Kylin的查询优化与性能调优
发布时间: 2024-02-24 00:18:45 阅读量: 39 订阅数: 21 

查询优化
# 1. Kylin简介与基本原理
## 1.1 Kylin的概述
Apache Kylin 是一个开源的分布式分析引擎,它提供了快速、交互式的 OLAP 查询能力,能够在海量数据上实现秒级查询。Kylin最初由eBay开发,并于2015年捐赠给Apache软件基金会,成为Apache顶级项目。Kylin的主要目标是为了解决BI查询中的大数据延迟和复杂性问题。
## 1.2 Kylin的架构与工作原理
Kylin的架构主要包括元数据存储模块、元数据管理模块、查询引擎以及存储层。其中元数据存储模块使用HBase存储Cube元数据,元数据管理模块负责元数据的维护和更新,查询引擎负责解析查询请求并执行Cube查询,存储层主要为HDFS,可支持各种数据源的接入。
## 1.3 Kylin的查询优化和性能调优的重要性
Kylin的查询优化和性能调优直接影响到查询效率和用户体验,通过合理的数据模型设计、Cube设计与构建、查询语句的编写与优化等手段,可以显著提升Kylin的性能表现。在大数据环境下,进行Kylin的性能调优也是保证数据分析效率和企业核心竞争力的重要一环。
# 2. Kylin查询优化的基本原则
### 2.1 数据模型设计
在Kylin中,数据模型设计是查询性能的基础。合理的数据模型设计可以大大提升查询效率。以下是一些建议的数据模型设计原则:
```java
// 示例代码:创建数据模型
CREATE TABLE facts_table (
id INT,
time_date DATE,
category VARCHAR(50),
value DECIMAL
);
// 示例代码:创建维度表
CREATE TABLE dim_table (
id INT,
category VARCHAR(50),
name VARCHAR(50)
);
// 示例代码:创建Kylin数据模型
{
"model_desc": {
"name": "demo_model",
"fact_table": "facts_table",
"lookup_tables": [
{
"alias": "dim_table",
"table": "dim_table",
"join": {
"type": "inner",
"primary_key": "id",
"foreign_key": "id"
}
}
]
}
}
```
### 2.2 Cube设计与构建
在Kylin中,Cube是预先计算好的数据集合,可以加速查询。Cube的设计和构建是优化查询性能的关键。以下是一些Cube设计与构建的关键点:
```java
// 示例代码:构建Cube
{
"cube": {
"name": "demo_cube",
"model_ref": "demo_model",
"aggregation_groups": [
{
"includes": [
{
"column": "category",
"measure_refs": ["sum(value)"]
}
]
}
]
}
}
```
### 2.3 查询语句编写与优化
编写高效的查询语句也是优化查询性能的重要步骤,可以通过合理的SQL语句编写来减少查询时间。以下是一些查询语句优化的建议:
```java
// 示例代码:优化查询语句
SELECT category, SUM(value)
FROM facts_table
JOIN dim_table ON facts_table.id = dim_table.id
WHERE time_date BETWEEN '2022-01-01' AND '2022-01-31'
GROUP BY category;
```
通过以上数据模型设计、Cube设计与构建以及查询语句优化的步骤,可以有效提升Kylin查询的性能和效率。
# 3. Kylin查询性能调优的实践与案例
在Kylin中,查询性能调优是至关重要的环节。通过实践与案例分析,我们可以更好地理解如何优化查询性能,提升系统整体性能。下面将介绍Kylin查询性能调优的实践方法和案例。
#### 3.1 基于数据模型的优化实践
为了提高Kylin查询的性能,首先要从数据模型的角度进行优化。以下是一些优化实践方法:
```java
// 示例代码:基于数据模型的查询优化实践
public class DataModelOptimization {
public static void main(String[] args) {
// 在数据模型中合理设计维度与度量
// 避免过度聚合,保持维度与指标的平衡
// 使用分层数据模型,避免过深的维度层级
// 定期评估数据模型的性能,并进行调整
}
}
```
**代码总结:** 数据模型设计的优化需要根据具体业务需求进行调整,并不断评估性能进行优化。
**结果说明:** 通过基于数据模型的优化实践,可以有效提升Kylin查询的性能和效率。
#### 3.2 Cube设计与构建的最佳实践
Cube是Kylin的核心概念,其设计与构建对整体性能具有重要影响。以下是一些Cube设计与构建的最佳实践:
```python
# 示例代码:Cube设计与构建的最佳实践
def cube_design_best_practice():
# 避免Cube设计过于复杂,保持简洁高效
# 合理选择Cube的切分策略,避免数据倾斜
# 定期更新Cube以保持数据的新鲜度
# 使用Incremental Build优化Cube的构建速度
```
**代码总结:** Cube设计与构建需要考虑数据的复杂性和实时性,选择合适的策略进行优化。
**结果说明:** 通过最佳实践的Cube设计与构建,可以提高Kylin系统的稳定性和性能。
#### 3.3 复杂查询优化的方法与技巧
复杂查询在实际应用中经常会遇到,针对复杂查询需要采取相应的优化方法与技巧。以下是一些优化方法与技巧:
```javascript
// 示例代码:复杂查询优化方法与技巧
const complexQueryOptimization = () => {
// 使用合适的索引提高查询速度
// 避免全表扫描,减少不必要的数据加载
// 拆分复杂查询为多个简单查询,并进行优化
// 使用缓存与预热技术加快查询速度
}
```
**代码总结:** 对于复杂查询,需要结合索引优化、查询拆分等技巧进行性能调优。
**结果说明:** 通过复杂查询优化的方法与技巧,可以提升Kylin系统对复杂查询的响应速度和稳定性。
在Kylin查询性能调优的实践与案例中,以上方法与技巧可以帮助我们更好地优化系统性能,提高用户体验。通过不断实践和优化,Kylin系统将能够更高效地支持复杂查询需求。
# 4. Kylin查询性能监控与诊断
在Kylin的查询优化过程中,监控与诊断是至关重要的一环。通过对查询执行情况进行监控分析,可以及时发现性能瓶颈并进行针对性优化,最大程度提升查询效率。本章将介绍Kylin查询性能监控与诊断的相关内容。
#### 4.1 查询日志分析与优化
Kylin会记录查询日志,包括查询的SQL、执行时间、扫描行数等信息。通过分析查询日志,可以发现哪些查询存在性能问题,并进行相应的优化调整。以下是一个简单的示例代码,演示如何分析查询日志并输出查询耗时最长的TOP N条SQL:
```python
# 读取Kylin查询日志文件
query_log_file = open("kylin_query.log", "r")
query_logs = query_log_file.readlines()
# 解析查询日志,提取SQL及执行时间
query_dict = {}
for log in query_logs:
log_split = log.split("\t")
query_sql = log_split[0]
execute_time = float(log_split[1])
query_dict[query_sql] = execute_time
# 找出执行时间最长的TOP N条SQL
top_n = 5
sorted_queries = sorted(query_dict.items(), key=lambda x: x[1], reverse=True)[:top_n]
# 输出查询耗时最长的TOP N条SQL
for i, query_info in enumerate(sorted_queries):
print(f"TOP {i+1} SQL - Execute Time: {query_info[1]}s")
print(query_info[0])
```
**代码总结:**
- 通过读取Kylin的查询日志文件,可以获取查询SQL及执行时间等信息。
- 利用Python解析查询日志,提取关键信息并存储到字典中。
- 使用排序函数找出执行时间最长的TOP N条SQL,并输出结果。
**结果说明:**
通过以上代码,可以快速定位Kylin查询中执行时间较长的SQL语句,有针对性地进行性能优化和调整。
#### 4.2 Kylin性能监控指标与工具
Kylin提供了丰富的性能监控指标和工具,帮助用户全面了解查询执行情况和集群性能状况。通过监控指标和工具,可以实时监控Kylin的运行状态,及时发现问题并采取措施。以下是Kylin常用的性能监控指标和工具:
- **JMX监控**:Kylin支持JMX(Java Management Extensions)监控,通过JConsole等工具可以获取Kylin的关键性能指标和运行状态。
- **Query Profile**:Kylin提供了Query Profile功能,用于查看查询的执行计划、统计信息、扫描行数等重要指标,帮助用户优化查询性能。
- **Kylin Web UI**:Kylin提供了Web界面,展示了关键的集群运行指标、查询分析、Cube状态等信息,方便用户实时监控和调优。
#### 4.3 查询执行计划的分析与优化
查询执行计划是优化查询性能的重要依据,通过分析执行计划可以了解查询的执行流程、扫描数据量、Join操作等信息。针对查询执行计划中的瓶颈,可以有针对性地进行优化调整。以下是一个简单的示例代码,展示如何获取查询执行计划并进行分析优化:
```java
// 获取查询执行计划
String sql = "SELECT * FROM TABLE WHERE condition";
QueryContext queryContext = kylinConnection.query(sql);
QueryPlan queryPlan = queryContext.explain();
// 分析执行计划
System.out.println("Query Execution Plan:");
System.out.println(queryPlan.getPlanDetails());
// 优化建议
System.out.println("Optimization Suggestions:");
System.out.println("1. Create index on the columns involved in the WHERE condition.");
System.out.println("2. Partition the table to reduce data scan.");
```
**代码总结:**
- 通过Kylin API获取查询执行计划,并输出执行计划详情。
- 根据执行计划分析提出优化建议,例如创建索引、分区表等方式优化查询性能。
**结果说明:**
通过查询执行计划的分析,可以深入了解查询的执行情况,有针对性地进行优化策略制定,提升查询效率。
在Kylin查询性能监控与诊断方面,以上介绍的内容可以帮助用户更好地优化Kylin查询性能,提升数据处理效率。
# 5. Kylin在大数据环境下的优化策略
在大数据环境下,Kylin的性能优化策略至关重要。以下是Kylin在与各种大数据组件集成时的优化策略:
#### 5.1 与Hadoop、Hive集成的性能调优策略
- **数据划分与分布式计算**:合理划分数据,并利用Hadoop的分布式计算能力进行数据处理,减轻Kylin的查询压力。
- **数据压缩与存储格式**:使用高效的数据压缩算法和存储格式,如Parquet或ORC,以提高数据读取效率。
- **并行计算与任务调度**:通过调整Hadoop集群的并行计算能力和任务调度机制,优化Kylin Cube的构建和查询性能。
#### 5.2 与Spark、HBase集成的性能优化实践
- **Spark作为计算引擎**:将Spark作为计算引擎,配合Kylin进行数据处理和计算,可以提高查询的速度和性能。
- **HBase作为存储引擎**:利用HBase的强大存储能力,Kylin可以快速读取和查询海量数据,加速数据处理过程。
- **内存计算与缓存机制**:结合Spark的内存计算和HBase的缓存机制,可以在一定程度上减少IO操作,提升数据处理效率。
#### 5.3 Kylin与其他大数据组件的整合优化
- **与Kafka整合**:通过与Kafka的整合,Kylin可以实时处理数据流,实现实时OLAP分析,提高数据处理速度。
- **与Flink整合**:结合Flink的流处理能力,Kylin可以实现流式数据计算与分析,满足更加复杂的实时分析需求。
- **与Druid整合**:与Druid整合可以实现Kylin对即席查询和快速OLAP分析的支持,优化数据处理和查询效率。
综合以上整合优化策略,Kylin可以在大数据环境中发挥更大的性能优势,为用户提供更加高效可靠的数据处理与分析能力。
# 6. Kylin性能调优的未来趋势与展望
Kylin作为大数据查询引擎,在性能调优方面还有许多未来发展的趋势和展望。随着大数据技术的不断演进,Kylin的性能优化也将会朝着以下方向发展:
## 6.1 Kylin与大数据技术的发展趋势
随着大数据领域的快速发展,Kylin将更多地与其他大数据技术进行深度整合。未来Kylin有望与更多大数据存储引擎、计算框架进行结合,以提升数据处理和查询的性能。例如,与新一代的大数据存储引擎进行适配,如Hudi、Iceberg等,以及与计算框架的深度融合,如与Flink、Presto等进行配合,以提供更加高效的分布式查询能力。
## 6.2 基于AI的Kylin性能优化前景
随着人工智能技术的快速发展,未来Kylin有望利用机器学习和深度学习等人工智能技术来进行性能优化。通过对查询和数据访问模式进行智能分析和预测,从而优化Kylin的物理存储结构、查询执行计划和缓存策略,实现更加智能化的性能调优。
## 6.3 Kylin查询优化的新技术与新方法
未来,随着Kylin自身技术的不断创新,将会涌现出更多的查询优化新技术和新方法。例如,基于向量化指令集的优化、基于硬件加速的查询处理、多维度索引优化等方面的探索与实践,将为Kylin的查询性能带来质的飞跃。
综上所述,Kylin作为大数据查询引擎,未来在与大数据技术的深度整合、基于AI的性能优化以及新技术新方法的探索方面,有着广阔的发展前景。随着大数据领域的不断发展,Kylin的性能调优也将会迎来更多创新与突破。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《超大数据集查询工具Kylin:亚秒级查询在大数据分析中的应用》专栏全面介绍了Kylin在大数据分析中的重要作用。专栏内包含多篇文章,涵盖了使用Kylin进行数据预处理与清洗、数据聚合与汇总操作、实时数据处理、数据安全与权限控制、机器学习与预测分析、时间序列数据处理、自然语言处理(NLP)数据分析、数据可视化与报表生成技巧,以及其在分布式计算与并行处理中的应用。通过本专栏,读者将深入了解Kylin在大数据分析中的广泛应用,以及如何利用Kylin进行亚秒级查询,提高数据分析的效率和准确性。无论是处理超大数据集、实时数据处理、安全权限控制,还是结合机器学习、时间序列分析、自然语言处理,甚至在数据可视化与报表生成方面,Kylin都展现出强大的功能和应用前景。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
深入剖析Vector VT-System:安装到配置的详细操作指南
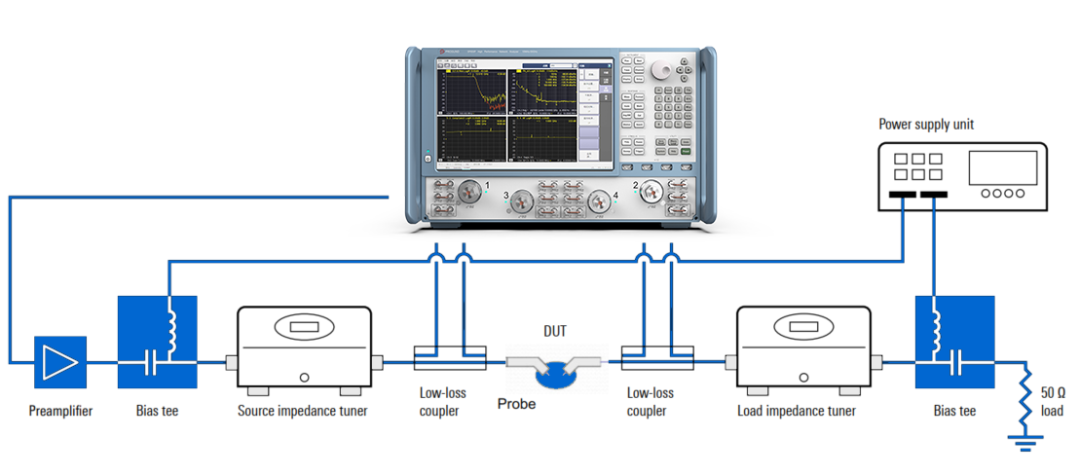
# 摘要
Vector VT-System作为一款功能全面的测试软件平台,广泛应用于嵌入式系统和实时测试领域。本文从VT-System的介绍开始,详细阐述了其安装过程中的系统要求、兼容性检查、安装步骤、环境配置以及安装验证和故障排除。继而深入探讨了VT-System的基本操作和配置,包括用户界面、项目创建与管理、网络设置与通信。进一步的,文章介
【声子晶体频率特性分析】:COMSOL结果的深度解读与应用
# 摘要
声子晶体作为一种具有周期性结构的新型材料,因其独特的频率特性在声学和振动控制领域具有重要应用。本文首先介绍了声子晶体的基本概念与特性,随后详细阐述了使用COMSOL Multiphysics软件进行声子晶体模型建立、网格划分及求解器设置的方法。通过理论分析和仿真实践,我们探讨了声子晶体的频率带隙和色散关系,以及缺陷态的产生和特性。文章最后展望了声子晶体在声学器件设计中的应用前景,提出了未来研究的新方向,强调了理论与实验结合的重要性。
# 关键字
声子晶体;频率特性;COMSOL Multiphysics;网格划分;带隙;缺陷态
参考资源链接:[Comsol计算2D声子晶体带隙详细
迁移学习突破高光谱图像分类:跨域少样本数据应用全攻略

# 摘要
迁移学习与高光谱图像分类领域的结合是当前遥感和计算机视觉研究的热点。本文系统地介绍了迁移学习的基本理论、技术及其在高光谱图像数据分类中的应用。首先,文章探讨了迁移学习和高光谱图像数据的特性,随后聚焦于迁移学习在实际高光谱图像分类任务中的实现和优化方法。案例研究部分详细分析了迁移学习模型在高光谱图像分类中的性能评估和比较。最后,文章展望
STM32 SPI_I2C通信:手册中的高级通信技巧大公开

# 摘要
本文全面探讨了STM32微控制器中SPI和I2C通信接口的基础知识、深入分析以及应用实践。文章首先介绍了SPI和I2C的协议基础,包括它们的工作原理、数据帧格式及时序分析。接着,详细解析了STM32平台上SPI和I2C的编程实践,覆盖初始化配置、数据传输、错误处理到性能优化。在此基础上,进一步探讨了高级通信特性,如DMA集成、多从机通信以及故障排除。文章最后通过综
运动追踪技术提升:ICM-42688-P数据融合应用实战
# 摘要
本文全面介绍了ICM-42688-P运动追踪传感器的功能和应用,重点探讨了数据融合的基础理论、技术分类及其在运动追踪中的实践。通过对ICM-42688-P的初始化、校准和预处理,阐述了数据融合算法如Kalman滤波器、Particle滤波器和互补滤波器的实现原理和优化策略。实战应用部分详细分析了姿态估计、动态追踪、运动分析及路径规划的案例,并对数据融合算法进行了性能评估。通过案例研究和实战部署,展示了运动追踪技术在体育和虚拟现实等领域的应用以及系统部署要点。最后,展望了未来发展趋势,包括深度学习与多传感器融合的研究进展、行业应用趋势、市场前景以及技术挑战和解决方案。
# 关键字
I
【紧急排查指南】:ORA-01480错误出现时的快速解决策略

# 摘要
ORA-01480错误是Oracle数据库中由于字符集不匹配导致的问题,它会影响数据库操作的正确执行。本文旨在探讨ORA-01480错误的成因、诊断策略以及解决和预防该错误的实践操作。首先,文章概述了ORA-01480错误及其对数据库的影响。接着,深入分析了字符集与绑定数据类型不匹配的机制,包括字符集转换原理及触发该错误的条件。然后,文章提供了详细的诊断和排查方法,如数据库诊断工具的使用
【VS2022代码效率提升秘籍】:掌握语法高亮与代码优化技巧
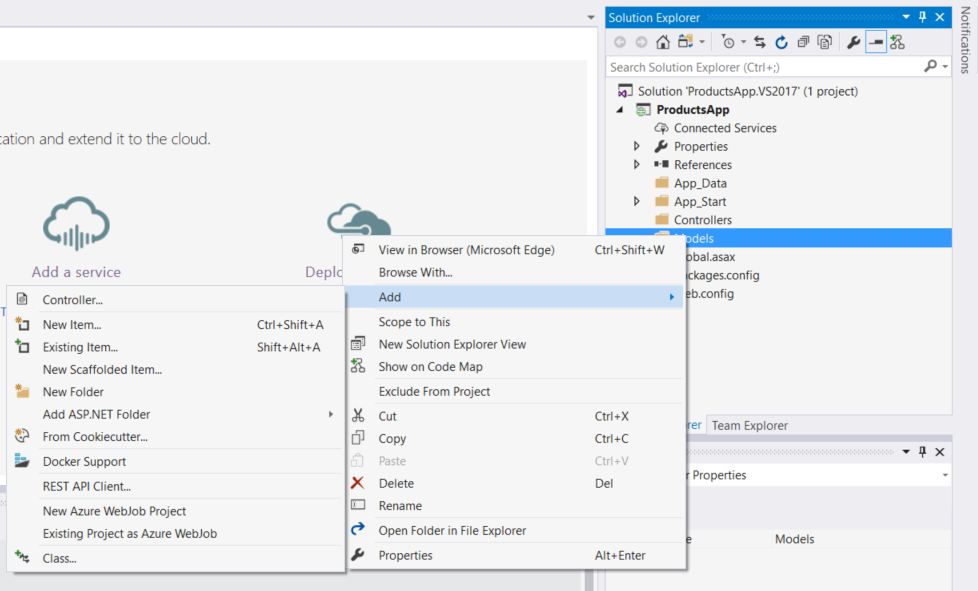
# 摘要
本文全面介绍了Visual Studio 2022(VS2022)的多个核心功能,包括其用户界面设置、语法高亮功能的深入理解及其自定义方法,代码优化工具与技术的探讨,扩展与插件系统的探索与开发,以及如何通过这些工具和策略提升代码效率和团队协作。文章强调
【Eclipse图表大师】:JFreeChart配置与优化的终极指南(包含10个技巧)

# 摘要
JFreeChart是一个广泛使用的Java图表库,适用于生成高质量的图表。本文首先介绍了JFreeChart的基础知识和核心组件,包括数据集、绘图器和渲染器,以及如何配置不同类型的图表。进一步探讨了高级配置技巧,包括数据集的高级处理和图表的动态更新及动画效
【Vivado功耗分析与优化指南】:降低FPGA能耗的专家策略
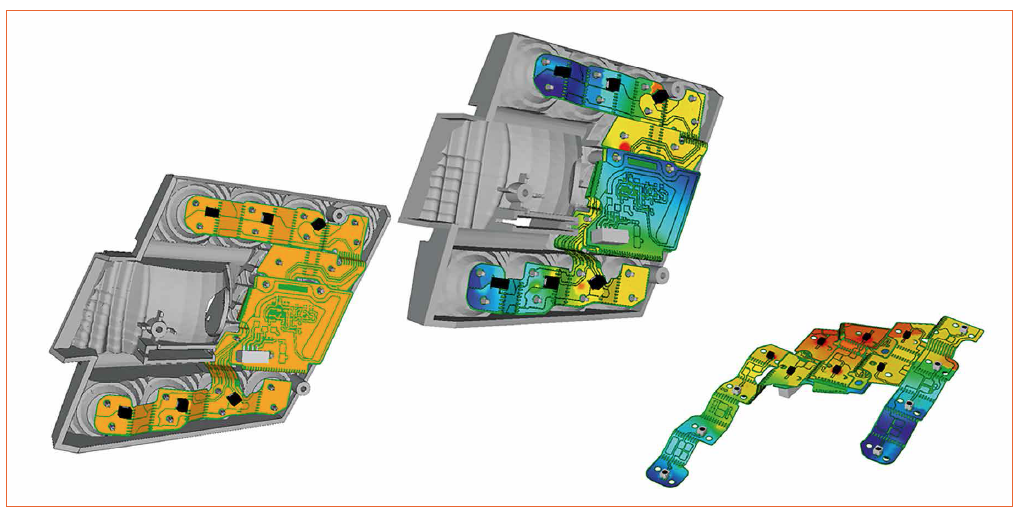
# 摘要
随着数字系统设计的复杂性日益增加,FPGA(现场可编程门阵列)因其灵活性和高性能在各种应用中越来越受欢迎。然而,功
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )