




【LabVIEW数据处理教程】:FIFO结构与流式处理的实践指南


LabVIEW条码对比处理系统的初学者指南:涵盖数据对比、处理、存储与报表生成功能
摘要
本文全面介绍了LabVIEW环境下数据处理的基础与高级应用,包括FIFO结构理论基础、流式处理技术、实时数据分析、多通道数据同步处理以及与外部设备的数据交互。通过细致的理论讲解和丰富的应用案例分析,本文展示了如何在LabVIEW中有效创建和管理数据结构,优化性能,以及构建实时决策系统。文章还讨论了LabVIEW在新兴技术中的融合趋势,如人工智能与物联网,并强调了开发者社区和技术文档在持续学习和技术支持中的作用。
关键字
LabVIEW;数据处理;FIFO;流式处理;实时分析;多通道同步;数据交互;人工智能;物联网;开发者社区
参考资源链接:LabVIEW循环与结构详解:从For循环到移位寄存器的应用
1. LabVIEW数据处理入门
1.1 LabVIEW简介
LabVIEW(Laboratory Virtual Instrument Engineering Workbench)是由National Instruments(NI)公司开发的一种图形化编程语言,用于数据采集、仪器控制以及工业自动化等领域。LabVIEW以其直观的图形化编程环境、丰富的硬件接口支持和强大的数据处理能力,成为工程师和科研人员广泛使用的工具。
1.2 LabVIEW环境基础
初次接触LabVIEW,用户会发现它与传统的文本编程语言截然不同,它采用的是图形化编程范式,即“G”语言(Graphical Programming Language),通过编辑器中的图形化块(称为Virtual Instruments,VI)来编写程序。LabVIEW程序由三部分组成:前面板(Front Panel)、块图(Block Diagram)和图标/连接器(Icon and Connector)。
1.3 数据处理的基本概念
数据处理在LabVIEW中是核心内容之一,包括数据的采集、分析、显示和存储等环节。理解数据类型、数据结构和数据流是进行有效数据处理的前提。LabVIEW提供了丰富的数据类型和内置的函数,支持数组、簇、图表、波形等数据处理方式,用户可以通过图形化的编程方式轻松实现数据的导入导出、转换、计算等复杂处理。
2. FIFO结构的理论基础与实现
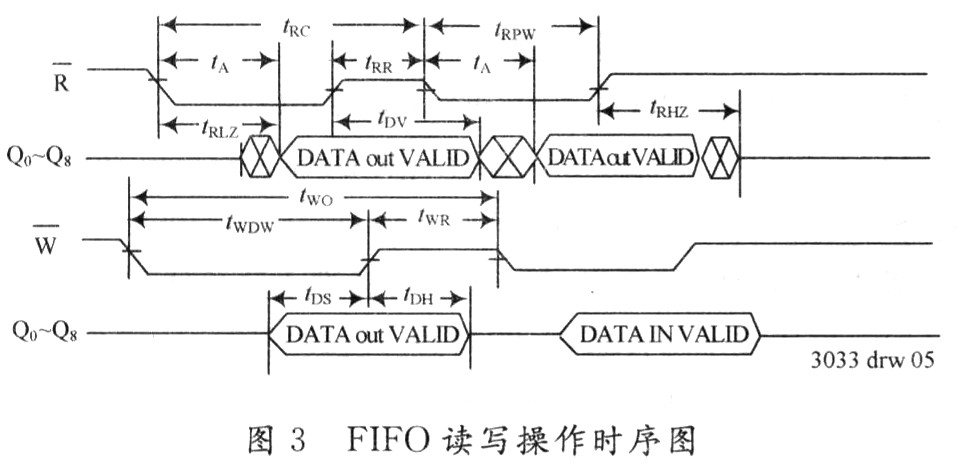
FIFO(First-In, First-Out)是一种广泛使用的数据存储和检索方法,尤其在实时数据处理、通信系统以及嵌入式系统中扮演着重要角色。FIFO能够保证数据的顺序处理,适合于数据流的管理和控制。
2.1 FIFO概念与数据流原理
2.1.1 FIFO的基本概念
FIFO是一种先进先出的数据结构,它允许数据以一种有序的方式进入并离开队列。就像在超市排队购物一样,站在队伍最前面的人会被优先服务。在FIFO中,最先被添加到队列的数据将是最先被取出的,这确保了数据按照它们到达的顺序被处理。
2.1.2 数据流的控制机制
数据流控制机制是确保数据按照预定方式传输的关键。这涉及到缓冲、同步和调度机制。缓冲是指在队列中临时存储数据的能力;同步是指在数据处理过程中维持不同部分之间的时间一致性;调度则涉及到决定哪些数据先被处理。
2.2 LabVIEW中的FIFO实现
2.2.1 FIFO数据结构的创建与管理
在LabVIEW中,FIFO可以通过队列结构来实现。创建和管理FIFO涉及以下几个关键步骤:
- 创建FIFO:使用LabVIEW中的队列函数来创建队列。
- 添加数据:将数据放入队列,通过特定的队列函数来实现。
- 读取数据:从队列中按顺序取出数据。
- 删除FIFO:在不再需要时删除队列,释放资源。
2.2.2 FIFO在LabVIEW中的应用案例
案例分析中,我们将通过一个简单的数据缓冲场景来展示FIFO的应用。在这个案例中,我们将设置一个生产者-消费者模型,生产者生成数据并将其放入队列,消费者从队列中取出数据进行处理。
代码示例
- // FIFO创建与使用示例
- VI Snippet - Queue.vi
- // 创建队列
- enqueueIndex = Queue Create
- enqueueRef = enqueueIndex[0]
- // 生产者向队列添加数据
- For i = 0 to N-1 do
- data = generateData()
- enqueueStatus = Queue Enqueue(enqueueRef, data)
- If enqueueStatus is True Then
- // 数据成功入队
- Else
- // 队列已满,处理异常
- EndIf
- EndFor
- // 消费者从队列中读取数据
- For i = 0 to N-1 do
- dequeueStatus, data = Queue Dequeue(enqueueRef)
- If dequeueStatus is True Then
- // 数据成功出队,进行处理
- Else
- // 队列为空,处理异常
- EndIf
- EndFor
- // 删除队列
- Queue Destroy(enqueueRef)
参数说明
enqueueIndex:队列创建的索引。enqueueRef:队列的引用,用于后续操作。data:需要处理的数据。enqueueStatus:数据入队的状态。dequeueStatus:数据出队的状态。
逻辑分析
在上述示例中,我们使用队列创建函数来初始化一个FIFO队列。生产者通过循环生成数据并使用Queue Enqueue函数将数据添加到队列中。消费者则通过Queue Dequeue函数从队列中移除数据进行处理。队列的引用enqueueRef用于标识特定的队列对象,确保生产者和消费者操作的是同一个队列。最后,使用Queue Destroy函数销毁队列以释放资源。
2.3 FIFO性能分析与优化
2.3.1 FIFO性能评估标准
FIFO性能评估标准通常包括以下几点:
- 吞吐量:单位时间内FIFO能够处理的数据量。
- 延迟:数据从进入队列到被取出的平均时间。
- 队列长度:队列中数据项的最大数量。
- 处理时间:数据在队列中停留的平均时间。
2.3.2 FIFO性能优化技巧
性能优化的关键在于平衡队列的长度和处理速度。优化技巧包括:
- 使用高效的数据结构来降低开销。
- 避免资源竞争,确保生产者和消费者之间同步。
- 根据实际需求调整队列的最大长度。
- 利用多线程或并行处理来提高吞吐量。
代码块示例
- // FIFO性能优化示例
- VI Snippet - QueueOptimized.vi
- // 优化队列操作
- // 1. 使用快速队列数据结构
- // 2. 确保线程安全的操作
- // 3. 并行处理提高吞吐量
- // 详细说明略
逻辑分析
在这个示例中,我们通过使用LabVIEW中的快速队列数据结构来优化队列操作。这可以减少队列操作的延迟,并提高数据处理的速度。同时,我们通过确保线程安全的方式来避免数据竞争和错误。通过并行处理,我们可以进一步提高队列的吞吐量。
通过这些优化技巧,我们可以显著提高FIFO的性能,使其更加适合于需要高速数据处理和数据流控制的应用场景。
3. 流式处理的理论与技巧
流式处理(stream processing)是一种数据处理方式,它强调在数据到达时即刻进行处理,而不是等到所有数据都收集完毕再进行批量处理。这种方法特别适用于大规模数据流的实时分析,以及需要快速响应的应用场景。
3.1 流式处理的基本概念
3.1.1 流式处理的定义与特点
流式处理的核心在于连续不断地接收和处理数据流。数据流可以是传感器数据、网络日志、金融交易信息等实时生成的数据。与传统的批处理不同,流处理对数据的处理是按需的,通常在数据生成的同时进行。
流式处理的特点包括:
- 低延迟:流式处理能够在数据生成后立即进行处理,降低了数据处理的整体延迟。
- 高吞吐量:由于数据是连续处理的,系统能够支持高频率的数据流。
- 可扩展性:流式系统设计上应支持横向扩展,能够增加节点以应对不断增长的数据流。
- 容错性:流式处理系统通常设计有错误恢复机制,以确保连续的

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
快速搭建内网Kubernetes集群:揭秘离线环境下的部署秘籍
【数据传输保卫战】:LoRa网络安全性深度探讨
【故障诊断与解决】:萤石CS-W1-FE300F(EM)问题快速定位与解决方案(故障处理必备)
【案例研究】:TDD-LTE信令流程与小区重选的实战解读
【Copula模型深度剖析】:理论与MATLAB实践相结合
DVE实用操作教程:步骤详解与最佳实践:精通DVE操作的秘诀
【Chrome安全机制深度解析】:加密与隐私保护的关键更新
SolidWorks钣金设计:【高级技巧】与应用案例分析
【信号完整性】:STC8串口通信硬件调试必修课与案例分析


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )





















