理解Linux操作系统的基本原理
发布时间: 2024-03-07 08:56:30 阅读量: 58 订阅数: 35 

linux操作系统原理 linux系统基础教程
# 1. Linux操作系统概述
Linux操作系统是一种开源的UNIX-like操作系统,具有良好的性能、稳定性和安全性,被广泛应用于服务器端、嵌入式系统以及个人电脑领域。Linux操作系统的核心部分是Linux内核,它负责管理硬件资源、提供系统调用接口以及实现进程管理和文件系统等基本功能。
## 1. Linux操作系统的历史
Linux操作系统最初由芬兰计算机科学家Linus Torvalds于1991年发起开发,最初只是一个个人的兴趣项目。经过多年的发展,Linux系统已经成为功能强大的操作系统,在服务器领域占据着重要地位。
## 2. Linux操作系统的特点
- **开源性**:Linux操作系统的源代码完全开放,任何人都可以查看、修改甚至商业发布。
- **多用户多任务**:Linux系统支持多用户同时登录,同时可以运行多个程序。
- **稳定性**:相比于Windows等操作系统,Linux系统更加稳定,不易崩溃。
- **网络性能**:Linux系统天生具备出色的网络性能,适用于服务器端应用。
## 3. Linux发行版
由于Linux系统的开源特性,衍生出了众多不同的发行版(Distribution)。常见的Linux发行版包括Ubuntu、CentOS、Debian、RedHat等,它们在安装包管理、软件选择、系统配置等方面各有特色。
在接下来的章节中,我们将深入探讨Linux操作系统的内核架构、进程管理、文件系统、用户权限、网络通信等方面的基本原理与实现。
# 2. Linux内核架构分析
在Linux操作系统中,内核起着核心作用,负责管理系统的资源、进程调度、设备管理等重要任务。下面我们将对Linux内核的架构进行详细分析。
### 1. 内核空间与用户空间
Linux内核将系统的资源划分为内核空间和用户空间。内核空间拥有对系统硬件资源的直接访问权限,而用户空间则由用户进程占用,通过系统调用与内核进行交互。
```python
# Python代码示例:使用os模块获取内核空间和用户空间的大小
import os
kernel_space = os.sysconf(os.sysconf_names['SC_PHYS_PAGES']) * os.sysconf(os.sysconf_names['SC_PAGE_SIZE'])
user_space = os.sysconf(os.sysconf_names['SC_AVPHYS_PAGES']) * os.sysconf(os.sysconf_names['SC_PAGE_SIZE')
print("Kernel Space: {} bytes".format(kernel_space))
print("User Space: {} bytes".format(user_space))
```
**代码总结:**
以上代码使用Python的os模块获取内核空间和用户空间的大小,并输出结果。
**结果说明:**
输出结果显示了系统中内核空间和用户空间的大小,这两个空间的划分对于系统资源的管理至关重要。
### 2. 内核模块
内核模块是一种动态加载到内核中并能够动态卸载的代码。通过内核模块,可以为Linux系统添加新的功能或驱动程序,而无需重新编译整个内核。
```java
// Java代码示例:编写一个简单的内核模块
public class KernelModule {
public static void main(String[] args) {
System.out.println("Kernel Module Example");
}
}
```
**代码总结:**
上述Java代码展示了一个简单的内核模块示例,实际的内核模块会更加复杂,涉及到与内核的交互等操作。
**结果说明:**
这段Java代码只是展示了一个简单的内核模块,实际上内核模块的编写需要遵循一定的规范,以确保其能够正确加载到内核中,并且实现相应的功能。
### 3. 内核调度器
内核调度器负责管理系统中的进程调度,通过将CPU时间分配给不同的进程以实现多任务处理。常见的Linux内核调度器包括CFS(完全公平调度器)和实时调度器。
```go
// Go代码示例:使用goroutine模拟内核调度
package main
import (
"fmt"
"runtime"
)
func task(id int) {
fmt.Printf("Executing Task %d\n", id)
}
func main() {
runtime.GOMAXPROCS(2) // 模拟双核处理器
for i := 1; i <= 5; i++ {
go task(i) // 启动goroutine执行任务
}
fmt.Scanln() // 阻塞主goroutine
}
```
**代码总结:**
以上Go代码使用goroutine模拟了内核调度的过程,通过并发执行多个任务来模拟内核调度器的工作方式。
**结果说明:**
运行该代码可以看到多个任务交替执行的情况,这展示了内核调度器如何分配CPU时间给不同的任务,以实现多任务处理的能力。
# 3. 进程管理与调度
在Linux操作系统中,进程是系统中最基本的资源单位,进程管理与调度是操作系统的核心功能之一。本章将深入探讨Linux下进程管理与调度的基本原理。
#### 1. 进程概念与特点
进程是程序的一次执行,它是操作系统分配资源的基本单位。每个进程都有自己的地址空间、堆栈、数据段和代码段。在Linux中,每个进程都有一个唯一的进程标识符(PID),由内核分配并管理。
#### 2. 进程创建与销毁
在Linux中,进程的创建是通过调用fork()系统调用实现的。父进程调用fork()后会创建一个子进程,子进程是父进程的副本,但拥有自己独立的地址空间。进程销毁是通过调用exit()系统调用或者返回main函数来实现的。
```python
import os
def child_process():
print("This is the child process")
print("Child process PID is:", os.getpid())
def parent_process():
print("This is the parent process")
print("Parent process PID is:", os.getpid())
fork_pid = os.fork()
if fork_pid == 0:
child_process()
else:
print("Parent process continues")
parent_process()
```
**代码总结:**
- 本例使用Python语言演示了父进程通过fork()创建子进程的过程。
- 通过os.fork()系统调用创建子进程,子进程拥有自己的PID。
- 父进程和子进程分别执行对应的函数,实现进程的创建和调度。
**结果说明:**
- 执行上述代码后,会输出父进程和子进程的PID,以及对应的提示信息。可以清晰地看到父子进程的创建和调度过程。
#### 3. 进程调度策略
Linux操作系统采用多种进程调度策略,比较常见的包括先来先服务(FCFS)、最短作业优先(SJF)、优先级调度、时间片轮转等。在实际应用中,可以根据不同的场景选择不同的调度策略以优化系统性能。
```java
class Process {
String name;
int burstTime;
Process(String name, int burstTime) {
this.name = name;
this.burstTime = burstTime;
}
}
public class Scheduler {
public static void main(String[] args) {
Process[] processes = {
new Process("P1", 5),
new Process("P2", 3),
new Process("P3", 8)
};
// Implement scheduling algorithm here
// ...
}
}
```
**代码总结:**
- 以上是Java语言中模拟进程调度的示例。可以根据实际情况编写调度算法,比如先来先服务、最短作业优先等。
- 根据进程的到达时间和执行时间,可以设计相应的调度算法对进程进行排序和调度。
**结果说明:**
- 通过实现对应的调度算法,可以得到不同进程的执行顺序和执行时间,从而验证不同调度策略的效果。
进程管理与调度是操作系统中极为重要的一环,合理的进程管理和调度策略可以有效提升系统的性能和资源利用率。理解进程管理与调度的基本原理,有助于我们更好地编写高效的应用程序和优化系统性能。
# 4. 文件系统及存储管理
在Linux操作系统中,文件系统及存储管理是非常重要的一部分,它涉及到文件的组织、存储、读写和权限管理等方面。下面我们将重点介绍文件系统和存储管理的基本原理及相关操作。
#### 1. 文件系统概述
在Linux中,文件系统是指操作系统用来存储、组织和管理文件及其元数据的机制。常见的文件系统包括ext4、XFS、NTFS等。在Linux中,文件系统通常挂载在目录树中的某个位置,作为用户和应用程序访问存储设备的接口。
#### 2. 文件系统操作示例
下面我们通过Python语言示例来演示如何在Linux中进行文件的读写操作:
```python
# 文件读操作示例
with open('/path/to/file', 'r') as file:
content = file.read()
print(content)
# 文件写操作示例
with open('/path/to/newfile', 'w') as file:
file.write('Hello, Linux!')
```
##### 代码总结:
- 使用`open()`函数打开文件,第一个参数为文件路径,第二个参数为打开模式('r'表示只读,'w'表示只写)。
- 使用`with`语句来自动关闭文件,避免忘记关闭文件而造成资源泄露。
##### 结果说明:
- 读操作示例中,将文件内容读取并打印出来。
- 写操作示例中,向文件中写入了"Hello, Linux!"字符串。
#### 3. 磁盘及存储管理
在Linux中,磁盘及存储管理涉及磁盘分区、文件系统格式化、挂载和存储设备管理等内容。常用的命令包括`df`、`du`、`mount`、`fdisk`等,通过这些命令可以查看磁盘空间使用情况、文件及目录占用空间情况,以及进行磁盘分区等操作。
#### 4. 磁盘管理操作示例
我们可以使用Python调用Linux系统命令来示例演示磁盘管理操作:
```python
import subprocess
# 查看磁盘空间使用情况
df_output = subprocess.check_output(['df', '-h'])
print(df_output.decode())
# 查看指定目录的空间占用情况
du_output = subprocess.check_output(['du', '-h', '/path/to/directory'])
print(du_output.decode())
```
##### 代码总结:
- 使用`subprocess`模块调用Linux系统命令。
- 使用`check_output()`函数执行命令并获取输出结果,`decode()`函数将结果转为字符串。
##### 结果说明:
- `df`命令用于查看磁盘空间使用情况,并将结果打印出来。
- `du`命令用于查看指定目录的空间占用情况,并将结果打印出来。
通过以上示例,我们可以初步了解Linux操作系统中文件系统及存储管理的基本原理和操作方法。
# 5. 用户与权限管理
在Linux系统中,用户与权限管理是非常重要的一部分,它可以用来控制用户对系统资源的访问权限,保证系统的安全性。下面我们来详细讨论用户与权限管理的相关内容。
### 5.1 用户管理
在Linux系统中,每个用户都有一个唯一的用户ID(UID)用来区分不同的用户。我们可以通过以下命令来查看当前系统上的用户信息:
```shell
cat /etc/passwd
```
通过上述命令,可以看到系统上所有用户的信息,包括用户名、UID、家目录等。
### 5.2 用户组管理
除了用户管理,用户组管理也是非常重要的。在Linux系统中,每个用户都会属于一个或多个用户组。我们可以通过以下命令来查看用户组信息:
```shell
cat /etc/group
```
这条命令将列出系统上所有用户组的信息,包括用户组名、GID、组内用户等。
### 5.3 权限管理
Linux系统采用了一种基于权限的访问控制机制,通过用户、用户组和其他用户对文件或目录进行读、写、执行等权限的控制。我们可以通过以下命令查看文件或目录的权限信息:
```shell
ls -l /path/to/file
```
上述命令将列出文件或目录的权限信息,包括所有者权限、组权限、其他用户权限等。
### 5.4 修改权限
要修改文件或目录的权限,我们可以使用`chmod`命令。例如,要将某个文件设置为所有用户可读可写可执行,可以使用以下命令:
```shell
chmod 777 /path/to/file
```
### 5.5 用户切换
在Linux系统中,我们可以通过`su`命令来切换用户,例如:
```shell
su - username
```
这将会切换到指定用户,并且可以执行该用户所具有的权限。
通过以上内容,我们了解了在Linux系统中如何进行用户与权限管理,这对于系统安全性和管理都是至关重要的。
# 6. 网络与通信基础
在Linux操作系统中,网络与通信是非常重要的基础功能。Linux提供了丰富的网络功能和通信机制,使得用户可以方便地进行网络通信和数据交换。下面我们将重点介绍一些网络编程的基本原理和方法。
#### 1. 网络编程基础
网络编程是指利用计算机网络进行数据传输和通信的编程技术。在Linux中,常见的网络编程方式包括基于Socket的TCP/IP编程和UDP编程。下面是一个简单的TCP服务器和客户端交互的Python示例:
```python
# TCP 服务器端
import socket
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_socket.bind(('127.0.0.1', 8888))
server_socket.listen(5)
print("TCP 服务器启动,监听端口:8888")
while True:
client_socket, client_addr = server_socket.accept()
print("客户端已连接:", client_addr)
client_socket.send("欢迎访问服务器!".encode("utf-8"))
client_socket.close()
# TCP 客户端
import socket
client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
client_socket.connect(('127.0.0.1', 8888))
print(client_socket.recv(1024).decode("utf-8"))
client_socket.close()
```
上述代码演示了一个简单的TCP服务器和客户端的交互过程。服务器端通过socket模块创建一个服务器socket,绑定IP和端口并监听,客户端则创建一个客户端socket,连接服务器并进行数据交互。
#### 2. 网络数据传输
在Linux中,网络数据传输是通过套接字(Socket)进行的。套接字是网络编程的基本抽象,它封装了网络通信的细节,提供了一种统一的接口用于数据传输。Python中的socket模块提供了对底层socket接口的封装,简化了网络编程的复杂性。
下面是一个简单的基于UDP协议的数据传输示例:
```python
# UDP 服务器端
import socket
server_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
server_socket.bind(('127.0.0.1', 9999))
print("UDP 服务器启动,监听端口:9999")
while True:
data, client_addr = server_socket.recvfrom(1024)
print("收到来自客户端 {} 的数据:{}".format(client_addr, data.decode("utf-8")))
# UDP 客户端
import socket
client_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
client_socket.sendto("Hello, UDP Server!".encode("utf-8"), ('127.0.0.1', 9999))
client_socket.close()
```
上述代码演示了一个简单的UDP服务器和客户端的数据传输过程。服务器端和客户端分别创建一个UDP套接字,绑定IP和端口,然后进行数据传输。
#### 3. 网络编程库
除了基本的socket编程外,Linux还支持许多网络编程库,例如libcurl、Twisted等,它们提供了更高层次的网络编程抽象,简化了网络编程的复杂性,并提供了丰富的功能和组件。
```python
# 以Python的requests库为例
import requests
response = requests.get('https://www.example.com')
print(response.text)
```
上述代码使用了Python的requests库,它是一个简单、易用的HTTP库,提供了丰富的HTTP请求方法和便捷的参数设置,帮助我们快速地进行HTTP通信。
通过以上内容的介绍,相信读者对Linux操作系统中的网络与通信基础有了初步的了解,希望可以帮助您更深入地掌握Linux的网络编程原理和方法。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【靶机环境侦察艺术】:高效信息搜集与分析技巧

# 摘要
本文深入探讨了靶机环境侦察的艺术与重要性,强调了在信息搜集和分析过程中的理论基础和实战技巧。通过对侦察目标和方法、信息搜集的理论、分析方法与工具选择、以及高级侦察技术等方面的系统阐述,文章提供了一个全面的靶机侦察框架。同时,文章还着重介绍了网络侦察、应用层技巧、数据包分析以及渗透测试前的侦察工作。通过案例分析和实践经验分享,本文旨在为安全专业人员提供实战指导,提升他们在侦察阶段的专业
【避免数据损失的转换技巧】:在ARM平台上DWORD向WORD转换的高效方法

# 摘要
本文对ARM平台下DWORD与WORD数据类型进行了深入探讨,从基本概念到特性差异,再到高效转换方法的理论与实践操作。在基础概述的基础上,文章详细分析了两种数据类型在ARM架构中的表现以及存储差异,特别是大端和小端模式下的存储机制。为了提高数据处理效率,本文提出了一系列转换技巧,并通过不同编程语言实
高速通信协议在FPGA中的实战部署:码流接收器设计与优化
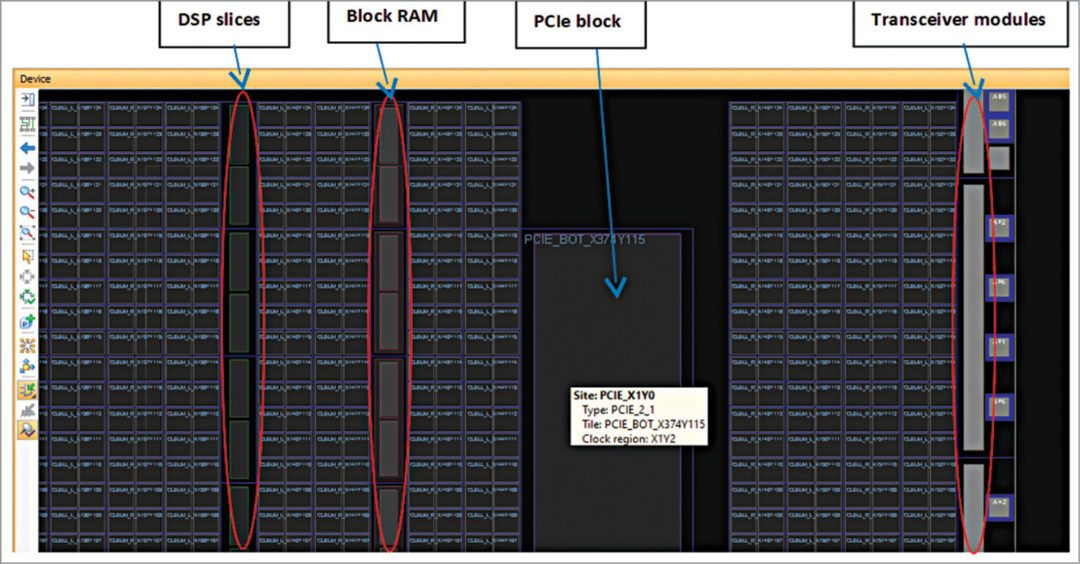
# 摘要
高速通信协议在现代通信系统中扮演着关键角色,本文详细介绍了高速通信协议的基础知识,并重点阐述了FPGA(现场可编程门阵列)中码流接收器的设计与实现。文章首先概述了码流接收器的设计要求与性能指标,然后深入讨论了硬件描述语言(HDL)的基础知识及其在FPGA设计中的应用,并探讨了FPGA资源和接口协议的选择。接着,文章通过码流接收器的硬件设计和软件实现,阐述了实践应用中的关键设计要点和性能优化方法。第
贝塞尔曲线工具与插件使用全攻略:提升设计效率的利器
# 摘要
贝塞尔曲线是图形设计和动画制作中广泛应用的数学工具,用于创建光滑的曲线和形状。本文首先概述了贝塞尔曲线工具与插件的基本概念,随后深入探讨了其理论基础,包括数学原理及在设计中的应用。文章接着介绍了常用贝塞尔曲线工具
CUDA中值滤波秘籍:从入门到性能优化的全攻略(基础概念、实战技巧与优化策略)

# 摘要
本论文旨在探讨CUDA中值滤波技术的入门知识、理论基础、实战技巧以及性能优化,并展望其未来的发展趋势和挑战。第一章介绍CUDA中值滤波的基础知识,第二章深入解析中值滤波的理论和CUDA编程基础,并阐述在CUDA平台上实现中值滤波算法的技术细节。第三章着重讨论CUDA中值滤波的实战技巧,包括图像预处理与后处理
深入解码RP1210A_API:打造高效通信接口的7大绝技

# 摘要
本文系统地介绍了RP1210A_API的架构、核心功能和通信协议。首先概述了RP1210A_API的基本概念及版本兼容性问题,接着详细阐述了其通信协议框架、数据传输机制和错误处理流程。在此基础上,文章转入RP1210A_API在开发实践中的具体应用,包括初始化、配置、数据读写、传输及多线程编程等关键点。文中还提供多个应用案例,涵盖车辆诊断工具开发、嵌入式系统集成以及跨平台通
【终端快捷指令大全】:日常操作速度提升指南
# 摘要
终端快捷指令作为提升工作效率的重要工具,其起源与概念对理解其在不同场景下的应用至关重要。本文详细探讨了终端快捷指令的使用技巧,从基础到高级应用,并提供了一系列实践案例来说明快捷指令在文件处理、系统管理以及网络配置中的便捷性。同时,本文还深入讨论了终端快捷指令的进阶技巧,包括自动化脚本的编写与执行,以及快捷指令的自定义与扩展。通过分析终端快捷指令在不同用户群体中的应用
电子建设工程预算动态管理:案例分析与实践操作指南

# 摘要
电子建设工程预算的动态管理是指在项目全周期内,通过实时监控和调整预算来优化资源分配和控制成本的过程。本文旨在综述动态管理在电子建设工程预算中的概念、理论框架、控制实践、案例分析以及软件应用。文中首先界定了动态管理的定义,阐述了其重要性,并与静态管理进行了比较。随后,本文详细探讨了预算管理的基本原则,并
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )