在大数据中实施验证规则:处理海量数据的规则格式201404方法
发布时间: 2024-12-15 06:45:52 阅读量: 1 订阅数: 3 

预支工资申请书.doc
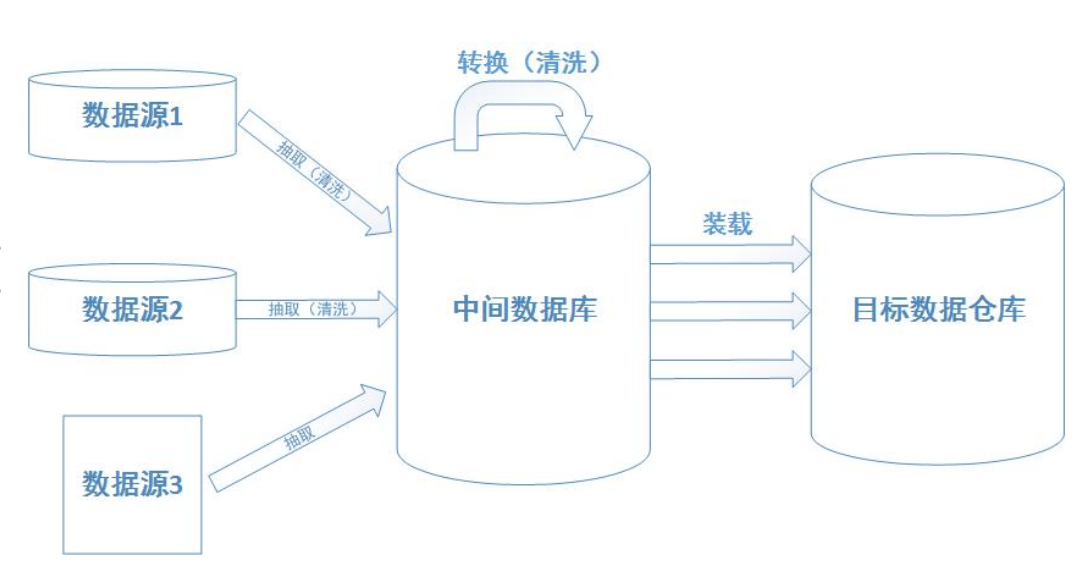
参考资源链接:[2014年Mentor Graphics Calibre SVRF标准验证规则手册](https://wenku.csdn.net/doc/70kc3iyyux?spm=1055.2635.3001.10343)
# 1. 大数据验证规则的重要性与背景
在当今的数据驱动世界中,数据验证规则成为了保障数据质量和价值的关键。随着数据量的急剧增长,数据的准确性、完整性和一致性变得越来越难以维护。企业和组织为了确保数据可以为决策提供有效的支持,必须依赖一套完善的验证规则。验证规则不仅帮助减少数据冗余和错误,还提高了数据处理效率和准确性。大数据技术的发展为验证规则的实施提供了新的可能性,同时也带来了挑战。本章将探讨验证规则的重要性以及它背后的技术和业务背景,为理解后续章节提供基础。
# 2. 数据验证规则的基本理论
数据验证规则是确保数据质量和数据可用性的基石,无论是在小规模还是大规模数据集的处理中都扮演着重要角色。本章将探讨数据验证的必要性,介绍不同类型的验证规则,并详细阐述验证规则的构建过程。
### 2.1 数据验证的必要性
数据验证的核心目的在于确保数据的准确性和完整性,它是提高数据质量的关键步骤。在企业决策中,高质量的数据能够带来更精确的洞察,有助于企业制定更为明智的商业策略。
#### 2.1.1 数据准确性与完整性的影响
准确性是指数据值的正确性,即数据记录与其在现实世界中的实际值是否一致。不准确的数据会造成错误的信息,影响决策的可靠性。例如,错误的客户信息可能导致错误的营销活动,不仅浪费资源,还可能损害品牌形象。
完整性则是指数据集是否包含了所有必要的信息。数据记录的缺失会限制信息的使用价值,导致分析结果的不完整或偏差。在实施客户关系管理(CRM)系统时,不完整的客户数据将难以对客户行为进行深入分析,影响产品的市场定位。
#### 2.1.2 数据质量对业务决策的影响
数据质量直接影响业务决策的质量。高质量的数据能够提供清晰的洞察,帮助企业及时发现问题,制定合适的策略。而数据质量不佳则会导致错误的分析结果,影响企业的市场竞争力。
### 2.2 数据验证规则的类型
数据验证规则可以从多个维度进行分类,主要分为以下几种类型:
#### 2.2.1 一致性规则
一致性规则确保数据在整个数据集中是统一的。例如,多个系统中关于同一客户的地址信息应该是一致的。违反一致性规则的常见情况是数据的不一致性,比如客户在不同的表中有着不同的性别、出生日期或其他标识信息。
```sql
-- 例如,使用SQL查询来检测不一致的数据:
SELECT customer_id, address_line1, address_line2, city, state
FROM customers
GROUP BY customer_id
HAVING COUNT(DISTINCT city) > 1;
```
上述查询将找出那些在城市信息上存在不一致的客户记录,这有助于进一步调查和修正数据。
#### 2.2.2 完整性规则
完整性规则确保数据集包含所有必需的信息,没有缺失的部分。完整性规则可以通过设置必填字段、检查字段长度等方式实现。完整性验证往往依赖于数据模型和业务逻辑。
#### 2.2.3 业务逻辑规则
业务逻辑规则与企业的特定业务需求相关。这些规则通常要复杂得多,它们可能包括计算特定数据字段的值是否在某个范围内,或者两个字段的值是否满足特定的逻辑关系。
### 2.3 数据验证规则的构建过程
构建数据验证规则是一个系统化的过程,需要遵循一定的原则,并进行充分的测试和部署。
#### 2.3.1 规则设计原则
构建数据验证规则时,应遵循以下设计原则:
- **最小必要性**:仅验证与业务需求直接相关的数据。
- **可理解性**:规则要简单明了,确保业务人员和开发人员都能够理解。
- **可执行性**:规则应该是可实现的,避免使用无法验证的模糊标准。
#### 2.3.2 规则的测试和部署
在规则设计完成之后,需要进行测试以确保其正确性。测试工作通常包括单元测试和集成测试。单元测试是对单个规则进行测试,而集成测试则是将规则集成到整个数据处理流程中去测试。
```python
# 示例:使用Python进行单元测试
def validate_phone_number(phone_number):
if len(phone_number) == 10 and phone_number.isdigit():
return True
return False
# 单元测试
import unittest
class TestPhoneNumberValidation(unittest.TestCase):
def test_valid_phone_number(self):
self.assertTrue(validate_phone_number("1234567890"))
def test_invalid_phone_number(self):
self.assertFalse(validate_phone_number("123456789"))
# 运行测试
if __name__ == '__main__':
unittest.main()
```
部署规则时,需要确保验证过程是透明的,并提供足够的日志记录以便于问题追踪。部署完成后,持续监控规则的执行效果,并根据反馈进行调整优化。
通过深入理解数据验证规则的必要性,掌握不同类型规则的构建和测试方法,我们可以建立一套高效且可靠的数据验证系统。这为后续章节中处理海量数据和实现验证规则的实践案例打下了坚实的基础。
# 3. 海量数据的处理技术
## 3.1 大数据处理基础
### 3.1.1 分布式处理架构概述
在大数据时代,传统的单机处理数据的方式已无法满足需求。数据量的爆炸式增长要求我们必须采用新的数据处理方式。分布式处理架构应运而生,它能够将任务分散到多个计算节点上并行处理,极大提升了数据处理的效率和速度。
分布式处理架构通常包含以下几个关键组件:
- **数据节点(Data Nodes)**:负责实际的数据存储和处理任务。
- **管理节点(Master Nodes)**:协调数据节点间的任务分配与数据同步。
- **网络**:连接各个节点,保证数据和任务的快速传输。
- **存储系统**:包括文件系统、数据库等,用于数据的长期存储。
分布式系统的核心设计原则之一是容错性,这意味着即使部分节点发生故障,系统依然能够继续运行,保证数据处理的连续性和完整性。例如,Hadoop生态系统中的HDFS(Hadoop Distributed File System)就是一个高度容错的分布式文件系统,非常适合处理大规模数据集。
### 3.1.2 数据存储解决方案
对于海量数据的存储,不能简单依赖传统关系型数据库。因此,NoSQL数据库应运而生,它们以非关系型、分布式的特性满足了大规模数据存储的需求。
以下是一些主流的数据存储解决方案:
#### NoSQL数据库
- **键值存储(Key-Value Stores)**:如Redis、DynamoDB。适用于需要快速读写操作的场景,数据以键值对的形式存储。
- **文档存储(Document Stores)**:如MongoDB。允许存储文档型数据,支持复杂的查询操作。
- **列式存储(Column Stores)**:如Cassandra、HBase。适合读写大规模数据集,能够高效处理大量列的数据分析。
- **图数据库(Graph Stores)**:如Neo4j。专注于处理实体间复杂关系的数据存储。
#### 分布式文件系统
- **HDFS**:作为Hadoop生态的一部分,HDFS适合存储大量数据文件。
- **Amazon S3**:适合云环境中存储和检索任意大小对象的分布式存储服务。
#### 数据仓库
- **Googl

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
SIMCA 14.1进阶秘籍:打造复杂3D火山图的5大技巧

参考资源链接:[SIMCA 14.1教程:3D火山图制作与解析](https://wenku.csdn.net/doc/6401ad16cce7214c31
Silvaco TCAD 与 Spice 对比分析

参考资源链接:[Silvaco TCAD器件仿真教程:材料与物理模型设定](https://wenku.csdn.net/doc/6moyf21a6v?spm=1055.2635.3001.10343)
# 1. TCAD与Spice简介
## 1.1 TCAD与Spice的基本概念
TCAD(Technology Computer-Aided Design)与Spice是半导
数据同步与恢复:光纤环网机制详解及最佳实践

参考资源链接:[光纤环网技术详解:组网方式与帧处理机制](https://wenku.csdn.net/doc/1q4ubo5bp2?spm=1055.2635.3001.10343)
# 1. 数据同步与恢复概述
在现代IT架构中,数据同步与恢复是确保业务连续性和数据安全的关键组成部分。本章将概述数据同步与恢复的基本概念,并探讨其在企业环境中的重要性。
【技术写作秘籍】:四级词汇在技术文档中的巧妙运用

参考资源链接:[四级核心词汇详解:高频词与相关术语](https://wenku.csdn.net/doc/5gxen3nh5w?spm=1055.2635.3001.10343)
# 1. 技术写作与四级词汇的重要性
在技术领域,准确而清晰的沟通是至关重要的。技术写作不仅需要传达具体信息,而且需要确保不同背景的读者都能理解。四级词汇,指的是大学英语四级考试中的核心词汇,它们在技术写作中扮演着不可或缺的角色。这些词汇因为其普遍性和准确
西门子FB284成本效益评估:如何进行ROI与TCO分析以优化项目预算
参考资源链接:[西门子FB284功能块在TIA Portal中的V90定位控制](https://wenku.csdn.net/doc/6401acffcce7214c316ede81?spm=1055.2635.3001.10343)
# 1. 理解西门子FB284在项目中的角色
在现代工业自动化项目中,西门子FB284作为一个功能块,扮演着至关重要的角色。FB284是西门子SI
【BELLHOP全面解读】:从基础操作到高级特性的全方位指南

参考资源链接:[BELLHOP中文使用指南及MATLAB操作详解](https://wenku.csdn.net/doc/6412b546be7fbd1778d42928?spm=1055.2635.3001.10343)
# 1. BELLHOP基础介绍与安装
## BELLHOP是什么
BELLHOP是一个先进的IT任务自动化和管理系统,旨在优化日常运维任务的效率。
快速识别库卡机器人故障:维修手册与预防策略大揭秘

参考资源链接:[库卡机器人kuka故障信息与故障处理.pdf](https://wenku.csdn.net/doc/64619a8c543f844488937510?spm=1055.2635.3001.10343)
# 1. 库卡机器人故障快速识别概述
## 1.1 故障识别的重要性
在自动化领域中,库卡机器人故障的快速识别对于确保生产线的稳定运行至关重要。通过及时的故障识别,可以最小化生产停滞时间,减少经济损失,并增强整个
【RTD2556深度剖析】:解锁顶尖技术手册的12个秘诀

参考资源链接:[RTD2556-CG多功能显示器控制器数据手册:集成接口与应用解析](https://wenku.csdn.net/doc/6412b6eebe7fbd1778d487eb?spm=1055.2635.3001.10343)
# 1. RTD2556技术概述
## 1.1 RTD2556简介
RTD2556是一颗高度集成的系统级芯片(SoC),专为视频处理
【Dalsa相机固件升级全攻略】:避免失败的5个关键步骤

参考资源链接:[Dalsa相机全面使用指南:硬件配置与软件开发](https://wenku.csdn.net/doc/57bgbkrhzu?spm=1055.2635.3001.10343)
# 1. Dalsa相机固件升级概览
在本章中,我们将对Dalsa相机固件升级做一个全面的了解,为后续章节深入探讨升级前的准备、过程、验证以及高级应用打下基础。固件升
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )