JavaWeb连接Spark数据库的深入分析:实时数据处理,提升决策效率
发布时间: 2024-07-17 13:21:22 阅读量: 46 订阅数: 45 

JAVAweb连接oracle数据库工程

# 1. JavaWeb与Spark数据库连接概述**
JavaWeb与Spark数据库的连接是将Java Web应用程序与Spark分布式数据库系统集成在一起的重要技术。它使开发人员能够从Java Web应用程序中访问、查询和操作Spark数据库中的数据。
Spark数据库以其分布式计算引擎和内存计算优化而著称,使其能够高效处理海量数据。通过连接Spark数据库,Java Web应用程序可以利用这些优势来实现实时数据分析、决策支持系统等各种应用程序。
# 2. JavaWeb连接Spark数据库的理论基础
### 2.1 Spark数据库架构与特性
#### 2.1.1 分布式计算引擎
Spark是一个分布式计算引擎,它可以将计算任务并行化地分布在多个节点上。这种分布式架构使得Spark能够处理海量数据,并实现高吞吐量和低延迟。
#### 2.1.2 内存计算优化
Spark采用了内存计算优化技术,将数据加载到内存中进行处理。这种方式可以显著提高查询性能,尤其是在处理大数据集时。
### 2.2 JDBC与Spark SQL连接机制
#### 2.2.1 JDBC连接原理
JDBC(Java Database Connectivity)是一种标准的Java API,用于连接和操作数据库。JDBC连接器提供了一个抽象层,允许Java应用程序与各种数据库系统交互。
#### 2.2.2 Spark SQL连接方式
Spark SQL是Spark中一个用于处理结构化数据的模块。它提供了一个类似SQL的接口,允许用户使用SQL查询和操作数据。Spark SQL支持多种数据源,包括Spark DataFrames、JDBC连接和Hive表。
# 3. JavaWeb连接Spark数据库的实践操作
### 3.1 JDBC连接实现
#### 3.1.1 导入相关依赖
在JavaWeb项目中连接Spark数据库,需要导入以下依赖:
```xml
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.30</version>
</dependency>
```
#### 3.1.2 建立数据库连接
建立JDBC连接的步骤如下:
1. 加载JDBC驱动:
```java
Class.forName("com.mysql.cj.jdbc.Driver");
```
2. 创建连接:
```java
Connection conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/spark_db", "root", "password");
```
3. 创建Statement:
```java
Statement stmt = conn.createStatement();
```
4. 执行SQL查询:
```java
ResultSet rs = stmt.executeQuery("SELECT * FROM users");
```
5. 处理结果集:
```java
while (rs.next()) {
System.out.println(rs.getString("name"));
}
```
6. 关闭资源:
```java
rs.close();
stmt.close();
conn.close();
```
### 3.2 Spark SQL连接实现
#### 3.2.1 创建SparkSession
SparkSession是Spark SQL连接的入口,创建SparkSession的步骤如下:
```java
SparkSession spark = SparkSession
.builder()
.appName("JavaWebSparkSQL")
.master("local[*]")
.getOrCreate();
```
#### 3.2.2 执行SQL查询
使用Spark SQL连接Spark数据库,可以执行SQL查询,步骤如下:
1. 创建DataFrame:
```java
DataFrame df = spark.read()
.format("jdbc")
.option("url", "jdbc:mysql://localhost:3306/spark_db")
.option("user", "root")
.option("password", "password")
.option("dbtable
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 JavaWeb 与各种数据库的连接技术,从基础到高级,全面涵盖了数据库连接的方方面面。专栏文章涵盖了 JavaWeb 数据库连接的秘籍、幕后机制、性能优化指南、最佳实践以及常见问题的解决方法。此外,还深入分析了与 MySQL、SQL Server、MongoDB、Redis、Elasticsearch、Cassandra、HBase、Hadoop、Spark、Flink、Kafka、RabbitMQ 和 ActiveMQ 等流行数据库的连接,提供了实用的经验和性能调优建议。通过阅读本专栏,JavaWeb 开发人员可以全面掌握数据库连接技术,提升数据库响应速度,并解决各种连接问题,从而构建高效、稳定且可扩展的 JavaWeb 应用。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
电力电子技术基础:7个核心概念与原理让你快速入门
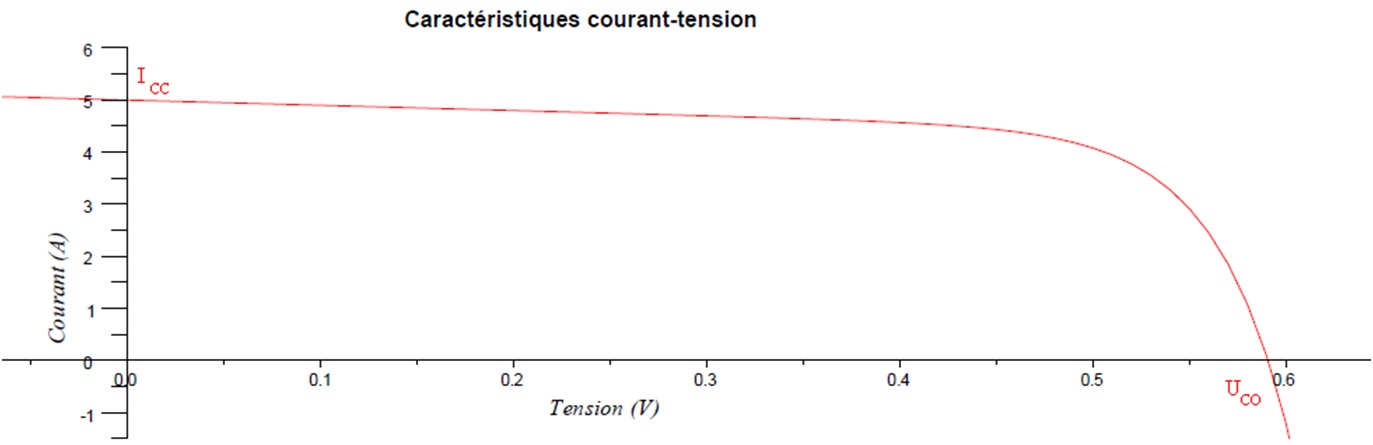
# 摘要
电力电子技术作为电力系统与电子技术相结合的交叉学科,对于现代电力系统的发展起着至关重要的作用。本文首先对电力电子技术进行概述,并深入解析其核心概念,包括电力电子变换器的分类、电力半导体器件的特点、控制策略及调制技术。进一步,本文探讨了电路理论基础、功率电子变换原理以及热管理与散热设计等基础理论与数学模型。文章接
PDF格式全面剖析:内部结构深度解读与高级操作技巧

# 摘要
PDF格式因其跨平台性和保持文档原貌的优势,在数字出版、办公自动化、法律和医疗等多个行业中得到广泛应用。本文首先概述了PDF格式的基本概念及其内部结构,包括文档组成元素、文件头、交叉引用表和PDF语法。随后,文章深入探讨了进行PDF文档高级操作的技巧,如编辑内容、处理表单、交互功能以及文档安全性的增强方法。接着,
【施乐打印机MIB效率提升秘籍】:优化技巧助你实现打印效能飞跃

# 摘要
施乐打印机中的管理信息库(MIB)是提升打印设备性能的关键技术,本文对MIB的基础知识进行了介绍,并理论分析了其效率。通过对MIB的工作原理和与打印机性能关系的探讨,以及效率提升的理论基础研究,如响应时间和吞吐量的计算模型,本文提供了优化打印机MIB的实用技巧,包括硬件升级、软件和固件调
FANUC机器人编程新手指南:掌握编程基础的7个技巧

# 摘要
本文提供了FANUC机器人编程的全面概览,涵盖从基础操作到高级编程技巧,以及工业自动化集成的综合应用。文章首先介绍了FANUC机器人的控制系统、用户界面和基本编程概念。随后,深入探讨了运动控制、I/O操作
【移远EC200D-CN固件升级速通】:按图索骥,轻松搞定固件更新

# 摘要
本文全面概述了移远EC200D-CN固件升级的过程,包括前期的准备工作、实际操作步骤、升级后的优化与维护以及案例研究和技巧分享。文章首先强调了进行硬件与系统兼容性检查、搭建正确的软件环境、备份现有固件与数据的重要性。其次,详细介绍了固件升级工具的使用、升级过程监控以及升级后的验证和测试流程。在固件升级后的章节中,本文探讨了系统性能优化和日常维护的策略,并分享了用户反馈和升级技巧。
【二次开发策略】:拉伸参数在tc itch中的应用,构建高效开发环境的秘诀

# 摘要
本文旨在详细阐述二次开发策略和拉伸参数理论,并探讨tc itch环境搭建和优化。首先,概述了二次开发的策略,强调拉伸参数在其中的重要作用。接着,详细分析了拉伸参数的定义、重要性以及在tc itch环境中的应用原理和设计原则。第三部分专注于tc itch环境搭建,从基本步骤到高效开发环境构建,再到性能调
CANopen同步模式实战:精确运动控制的秘籍
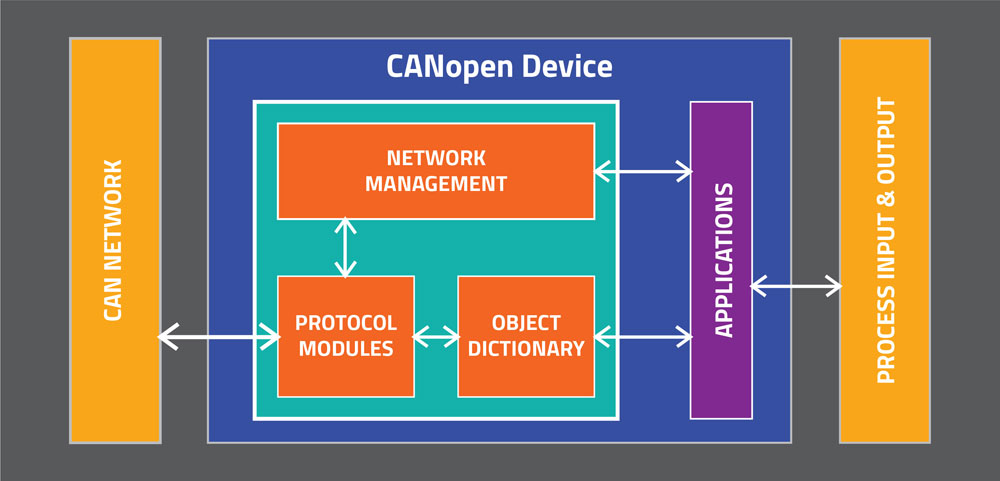
# 摘要
CANopen是一种广泛应用在自动化网络通信中的协议,其中同步模式作为其重要特性,尤其在对时间敏感的应用场景中扮演着关键角色。本文首先介绍了CANopen同步模式的基础知识,然后详细分析了同步机制的关键组成部分,包括同步消息(SYNC)的原理、同步窗口(SYNC Window)的配置以及同步计数器(SYNC Counter)的管理。文章接着
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )