复杂指令集计算机体系结构设计
发布时间: 2024-01-31 10:08:06 阅读量: 45 订阅数: 45 
# 1. 引言
## 1.1 选题背景
在计算机科学领域,计算机体系结构是指计算机硬件和软件之间的接口,它定义了指令集架构和计算机组织结构的规范。复杂指令集计算机(CISC)体系结构作为一种传统的计算机架构,经过多年的发展和优化,在各个领域都有着广泛的应用。
## 1.2 目的和意义
本文旨在介绍复杂指令集计算机体系结构的设计原则和方法,并通过实际案例探讨其优缺点。对于计算机科学相关从业人员和研究者,了解和掌握复杂指令集计算机体系结构的设计原理具有重要的意义,可以帮助他们在实际工作中进行系统设计和性能优化。
## 1.3 文章结构
本文将按照以下结构进行论述。首先,在第二章中,将介绍复杂指令集计算机的概念、定义以及其关键特点和优缺点。然后,在第三章中,将详细阐述复杂指令集计算机体系结构设计的原则,包括性能要求、可扩展性和灵活性要求、可靠性和容错性要求、节能和功耗控制要求等。接下来,在第四章中,将介绍复杂指令集计算机体系结构设计的具体流程,包括需求分析和问题定义、功能规划和设计、数据通路和控制单元设计、存储器和寄存器设计、性能分析和优化以及硬件描述语言和仿真验证等。然后,在第五章中,将通过介绍一些典型的复杂指令集计算机体系结构案例,包括Intel x86体系结构、ARM体系结构、MIPS体系结构、PowerPC体系结构和SPARC体系结构,来加深对复杂指令集计算机体系结构的理解。最后,在第六章中,将总结复杂指令集计算机体系结构设计的发展趋势,并展望未来的研究方向。
通过以上结构的安排和论述,本文将全面介绍复杂指令集计算机体系结构的设计原则和方法,以及相关的案例分析,为读者深入理解和应用复杂指令集计算机体系结构提供指导和参考。
# 2. 复杂指令集计算机简介
### 2.1 计算机体系结构概述
计算机体系结构是指计算机硬件和系统软件之间的接口规范,包括处理器、内存、输入输出设备等组成部分的组织方式、指令集和数据结构等。体系结构的设计直接影响计算机的性能、可扩展性和可靠性等方面。
### 2.2 复杂指令集计算机的定义
复杂指令集计算机(CISC)是一种计算机体系结构,其指令集极其丰富,包含了大量的指令操作,这些指令可以执行复杂的操作,如乘法、除法、浮点运算等。CISC体系结构的设计初衷是为了提高编程的便利性,减少程序员的工作量,但同时也会增加硬件设计的复杂度。
### 2.3 关键特点和优缺点
复杂指令集计算机具有以下关键特点:
- 指令集丰富:提供了大量的指令操作,可以执行复杂的操作,如字符串处理、位操作、浮点运算等。
- 复杂的硬件设计:由于指令集复杂,需要设计复杂的硬件电路来支持这些指令操作。
- 内存访问模式复杂:CISC体系结构中的指令可以直接访问内存中的数据,从而减少了对寄存器的需求,但同时也增加了内存访问的复杂性。
- 编程便利性高:由于指令集丰富,编写程序时可以使用更多的高级指令,提高了编程的便利性。
复杂指令集计算机的优点包括:
- 编程便利性高:由于指令集丰富,编写程序时可以使用更多的高级指令,减少了程序员的工作量。
- 性能较高:由于指令集丰富,可以执行更复杂的操作,提高了处理器的性能。
然而,复杂指令集计算机也存在以下缺点:
- 硬件设计复杂:由于指令集复杂,需要设计更复杂的硬件电路来支持这些指令操作,增加了硬件设计的困难和成本。
- 指令执行延迟较高:由于指令集复杂,执行一条指令所需的时间较长,并且存在较多的乘除法指令,增加了指令执行的延迟。
- 芯片面积较大:由于指令集复杂,需要较大的芯片面积来容纳更多的指令。
- 能耗较高:由于指令集复杂,实际功耗较高,不利于电池续航和节能。
综上所述,复杂指令集计算机在编程便利性和性能方面具有优势,但在硬件设计复杂、指令执行延迟、芯片面积和能耗方面存在一些不足。在实际应用中,需要根据具体需求权衡利弊,选择适合的计算机体系结构。
# 3. 复杂指令集计算机体系结

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏《微处理器与嵌入式系统设计》涵盖了计算机系统的基本结构与组成、微处理器体系结构的发展与演进、指令执行流程及执行单元等多个重要主题。在专栏内部的多篇文章中,我们将深入探讨计算机系统内部组成及功能、复杂指令集计算机体系结构设计、指令流水线设计的原理与实践等技术优化领域。此外,我们还将探讨微处理器体系结构的技术优化、总线操作与仲裁技术的优化与改进等内容,为读者呈现计算机系统的分类与性能评估、指令结构的设计与优化等核心知识。通过本专栏的学习,读者将能够全面了解嵌入式系统设计的相关知识,并掌握现代微处理器体系结构设计的关键技术及发展动态。
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
SAE J1772充电模式详解:性能、限制与技术革新路径探究
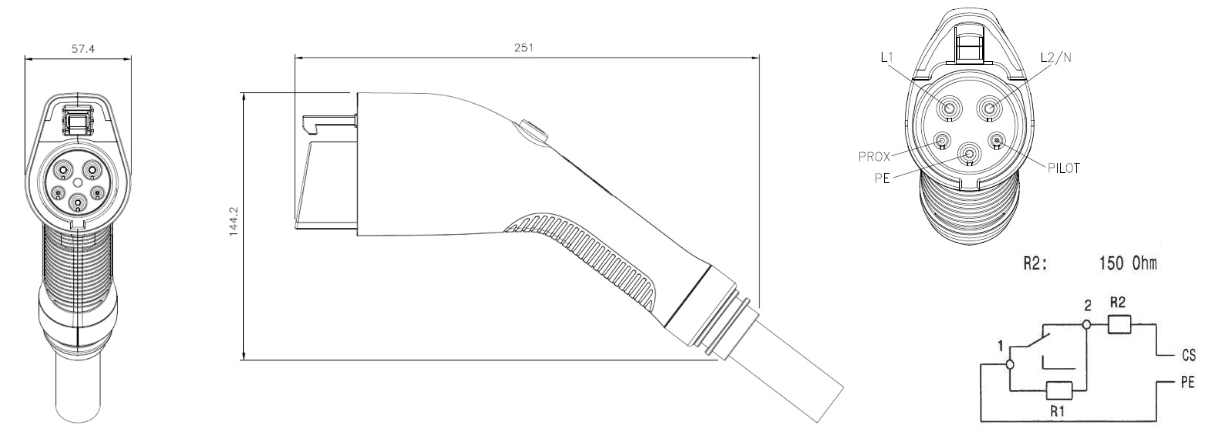
参考资源链接:[SAE J1772-2017.pdf](https://wenku.csdn.net/doc/6412b74abe7fbd1778d49c4f?spm=1055.2635.3001.10343)
# 1. SAE J1772充电模式概述
## 1.1 SAE J1772充电模式简介
SAE J1772标准定义了电动汽车(EV)和充
库转换项目管理:高效处理.a转.lib批量任务的方法

参考资源链接:[mingw 生成.a 转为.lib](https://wenku.csdn.net/doc/6412b739be7fbd1778d4987e?spm=1055.2635.3001.10343)
# 1. 库转换项目管理的基本概念与重要性
在IT领域中,库转换项目管理是一个关键的活动,它涉及软件库的版本控制、兼容性管理、
WINCC依赖性危机:彻底解决安装时遇到的所有依赖问题

参考资源链接:[Windows XP下安装WINCC V6.0/V6.2错误解决方案](https://wenku.csdn.net/doc/6412b6dcbe7fbd1778d483df?spm=1055.2635.3001.10343)
# 1. WINCC依赖性问题概述
## 依赖性问题定义
在工业自动化领域,依赖性问题指的是在安装、运行WINCC(Windows Control Ce
Strmix Simplis安装配置:最佳实践指南,避免仿真软件的坑

参考资源链接:[Simetrix/Simplis仿真教程:从基础到进阶](https://wenku.csdn.net/doc/t5vdt9168s?spm=1055.2635.3001.10343)
# 1. Strmix Simplis软件介绍与安装前准备
Strmix Sim
【系统集成挑战】:RTC6激光控制卡在复杂系统中的应用案例与策略

参考资源链接:[SCANLAB激光控制卡-RTC6.说明书](https://wenku.csdn.net/doc/71sp4mutsg?spm=1055.2635.3001.10343)
# 1. RTC6激光控制卡概述
RTC6激光控制卡是业界领先的高精度激光控制系统,专门设计用于满足
【人机交互的发展】:FANUC 0i-MF界面设计与用户体验改进的4大趋势
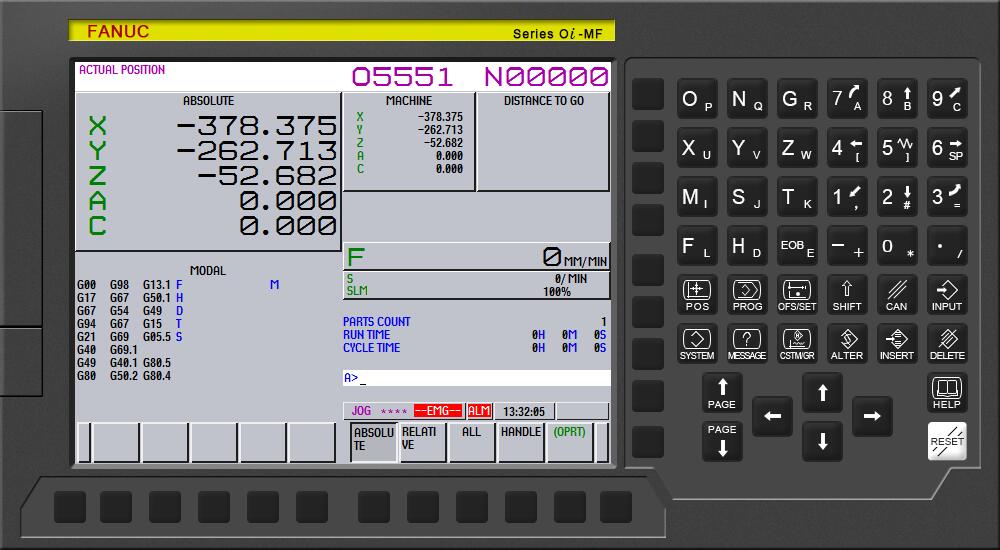
参考资源链接:[FANUC 0i-MF 加工中心系统操作与安全指南](https://wenku.csdn.net/doc/6401ac08cce7214c316ea60a?spm=1055.2635.3001.10343)
# 1. 人机交互的基础知识与发展
## 1.1 人机交互的定义与重要性
人机交互(Human-Computer Interaction, HCI)是研究人与计算机
【Maxwell仿真与实验对比】:验证铁耗与涡流损耗计算的准确性和可靠性
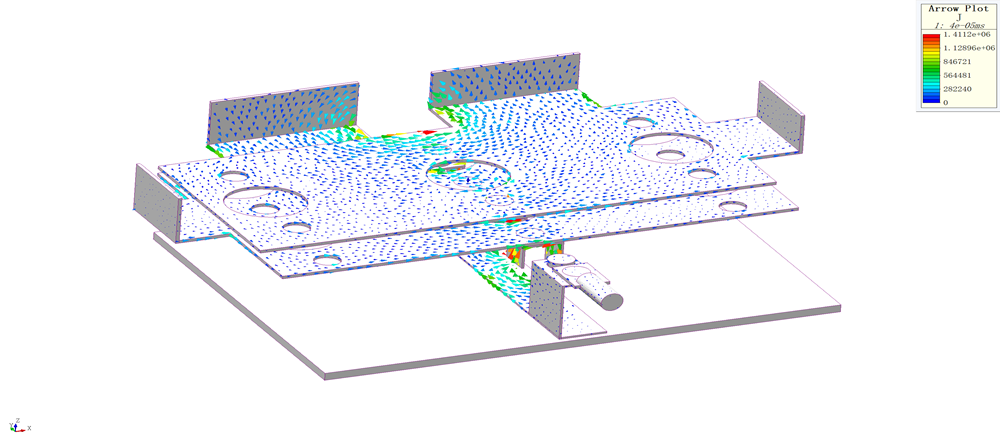
参考资源链接:[Maxwell中的铁耗分析与B-P曲线设置详解](https://wenku.csdn.net/doc/69syjty4c3?spm=1055.2635.3001.10343)
# 1. Maxwell仿真软件概述
在本章中,我们将介绍Maxwell仿真软件的基础知识,它是一款由Ansys公司开发的领先电磁场仿真工具,广泛
【VCS数据保护策略】:备份与恢复技巧,确保数据万无一失

参考资源链接:[VCS用户手册:2020.03-SP2版](https://wenku.csdn.net/doc/hf87hg2b2r?spm=1055.2635.3001.10343)
# 1. VCS数据保护策略概述
在信息技术飞速发展的今天,数据保护已经成为企业运营中不可或缺的一环。尤其是对于依赖于关键数据的业务系统来说,VCS(Virtual Cluste
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )