Keil反汇编自动化工具:快速提升反编译效率的秘诀
发布时间: 2024-12-17 02:17:10 订阅数: 2 

8051asm_c51反编译工具_反汇编_

参考资源链接:[keil对lib封装库反汇编成C语言](https://wenku.csdn.net/doc/6401ad09cce7214c316ee0ef?spm=1055.2635.3001.10343)
# 1. Keil反汇编自动化工具概述
## 简介
在软件开发生命周期中,对二进制代码的分析是不可或缺的一个环节。特别是在嵌入式系统开发领域,Keil反汇编自动化工具为开发者提供了一种高效、精准的分析方法。通过自动化手段,这款工具能够将目标文件中的机器代码快速转换为可读的汇编指令,极大地提高了代码审查、调试和安全分析的效率。
## 发展背景
随着物联网和智能设备的普及,嵌入式软件开发需求日益增长。传统的反汇编方法耗时且易出错,无法满足现代软件开发的节奏。为了解决这一痛点,Keil反汇编自动化工具应运而生,它整合了高级算法和用户友好的界面,使得复杂代码的解析变得触手可及。
## 功能概览
这款工具不仅能反汇编单个文件,还支持批量处理和反汇编结果的查询与优化。用户可以通过图形化界面轻松设定参数,或通过命令行实现更精细的控制。自动化工具还提供了丰富的报告输出选项,帮助开发者从宏观到微观全面掌握程序结构和潜在问题。
# 2. ```
# 第二章:工具理论基础与设计理念
## 2.1 反汇编基本原理
### 2.1.1 汇编语言与机器语言的关系
在计算机科学中,汇编语言和机器语言是软件底层开发的两个重要概念。机器语言是计算机处理器能直接理解和执行的指令集合,通常是一系列二进制代码。而汇编语言则是一种低级语言,它使用助记符来表示机器语言中的操作码和操作数,使得编程人员更容易编写和理解。
在反汇编的过程中,将机器语言翻译回汇编语言是一项基础且复杂的工作。由于不同的处理器架构可能有不同的指令集,这种翻译过程需要对特定的指令集有深入的理解。反汇编工具能够通过分析二进制代码,将这些零和一的序列转换为更加易于阅读的汇编指令,这对于软件逆向工程和漏洞分析尤为重要。
### 2.1.2 反汇编过程中的挑战
反汇编并非总是直接且明确的过程,它涉及到若干技术和非技术性的挑战。技术上,不同架构的处理器指令集可能大相径庭,而一个反汇编器需要支持多种指令集以满足不同环境下的需求。此外,由于现代编译器优化技术的存在,编译出的二进制代码可能包含了大量的优化,这些优化有时会使得反汇编出的汇编代码难以理解。
非技术上的挑战包括了解和适应不同的法律和伦理标准,特别是在安全研究和逆向工程领域。为了在不违反法律的前提下进行反汇编,研究人员需要对相关的法规有充分的了解。
## 2.2 自动化工具的设计理念
### 2.2.1 提高效率的必要性分析
随着软件系统的日益复杂,手工进行反汇编工作已经变得不切实际,特别是在面对大型项目或需要快速分析的场景时。自动化工具的设计理念之一就是为了提高效率,使反汇编工作更加高效和准确。通过对常见任务的自动化,研究人员可以将更多的精力投入到反汇编结果的分析和研究中去。
自动化工具还可以降低对经验的依赖。初学者和不熟悉特定汇编语言的人员通过使用这些工具,也可以快速上手进行反汇编和分析工作。
### 2.2.2 设计目标与预期效果
设计一款反汇编自动化工具时,需要考虑其功能的全面性、使用的便捷性以及结果的准确性。工具应该支持多种架构的处理器,拥有友好的用户界面,并且提供准确的反汇编输出结果。
预期效果是,通过使用该自动化工具,用户能够快速获得反汇编代码,并且这些代码易于理解。此外,工具应该支持扩展性,方便未来添加新的功能或支持新的指令集。
## 2.3 工具架构与工作流程
### 2.3.1 架构概览
一个典型的反汇编自动化工具架构可以分为几个主要组件:输入模块、反汇编核心、输出模块和用户界面。输入模块负责接收用户输入的二进制文件;反汇编核心则包含了解析指令集和实际转换逻辑的算法;输出模块负责将反汇编结果展示给用户或保存到文件;用户界面则提供了一个交互环境,让用户可以更容易地使用工具。
### 2.3.2 工作流程详解
反汇编自动化工具的工作流程可以分为以下几个步骤:
1. 用户通过用户界面选择输入文件,并指定输出格式和选项。
2. 输入模块读取用户选定的二进制文件,并传递给反汇编核心。
3. 反汇编核心解析二进制代码,将其转换为汇编指令,并处理任何可能的代码优化或异常。
4. 输出模块接收汇编代码,并根据用户设置的选项进行输出,可以选择在用户界面直接展示或保存到文件中。
5. 用户分析输出结果,并根据需要调整输入选项,重复以上步骤以获得更好的反汇编效果。
以下是一个简单的伪代码示例,展示如何使用自动化工具的基本逻辑:
```python
def disassemble(file_path, output_format, options):
# 读取二进制文件
binary_data = read_binary_file(file_path)
# 调用反汇编核心
assembly_code = disassemble_core(binary_data, options)
# 输出结果
output_module(assembly_code, output_format)
# 用户界面调用
disassemble("example.bin", "text", {"verbose": True})
```
在上述代码中,`read_binary_file`、`disassemble_core` 和 `output_module` 分别对应于输入模块、反汇编核心和输出模块的功能。用户通过设置 `options` 参数来控制反汇编行为和输出格式。
```
以上是文章第二章的内容,根据您提供的目录大纲结构与内容要求,按照Markdown格式编写完成。
# 3. 工具核心功能与实现
## 3.1 源码与反汇编代码同步
### 3.1.1 同步机制的建立
为了实现源码和反汇编代码的同步,我们首先需要构建一个可靠的同步机制。这种机制将涉及以下几个方面:
- **符号表匹配**:通过解析编译器生成的符号表,我们可以将源码中的函数和变量名与反汇编后的符号进行匹配。
- **代码结构映射**:在反汇编过程中,识别出程序的控制流结构,如循环、条件分支和函数调用,并将其映射回源码。
- **源码行号关联**:将反汇编代码中的每一行与源码中的相应行号关联起来,这通常通过编译器生成的调试信息完成。
构建同步机制的基本步骤如下:
1. **解析源码**:通过编译器前端(如Clang前端)解析源码,提取符号和代码结构。
2. **生成中间表示**:将源码转换为一种中间表示形式,该形式便于存储和处理。
3. **执行反汇编**:使用反汇编引擎(如LLVM的反汇编器)处理目标文件,生成反汇编代码。
4. **映射同步**:通过中间表示,将反汇编代码与源码进行映射匹配,同步两者的信息。
在实现上,可以采用多种编程语言来构建这一机制,例如Python因为其丰富的库支持,可以方便地解析文本文件和处理正则表达式,是构建此类同步机制的理想选择。
### 3.1.2 实际应用案例分析
让我们来看一个简单的案例,来了解同步机制是如何工作的。假设我们有一个用C语言编写的简单函数:
```c
int add(int a, int b) {
return a + b;
}
```
编译后,使用我们的同步工具进行反汇编和源码同步:
1. **解析源码**:工具会识别出`add`函数,并提取其中的符号`a`, `b`和操作`+`。
2. **生成中间表示**:中间表示将包含函数的名称、参数列表和操作符等信息。
3. **执行反汇编**:目标文件反汇编后的代码可能类似于:
```asm
add:
push ebp
mov ebp, esp
mov eax, [ebp+8] ; a
add eax, [ebp+12] ; b
pop ebp
ret
```
4. **映射同步**:将上述反汇编代码中的每一行与源码的相应行进行关联。
最终,我们的同步机制能够展示出如下关联:
- 函数`add`与反汇编标签`add:`对应。
- 源码中的`return a + b;`与反汇编代码中的`mov eax, [ebp+8]`和`add eax,

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
逻辑设计的艺术精髓:数字设计原理与实践第四版全面解读
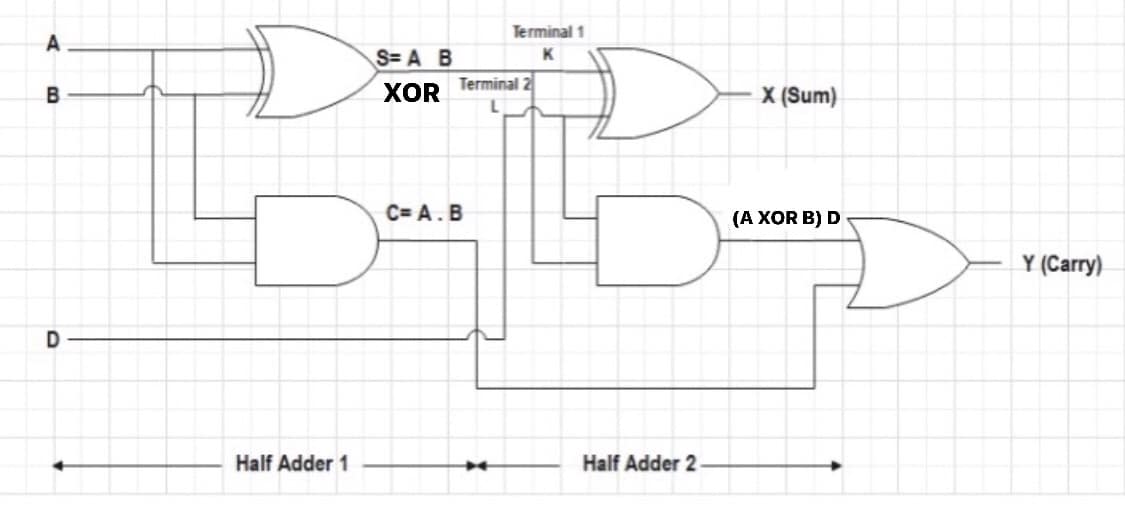
参考资源链接:[John F.Wakerly《数字设计原理与实践》第四版课后答案解析:逻辑图与数制转换](https://wenku.csdn.net/doc/1qxugirwra?spm=1055.2635.3001.10343)
# 1. 数字设计的基本概念与原理
## 理解数字系统设计
在数字设计领域,理解基本概念
TSPL2指令集入门指南:初学者必须掌握的8大基础知识与实践技巧

参考资源链接:[TSPL2指令集详解:TSC条码打印机编程指南](https://wenku.csdn.net/doc/5h3qbbyzq2?spm=1055.2635.3001.10343)
# 1. TSPL2指令集概述
## 1.1 简介与重要性
TSPL2指令集是针对特定硬件平台设计的一套指令集架构,它定义了一系列的操作码(opcode)以及每种操作码的寻址模式、操
构建高效电池通信网络:BMS通讯协议V2.07实战篇(权威教程)
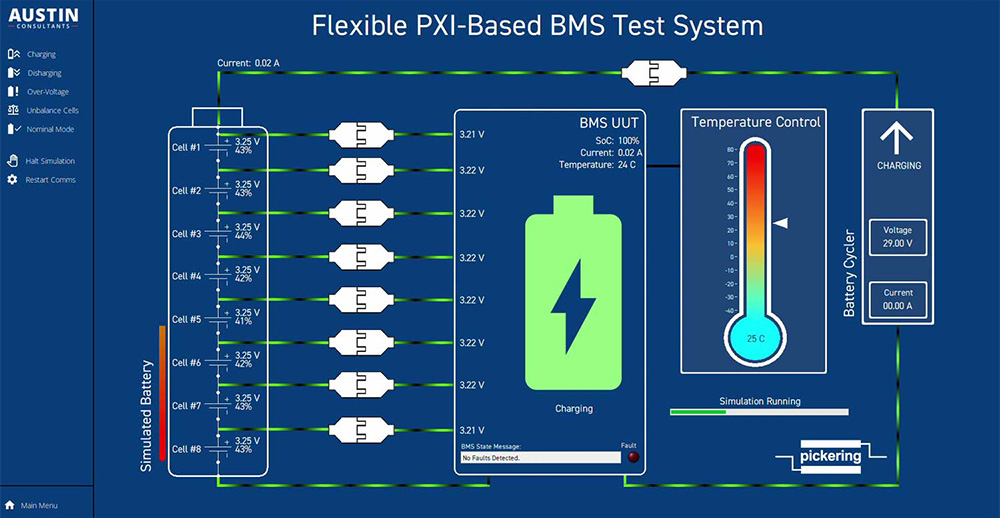
参考资源链接:[沃特玛BMS通讯协议V2.07详解](https://wenku.csdn.net/doc/oofsi3m9yc?spm=1055.2635.3001.10343)
# 1. BMS通讯协议V2.07概述
BMS通讯协议V2.07,作为电池管理系统(Battery Management System)的核心,负责电池模块间的信息交换和数据共享。本章节将概述该协议的主要特点,以及其在现代电池管理系
二手交易平台的7大需求分析秘诀:从用户需求到功能框架的全面解读
参考资源链接:[校园二手交易网站需求规格说明书](https://wenku.csdn.net/doc/2v1uyiaeu5?spm=1055.2635.3001.10343)
# 1. 二手交易平台的市场定位与用户需求
在当下互联网市场中,二手交易平台如雨后春笋般兴起,其具有独特的市场定位和用户需求。首先,从市场定位来看,这些平台通常聚焦于商品的循环利用,满足用户对
【内存管理与指针】:C语言动态内存分配的艺术,彻底解决内存碎片

参考资源链接:[C语言指针详细讲解ppt课件](https://wenku.csdn.net/doc/64a2190750e8173efdca92c4?spm=1055.2635.3001.10343)
# 1. 内存管理和指针的基础知识
## 内存管理的简述
在计算机科学中,内存管理是指对计算机内存资源的分配和回收的过程。有效的内存管理对于保证程序的稳定性和效率至关重
GC2083硬件稳定性保障:兼容性问题全面剖析

参考资源链接:[GC2083CSP: 1/3.02'' 2Mega CMOS Image Sensor 数据手册](https://wenku.csdn.net/do
【Mathematica模式匹配】:深入理解变量替换与函数映射机制

参考资源链接:[Mathematica教程:变量替换与基本操作](https://wenku.csdn.net/doc/41bu50ed0y?spm=1055.2635.3001.10343)
# 1. Mathematica的模式匹配简介
在现代编程实践中,模式匹配已经成为一种强大的工具,用于解决各种问题,从简单的字符串处理到复杂的图形模式识别。Mathematic
【PFC电感参数计算速成】:从理论到应用,一步到位掌握核心技巧

参考资源链接:[Boost PFC电感计算详解:连续模式、临界模式与断续模式](https://wenku.csdn.net/doc/790zbqm1tz?spm=1055.2635.3001.10343)
# 1. PFC电
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )