目标检测中的图像分割技术与应用
发布时间: 2024-01-27 00:32:04 阅读量: 34 订阅数: 25 

图像分割技术
# 1. 目标检测与图像分割技术概述
## 1.1 目标检测技术简介
目标检测技术是指在图像或视频中识别和定位特定对象的能力。通常包括定位目标位置并进行分类。随着深度学习的发展,目标检测技术在自动驾驶、安防监控、医学影像等领域得到了广泛应用。
## 1.2 图像分割技术概述
图像分割技术是将图像分解为若干个具有语义信息的区域或像素的过程。常见的图像分割包括语义分割(将图像分为具有语义信息的区域)、实例分割(区分图像中的不同实例)等。
## 1.3 目标检测与图像分割的关系和区别
目标检测关注的是定位和分类图像中的对象,而图像分割则更侧重于将图像分解为具有语义信息的区域。两者可以相辅相成,目标检测通常需要依赖图像分割技术进行辅助。
以上是第一章的内容,接下来将继续完善后续章节的内容。
# 2. 常见的目标检测与图像分割技术
在本章中,我们将介绍一些常见的目标检测与图像分割技术,并讨论它们在不同应用领域中的应用。
### 2.1 基于深度学习的目标检测技术
基于深度学习的目标检测技术是当前目标检测领域中最为流行的方法之一。它通过构建深度神经网络模型,从图片中检测和定位出目标物体。其中,一些常用的深度学习目标检测算法包括:
- R-CNN (Region-based Convolutional Neural Networks)
- Fast R-CNN
- Faster R-CNN
- YOLO (You Only Look Once)
- SSD (Single Shot MultiBox Detector)
这些算法在目标检测任务中取得了很好的效果,能够实现较高的准确率和实时性。
具体代码示例如下(以Python语言为例):
```python
import tensorflow as tf
from tensorflow.keras.applications import VGG16
from tensorflow.keras.layers import Input, Dense
# Load pre-trained VGG16 model
base_model = VGG16(weights='imagenet', include_top=False, input_tensor=Input(shape=(224, 224, 3)))
# Add a fully connected layer for object detection
x = base_model.output
x = tf.keras.layers.GlobalAveragePooling2D()(x)
x = Dense(1024, activation='relu')(x)
predictions = Dense(num_classes, activation='softmax')(x)
# Create the final model for object detection
model = tf.keras.models.Model(inputs=base_model.input, outputs=predictions)
```
### 2.2 语义分割技术及其应用
语义分割技术是一种将图像中的每个像素分配到特定的目标类别的方法。与目标检测技术不同,语义分割不仅需要检测目标物体,还需要对每个像素进行分类。语义分割在许多领域中都具有重要的应用,例如自动驾驶、医学影像分析等。
常见的语义分割方法包括基于卷积神经网络的全卷积网络(FCN)、U-Net、DeepLab等。
以下是一个使用FCN进行语义分割的简单示例(Python语言):
```python
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, UpSampling2D
# Define the FCN model
model = Sequential()
model.add(Conv2D(64, kernel_size=(3, 3), activation='relu', padding='same', input_shape=(128, 128, 3)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu', padding='same'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(256, kernel_size=(3, 3), activation='relu', padding='same'))
model.add(UpSampling2D(size=(2, 2)))
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu', padding='same'))
model.add(UpSampling2D(size=(2, 2)))
model.add(Conv2D(64, kernel_size=(3, 3), activation='relu', padding='same'))
model.add(Conv2D(1, kernel_size=(1, 1), activation='sigmoid'))
# Compile and train the model
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.fit(x_train, y_train, batch_size=32, epochs=10, validation_data=(x_val, y_val))
```
### 2.3 实例分割技术在目标检测中的应用
实例分割技术是在目标检测的基础上进一步细化,不仅需要检测和定位出目标物体,还需要将每个目标物体的边界进行精确分割。相比于语义分割,实例分割不仅可以得到每个像素所属的类别,还能区分不同目标物体之间的差异。
当前在实例分割领域比较热门的方法包括Mask R-CNN、Panoptic Segmentation等。
以下是一个使用Mask R-CNN进行实例分割的简单示例(Python语言):
```python
import tensorflow as tf
from mrcnn import model as modellib
# Define the Mask R-CNN model
class CustomConfig(Config):
# Custom model configuration
# ...
custom_config = CustomConfig()
model = modellib.MaskRCNN(mode="inference", config=custom_config, model_dir=MODEL_DIR)
# Load pre-trained weights
model.load_weights(COCO_MODEL_PATH, by_name=True)
# Run instance segmentation on the input image
results = model.detect([image], verbose=1)
# Visualize the segmentation results
visualize.display_instances(image, results['rois'], results['masks'], results['class_ids'], class_names, results['scores'])
```
以上是第二章内容的简要介绍,我们将在后续章节中进一步讨论这些技术在不同应用场景中的具体应用及效果。
# 3. 图像分割在目标检测中的关键技术
目标检测和图像分割是计算机视觉领域中两项重要的技术,它们在人工智能、自动驾驶、医学影像等领域都有着广泛的应用。本章将深入探讨图像分割在目标检测中的关键技术,包括区域提议技术的作用与原理、特征提取的重要性以及多尺度处理在图像分割中的应用。
#### 3.1 区域提议技术的作用与原理
在目标检测中,区域提议技术起着至关重要的作用。其主要目标是生成候选的目标区域,以便后续的目标分类和定位。常见的区域提议技术包括Selective Search、EdgeBoxes和R-CNN系列等。这些技术大大减少了目

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
计算机视觉技术中的目标检测算法专栏深入探讨了SSD算法的单次多尺度目标检测原理。SSD算法是一种在计算机视觉领域中应用广泛的目标检测算法。该专栏旨在解析SSD算法的工作原理及其在多尺度目标检测中的应用。专栏内部的文章涵盖了SSD算法的基本原理、多尺度目标检测方法、模型架构和训练策略等方面的内容。通过深入剖析SSD算法的技术细节,读者可以全面了解该算法在目标检测领域的重要性和应用价值,以及其在实际场景中的性能表现和优势。此专栏旨在为计算机视觉领域的从业者和研究人员提供一个深入学习和交流的平台,帮助他们更好地理解并应用目标检测算法,推动计算机视觉技术的发展与创新。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【数据持久化策略】:3招确保Docker数据卷管理的高效性

# 摘要
数据持久化是确保数据在软件生命周期中保持一致性和可访问性的关键策略。本文首先概述了数据持久化的基础策略,并深入探讨了Docker作为容器化技术在数据持久化中的作用和机制。章节二分析了Docker容器与数据持久化的关联,包括容器的短暂性、Docker镜像与容器的区别,以及数据卷的类型和作用。章节三着重于实践层面,
HoneyWell PHD数据库驱动:一站式配置与故障排除详解

# 摘要
HoneyWell PHD数据库驱动作为工业自动化领域的重要组件,对系统的稳定性与性能起着关键作用。本文首先介绍了该驱动的概况及其配置方法,包括环境搭建、数据库连接和高级配置技巧。随后,深入探讨了该驱动在实践应用中的日志管理、故障诊断与恢复以及高级场景的应用探索。文中还提供了详细的故障排除方法,涵盖问题定位、性能优化和安全漏洞管理。最后,展望了HoneyWell PHD数据库
频域辨识技巧大公开
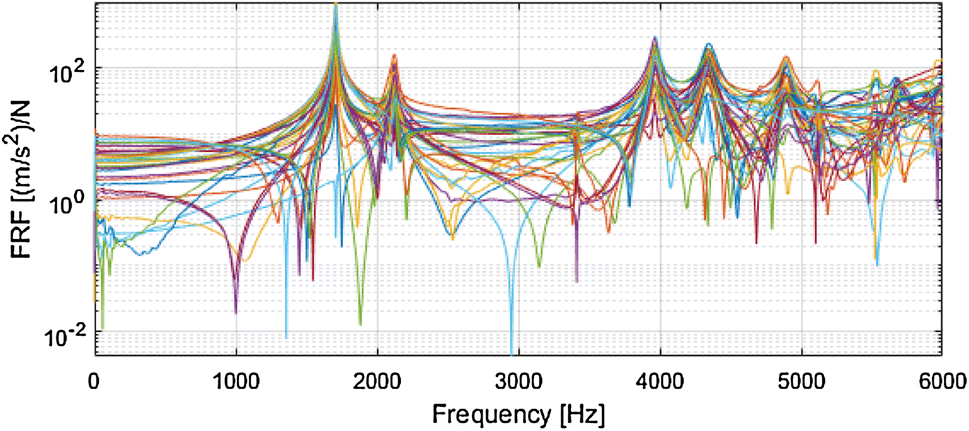
# 摘要
频域辨识技术作为系统分析的重要方法,在工程系统、控制系统和信号处理领域中发挥着关键作用。本文首先概述了频域辨识技术及其基础理论,强调了频域与时域的转换方法和辨识模型的数学基础。随后,文章探讨了频域辨识的实践方法,包括工具使用、实验设计、数据采集和信号分析等关键环节。通过分析
【跨平台WebView应用开发】:实现一个高效可复用的HTML内容展示框架

# 摘要
本文对跨平台WebView应用开发进行了全面探讨,涵盖了从理论基础到技术选型、核心框架构建、功能模块开发以及框架实践与案例分析的全过程。首先介绍了跨平台开发框架的选择与WebView技术原理,然后深入解析了如何构建高效的核心框架,包括HTML内容展示、资源管
Local-Bus总线兼容性解决方案:确保系统稳定运行
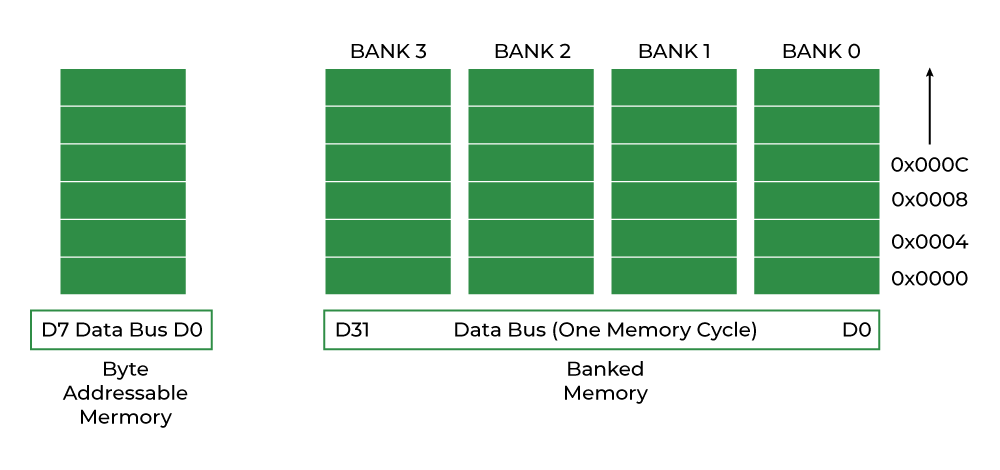
# 摘要
Local-Bus总线技术作为一种早期的高速数据传输接口,在计算机硬件领域中扮演了重要角色。本文旨在探讨Local-Bus总线技术的兼容性问题及其影响,通过分析其工作原理、硬件与软件层面的兼容性挑战,总结了诊断和解决兼容性问题的实践策略。在此基础上,文章探讨了保持Local-Bus总线系统稳定运行的关键措施,包括系统监控、故障恢复以及性
递归算法揭秘:课后习题中的隐藏高手
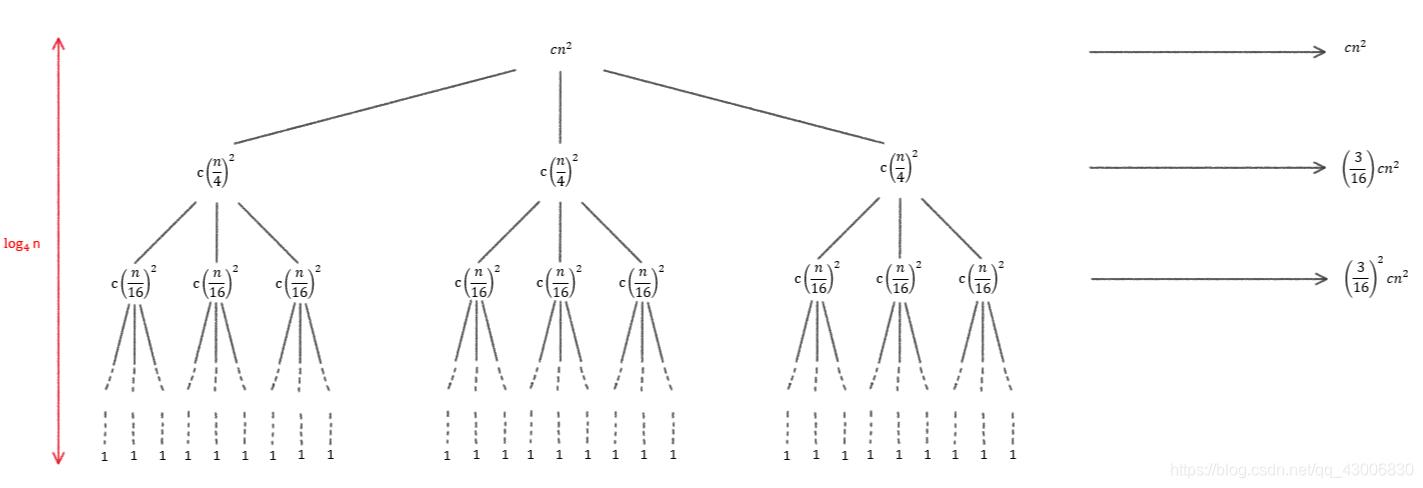
# 摘要
递归算法作为计算机科学中的基础概念和核心技术,贯穿于理论与实际应用的多个层面。本文首先介绍了递归算法的理论基础和核心原理,包括其数学定义、工作原理以及与迭代算法的关系
【雷达信号处理:MATLAB仿真秘籍】

# 摘要
本文首先介绍雷达信号处理的基础知识,随后深入探讨MATLAB在该领域的应用,包括软件环境的搭建、信号生成与模拟、信号处理工具箱的使用等。接着,文章详细阐述了雷达波形设计、信号检测与跟踪、以及雷达信号的成像处理等实践操作。此外,本文还涵盖了一些高级技巧,如MIMO雷达信号处理、自适应信号处理技术,以及GPU加速处理在雷达信号处理中的应用。最后,通过实际案例分析,展示雷达信号
Zkteco智慧系统E-ZKEco Pro安装详解:新手到专家的快速通道
# 摘要
本文全面介绍了E-ZKEco Pro系统的概览、安装、配置、优化及故障排除的全过程。首先概述了系统的架构和特点,然后详述了安装前的准备,包括硬件、软件的要求与兼容性以及安装介质的准备和校验。在系统安装部分,本文指导了全新安装和系统升级的具体步骤,并对多节点部署和集群设置进行了阐述。接着,本文深入探讨了系统配置与优化的策略,包括基础设置和性能调优技巧。最后,通过故障排除章节,介绍了常见的问题诊断、数据备份与恢复方法,并对E-ZKEco Pro系统的行业应用案例和未来发展趋势进行了分析,旨在为用户提供一个高效、稳定且可持续发展的系统解决方案。
# 关键字
E-ZKEco Pro系统;系
高级调试与优化技巧:提升Media新CCM18(Modbus-M)安装后性能

# 摘要
本文详细介绍了Media新CCM18(Modbus-M)系统的概览、安装流程、以及与Modbus协议的集成要点和性能评估。文章深入探讨了Modbus协议的基础知识和集成过程,包括硬件集成和软件配置等方面,并通过初步性能基准测试对集成效果进
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )