【应用案例分析】:从成功故事中学习google.appengine.api最佳实践
发布时间: 2024-10-12 08:51:42 阅读量: 34 订阅数: 32 

appengine-crawl-mapreduce-test:一个简单的多模块appengine项目,学习多模块、crawler4j和map reduce
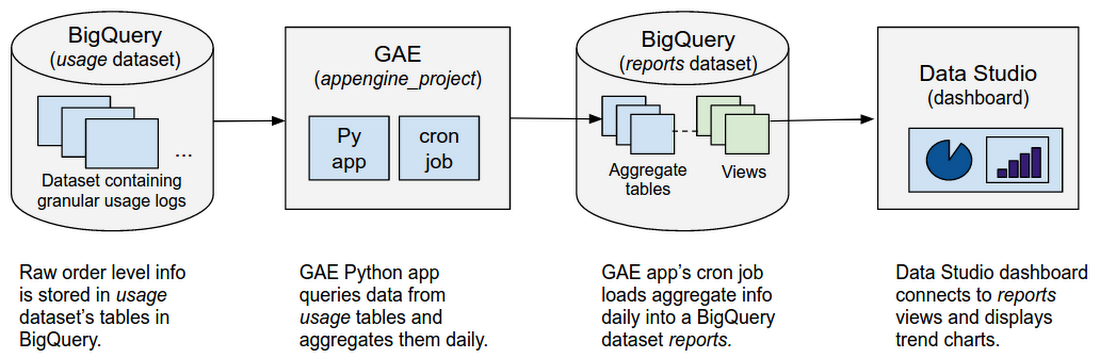
# 1. Google App Engine API 概述
Google App Engine(GAE)是一个完全托管的平台,允许开发者构建、部署和扩展Web应用程序和移动后端。GAE为开发者提供了一个灵活而强大的API集合,这些API允许在云端运行代码而无需关心底层硬件配置和维护。
在这个章节中,我们将简要介绍Google App Engine API的基本概念,包括它如何使得开发者可以集中精力在业务逻辑上,而无需担心服务器的可扩展性和性能问题。我们还将探讨GAE的自动扩展功能,它可以根据应用的需求动态地扩展资源。为了更好地理解API的实际应用,我们会在后续章节深入探讨设计、实现、性能优化和安全性最佳实践。
## 1.1 GAE平台架构
GAE平台基于Google的基础设施,它支持多语言环境如Python、Java、Go和Node.js,为不同的应用场景提供了丰富的API和SDK。GAE的架构允许应用在高流量期间自动增加资源,并在流量减少时自动缩减资源。
```python
# Python 示例代码展示如何使用GAE SDK初始化一个简单应用
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello_world():
return 'Hello, GAE!'
if __name__ == '__main__':
app.run()
```
在上面的Python代码示例中,使用了Google App Engine的Flask框架来创建一个基本的Web服务。这个简单的"Hello World"应用是理解如何与GAE API交互的起点。
## 1.2 GAE API的特点
Google App Engine API的特性之一是其无服务器架构,这允许开发者专注于代码编写,而不必过多关注服务器管理。此外,GAE提供了多种服务,例如Memcache、Datastore和Task Queue,用于数据存储、任务处理等,极大地提高了开发效率。
接下来,我们将深入探讨API设计与实现的最佳实践,为构建高效、可维护的应用打下坚实的基础。
# 2. API 设计与实现的最佳实践
## 2.1 API 设计原则
### 2.1.1 RESTful 架构风格
在设计现代Web API时,RESTful架构风格已经成为了一种标准方法。REST,即Representational State Transfer的缩写,强调的是资源的无状态传输。RESTful API设计原则建议使用HTTP的方法,如GET、POST、PUT和DELETE来操作资源,并返回适合的HTTP状态码来表示操作成功或失败。
在实现Google App Engine API时,一个基本的RESTful原则是使用URL来表示资源路径。例如,`/users/{userId}`可以用来表示一个用户资源。对于资源的创建、更新、删除等操作,可以通过HTTP的动词来实现:`POST /users` 创建新用户,`PUT /users/{userId}` 更新一个用户信息,`DELETE /users/{userId}` 删除一个用户。
RESTful API的另一个关键特征是无状态通信。这意味着每个请求都包含了执行操作所需的全部信息,服务器端不需要保存客户端的状态信息。这不仅简化了服务器的设计,还提高了API的可伸缩性和可靠性。
### 2.1.2 资源的合理划分
在RESTful API中,合理划分资源是设计高质量API的关键。设计资源时,需考虑资源的粒度以及资源之间的关系。一个常见的错误是将多个资源合并为一个资源,这可能导致操作变得复杂,难以维护。
例如,在一个博客API中,博客文章和评论应被视为独立的资源。这样,用户可以独立地获取文章列表(`GET /articles`)和评论列表(`GET /comments`),同时也可以通过关联文章ID获取特定文章的评论(`GET /articles/{articleId}/comments`)。这种设计不仅清晰地表达了资源之间的关系,而且使得API的维护和扩展变得更加容易。
资源应该尽可能细粒度化,这样可以为客户端提供更多的灵活性,但也需要确保API调用的效率,避免过于细粒度导致的性能问题。
## 2.2 代码实现策略
### 2.2.1 使用 Google 提供的 SDK
Google App Engine提供了丰富的SDK,方便开发者快速搭建和部署应用。在API的设计和实现阶段,使用这些SDK可以大大简化开发流程。例如,使用Python SDK时,可以利用`appengine.ext`包中的模块来轻松地与Google App Engine的数据库进行交互。
使用SDK的好处在于它封装了很多底层细节,让开发者可以聚焦于业务逻辑的实现。在实现RESTful API时,Google的SDK通常提供了与路由、请求处理和响应生成相关的抽象,这有助于快速实现符合REST原则的API。
```python
from google.appengine.ext import db
class User(db.Model):
username = db.StringProperty()
email = db.StringProperty()
@app.route('/users', methods=['POST'])
def create_user():
user = User()
user.username = request.POST['username']
user.email = request.POST['email']
user.put()
return make_response(jsonify({'status': 'success'}), 201)
@app.route('/users/<user_id>', methods=['GET'])
def get_user(user_id):
user = User.get_by_id(int(user_id))
if user:
return make_response(jsonify(user.to_dict()), 200)
else:
return make_response(jsonify({'status': 'user not found'}), 404)
```
上面的Python代码展示了如何使用Google App Engine的Python SDK定义一个用户模型以及如何创建和获取用户的RESTful API接口。
### 2.2.2 编写高效可读的代码
在API开发过程中,编写高效的代码是至关重要的。这不仅影响API的响应时间,还影响到维护成本。一个高效且可读的代码库可以让其他开发者更容易理解和扩展API。
高效代码的关键在于使用适当的数据结构、避免不必要的计算以及优化数据库查询。同时,代码应该具有良好的模块化结构和清晰的命名约定,这有助于其他开发者阅读和理解代码。
```python
def calculate_stats(data):
# 使用列表推导式进行数据处理,提高效率
filtered_data = [item for item in data if item > 0]
total = sum(filtered_data)
average = total / len(filtered_data) if filtered_data else 0
return total, average
# 示例数据
data_points = [1, 2, 3, -4, 5, -6, 7]
# 调用函数并打印结果
total, average = calculate_stats(data_points)
print(f"Total: {total}, Average: {average}")
```
在编写代码时,应避免在循环中使用数据库查询,尽可能地减少数据库的I/O操作。此外,合理利用缓存可以显著提升API性能。
## 2.3 数据存储与检索
### 2.3.1 数据模型的选择
Google App Engine支持多种数据存储选项,包括Datastore、Memcache、Cloud SQL等。数据模型的选择取决于API的具体需求和预期的读写频率。例如,如果应用需要频繁读取但写入较少,可以使用内存缓存系统如M

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 库 google.appengine.api,这是一个用于构建和部署 Google App Engine 应用程序的强大工具。它提供了 10 个核心组件的全面解读,涵盖了从新手入门到高级特性解析的各个方面。专栏还提供了实践案例、性能优化指南、数据库交互技巧和内存缓存技术详解,帮助开发人员充分利用该库。此外,它还探讨了云计算协作、安全指南、并发控制秘籍和故障排查手册,确保应用程序的安全性和高效性。通过深入的数据分析优势、静态文件服务优化、实时通信解决方案和响应速度提升的讨论,该专栏为开发人员提供了构建可扩展、高性能的 Python 应用程序所需的全面知识和技巧。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【MotoHawk终极指南】:10大技巧助你快速精通
# 摘要
本文全面介绍了MotoHawk软件的基础知识、架构解析、编程接口和集成开发环境,以及编程技巧、项目管理和实际案例应用。MotoHawk作为一个功能丰富的软件平台,尤其在状态机编程、实时性能优化、数据采集分析及自动化测试等方面展现出其先进性和高效性。本文还探讨了MotoHawk在新兴技术融合、行业前瞻性应用的潜力,以及通过专家经验分享,为读者提供了实用的编程与项目管理建议,帮助开发人员在智能制造、自动驾驶等关键
深入解析多目标跟踪中的数据关联:6个关键问题与解决方案
# 摘要
多目标跟踪在计算机视觉和视频监控领域中扮演着重要角色,它涉及到数据关联、目标检测与跟踪同步、遮挡和交叠目标处理、系统评估与优化以及数据融合等多个核心问题。本文系统地探讨了这些关键问题的理论基础与实践应用,提出了一系列解决方案和优化策略,并讨论了如何评估和优化跟踪系统性能。此外,本文也研究了如何让多目标跟踪系统适应不同的应用场景,并对未来的发展趋势进行了展望。这些讨论有助于推动多目标跟踪
【HeidiSQL导出导入基础】:快速入门指南
# 摘要
HeidiSQL是一款功能强大的数据库管理工具,其导出导入功能在数据迁移、备份和管理中扮演着关键角色。本文旨在全面介绍HeidiSQL的导出导入功能,从理论基础到实践操作,再到进阶应用和故障诊断,提供了详尽的指导。文章首先概述了HeidiSQL导出导入功能的基本概念和重要性,随后通过实际案例展示了如何配置和执行导出导入操作,涵盖了定制化模板、批量操作、定时任务等高级技巧。文章还探讨了在大数据时代HeidiSQL导出
BK7231故障排除宝典:常见问题的快速解决之道
# 摘要
本文详细探讨了BK7231芯片的故障诊断、排除和预防性维护策略。首先,概述了BK7231芯片并介绍了基础故障诊断的理论和工具。接着,针对电源、通信和程序相关故障提供了诊断和解决方法,同时通过实际案例分析加深理解。高级故障排查章节涉及温度异常、性能问题及系统集成难题的应对策略。最后一章着重于 BK7231的预防性维护和故障预防措施,强调定期维护的重要性,以及通过持续改进和故障管理流程来提升系统的稳定性和可靠性。
# 关
【Win7部署SQL Server 2005】:零基础到精通的10大步骤
# 摘要
本论文详细介绍了SQL Server 2005的安装、配置、管理和优化的全过程。首先,作者强调了安装前准备工作的重要性,包括系统要求的检查与硬件兼容性确认、必备的系统补丁安装。随后,通过详尽的步骤讲解了SQL Server 2005的安装过程,确保读者可以顺利完成安装并验证其正确性。基础配置与管理章节侧重于服务器属性的设置、数据库文件管理、以及安全性配置,这些都是确保数据库稳定运行的基础。数据库操作与维护章节指导读者如何进行数据库的创建、管理和日常操作,同时强调了维护计划的重要性,帮助优化数据库性能。在高级配置与优化部分,探讨了高级安全特性和性能调优策略。最后,论文提供了故障排除和性
ASCII编码全解析:字符编码的神秘面纱揭开

# 摘要
ASCII编码作为计算机字符编码的基础,其起源和原理对现代文本处理及编程具有深远影响。本文首先介绍ASCII编码的起源、分类和表示方法,包括字符集的组成和
案例解析:揭秘SAP MTO业务实施的5个成功关键

# 摘要
SAP MTO(Make-to-Order)业务实施是针对特定市场需
【xHCI 1.2b驱动开发入门】:打造高效兼容性驱动的秘诀

# 摘要
本文旨在全面介绍xHCI(扩展主机控制器接口)驱动的开发与优化。首先概述了xHCI的历史发展和1.2b规范的核心概念,包括架构组件、数据流传输机制,以及关键特性的
【PIC单片机响应速度革命】:中断管理,提升系统性能的秘诀

# 摘要
中断管理是确保PIC单片机高效运行的关键技术之一,对于提升系统的实时性能和处理能力具有重要作用。本文首先介绍了PIC单片机中断系统的基础知
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )