粒子群算法教育优化:教学策略升级,提升学习效果
发布时间: 2024-07-20 08:20:12 阅读量: 44 订阅数: 46 
# 1. 粒子群算法概述**
粒子群算法(PSO)是一种受鸟类或鱼群等群体行为启发的优化算法。它模拟了群体中的个体(粒子)相互学习和协作的过程,以找到问题的最优解。
PSO算法的基本原理是:每个粒子在搜索空间中移动,并根据自身最佳位置(pbest)和群体最佳位置(gbest)更新自己的速度和位置。通过迭代更新,粒子群逐渐收敛到最优解附近。
# 2. 粒子群算法在教育优化中的应用
### 2.1 粒子群算法的原理和特点
粒子群算法(PSO)是一种受鸟群觅食行为启发的优化算法。它模拟一群粒子在搜索空间中移动,每个粒子代表一个潜在的解决方案。粒子通过相互交流和学习,逐步向最优解移动。
PSO算法的关键概念包括:
- **粒子:**代表一个潜在的解决方案,具有位置和速度。
- **群体:**一群粒子,每个粒子相互交流和学习。
- **最优位置:**每个粒子记录的迄今为止找到的最佳位置。
- **全局最优位置:**群体中所有粒子找到的最佳位置。
PSO算法的步骤如下:
1. 初始化粒子群,包括粒子的位置和速度。
2. 评估每个粒子的适应度,即目标函数的值。
3. 更新每个粒子的最优位置和全局最优位置。
4. 计算每个粒子的速度和位置。
5. 重复步骤2-4,直到达到停止条件(例如,达到最大迭代次数或满足收敛标准)。
### 2.2 粒子群算法在教育优化中的优势和局限
粒子群算法在教育优化中具有以下优势:
- **全局搜索能力:**PSO算法能够有效地探索搜索空间,避免陷入局部最优解。
- **简单易用:**PSO算法的实现相对简单,易于理解和应用。
- **鲁棒性:**PSO算法对参数设置不敏感,具有较好的鲁棒性。
然而,粒子群算法也存在一些局限:
- **收敛速度慢:**PSO算法在某些情况下收敛速度较慢,尤其是在高维搜索空间中。
- **参数敏感性:**虽然PSO算法对参数设置不敏感,但不同的参数设置可能会影响算法的性能。
- **精度有限:**PSO算法可能无法找到全局最优解的精确解,而是找到一个近似解。
# 3. 粒子群算法优化教学策略
### 3.1 教学目标和优化目标的确定
在粒子群算法优化教学策略之前,需要明确教学目标和优化目标。教学目标是教育活动中预期的学习成果,而优化目标是通过粒子群算法优化教学策略所要达到的具体目标。
教学目标应根据课程标准、教学大纲和学生实际情况制定,遵循SMART原则(具体、可衡量、可实现、相关、有时限)。优化目标应与教学目标相对应,并根据教学策略的具体内容进行细化。
### 3.2 粒子群算法优化教学策略的步骤
粒子群算法优化教学策略的步骤主要包括:
1. **初始化粒子群:**确定粒子群规模、粒子位置和速度。
2. **计算适应度值:**根据优化目标计算每个粒子的适应度值。
3. **更新粒子位置和速度:**根据粒子群算法公式更新粒子的位置和速度。
4. **更新最优粒子:**比较当前粒子群中所有粒子的适应度值,更新全局最优粒子(gbest)和个体最优粒子(pbest)。
5. **重复步骤2-4:**重复以上步骤,直到达到终止条件(如最大迭代次数或适应度值收敛)。
### 3.3 优化教学策略的案例分析
**案例:**优化高中数学教学策略
**教学目标:**提高学生对函数概念的理解和应用能力。
**优化目标:**
* 提高学生对函数图象的绘制能力。
* 提高学生对函数性质的理解。
* 提高学生对函数应用的解决问题能力。
**粒子群算法优化教学策略:**
1. **初始化粒子群:**粒子群规模为20,粒子位置和速度随机初始化。
2. **计算适应度值:**根据学生对函数图象绘制、函数性质理解和函数应用解决问题能力的测试成绩计算适应度值。
3. **更新粒子位置和速度:**使用粒子群算法公式更新粒子的位置和速度。
4. **更新最优粒子:**比较当前粒子群中所有粒子的适应度值,更新全局最优粒子(gbest)和个体最优粒子(pbest)。
5. **重复步骤2-4:**重复以上步骤,直到达到最大迭代次数(50)。
**结果:**
经过粒子群算法优化后,学生的函数图象绘制能力、函数性质理解和函数应用解决问题能力均有显著提高。
**代码块:**
```python
import numpy as np
class Particle:
def __init__(self, position, velocity):
self.position = position
self.velocity = velocity
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
粒子群算法专栏深入探讨了这一创新算法在广泛领域的应用,从图像处理到医疗诊断,再到制造业优化和教育升级。通过深入浅出的案例分析,专栏揭示了粒子群算法如何解决复杂问题,提高效率,并为各种行业带来变革性影响。从机器学习模型的性能提升到云计算资源的优化,粒子群算法正以其强大的优化能力和创新潜力,推动着各个领域的进步。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
VW80808-1负载均衡策略:设计高可用架构的终极指南(架构设计)

参考资源链接:[VW80808-1中文版:2020电子组件标准规范](https://wenku.csdn.net/doc/3obrzxnu87?spm=1055.2635.300
【多语言使用指南】:ATEQ F610_F620_F670国际化体验速成

参考资源链接:[ATEQ F610/F620/F670中文手册:全面详尽操作指南](https://wenku.csdn.net/doc/6412b730be7fbd1778d49679?spm=1055.2635.3001.10343)
# 1. 多语言国际化的重要性与基本概念
在全球化的今天,软件和产品不再仅仅面向本地市场。多语言国际化是企业产品在全球范围内成功的关键因素之一。本章将探讨国际化的重要性,并介绍一些核心概念。
##
硬盘SMART信息解读:高级用户必备知识
参考资源链接:[硬盘SMART错误警告解决办法与诊断技巧](https://wenku.csdn.net/doc/7cskgjiy20?spm=1055.2635.3001.10343)
# 1. 硬盘与SMART技术概述
硬盘是计算机中存储数据的关键部件,它的稳定性直接关系到整个系统的运行。随着技术的发展,硬盘存储容量和速度不断提升,随之而来的是更高的故障风险。因此,硬盘的健康监测变得至关重要。SMART(Self-Monitoring, Analysis, and Reporting Technology)技术应运而生,它是一种硬盘自我监测、分析和报告技术,目的是通过持续监控硬盘运行状态
FANUC机器人与数据库集成:数据持久化与查询优化的完美结合
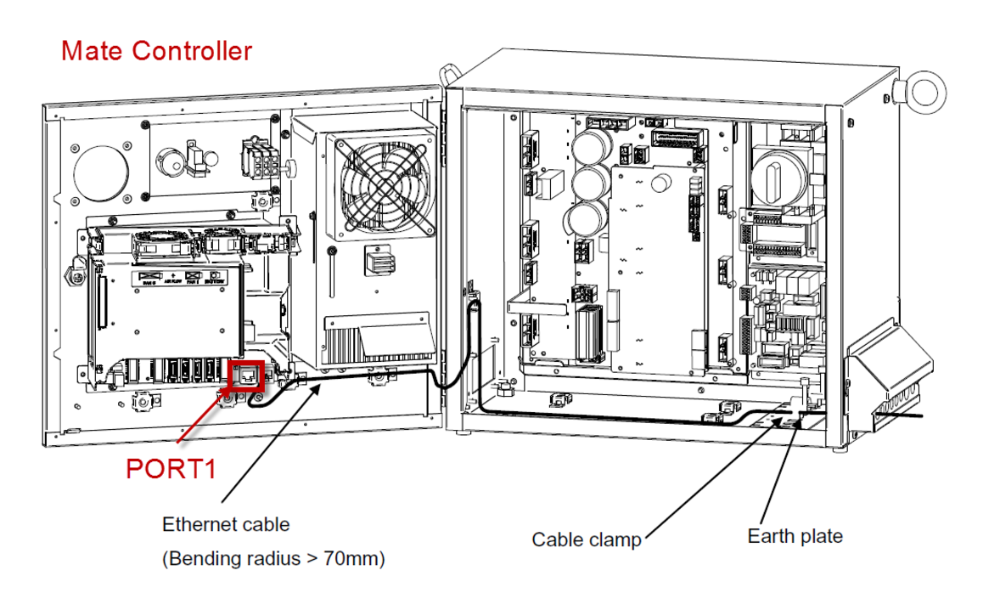
参考资源链接:[FANUC机器人TCP/IP通信设置手册](https://wenku.csdn.net/doc/6401acf8cce7214c316edd05?spm=1055.2635.3001.10343)
# 1. FANUC机器人与数据库集成概述
## 1.1 集成背景与需求分析
在现代制造业中,机器人与数据库的集成变得越来越重要。FANUC机器人作为工业自动化领域的领头羊,其与数据库的高效集成能够帮助企业实现数据驱动的智能化生
【自动编译问题排查】:IDEA编译错误,快速诊断与解决
参考资源链接:[IDEA 开启自动编译设置步骤](https://wenku.csdn.net/doc/646ec8d7d12cbe7ec3f0b643?spm=1055.2635.3001.10343)
# 1. 理解IDEA中的自动编译机制
在使用现代集成开发环境(IDE)如IntelliJ IDEA进行
航空航天领域的比例谐振控制前沿研究:探索未来技术

参考资源链接:[比例谐振PR控制器详解:从理论到实践](https://wenku.csdn.net/doc/5ijacv41jb?spm=1055.2635.3001.10343)
# 1. 比例谐振控制在航空航天领域的概述
## 1.1 航空航天控制需求的特殊性
在航空航天领域,控制系统的精确性和可靠性是至关重要的。由于航空航天环境的严酷
【PFC5.0高可用性架构设计】:保障业务连续性的策略与技巧

参考资源链接:[PFC5.0用户手册:入门与教程](https://wenku.csdn.net/doc/557hjg39sn?spm=1055.2635.3001.10343)
# 1. PFC5.0高可用性架构概述
PFC5.0高可用性架构作为企业级解决方案的最新突破,旨在为企业提供不间断的业务运行和数据
【Star CCM+模型验证与准确性保障】:严格验证流程,确保仿真结果的可靠性
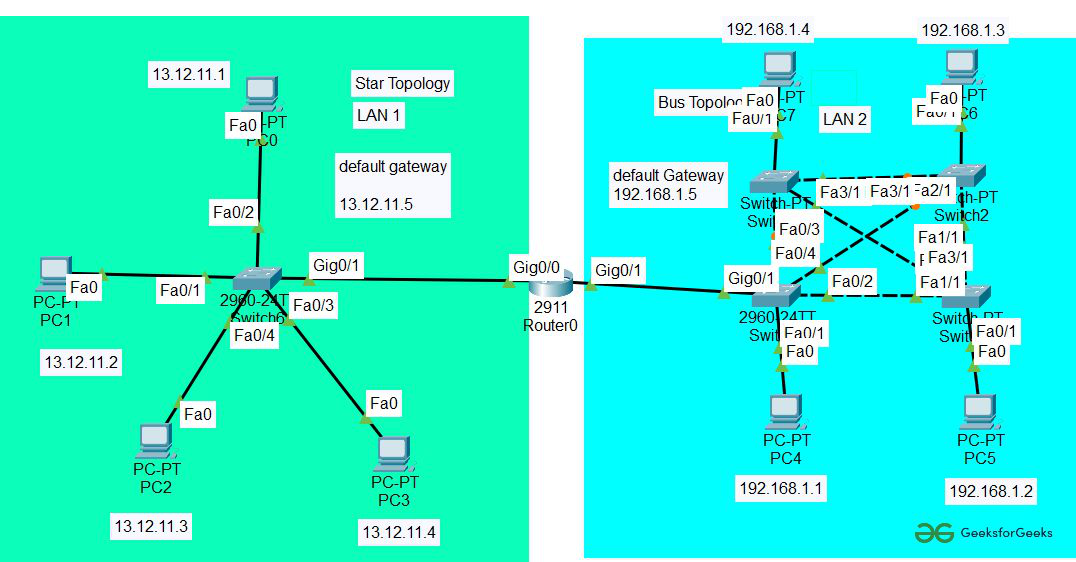
参考资源链接:[STAR-CCM+用户指南:版本13.02官方文档](https://wenku.csdn.net/doc/2x631xmp84?spm=1055.2635.3001.10343)
# 1. Star CCM+简介及仿真模型基础
## Star CCM+软件概述
Star CCM+是一款功能强大的多物理场计算流体动力学(CFD)仿真软件,由
STM32F103VET6编程接口设计:ISP与JTAG注意事项详解
参考资源链接:[STM32F103VET6 PCB原理详解:最小系统板与电路布局](https://wenku.csdn.net/doc/6412b795be7fbd1778d4ad36?spm=1055.2635.3001.10343)
# 1. STM32F103VET6硬件概述与接口介绍
## 简介
在嵌入式系统开发中,STM32F103VET6
iSecure Center审计功能:合规性监控与审计报告完全解析

参考资源链接:[iSecure Center 安装指南:综合安防管理平台部署步骤](https://wenku.csdn.net/doc/2f6bn25sjv?spm=1055.2635.3001.10343)
# 1. iSecure Center审计功能概述
## 1.1 了解iSecure Center
iSecure Center是一个高效的审计和合规性
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )