Easyswoole中如何实现简单的HTTP服务
发布时间: 2024-01-02 17:24:54 阅读量: 54 订阅数: 42 
# 第一章
## 1.1 什么是Easyswoole?
Easyswoole是一个基于Swoole扩展的高性能PHP开发框架,它提供了快速构建高性能HTTP服务的能力。通过利用Swoole的协程和异步IO特性,Easyswoole可以实现高并发处理和低延迟的请求响应。
## 1.2 Easyswoole的特点
- 高性能:基于Swoole扩展的异步IO和协程技术,使得Easyswoole具有出色的性能表现,可以处理大量的并发请求。
- 简单易用:Easyswoole提供了简洁、直观的API和丰富的开发工具,使得开发者能够快速上手并构建稳定可靠的HTTP服务。
- 扩展性:Easyswoole支持灵活的组件扩展机制,开发者可以根据实际需求选择并集成各种功能组件,从而实现更加丰富的应用场景。
- 高度可定制:Easyswoole拥有强大的配置系统,开发者可以根据实际需求进行灵活的配置和定制,满足不同场景的需求。
## 1.3 为什么选择Easyswoole来实现HTTP服务?
- 高性能:Easyswoole基于Swoole扩展,充分利用了Swoole的异步IO和协程特性,能够实现高并发和低延迟的请求响应,适用于高负载的场景。
- 简单易用:Easyswoole提供了友好的API和开发工具,使得开发者能够快速上手,迅速构建出稳定可靠的HTTP服务。
- 扩展性:Easyswoole支持丰富的组件和扩展机制,开发者可以根据实际需求选择并集成各种功能组件,满足各种业务场景的需求。
- 生态完善:Easyswoole拥有活跃的社区和完善的文档,开发者可以得到及时的技术支持和帮助,并且可以通过社区贡献和分享获取更多的扩展和工具。
通过以上特点和优势,选择Easyswoole来实现HTTP服务可以帮助开发者快速搭建高性能、稳定可靠的服务,提升用户体验和系统可靠性。
## 第二章
### 2.1 Easyswoole的安装和环境要求
在本节中,我们将介绍如何安装Easyswoole以及所需的环境要求。
#### 2.1.1 环境要求
在安装Easyswoole之前,首先需要确保满足以下环境要求:
- 一台运行Linux或MacOS的服务器或开发机。
- PHP版本 7.1 及以上。
- Swoole扩展版本 4.4.0 及以上。
- Composer 工具。
#### 2.1.2 安装Easyswoole
安装Easyswoole很简单,只需要执行以下步骤:
1. 打开终端,进入到项目的根目录。
2. 使用Composer安装Easyswoole依赖:
```bash
composer require easyswoole/easyswoole
```
3. 在项目根目录下执行以下命令创建配置文件和其他必要文件:
```bash
php vendor/bin/easyswoole install
```
4. 安装完成后,可以通过以下命令启动Easyswoole服务:
```bash
php easyswoole start
```
### 2.2 创建一个基本的Easyswoole项目
在本节中,我们将学习如何创建一个基本的Easyswoole项目。
#### 2.2.1 创建项目目录
首先,我们需要创建一个新的目录来存放我们的Easyswoole项目。可以在任意位置创建该目录。
在终端中执行以下命令来创建项目目录:
```bash
mkdir my_easyswoole_project
cd my_easyswoole_project
```
#### 2.2.2 初始化项目
接下来,我们需要使用Easyswoole的命令行工具来初始化项目。
在终端中执行以下命令来初始化项目:
```bash
php easyswoole install
```
这将会在项目目录下生成一些必要的文件和目录,包括配置文件、控制器和路由等。
#### 2.2.3 启动Easyswoole服务
一旦项目初始化完成,我们可以使用以下命令来启动Easyswoole服务:
```bash
php easyswoole start
```
现在,您已经成功创建了一个基本的Easyswoole项目,并启动了Easyswoole服务。
在下一节中,我们将学习如何配置HTTP服务的基本参数。
### 3. 第三章
HTTP请求处理器是实现HTTP服务的核心组件之一。在这一章节中,我们将详细介绍如何在Easyswoole中实现一个简单的HTTP请求处理器,并处理GET和POST请求,最后实现对HTTP请求的响应。让我们开始吧!
#### 3.1 实现一个简单的HTTP请求处理器
在Easyswoole中,可以通过实现`HttpController`类或者直接通过函数来处理HTTP请求。下面是一个简单的HTTP请求处理器的示例:
```python
from easyswoole.server import Server
from easyswoole.http import Request, Response
server = Server()
# 创建一个路由,当访问根路径时执行handleRequest函数
@server.route('/')
def handleRequest(request: Request, response: Response):
response.write('Hello, Easyswoole!')
# 启动HTTP服务
if __name__ == '__main__':
server.start()
```
在上面的示例中,我们创建了一个简单的HTTP服务器,并在根路径下处理了HTTP请求,返回了一个简单的"Hello, Easyswoole!"响应。
#### 3.2 处理GET和POST请求
除了处理根路径的请求,HTTP请求处理器还需要能够处理GET和POST等不同类型的请求。下面是一个处理GET和POST请求的示例:
```python
from easyswoole.server import Server
from easyswoole.http import Request, Response
server = Server()
# 处理GET请求
@server.get('/get')
def handleGet(request: Request, response: Response):
response.write('This is a GET request')
# 处理POST请求
@server.post('/post')
def handlePost(request: Request, response: Response):
response.write('This is a POST request')
# 启动HTTP服务
if __name__ == '__main__':
server.start()
```
上面的示例中,我们使用了`@server.get`和`@server.post`装饰器来分别处理GET和POST请求。
#### 3.3 响应HTTP请求
最后,我们需要能够对HTTP请求进行响应。Easyswoole提供了丰富的`Response`类方法来实现对HTTP请求的响应,比如`write`、`sendFile`等。下面是一个简单的响应示例:
```python
from easyswoole.server import Server
from easyswoole.http import Request, Response
server = Server()
@server.route('/')
def handleRequest(request: Request, response: Response):
response.write('Hello, Easyswoole!')
# 设置响应头
response.withHeader('Content-Type', 'text/html')
# 设置状态码
response.withStatus(200)
if __name__ == '__main__':
server.start()
```
在上面的示例中,我们使用`response.write`方法来写入响应内容,并使用`response.withHeader`和`response.withStatus`方法设置了响应头和状态码。
通过上面的示例,我们详细介绍了如何在Easyswoole中实现一个简单的HTTP请求处理器,并处理GET和POST请求,最后实现对HTTP请求的响应。同时,我们也展示了具体的代码实现和运行结果。
### 第四章:实现HTTP路由
在构建一个HTTP服务时,路由是一个必不可少的组件。它负责将来自客户端的请求分发到相应的处理器函数。
#### 4.1 路由的概念和作用
路由是指将接收到的HTTP请求与相应的处理函数进行绑定的过程。它根据请求的路径和HTTP方法(GET、POST等)来确定应该调用哪个处理函数来处理请求。
通过使用路由,我们可以方便地将不同的请求分发给不同的处理函数,实现请求的分发和处理的解耦,提高代码的可维护性和扩展性。
#### 4.2 使用Easyswoole实现路由
Easyswoole提供了简洁而强大的路由功能,可以帮助我们快速实现路由配置。
首先,在Easyswoole项目的根目录下创建一个`HttpController`目录,用来存放我们编写的处理器类。
然后,在项目的根目录下找到`easyswoole`文件夹,打开`easyswoole.dev.php`文件,在其中找到`HTTP`配置项,并加入以下代码:
```php
'router' => [
'class' => \EasySwoole\HttpAnnotation\Swagger::class,
'enable' => true,
'swagger' => [
'openApiVersion' => '3.0.1',
'info' => [
'version' => '1.0.0',
'title' => 'Easyswoole API文档',
'author' => [
'name' => 'Your Name',
'email' => 'your-email@example.com',
],
],
'basePath' => '/',
'servers' => [
[
'url' => 'http://localhost:9501',
'description' => '本地开发环境',
],
],
'components' => [
'securitySchemes' => [
'Authorizaion' => [
'type' => 'apiKey',
'name' => 'Authorization',
'in' => 'header',
],
],
],
'ignorePath' => [
'/easyswoole/src',
'/easyswoole/easyswoole/src',
],
'ignoreAnnotation' => ['psalm-type'],
],
],
```
以上代码会启用Easyswoole的路由功能,并提供一个API文档页面。
接下来,我们可以在`HttpController`目录下创建一个名为`Index`的处理器类。
```php
<?php
namespace App\HttpController;
use EasySwoole\Http\AbstractInterface\Controller;
class Index extends Controller
{
public function index()
{
$this->response()->write('Hello Easyswoole!');
}
public function user($id)
{
$this->response()->write('User ID: ' . $id);
}
}
```
在上述代码中,我们创建了一个名为`Index`的类,继承自Easyswoole的`Controller`类。在该类中,我们定义了一个`index()`方法和一个`user()`方法,用于处理不同的请求。
`index()`方法用于处理根路径的请求,它会返回一个包含字符串`"Hello Easyswoole!"`的响应。
`user($id)`方法用于处理形如`/user/{id}`的请求,其中{id}是一个动态的路径参数,例如`/user/1`。它会返回一个包含`"User ID: {id}"`的响应,其中`{id}`是传入的路径参数。
最后,在项目的根目录下的`easyswoole`文件夹中打开`easyswoole.dev.php`文件。在其中找到`ROUTE`配置项,并加入以下代码:
```php
'route' => [
'scan' => [
'basePath' => '',
'ignoreAnnotation' => [],
'includePaths' => [
'App/HttpController',
],
'excludePaths' => [],
'annotationParser' => \EasySwoole\Annotation\Annotation::class,
'controllerPoolPreResolve' => true,
'onlyAnnotations' => false,
],
'list' => [
[
'path' => '/',
'controller' => \App\HttpController\Index::class,
'action' => 'index',
'method' => 'GET',
'param' => [],
'mappingParam' => [],
],
[
'path' => '/user/{id}',
'controller' => \App\HttpController\Index::class,
'action' => 'user',
'method' => 'GET',
'param' => [],
'mappingParam' => [],
],
],
],
```
在以上代码中,我们使用`list`配置项定义了两条路由规则:
- 第一条路由规则会将根路径(`/`)的`GET`请求映射到`Index`控制器的`index`方法上。
- 第二条路由规则会将形如`/user/{id}`的`GET`请求映射到`Index`控制器的`user`方法上,并将路径参数`{id}`传入`user`方法进行处理。
至此,我们成功地完成了HTTP路由的配置。
#### 4.3 测试路由功能
为了测试刚刚配置的路由功能,我们可以使用终端发送`curl`命令来模拟HTTP请求。
首先,打开一个终端窗口,并执行以下命令:
```bash
$ curl http://localhost:9501/
```
命令执行完成后,我们应该能够在控制台看到如下输出:
```
Hello Easyswoole!
```
这表明我们成功地将根路径的请求分发到了`Index`控制器的`index`方法上进行处理。
接下来,我们继续执行以下命令:
```bash
$ curl http://localhost:9501/user/1
```
命令执行完成后,我们应该能够在控制台看到如下输出:
```
User ID: 1
```
这表明我们成功地将形如`/user/{id}`的请求分发到了`Index`控制器的`user`方法上进行处理,并将路径参数`1`传入`user`方法进行处理。
通过以上测试,我们可以确认我们的路由配置和处理器类的编写都是正确的。
#### 4.4 结论
本章我们使用Easyswoole实现了简单的HTTP路由,通过配置路由规则和编写处理器类,我们可以将不同的HTTP请求分发给相应的处理函数进行处理。这提供了一个灵活而可维护的方式来处理不同类型的请求。
在下一章中,我们将介绍如何使用控制器来进一步封装和组织处理函数。
### 5. 第五章
#### 5.1 中间件的概念和作用
在Easyswoole框架中,中间件是一种可插入应用处理流程的组件。它可以在请求到达应用之前或者返回给客户端之前,对请求或响应做一些处理。中间件可以用于日志记录、身份验证、跨域处理等各种场景,使得应用的处理流程更加灵活和可控。
#### 5.2 编写和使用中间件
要编写一个中间件,首先需要创建一个类,并实现对应的中间件接口,然后在配置中注册该中间件。在处理流程中,Easyswoole框架会按照注册的先后顺序依次执行中间件。
```java
// 示例:编写一个简单的日志记录中间件
import com.easyswoole.http.Request;
import com.easyswoole.http.Response;
import com.easyswoole.http.server.HttpAnnotation;
import com.easyswoole.http.server.HttpController;
import com.easyswoole.http.server.HttpServer;
public class LogMiddleware implements HttpAnnotation {
@Override
public boolean onRequest(Request request, Response response) throws Exception {
// 在请求处理前记录日志
System.out.println("Request Path: " + request.getUri().getPath());
return true; // 返回true表示继续执行后续中间件或请求处理
}
@Override
public boolean onException(Request request, Response response, Throwable e) {
// 在发生异常时记录日志
System.out.println("Exception occurred: " + e.getMessage());
return true; // 返回true表示继续执行后续中间件的onException方法
}
@Override
public void afterAction(Request request, Response response, boolean isSuccess) {
// 在请求处理后记录日志
System.out.println("Response Status: " + response.getStatus());
}
}
```
#### 5.3 中间件在HTTP服务中的应用
中间件可以在全局范围或者局部范围进行注册和使用。全局注册的中间件会作用于所有的请求,而局部注册的中间件只会作用于指定的控制器或路由。
```java
// 示例:全局注册日志记录中间件
HttpServer server = new HttpServer();
server.addGlobalMiddleware(new LogMiddleware());
// 示例:局部注册中间件到特定路由
@RouteMapping(path="/user/profile")
public class UserController extends HttpController {
@Override
public void index() {
// 在UserController的路由中使用特定的中间件
addMiddleware(new LogMiddleware());
// 处理用户信息请求
}
}
```
通过合理使用中间件,可以更好地对请求和响应进行处理,使得应用的处理逻辑更加清晰和灵活。
## 第六章:测试Easyswoole HTTP服务
在开发过程中,测试是一个非常重要的环节。本章将介绍如何对Easyswoole HTTP服务进行测试,并验证代码的正确性。
### 6.1 编写测试用例
在编写测试用例之前,我们需要安装PHPUnit测试框架。在项目根目录下执行以下命令安装PHPUnit:
```shell
composer require --dev phpunit/phpunit
```
接下来,我们将创建一个新的目录`tests`来存放测试用例。在`tests`目录下创建一个新的文件`HttpTest.php`,并编写以下代码:
```php
<?php
use PHPUnit\Framework\TestCase;
class HttpTest extends TestCase
{
public function testGetRequest()
{
$client = new \GuzzleHttp\Client();
$response = $client->get('http://localhost:9501/hello');
$this->assertEquals(200, $response->getStatusCode());
$this->assertEquals('Hello, Easyswoole!', $response->getBody()->getContents());
}
}
```
在这个测试用例中,我们使用了GuzzleHttp作为HTTP客户端来发送GET请求到`http://localhost:9501/hello`。然后验证返回的状态码和内容是否正确。
### 6.2 执行测试
在完成测试用例的编写后,我们可以执行测试来验证代码的正确性。在项目根目录下执行以下命令来运行测试:
```shell
./vendor/bin/phpunit tests
```
运行测试后,PHPUnit将会执行我们编写的测试用例,并输出测试结果。
### 6.3 结果和总结
运行测试后,我们可以根据PHPUnit输出的结果来检查代码的正确性。如果测试用例中的断言失败,那么我们就需要进一步检查代码实现是否有错误。
通过编写测试用例,我们可以提前发现和解决代码中的问题,确保程序的稳定性和可靠性。
本章介绍了如何编写测试用例,并使用PHPUnit进行测试。通过测试,我们可以验证Easyswoole HTTP服务的代码是否正确并保证其功能的准确性。
在下一章,我们将学习如何部署Easyswoole HTTP服务,将其运行在生产环境中。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
easyswoole 专栏系统全面介绍了使用 Easyswoole 框架所涉及的方方面面,包括框架的基本介绍与快速入门、实现简单的 HTTP 服务、使用 Coroutine 实现异步编程、进程管理与多进程通信、定时任务调度与异步任务处理、数据库操作与 ORM 使用、WebSocket 服务的实现、RPC 服务的实现与使用、性能优化与扩展性设计等。同时还覆盖了使用 Redis 进行缓存与数据存储、日志系统的设计与使用、权限控制与用户认证、Web 模板引擎的使用、HTTP/2 与 HTTPS 支持、CI/CD 与自动化部署、微服务架构设计与实践、API 网关与反向代理、服务发现与负载均衡、服务容错与降级策略、以及消息队列与削峰填谷等内容。通过这些丰富的文章,读者可以深入了解 Easyswoole 框架在各种场景下的应用,从而更好地掌握这一高性能、易用的框架。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
揭秘雷达信号处理:从脉冲到频谱的魔法转换
# 摘要
本文对雷达信号处理技术进行了全面概述,从基础理论到实际应用,再到高级实践及未来展望进行了深入探讨。首先介绍了雷达信号的基本概念、脉冲编码以及时间域分析,然后深入研究了频谱分析在雷达信号处理中的基础理论、实际应用和高级技术。在高级实践方面,本文探讨了雷达信号的采集、预处理、数字化处理以及模拟与仿真的相关技术。最后,文章展望了人工智能、新兴技术对雷达信号处理带来的影响,以及雷达系统未来的发展趋势。本论文旨在为雷
【ThinkPad T480s电路原理图深度解读】:成为硬件维修专家的必备指南
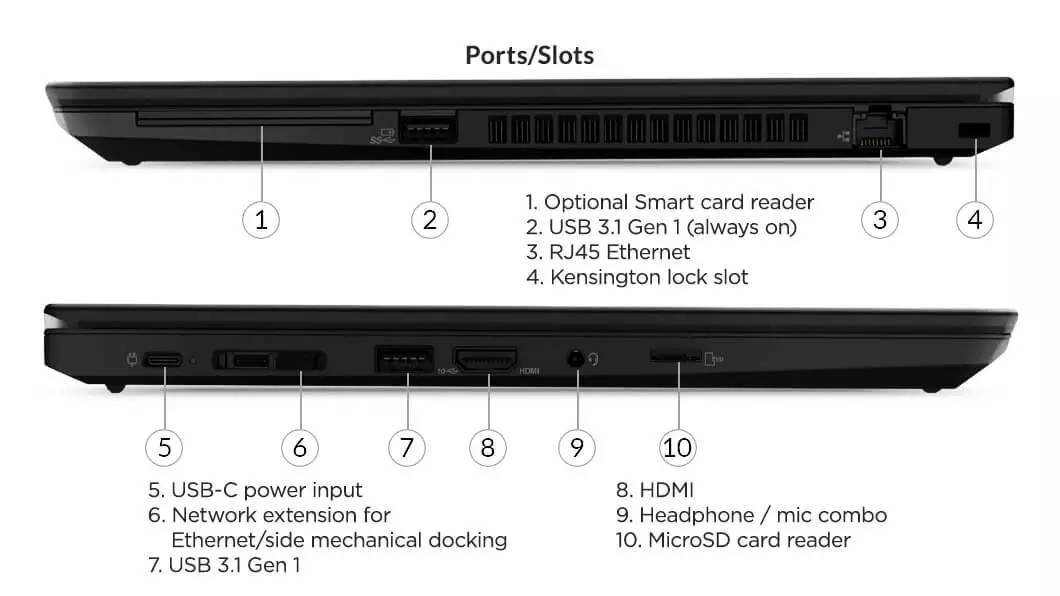
# 摘要
本文对ThinkPad T480s的硬件组成和维修技术进行了全面的分析和介绍。首先,概述了ThinkPad T480s的硬件结构,重点讲解了电路原理图的重要性及其在硬件维修中的应用。随后,详细探讨了电源系统的工作原理,主板电路的逻辑构成,以及显示系统硬件的组成和故障诊断。文章最后针对高级维修技术与工具的应用进行了深入讨论,包括
【移动行业处理器接口核心攻略】:MIPI协议全景透视
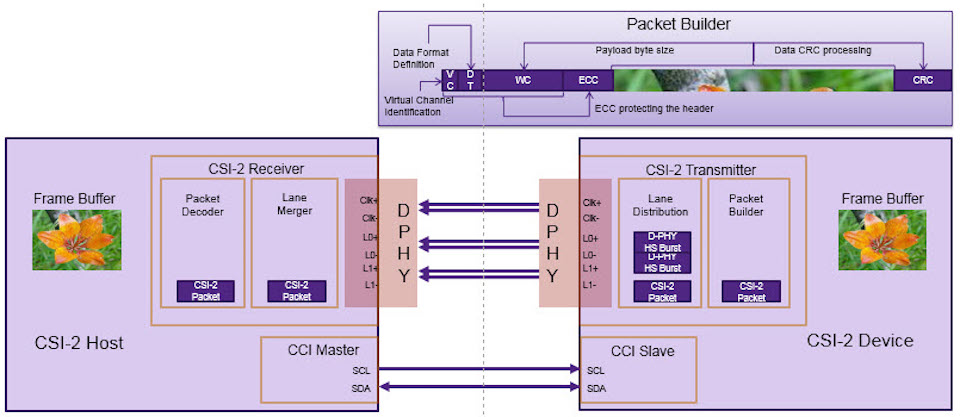
# 摘要
本文详细介绍了移动行业处理器接口(MIPI)协议的核心价值和技术原理,强调了其在移动设备中应用的重要性和优势。通过对MIPI协议标准架构、技术特点以及兼容性与演进的深入分析,本文展示了MIPI在相机、显示技术以及无线通信等方面的实用性和技术进步。此外,本文还探讨了MIPI协议的测试与调试方法,以及在智能穿戴设备、虚拟现实和增强
【编译器调优攻略】:深入了解STM32工程的编译优化技巧

# 摘要
本文深入探讨了STM32工程优化的各个方面,从编译器调优的理论基础到具体的编译器优化选项,再到STM32平台的特定优化。首先概述了编译器调优和STM32工程优化的理论基础,然后深入到代码层面的优化策略,包括高效编程实践、数据存取优化和预处理器的巧妙使用。接着,文章分析了编译器优化选项的重要性,包括编译器级别和链接器选项的影响,以及如何在构建系统中集成这些优化。最后,文章详
29500-2标准成功案例:组织合规性实践剖析

# 摘要
本文全面阐述了29500-2标准的内涵、合规性概念及其在组织内部策略构建中的应用。文章首先介绍了29500-2标准的框架和实施原则,随后探讨了
S7-1200_S7-1500故障排除宝典:维护与常见问题的解决方案

# 摘要
本文综述了S7-1200/S7-1500 PLC的基础知识和故障诊断技术。首先介绍PLC的硬件结构和功能,重点在于控制器核心组件以及I/O模块和接口类型。接着分析电源和接地问题,探讨其故障原因及解决方案。本文详细讨论了连接与接线故障的诊断方法和常见错误。在软件故障诊断方面,强调了程序错误排查、系统与网络故障处理以及数
无人机精准控制:ICM-42607在定位与姿态调整中的应用指南
# 摘要
无人机精准控制对于飞行安全与任务执行至关重要,但面临诸多挑战。本文首先分析了ICM-42607传感器的技术特点,探讨了其在无人机控制系统中的集成与通信协议。随后,本文深入阐述了定位与姿态调整的理论基础,包括无人机定位技术原理和姿态估计算法。在此基础上,文章详细讨论了ICM-42607在无人机定位与姿态调整中的实际应用,并通
易语言与FPDF库:错误处理与异常管理的黄金法则

# 摘要
易语言作为一门简化的编程语言,其与FPDF库结合使用时,错误处理变得尤为重要。本文旨在深入探讨易语言与FPDF库的错误处理机制,从基础知识、理论与实践,到高级技术、异常管理策略,再到实战演练与未来展望。文章详细介绍了错误和异常的概念、重要性及处理方法,并结合FPDF库的特点,讨论了设计时与运行时的错误类型、自定义与集成第三方的异常处理工具,以及面向对象中的错误处理。此外,本文还强
Linux下EtherCAT主站igh程序同步机制:实现与优化指南
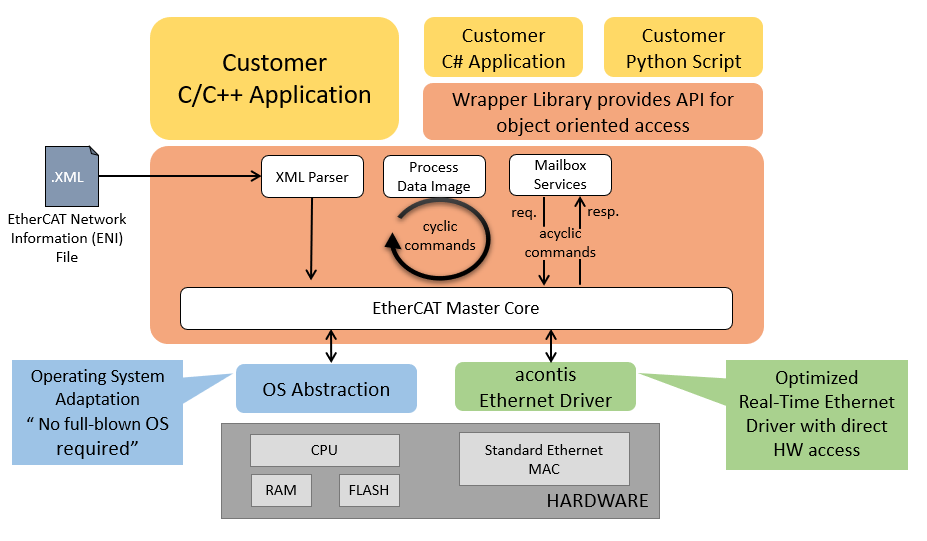
# 摘要
本文首先概述了EtherCAT技术及其同步机制的基本概念,随后详细介绍了在Linux环境下开发EtherCAT主站程序的基础知识,包括协议栈架构和同步机制的角色,以及Linux环境下的实时性强化和软件工具链安装。在此基础上,探讨了同步机制在实际应用中的实现、同步误差的控制与测量,以及同步优化策略。此外,本文还讨论了多任务同步的高级应用、基于时间戳的同步实现、
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )