间的关系。每个节点代表一个实体,每条边代表实体间的关系。适用于社交网络、推荐系统等需要处理复杂关系的应用。
## 2.2 性能考量
### 2.2.1 MySQL的性能优化
MySQL的性能优化是数据库管理员关注的重点之一。性能优化可以分为硬件层面、软件层面和查询层面。
#### 硬件层面
硬件层面的优化通常包括增加内存、使用更快的硬盘(如SSD)、提升CPU性能等。
#### 软件层面
软件层面包括数据库的参数配置、表的分区、索引优化和查询缓存等。
```sql
ALTER TABLE table_name PARTITION BY RANGE (column_name) (
PARTITION p0 VALUES LESS THAN (value1),
PARTITION p1 VALUES LESS THAN (value2),
...
);
```
#### 查询层面
查询层面主要涉及查询语句的编写,包括使用正确的索引、避免全表扫描、优化连接查询等。
### 2.2.2 NoSQL的性能特点
NoSQL数据库的设计目标就是提供高性能、高可用性和易扩展性。性能优化方面,NoSQL数据库往往采用水平扩展的方式,通过增加节点数量来提升处理能力。
#### 数据模型的适应性
由于其非关系型的数据模型,NoSQL在某些场景下能够提供更优的读写性能。例如,键值存储可以快速响应简单的键查找操作。
#### 分布式特性
NoSQL的分布式特性可以实现数据的自动分片(sharding),这种机制能够将数据和负载均匀分布在多个服务器上,提高性能。
#### 异步复制
NoSQL数据库往往采用异步复制机制,这种机制在不牺牲太多性能的情况下保证了数据的高可用性。
## 2.3 可用性和一致性
### 2.3.1 MySQL的事务支持和锁机制
MySQL支持ACID事务模型(原子性、一致性、隔离性、持久性),这使得MySQL在需要严格事务处理的场合中非常适用。
#### 事务的隔离级别
MySQL提供了四种事务隔离级别,分别为:读未提交(READ UNCOMMITTED)、读提交(READ COMMITTED)、可重复读(REPEATABLE READ)和串行化(SERIALIZABLE)。不同的隔离级别会影响性能和数据的一致性。
#### 锁机制
MySQL的锁机制分为表级锁和行级锁。行级锁提供了更好的并发控制,但开销相对较大。表级锁在并发较低的环境下性能较好。
```sql
START TRANSACTION;
SELECT * FROM table_name WHERE id = 1001 FOR UPDATE;
```
### 2.3.2 NoSQL的CAP理论和一致性模型
NoSQL数据库通常遵循CAP理论,即在一致性(Consistency)、可用性(Availability)和分区容忍性(Partition Tolerance)之间进行权衡。NoSQL往往优先保证分区容忍性和可用性。
#### CAP理论
在一个网络分区发生的情况下,系统只能满足一致性和可用性中的一个,这就产生了CAP理论。NoSQL数据库如Cassandra采用最终一致性模型,允许在一定时间内存在数据副本不一致的情况。
#### 一致性模型
NoSQL数据库根据其应用场景的不同,提供不同的一致性模型。例如,DynamoDB提供两种一致性模型:强一致性和最终一致性。
#### 读写策略
不同的NoSQL数据库有不同的读写策略。例如,Cassandra通过一致性哈希来平衡读写请求,保证系统的均匀负载。
以上内容从技术深度和广度上对MySQL和NoSQL之间的技术对比进行了详尽分析,从数据模型差异到性能考量,再到可用性和一致性,力求为读者提供全面的技术比较和深入了解,为后续章节中混合架构的设计与实践打下坚实的基础。
# 3. 混合架构的设计原则
## 3.1 架构设计要点
### 3.1.1 数据一致性和同步策略
在混合架构中,数据的一致性和同步是关键问题之一。要实现数据在MySQL和NoSQL数据库间的一致性,可以采用数据复制技术,如主从复制、双主复制等。确保数据在多个数据源间保持一致,需要选择合适的同步策略,并考虑到数据一致性的级别。
在设计混合架构时,通常有两种策略:强一致性模型和最终一致性模型。强一致性模型可以保证事务操作立即反映到所有副本上,但它可能会带来性能的损失,适用于对数据一致性要求极高的场景。而最终一致性模型则允许在一定时间内数据不一致,但最终所有副本上的数据会达到一致的状态,适用于对性能要求更高的场景。
同步策略的选择取决于具体的业务需求和预期的用户体验。例如,在电子商务平台中,商品库存信息需要实时更新并保持一致性,以避免超卖现象,因此适合采用强一致性模型。而在社交网络中,用户发布的内容可以采用最终一致性模型,因为用户通常对延迟几秒钟的更新是可以接受的。
### 3.1.2 高可用性和灾难恢复
高可用性(HA)意味着系统能够在出现故障时继续运作,而灾难恢复(DR)则指系统在遭受严重故障后能够迅速恢复的能力。为了保证系统的高可用性和灾难恢复,混合架构设计中必须包含冗余组件、故障转移机制和数据备份策略。
冗余组件可以通过设置多

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《MySQL在数据分析中的应用》专栏深入探讨了MySQL数据库在数据分析领域的应用和优化技巧。从初级到高级,专栏涵盖了MySQL性能优化、查询速度提升、数据备份与恢复、查询缓存优化、监控工具对比、高可用架构部署、存储过程与函数高级应用、触发器与性能优化、分区表设计、混合架构、大数据扩展策略、慢查询日志分析、数据仓库应用、查询优化器、云计算部署、版本升级与迁移等方面。通过实战指南、专家建议和深入分析,专栏旨在帮助数据分析师和数据库管理员充分利用MySQL数据库,提高数据分析效率和性能。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
SIMCA 14.1进阶秘籍:打造复杂3D火山图的5大技巧

参考资源链接:[SIMCA 14.1教程:3D火山图制作与解析](https://wenku.csdn.net/doc/6401ad16cce7214c31
Silvaco TCAD 与 Spice 对比分析

参考资源链接:[Silvaco TCAD器件仿真教程:材料与物理模型设定](https://wenku.csdn.net/doc/6moyf21a6v?spm=1055.2635.3001.10343)
# 1. TCAD与Spice简介
## 1.1 TCAD与Spice的基本概念
TCAD(Technology Computer-Aided Design)与Spice是半导
数据同步与恢复:光纤环网机制详解及最佳实践

参考资源链接:[光纤环网技术详解:组网方式与帧处理机制](https://wenku.csdn.net/doc/1q4ubo5bp2?spm=1055.2635.3001.10343)
# 1. 数据同步与恢复概述
在现代IT架构中,数据同步与恢复是确保业务连续性和数据安全的关键组成部分。本章将概述数据同步与恢复的基本概念,并探讨其在企业环境中的重要性。
【技术写作秘籍】:四级词汇在技术文档中的巧妙运用

参考资源链接:[四级核心词汇详解:高频词与相关术语](https://wenku.csdn.net/doc/5gxen3nh5w?spm=1055.2635.3001.10343)
# 1. 技术写作与四级词汇的重要性
在技术领域,准确而清晰的沟通是至关重要的。技术写作不仅需要传达具体信息,而且需要确保不同背景的读者都能理解。四级词汇,指的是大学英语四级考试中的核心词汇,它们在技术写作中扮演着不可或缺的角色。这些词汇因为其普遍性和准确
西门子FB284成本效益评估:如何进行ROI与TCO分析以优化项目预算
参考资源链接:[西门子FB284功能块在TIA Portal中的V90定位控制](https://wenku.csdn.net/doc/6401acffcce7214c316ede81?spm=1055.2635.3001.10343)
# 1. 理解西门子FB284在项目中的角色
在现代工业自动化项目中,西门子FB284作为一个功能块,扮演着至关重要的角色。FB284是西门子SI
【BELLHOP全面解读】:从基础操作到高级特性的全方位指南

参考资源链接:[BELLHOP中文使用指南及MATLAB操作详解](https://wenku.csdn.net/doc/6412b546be7fbd1778d42928?spm=1055.2635.3001.10343)
# 1. BELLHOP基础介绍与安装
## BELLHOP是什么
BELLHOP是一个先进的IT任务自动化和管理系统,旨在优化日常运维任务的效率。
快速识别库卡机器人故障:维修手册与预防策略大揭秘

参考资源链接:[库卡机器人kuka故障信息与故障处理.pdf](https://wenku.csdn.net/doc/64619a8c543f844488937510?spm=1055.2635.3001.10343)
# 1. 库卡机器人故障快速识别概述
## 1.1 故障识别的重要性
在自动化领域中,库卡机器人故障的快速识别对于确保生产线的稳定运行至关重要。通过及时的故障识别,可以最小化生产停滞时间,减少经济损失,并增强整个
【RTD2556深度剖析】:解锁顶尖技术手册的12个秘诀

参考资源链接:[RTD2556-CG多功能显示器控制器数据手册:集成接口与应用解析](https://wenku.csdn.net/doc/6412b6eebe7fbd1778d487eb?spm=1055.2635.3001.10343)
# 1. RTD2556技术概述
## 1.1 RTD2556简介
RTD2556是一颗高度集成的系统级芯片(SoC),专为视频处理
【Dalsa相机固件升级全攻略】:避免失败的5个关键步骤

参考资源链接:[Dalsa相机全面使用指南:硬件配置与软件开发](https://wenku.csdn.net/doc/57bgbkrhzu?spm=1055.2635.3001.10343)
# 1. Dalsa相机固件升级概览
在本章中,我们将对Dalsa相机固件升级做一个全面的了解,为后续章节深入探讨升级前的准备、过程、验证以及高级应用打下基础。固件升
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )