【数据库急救手册】:掌握MySQL表缺失问题的十大解决方案
发布时间: 2024-11-30 01:48:54 阅读量: 38 订阅数: 33 

日常急救手册ACCESS数据库

参考资源链接:[MySQL数据恢复:解决表不存在错误的步骤与技巧](https://wenku.csdn.net/doc/6412b4cebe7fbd1778d40e46?spm=1055.2635.3001.10343)
# 1. MySQL表缺失问题概览
在数据库管理中,数据表的缺失是一个紧急且具有破坏性的问题,它可能导致数据丢失和业务中断。当数据表消失时,企业不仅面临数据恢复的挑战,还需要确保系统的稳定性和数据的完整性。在本章中,我们将介绍MySQL表缺失问题的基本概念,以及它可能对业务造成的各种影响。通过概览,读者将对这一问题有一个初步的理解,并认识到预防和解决表缺失问题的重要性。
## 1.1 数据表的作用
在关系型数据库中,数据表是存储和管理数据的基本单位。它们在组织数据、查询、更新、删除等方面发挥着关键作用。每张表都有其独特的结构,由一系列的行和列组成,每行代表一条记录,而每列则代表记录中不同的数据字段。
## 1.2 表缺失的影响
数据表的丢失会立即导致数据访问中断,影响到依赖这些数据的所有应用程序。更糟糕的是,如果丢失的数据未得到及时恢复,可能导致业务决策失误,甚至引起客户的不满和信任危机。长期的数据丢失还可能违反法规遵从性要求,给企业带来法律责任和声誉损失。
## 1.3 理解数据表丢失的原因
数据表的丢失可能由多种原因引起,包括但不限于硬件故障、软件错误、操作失误或恶意软件攻击。深入理解这些原因对于预防未来的数据表缺失至关重要。下一章,我们将详细探讨这些原因,并分析如何诊断和预防这一问题。
# 2. 理解表缺失的理论基础
在现代数据库管理系统中,表是存储数据的基本单位,确保数据的完整性和一致性对于数据库的正常运行至关重要。当数据库表丢失时,可能会导致数据访问异常,甚至整个应用的中断。因此,理解表缺失的原因、掌握诊断方法和预防策略,对于保障数据库安全运行具有重要意义。
## 2.1 数据库表结构的重要性
### 2.1.1 数据表的角色和作用
数据表是组织和存储数据的结构化方法,它由行和列组成,每列代表数据的一个特定属性,每一行代表一组数据。数据表允许数据库管理系统以高效、有序的方式执行数据的增删改查操作。此外,它还是实现数据关系模型,支持事务处理、并发控制和数据完整性约束的关键组件。
### 2.1.2 数据表缺失的常见原因
数据表丢失可能由多种原因引起,包括但不限于:硬件故障,如磁盘损坏或服务器故障;软件错误,如数据库软件崩溃或文件系统损坏;人为错误,例如不当的数据库操作或误删除;以及外部因素,例如网络中断或电力故障。了解这些常见原因有助于提前制定应对策略,避免数据丢失。
## 2.2 MySQL表丢失的诊断方法
### 2.2.1 日志分析和错误信息解读
MySQL数据库通过日志文件记录了所有的操作和系统事件。在发生表丢失的情况下,可以通过查看错误日志、二进制日志和InnoDB的事务日志来诊断问题。这些日志文件通常位于数据库服务器的指定目录下,错误日志通常记录了系统级别的错误,而二进制日志记录了所有对数据库的修改操作,可以用来进行数据恢复。
```sql
SHOW VARIABLES LIKE 'log_error'; -- 查看错误日志文件位置
SHOW VARIABLES LIKE 'log_bin'; -- 查看二进制日志文件位置
SHOW VARIABLES LIKE 'innodb_log_file_path'; -- 查看InnoDB日志文件位置
```
### 2.2.2 数据库备份的验证和恢复点
备份是防止数据丢失的重要手段之一,有效的备份策略是确保数据安全的关键。通过对备份数据的定期验证和恢复测试,可以确保在真正的数据丢失事件中能够迅速且准确地恢复数据。备份验证包括检查备份文件的完整性、执行恢复操作的可行性等。
### 2.2.3 系统性能监控与异常检测
系统监控是识别问题早期迹象的预防措施。通过监控数据库服务器的性能指标,例如CPU使用率、内存使用量、磁盘I/O性能等,可以快速发现异常行为。此外,使用高级监控工具进行异常检测,比如基于机器学习的方法,可以帮助数据库管理员在系统性能出现异常之前及时采取行动。
通过理解表缺失的理论基础,我们能够更深入地认识到数据表在数据库系统中的重要性,以及如何通过日志分析和系统监控等方法预防和诊断表丢失的问题。下一章节将深入探讨预防MySQL表丢失的策略,以进一步加强数据安全防护。
# 3. 预防MySQL表丢失的策略
在信息化日益增长的今天,数据已成为组织最宝贵的资产之一。数据库的稳定性直接关系到业务的连续性和数据的安全。然而,由于硬件故障、软件缺陷、操作失误等多种因素的影响,MySQL数据库表丢失的情况时有发生。为了最大限度地降低数据丢失带来的风险,我们需要深入理解预防策略,从备份、日志管理、系统监控等方面来规避和减少数据库表丢失的风险。
## 3.1 数据库定期备份机制
备份作为数据库最基础也是最重要的预防措施之一,其重要性不言而喻。定期备份能够保证在发生数据丢失时,我们有可靠的数据副本可以使用,以恢复到丢失数据之前的状态。实践中,建立一个有效的备份计划是确保数据安全的关键。
### 3.1.1 定时备份计划的设置
为了实现定时备份,可以使用MySQL自带的备份工具如`mysqldump`,或通过第三方备份软件来实现。以下是一个简单的`mysqldump`命令,用于备份名为`mydatabase`的数据库:
```bash
mysqldump -u root -p mydatabase > mydatabase_backup_$(date +%F).sql
```
上面的命令将`mydatabase`数据库备份到当前目录下,并以日期格式命名备份文件。此命令应该被加入到一个定时任务中,比如使用cron进行设置。一个cron任务的示例配置如下:
```cron
0 2 * * * /usr/bin/mysqldump -u root -p mydatabase > /var/backups/mydatabase_backup_$(date +\%F).sql
```
这个cron任务表示每天凌晨2点执行一次备份操作。
### 3.1.2 多版本备份与恢复测试
虽然单一版本的备份能够提供一定程度的保护,但面对复杂的业务环境和可能出现的各种问题,多版本备份显得更为必要。这样,即使最新的备份在恢复时出现问题,我们也可以从更早的备份版本中恢复数据。建议的做法是:
- 每日全备份
- 每小时增量备份
- 每次重要更新后进行一次全备份
此外,定期进行恢复测试是确保备份有效性的重要手段。这样做的目的不仅是验证备份文件的完整性,同时也是对数据库管理员操作技能的练兵。
## 3.2 事务和日志管理优化
事务和日志是MySQL数据库的重要组成部分,合理的配置和管理可以有效地避免数据丢失的情况。
### 3.2.1 事务隔离级别的选择与调整
事务隔离级别定义了一个事务可能受到其他事务的干扰程度。MySQL提供了四种隔离级别:READ UNCOMMITTED、READ COMMITTED、REPEATABLE READ以及SERIALIZABLE。其中,较低的隔离级别可能会导致脏读、不可重复读和幻读等问题,而较高的隔离级别虽然可以避免这些问题,但同时也会带来性能的下降。
选择合适的隔离级别是平衡事务隔离性和系统性能的关键。一般而言,READ COMMITTED级别既能够满足大多数应用的需求,又能在大多数情况下保持良好的性能。
### 3.2.2 二进制日志的合理配置
MySQL的二进制日志(binlog)记录了数据库中所有更改数据的语句。在发生故障时,可以通过二进制日志来进行数据恢复或复制到其他服务器。因此,合理配置和管理二进制日志对于避免数据丢失至关重要。
```sql
-- 配置二进制日志
SET GLOBAL log_bin = 'mysql-bin';
-- 启用二进制日志记录
SET GLOBAL binlog_format = 'ROW';
-- 设置二进制日志自动清理时间
SET GLOBAL expire_logs_days = 10;
```
在上面的示例中,我们启用了二进制日志,并设置了日志格式为基于行的复制(ROW),这种方式能够提供更加详细的日志信息,有助于数据恢复。此外,设置合理的过期时间可以避免日志文件无限制的增长,造成磁盘空间的浪费。
## 3.3 系统监控和警告机制
及时发现数据库的异常行为并采取行动是预防数据丢失的最后一步。一个有效的监控系统能够实时监测数据库的状态,发现问题时及时通知相关人员。
### 3.3.1 实时监控系统的建立
建立一个全面的数据库监控系统需要考虑多个方面,包括但不限于:
- 系统资源使用情况,如CPU、内存、磁盘I/O和网络I/O
- 数据库的性能指标,如查询响应时间、事务吞吐量和锁等待时间
- 数据库错误日志和系统日志的分析
市面上有很多成熟的监控工具,如Prometheus结合Grafana、Percona Monitoring and Management(PMM)等,可以帮助数据库管理员实时监控数据库的状态,及时发现异常。
### 3.3.2 报警规则的设置与维护
有了监控系统之后,如果没有合适的报警机制,管理人员可能无法及时接收到问题的通知。因此,根据不同的监控指标设置合理的报警规则显得至关重要。例如:
- 当事务的平均响应时间超过500毫秒时发送警告。
- 当系统磁盘使用率达到90%时发送警告。
通过设定阈值并根据实际情况调整,可以有效提高数据库的运行稳定性,避免因监控系统的失察而导致的数据丢失。
通过本章节的详细介绍,我们已经了解了如何通过数据库备份、事务和日志管理以及系统监控等多方面措施来预防MySQL表丢失的风险。下一章节,我们将进一步深入探讨,当表丢失真的发生时,我们有哪些解决方案可以进行应对和恢复。
# 4. MySQL表缺失的解决方案实战
## 4.1 利用InnoDB的崩溃恢复
### 4.1.1 崩溃恢复的执行步骤
在MySQL中,InnoDB存储引擎提供了崩溃恢复功能,以处理数据文件损坏或系统异常终止后数据库的自动恢复。InnoDB的崩溃恢复主要包括三个步骤:恢复数据、重做日志应用以及撤销未提交的事务。
1. **恢复数据**:InnoDB在启动时会尝试打开数据文件。如果文件无法打开或损坏,InnoDB会将该数据表置于不可用状态,并尝试从备份文件中恢复。恢复过程中,InnoDB会读取已提交事务的数据,并将其应用到数据文件中。
2. **重做日志应用**:InnoDB利用重做日志(redo log)文件中的信息来重建数据文件未提交事务的修改。重做日志记录了所有对数据库数据所做的更改,InnoDB通过重做日志恢复到最近一次一致的状态。
3. **撤销未提交事务**:在重做日志应用完成后,InnoDB会查找崩溃时未提交的事务,并执行回滚操作以撤销这些事务的更改。
### 4.1.2 崩溃恢复过程中的注意事项
在进行崩溃恢复时,需要确保以下几点:
- **确保足够的日志空间**:重做日志文件需要足够大,以便记录崩溃期间发生的所有更改。可以通过调整 `innodb_log_file_size` 参数来增加日志文件的大小。
- **监控恢复过程**:在执行崩溃恢复期间,应密切监控MySQL的错误日志和状态变量,以便于发现任何潜在的问题。
- **考虑恢复时间**:崩溃恢复时间取决于需要处理的重做日志量。对于大型数据库,这个过程可能比较耗时,建议在系统负载较低时进行崩溃恢复操作。
- **避免强制关闭MySQL服务**:在恢复过程中的任何点强制关闭MySQL服务可能会导致数据不一致。如果必须要停止服务,应先确保所有事务都被正确地回滚。
## 4.2 手动重建丢失的数据表
### 4.2.1 根据逻辑备份文件恢复
在数据表丢失的情况下,如果事先有逻辑备份(例如使用 `mysqldump` 工具),则可以通过恢复备份文件来重建表。执行恢复的基本步骤如下:
1. **准备备份文件**:确认备份文件的完整性和最新性,确保它们包含了丢失的数据表。
2. **执行恢复命令**:使用 `mysql` 或 `mysqlimport` 命令将备份文件导入到MySQL实例中。
```bash
mysql -u username -p database_name < backup_file.sql
```
或者使用 `mysqlimport` 工具:
```bash
mysqlimport -u username -p database_name backup_file.sql
```
3. **验证数据**:导入完成后,检查数据表和数据记录是否正确恢复。
### 4.2.2 利用物理备份和二进制日志重建
物理备份(如 `xtrabackup`)提供了另一种恢复数据表的途径。结合二进制日志(binlog),可以更精确地重放丢失数据的特定时间点。
1. **使用物理备份**:首先,从物理备份中恢复数据库到最近的备份点。例如使用 `xtrabackup` 命令:
```bash
xtrabackup --copy-back --target-dir=/path/to/backup
```
2. **找到故障点**:确定数据表丢失时对应的二进制日志位置。可以通过查看 `mysql-bin.index` 或日志管理命令来查找。
3. **重放二进制日志**:使用 `mysqlbinlog` 命令从指定的二进制日志位置开始重放日志,直到数据库状态与故障点一致。
```bash
mysqlbinlog --start-datetime="2023-01-01 00:00:00" --stop-datetime="2023-01-01 23:59:59" /path/to/binlog.000001 | mysql -u username -p database_name
```
## 4.3 选择合适的工具和脚本
### 4.3.1 数据库恢复工具的比较
目前市场上存在多种MySQL数据恢复工具,各有特点。选择合适的工具时,需要考虑以下几个因素:
- **用户界面**:工具是否提供图形界面(GUI),或者仅支持命令行操作。
- **支持的数据库版本**:不同的工具可能支持不同版本的MySQL数据库。
- **恢复类型**:有的工具专门用于恢复被删除的表,有的则支持更广泛的数据库恢复工作。
- **性能和效率**:不同工具的恢复速度和效率也各不相同。
- **价格**:商用工具通常需要购买许可,而开源工具则可能是免费的。
### 4.3.2 脚本自动化恢复过程
自动化脚本可以在遇到表丢失时快速执行恢复操作,减少人工干预和错误的可能性。脚本中可能包含如下内容:
- **备份和日志文件的位置**:自动找到备份文件和日志文件的位置。
- **备份验证**:确认备份文件的有效性。
- **恢复操作**:执行数据恢复命令,包括导入备份文件和重放二进制日志。
- **日志记录**:记录恢复过程中的所有操作,便于后续审计和分析。
例如,一个简单的Shell脚本可能如下所示:
```bash
#!/bin/bash
BACKUP_DIR="/path/to/backup"
LOG_DIR="/path/to/logs"
DB_NAME="database_name"
# 检查备份文件
if [ ! -f "${BACKUP_DIR}/backup_file.sql" ]; then
echo "备份文件不存在"
exit 1
fi
# 恢复数据表
mysql -u username -p${DB_PASSWORD} ${DB_NAME} < "${BACKUP_DIR}/backup_file.sql"
# 重放二进制日志
LAST_BINLOG=$(mysql -u username -p${DB_PASSWORD} -e "SHOW BINARY LOGS;" | tail -n 1 | awk '{print $1}')
mysqlbinlog --start-datetime="2023-01-01 00:00:00" --stop-datetime="2023-01-01 23:59:59" "${LOG_DIR}/${LAST_BINLOG}" | mysql -u username -p${DB_PASSWORD} ${DB_NAME}
# 记录恢复操作到日志文件
echo "数据库恢复操作完成,备份文件使用:${BACKUP_DIR}/backup_file.sql" >> recovery.log
```
这个脚本首先检查备份文件是否存在,然后通过mysql命令恢复备份,接着利用mysqlbinlog重放二进制日志。脚本运行的所有步骤都会被记录到指定的日志文件中。在实际使用中,需要根据实际情况对脚本进行调整和完善。
# 5. 数据库急救后的评估与优化
数据库急救操作完成后,进行彻底的评估和优化是非常必要的。这一步骤确保了数据的完整性,并为未来的预防措施提供了反馈。同时,优化数据库性能和安全性可以提高数据库的整体健康状况。
## 5.1 恢复后的数据完整性校验
在数据库急救操作完成后,首要任务是确保数据的完整性和一致性。数据完整性校验不仅是对急救操作成功性的验证,也是对数据库完整性的复核。
### 5.1.1 数据一致性检查方法
执行数据一致性检查,可以使用多种工具和命令,例如:
- 使用 `CHECK TABLE` 命令检查 MySQL 数据库中的表的完整性。
- 使用第三方工具如 Percona Toolkit 中的 `pt-table-checksum` 和 `pt-table-sync` 进行数据校验和同步。
举例代码:
```sql
CHECK TABLE my_table;
```
### 5.1.2 校验结果的分析与处理
校验完毕后,通常会有多种结果:
- `OK` 表示表已经完整。
- `warning` 可能表示潜在问题,需要进一步分析。
- `ERROR` 需要立即处理。
针对不同的校验结果,可以使用以下策略:
- 对于 `ERROR`,根据错误信息采取相应措施,如重建索引、修复表等。
- 对于 `warning`,进行深入的分析和手动干预。
## 5.2 急救操作的效果评估
评估急救操作的成效,可以帮助我们了解当前的数据库状态,并为未来的预防措施提供方向。
### 5.2.1 急救成功率的统计与分析
急救成功率的统计可以通过记录每次急救操作前后的状态来实现。这通常涉及到日志分析和统计数据库操作的历史数据。
可以使用类似如下的脚本进行急救成功率的统计:
```python
import MySQLdb
# 连接到数据库
db = MySQLdb.connect("host", "user", "password", "database")
cursor = db.cursor()
# 执行查询
cursor.execute("SELECT * FROM recovery_operations_log WHERE result='SUCCESS';")
# 获取结果
records = cursor.fetchall()
# 计算成功率
success_count = len(records)
total_count = cursor.rowcount
success_rate = success_count / total_count * 100
print(f"Recovery Success Rate: {success_rate}%")
cursor.close()
db.close()
```
### 5.2.2 对未来预防措施的评估
评估急救操作的成功率和可能存在的问题,可以对未来的预防措施进行评估和改进。
## 5.3 数据库性能和安全性的优化
数据库急救操作之后,优化性能和安全性可以进一步提高数据库的整体健康状况。
### 5.3.1 优化数据库性能的策略
性能优化可以从多个角度进行:
- 优化索引,定期执行 `ANALYZE TABLE` 命令。
- 检查并调整查询缓存设置。
- 审核和优化缓慢的查询,使用工具如 `EXPLAIN`。
- 调整数据库配置参数,比如 `innodb_buffer_pool_size`。
具体操作如下:
```sql
ANALYZE TABLE my_table;
```
### 5.3.2 加强数据库安全防护的措施
安全性优化包括:
- 使用强密码策略和定期更换密码。
- 定期审核用户权限,移除不必要的权限。
- 使用防火墙来限制访问,如 `iptables` 或云服务提供的安全组。
- 定期备份数据,并确保备份的安全性。
举例配置iptables规则:
```iptables
iptables -A INPUT -p tcp --dport 3306 -j ACCEPT
iptables -A INPUT -p tcp --dport 3306 -j DROP
```
通过这些步骤,您可以确保数据库在急救操作后恢复到最佳状态,同时为未来的稳定运行打下坚实的基础。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
MySQL数据库中表不存在问题是数据库管理员经常遇到的棘手问题。本专栏提供了全面的指南,帮助您解决这一问题。从紧急情况的急救方案到深入的故障排除技巧,本专栏涵盖了所有内容。您将学习如何恢复丢失的表、防止数据丢失,以及创建高效的备份计划。此外,本专栏还提供了高级解决方案,例如数据库日志分析和数据结构重建,以帮助您解决最复杂的表不存在问题。无论您是经验丰富的数据库管理员还是初学者,本专栏都将为您提供所需的知识和工具,以有效地解决MySQL表不存在问题。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【高级FANUC RS232通讯故障诊断技巧】:提升问题解决效率,手把手教学!
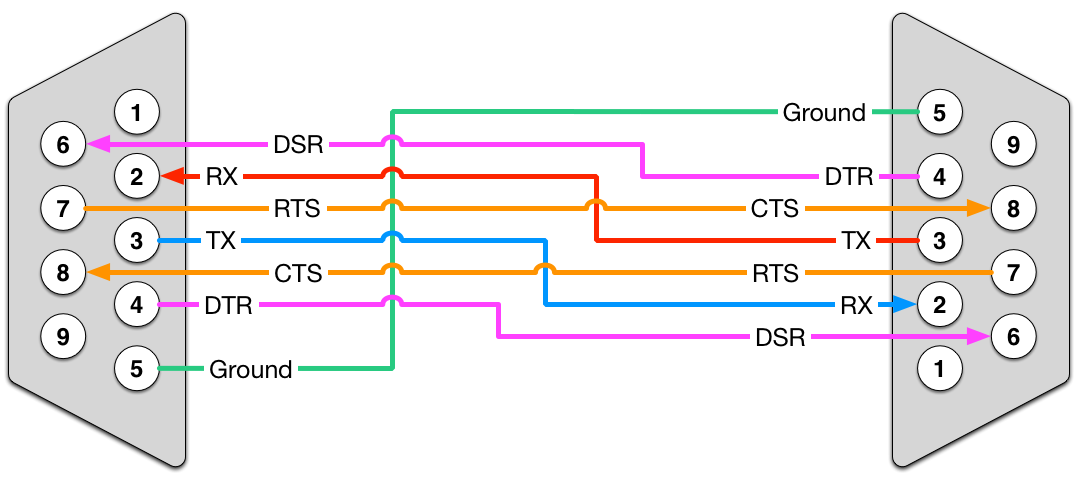
# 摘要
FANUC RS232通讯作为一种常见的工业通讯协议,对于自动化设备间的通信至关重要。本文旨在深入解析FANUC RS232通讯的基础知识、协议细节、故障诊断理论与实践,并提供相应的解决方法。通过系统地了解和实施该通讯协议,可以有效预防和解决通讯故障,确保工业自动化系统的稳定运行。本文亦强调了FANUC RS232通讯的日常维护工作,从而延长设备寿命并提升系统
【模具制造数字化转型】:一文看懂如何用术语对照表优化CAD_CAM流程

# 摘要
数字化转型在模具制造行业中扮演着至关重要的角色,特别是在CAD/CAM流程优化方面。本文首先强调了数字化转型的重要性,并探讨了CAD/CAM流程优化的基础,包括术语对照表的作用、当前流程的局限性,以及优化原则。进一步地,文章通过实践案例深入分析了术语标准化和术语对照表的应用,特别是在设计、制造
模块集成专家指南:HUAWEI ME909s-821嵌入式系统集成详解
# 摘要
HUAWEI ME909s-821嵌入式系统作为研究对象,本文首先对嵌入式系统及其集成理论进行了概述,阐述了系统集成的定义、目标、挑战以及模块化设计原则和模块间通信机制。接着,通过实践角度分析了系统环境搭建、驱动开发与集成、API封装与使用的关键步骤,重点探讨了如何优化系统性能和提升安全性,以及系统升级与维护的策略。最后,通过案例研究,本文分析了典型应用场景,诊断并解决实际问题,并展望了嵌入式系统集成的未来发展趋势。
# 关键字
嵌入式系统;系统集成;模块化设计;性能优化;安全性;API封装
参考资源链接:[华为ME909s-821 LTE Mini PCIe模块硬件指南](ht
【事务管理与并发控制艺术】:数据库操作的原子性,你也可以轻松掌握!
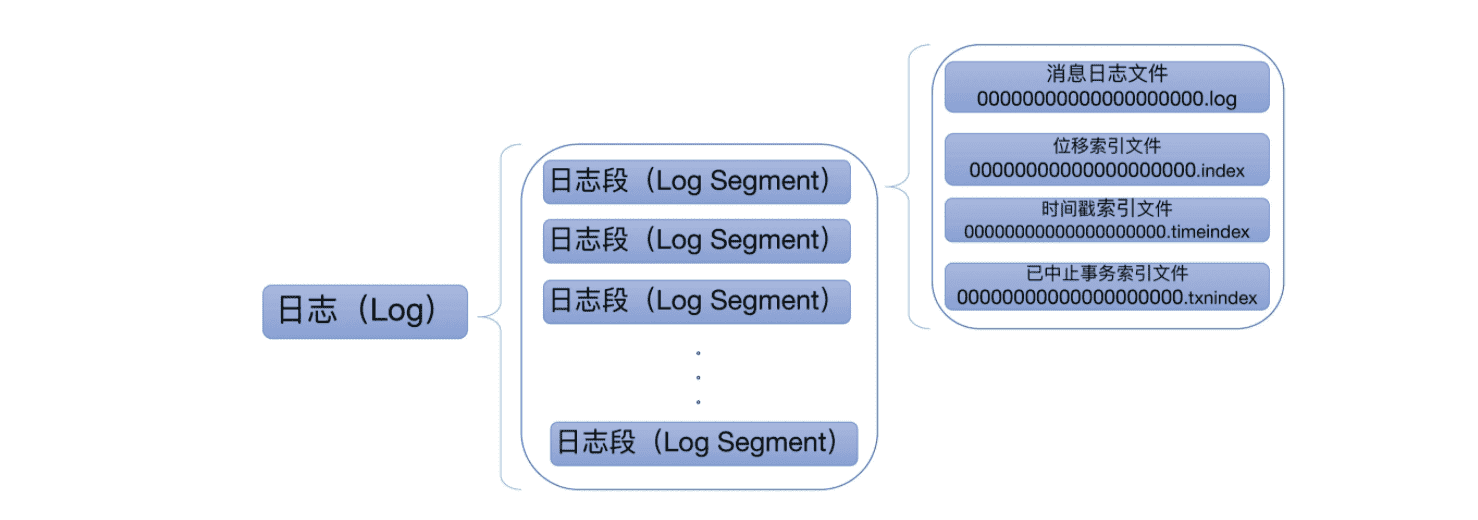
# 摘要
事务管理是数据库系统的核心机制,确保数据操作的可靠性和一致性。本文首先介绍了事务管理的基本概念及其重要性,随后详细阐述了ACID属性的各个方面,包括原子性、一致性、隔离性和持久性,并探讨了其实现技术。在并发控制方面,本文讨论了锁机制、事务隔离级别和乐观并发控制策略,以及它们对性能和数据一致性的影响。接下来,文章分析了不同数据库系统中事务管理的实现,包括关系
【模型重用与封装技巧】

# 摘要
模型重用与封装是提高软件开发效率和质量的关键技术。本文首先阐述了模型重用与封装的重要性,分析了重用模型的优势及其在不同领域的应用案例。接着,探讨了模
数字信号处理深度揭秘:通信领域的10大应用实例

# 摘要
数字信号处理(DSP)是现代通信技术不可或缺的部分,本文全面概述了DSP的基础理论及其在通信中的应用。从基础理论出发,本文深入探讨了D
E4440A故障诊断全攻略:遇到这些问题,这样做立刻解决!
# 摘要
本文对E4440A射频信号发生器进行了全面的概览和故障诊断的深入分析。首先介绍了E4440A的基础知识,包括其操作原理、工作机制以及主要组成部分。接着,本文详细阐述了E4440A的常规操作流程、故障诊断步骤和实践技巧,为操作人员提供了一套完整的操作和维护指南。此外,本文还探讨了E4440A的高级故障诊断技术,如进阶测试功能和专用诊断工具的应用,以及复杂故障案例的研究。最后,提出了E4440A的维护和优化策略,
忘记密码了?Windows 10系统密码恢复的4个快速技巧
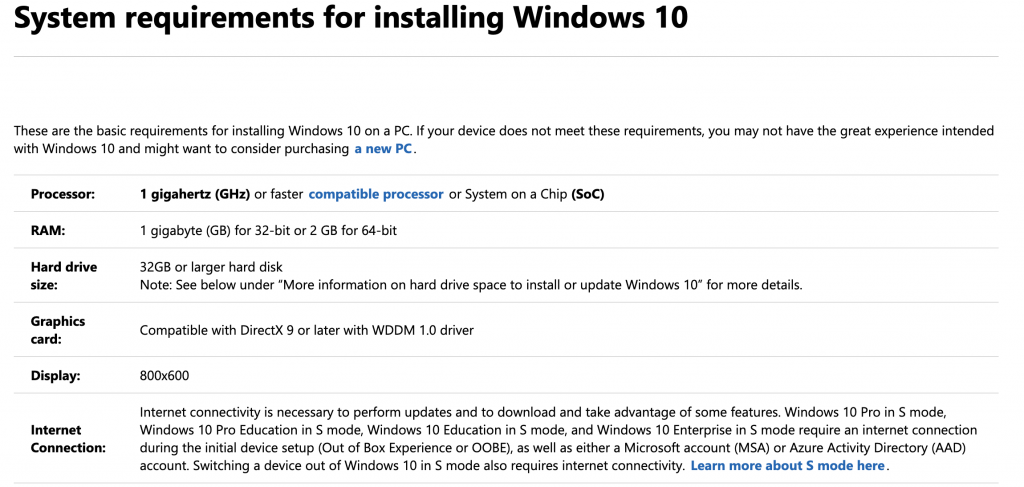
# 摘要
Windows 10系统的密码管理是保障用户账户安全的关键部分。本文首先强调了密码在系统安全中的重要性,随后介绍了不同类型的Windows账户以及相应的安全策略。文中详细阐述了多种密码恢复工具和技术,包括利用系统自带工具和第三方软件,以及创建紧急启动盘的步骤,为忘记密码用户提供了解决方案。本文还探讨了预防措施,如备份账户信息和定期更新安全策略,以减少密码丢失的可
【STAR-CCM+多相流仿真】:深入解析气动噪声在模拟中的角色
# 摘要
本论文旨在探究气动噪声在多相流仿真中的基础概念及其在工程应用中的实际分析。首先介绍了气动噪声的理论基础和数学模型,并详细讲解了STAR-CCM+软件的安装、环境配置以及用户界面。通过阐述气动噪声的物理机制和类型、控制方程以及噪声模型的计算方法,为后续模拟实践打下理论基础。文章进一步介绍了在STAR-CCM+软件中进行气
【XML DOM编程】:JavaScript操作XML文档的黄金法则

# 摘要
本文全面探讨了XML和DOM的基础概念、操作与解析,以及在现代Web开发中的应用和高级技巧。首先,文章介绍了XML和DOM的基本知识,随后深入JavaScript中DOM操作和XML文档解析的技术细节。接着,文章通过实践活动介绍了XML数据交互和操作,强调了事件处理在动态用户界面构建中的重要
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )