Python在城市规划中的作用:构建可持续发展的智能城市
发布时间: 2024-12-06 23:53:50 阅读量: 10 订阅数: 11 

城市规划原理课件.zip
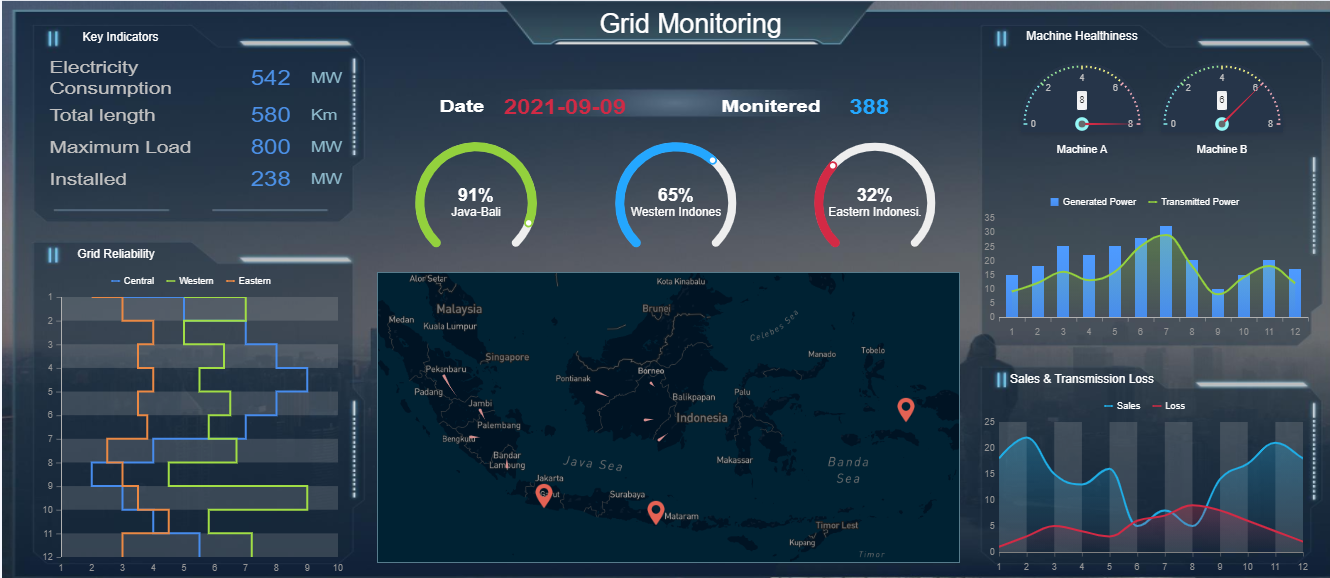
# 1. Python在智能城市中的应用概览
智能城市的构建是现代城市发展的重要方向,其中,Python作为一种高效、简洁的编程语言,在智能城市的多个方面发挥着关键作用。本章将概述Python在智能城市中的主要应用领域,并简要分析其重要性。Python在数据分析、机器学习、空间分析、物联网集成以及城市建模等众多领域中的应用,为智能城市的建设和管理提供了强大的技术支持。接下来的章节将对这些应用进行深入探讨,揭示Python如何优化智能城市的发展和运营。
# 2. Python的数据分析与处理
## 2.1 数据分析基础
### 2.1.1 Python中的数据分析库介绍
数据分析是智能城市构建的核心组成部分,Python在数据分析方面拥有一系列强大的库。其中最为广泛使用的包括Pandas、NumPy和SciPy等。Pandas提供了高性能的数据结构和数据分析工具,特别适合于处理结构化数据。NumPy则是Python的数值计算扩展,它对大规模数组和矩阵运算进行了优化。SciPy则是建立在NumPy之上,用于科学和技术计算的库。
在进行数据分析时,我们通常会通过Pandas库来读取数据,然后使用NumPy进行数值计算,再利用SciPy来执行更复杂的数学运算。这样的组合可以让我们高效地处理数据,并在此基础上进行深入的数据分析。
### 2.1.2 数据采集和清洗技巧
数据采集是数据分析的第一步。在Python中,我们可以使用requests库来从网络上获取数据。此外,Scrapy框架可以帮助我们构建复杂的爬虫程序,以自动化的形式采集大规模数据。采集到数据之后,通常需要进行清洗才能用于后续的分析工作。
数据清洗包括去除重复数据、填充或删除缺失值、纠正错误和标准化数据格式等。Python中的Pandas库提供了丰富的数据清洗功能,比如`drop_duplicates()`用于删除重复数据,`fillna()`用于填充缺失值等。
```python
import pandas as pd
# 示例代码:数据清洗
# 假设有一个CSV文件,包含未经清洗的数据
df = pd.read_csv('unclean_data.csv')
# 去除重复数据
df_cleaned = df.drop_duplicates()
# 填充缺失值
df_cleaned.fillna(0, inplace=True)
# 保存清洗后的数据到新的CSV文件
df_cleaned.to_csv('cleaned_data.csv', index=False)
```
以上代码块展示了如何使用Pandas进行基本的数据清洗。在实际应用中,数据清洗的过程可能会更加复杂,包含多种数据质量的检查和处理。
## 2.2 高级数据处理技术
### 2.2.1 数据探索性分析
数据探索性分析(Exploratory Data Analysis, EDA)是数据分析中不可或缺的一部分,通过统计图表和摘要统计量来发现数据集中的模式、异常值以及数据间的关系。
Python中的Matplotlib和Seaborn是两个非常流行的数据可视化库。Matplotlib提供了绘制基本图形的能力,而Seaborn则在Matplotlib的基础上,提供了更多高级的绘图功能和更美观的图表样式。
在进行数据探索性分析时,我们通常会绘制直方图、箱线图、散点图等,以观察数据的分布和变量之间的关系。
```python
import seaborn as sns
import matplotlib.pyplot as plt
# 示例代码:使用Seaborn进行数据探索性分析
# 假设有一个DataFrame df_cleaned,已经进行了清洗
# 绘制直方图
sns.histplot(df_cleaned['某列数据'])
# 绘制箱线图
sns.boxplot(x='分类变量', y='数值变量', data=df_cleaned)
plt.show()
```
### 2.2.2 预测建模和机器学习
在数据探索和分析的基础上,预测建模和机器学习可以帮助我们对未来趋势做出预测,并为智能城市规划提供数据支持。
使用Python进行机器学习,我们可以利用Scikit-learn库,它提供了广泛的机器学习算法,例如线性回归、决策树、随机森林和支持向量机等。通过这些算法,我们能够建立预测模型,并进行预测分析。
```python
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
# 示例代码:使用随机森林进行分类
# 假设有一个经过清洗的DataFrame df_cleaned,并且我们已经确定了特征和标签
X = df_cleaned.drop('标签列', axis=1)
y = df_cleaned['标签列']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建随机森林模型
clf = RandomForestClassifier(n_estimators=100)
# 训练模型
clf.fit(X_train, y_train)
# 预测测试集
y_pred = clf.predict(X_test)
# 输出分类报告
print(classification_report(y_test, y_pred))
```
这段代码展示了使用Scikit-learn库创建随机森林模型,并对测试集进行预测的过程。通过评估指标,我们可以了解模型的预测性能,为改进模型提供依据。
## 2.3 数据可视化实践
### 2.3.1 可视化工具和库的选择
在数据可视化方面,除了前面提到的Matplotlib和Seaborn,还可以使用Plotly和Bokeh这两个库来创建交互式的图表。交互式图表可以提供更丰富的用户体验,例如,允许用户通过鼠标悬停来查看具体的数据点信息。
选择合适的可视化工具对于展示数据分析的结果至关重要。如果数据集很大或者需要动态交互,Plotly和Bokeh会是更好的选择。对于静态图像,Matplotlib和Seaborn仍然十分实用。
### 2.3.2 实时数据的动态可视化
实时数据可视化是智能城市数据分析中的一个重要方面,它能够帮助城市管理者及时了解城市运行状况,并作出快速反应。
在Python中,可以使用Flask或Django等Web框架结合Plotly或Bokeh来实现动态的实时数据可视化。通过Web应用,我们可以展示实时更新的图表,比如实时交通流量、空气质量指数等。
```python
# 示例代码:使用Flask和Plotly创建实时数据可视化Web应用
from flask import Flask, render_template
import plotly.graph_objs as go
import random
app = Flask(__name__)
@app.route('/')
def index():
# 随机生成一组实时数据
data = [go.Scatter(x=[0, 1, 2], y=[random.randint(0, 10) for _ in range(3)])]
layout = go.Layout(title='实时数据可视化')
fig = go.Figure(data=data, layout=layout)
return render_template('index.html', figure=fig.to_plotly_json())
if __name__ == '__main__':
app.run(debug=True)
```
此代码创建了一个简单的Flask Web应用,它会显示一个实时更新的图表。在实际应用中,数据应该是从数据库或实时数据源动态获取的。
# 3. Python在城市空间分析中的运用
城市空间分析是智能城市规划中的关键组成部分,它涉及利用数据和算法来理解城市的空间结构和动态变化。Python作为一种强大的编程语言,在GIS(地理信

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 在可持续发展技术中的广泛应用。从绿色计算策略到能源管理系统,再到物联网集成和环境数据分析,专栏提供了全面的指南,展示了 Python 如何帮助企业和个人实现可持续发展目标。它还探讨了 Python 在城市规划、交通领域、气候变化研究和野生动植物保护中的作用,强调了其在构建更可持续的未来的关键作用。通过深入的见解、实际示例和代码片段,本专栏为希望利用 Python 的力量推进可持续发展事业的读者提供了宝贵的资源。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Ubuntu文件系统选择:专家推荐,匹配最佳安装场景

参考资源链接:[Ubuntu手动分区详解:步骤与文件系统概念](https://wenku.csdn.net/doc/6483e7805753293249e57041?spm=1055.2635.3001.10343)
# 1. Ubuntu文件系统概述
Linux操作系统中,文件系统扮演着存储和管理数据的核心角色。Ubuntu作为广泛使用的Linux发行版,支持多
飞腾 U-Boot 初始化流程详解:启动前的准备步骤(内含专家技巧)
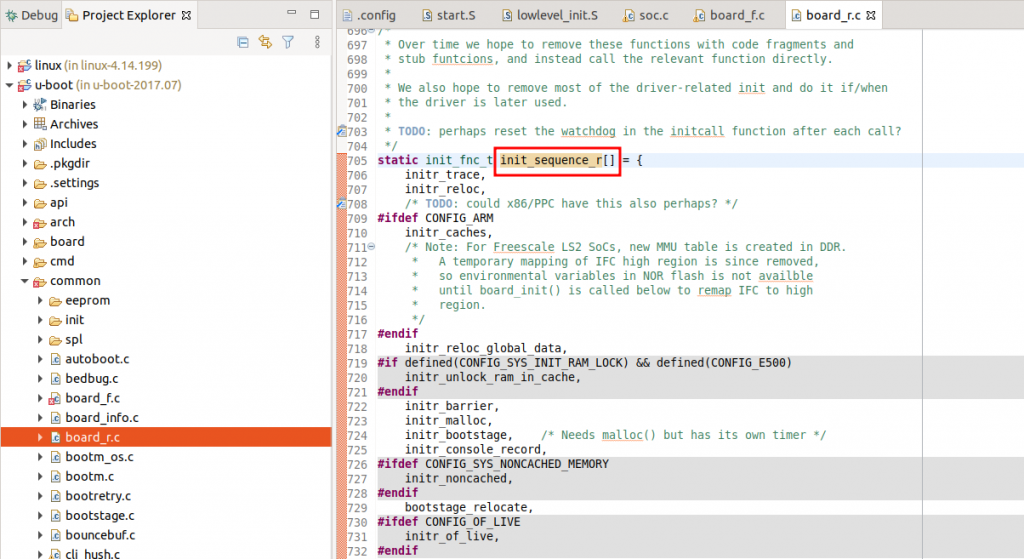
参考资源链接:[飞腾FT-2000/4 U-BOOT开发与使用手册](https://wenku.csdn.net/doc/3suobc0nr0?spm=1055.2635.3001.10343)
# 1. 飞腾U-Boot及其初始化流程概述
飞腾U-Boot作为一款开源的引导加载器,是许多嵌入式系统的首选启动程序,尤其在飞腾处理器的硬件平台上占据重要地位
【Ubuntu上安装QuestaSim 2021终极指南】:全面优化性能与兼容性

参考资源链接:[Ubuntu 20.04 安装QuestaSim2021全步骤指南](https://wenku.csdn.net/doc/3siv24jij8?spm=1055.2635.3001.10343)
# 1. QuestaSim与数字仿真基础
## 数字仿真简述
数字仿真是一种技术手段,通过计算机模拟电子系统的操作过程,以预测系统对各种输入信号的响应。它在电子设计
HyperMesh材料属性设置:确保正确赋值与验证的秘诀
参考资源链接:[HyperMesh入门:网格划分与模型优化教程](https://wenku.csdn.net/doc/7zoc70ux11?spm=1055.2635.
MODBUS故障排查实战:使用MODSCAN32迅速诊断和解决问题

参考资源链接:[基于MODSCAN32的MODBUS通讯数据解析](https://wenku.csdn.net/doc/6412b5adbe7fbd1778d44019?spm=1055.2635.3001.10343)
# 1. MODBUS协议基础知识
MODBUS协议是工业领域广泛使用的一种简单、开放、可靠的通信协议。最初由Modicon公司开发,现已成为工业电子通信
MATPOWER潮流计算可视化解读:结果展示与深度分析

参考资源链接:[MATPOWER潮流计算详解:参数设置与案例示范](https://wenku.csdn.net/doc/6412b4a1be7fbd1778d40417?spm=1055.2635.3001.10343)
# 1. 潮流计算基础与MATPOWER简介
潮流计算是电力系统分析的基石,它涉及计算在不同
电源管理芯片应用详解:为单片机USB供电电路选型与配置指南
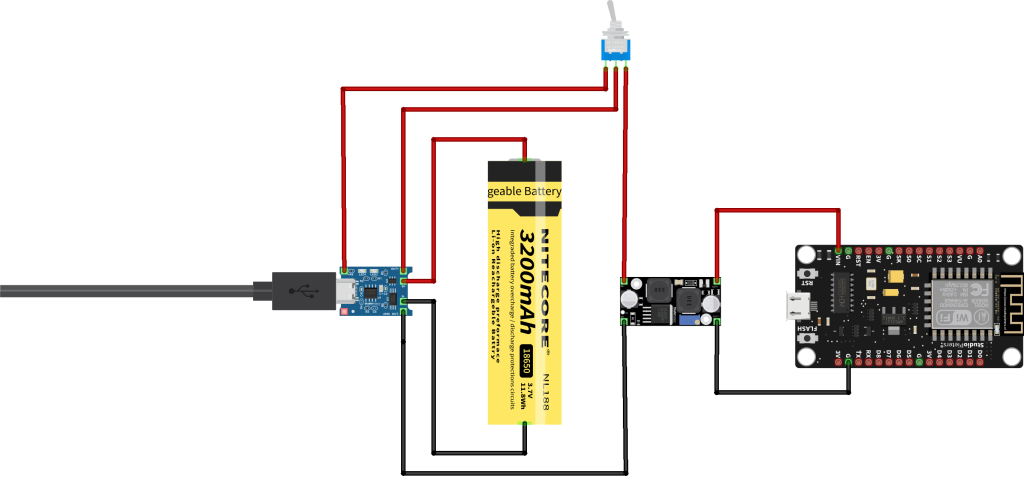
参考资源链接:[单片机使用USB接口供电电路制作](https://wenku.csdn.net/doc/6412b7abbe7fbd1778d4b20d?spm=1055.2635.3001.10343)
# 1. 电源管理芯片基础与重要性
电源管理芯片是电子系统中不可或缺的组件,它负责调节供电电压和电流,以确保各部分电子设备能够稳定、高效地工作。随着技术的进步,电源
10GBASE-R技术深度剖析:如何确保数据中心的网络性能与稳定性
参考资源链接:[10GBASE-R协议详解:从Arria10 Transceiver到PCS架构](https://wenku.csdn.net/doc/10ayqu73ib?spm=1055.2635.3001.10343)
# 1. 10GBASE-R技术概述
## 1.1 技术背景与定义
10GBASE-R技术是IEEE 802
【兼容性保证】:LAN8720A与IEEE标准的最佳实践

参考资源链接:[Microchip LAN8720A/LAN8720Ai: 低功耗10/100BASE-TX PHY芯片,全面RMII接口与HP Auto-MDIX支持](https://wenku.csdn.net/doc/6470614a543f844488
B-6系统集成挑战:与第三方服务无缝对接的7个策略
参考资源链接:[墨韵读书会:软件学院书籍共享平台详细使用指南](https://wenku.csdn.net/doc/74royby0s6?spm=1055.2635.3001.10343)
# 1. 系统集成与第三方服务对接概述
在当今高度数字化的商业环境中,企业运作越来越依赖于技术系统来优化流程、增强用户体验和提高竞争力。系统集成(
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )