如何使用Spark构建实时数据处理流水线
发布时间: 2023-12-16 20:31:49 阅读量: 35 订阅数: 49 

如何基于SparkStreaming构建实时计算平台
# 1. 引言
## 1.1 什么是实时数据处理流水线
实时数据处理流水线是指一套由数据采集、数据处理、数据存储和数据可视化构成的完整流程,能够实时地处理和分析不断产生的数据流。通过实时数据处理流水线,我们可以及时发现数据中的模式、趋势和异常,为业务决策提供及时支持。
## 1.2 Spark的优势和应用场景
Apache Spark是一个快速、通用的大数据处理引擎,具有内存计算能力和容错机制,并提供了丰富的API,支持多种数据处理场景,如批处理、实时流处理、机器学习和图计算等。在实时数据处理流水线中,Spark可以通过其强大的实时流处理引擎Spark Streaming,结合丰富的数据处理库和易用的API,实现高效的实时数据处理和分析。
在实时数据处理流水线中,Spark常见的应用场景包括实时日志分析、实时推荐系统、实时欺诈检测、实时监控系统等。其高性能、易用性和灵活性使得Spark成为实时数据处理的首选引擎之一。
# 2. 搭建Spark环境
在构建实时数据处理流水线之前,我们首先需要搭建一个可运行Spark的环境。本章将介绍Spark的安装、配置Spark集群以及确认环境搭建是否成功的方法。
### 2.1 安装Spark
要在本地机器上安装Spark,我们需要按照以下步骤进行操作:
1. 访问Spark官方网站(https://spark.apache.org/downloads.html)下载Spark的最新版本。
2. 解压Spark压缩包到您选择的目录中。
3. 配置Spark环境变量。在`~/.bashrc`或`~/.bash_profile`文件中添加以下行:
```
export SPARK_HOME=/path/to/spark
export PATH=$PATH:$SPARK_HOME/bin
```
请将`/path/to/spark`替换为您解压Spark的目录路径。
4. 刷新bash配置文件:`source ~/.bashrc`或`source ~/.bash_profile`。
5. 使用`spark-shell`命令验证Spark是否安装成功。
### 2.2 配置Spark集群
如果您要搭建一个Spark集群环境,可以按照以下步骤进行操作:
1. 在集群中的每台机器上安装和配置相同版本的Spark。
2. 在Spark的`conf`目录中创建一个`spark-env.sh`文件,并在其中设置以下环境变量:
```
export SPARK_MASTER_HOST=<master-node-ip>
export SPARK_MASTER_PORT=<master-node-port>
export SPARK_WORKER_CORES=<number-of-cores-per-worker>
export SPARK_WORKER_MEMORY=<memory-amount-per-worker>
```
请将`<master-node-ip>`替换为Spark主节点的IP地址,将`<master-node-port>`替换为Spark主节点的端口号,将`<number-of-cores-per-worker>`替换为每个工作节点的核心数,将`<memory-amount-per-worker>`替换为每个工作节点的可用内存数。
3. 配置主节点和工作节点的IP地址。在Spark的`conf`目录中的`slaves`文件中添加每个工作节点的IP地址,每个IP地址一行。
4. 启动Spark集群。在Spark的安装目录中运行以下命令:
```
./sbin/start-master.sh
./sbin/start-workers.sh
```
这将启动Spark的主节点和工作节点。
5. 您可以访问Spark的Web界面(默认为http://<master-node-ip>:8080)来确认集群是否启动成功。
### 2.3 确认环境搭建是否成功
为了确认我们的Spark环境搭建成功,我们可以通过简单的代码来进行验证。在命令行中输入以下命令:
```
spark-shell
```
这将启动Spark的交互式Shell。在Spark Shell中,输入以下代码:
```scala
val data = Array(1, 2, 3, 4, 5)
val rdd = spark.sparkContext.parallelize(data)
val sum = rdd.reduce(_ + _)
println("Sum of the elements in the RDD: " + sum)
```
这段代码将创建一个包含整数的数组,并将其转化为一个RDD(弹性分布式数据集)。然后,我们使用`reduce`操作来计算RDD中元素的和,并将其打印出来。如果一切正常,您将看到以下输出:
```
Sum of the elements in the RDD: 15
```
这表示您的Spark环境已经成功搭建,并且可以执行基本的Spark操作。
在本章中,我们介绍了如何安装Spark、配置Spark集群以

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏旨在帮助读者全面掌握Spark基础知识,并深入了解其各种应用场景和技术细节。从安装开始,我们将详细介绍Spark的基本概念和核心特性,包括RDD和计算模型等。同时,我们还将重点讲解Spark中的转换操作,如map、filter、reduce以及性能优化技巧和策略,以及Broadcast变量的使用方法。接着,我们将深入讨论Spark中的键值对操作、DataFrame和DataSet的数据处理方式,以及Spark SQL进行数据查询与分析的技巧。此外,我们还将介绍Spark Streaming的基础知识和机器学习库MLlib的使用方法,并讨论Spark在批处理数据挖掘、推荐系统、图计算、文本处理、图像处理等领域的应用。最后,我们将探讨Spark与Hadoop、Kafka的整合,并讲解机器学习管道与特征工程的应用技巧。通过本专栏的学习,读者将全面掌握Spark技术,并对大数据处理、实时数据处理等领域有深入的理解和实践能力。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
PyroSiM中文版模拟效率革命:8个实用技巧助你提升精确度与效率
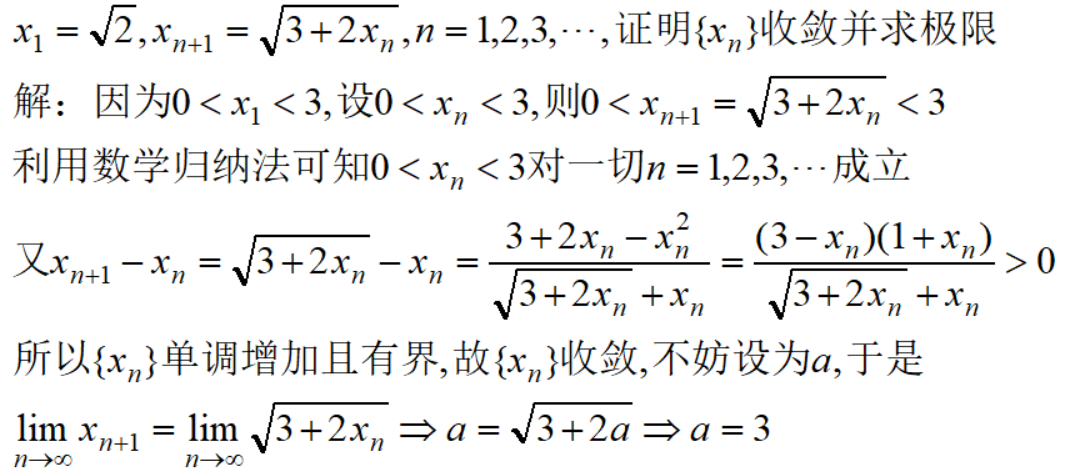
# 摘要
PyroSiM是一款强大的模拟软件,广泛应用于多个领域以解决复杂问题。本文从PyroSiM中文版的基础入门讲起,逐渐深入至模拟理论、技巧、实践应用以及高级技巧与进阶应用。通过对模拟理论与效率提升、模拟模型精确度分析以及实践案例的探讨,本文旨在为用户提供一套完整的PyroSiM使用指南。文章还关注了提高模拟效率的实践操作,包括优化技巧和模拟工作流的集成。高级
QT框架下的网络编程:从基础到高级,技术提升必读
# 摘要
QT框架下的网络编程技术为开发者提供了强大的网络通信能力,使得在网络应用开发过程中,可以灵活地实现各种网络协议和数据交换功能。本文介绍了QT网络编程的基础知识,包括QTcpSocket和QUdpSocket类的基本使用,以及QNetworkAccessManager在不同场景下的网络访问管理。进一步地,本文探讨了QT网络编程中的信号与槽
优化信号处理流程:【高效傅里叶变换实现】的算法与代码实践

# 摘要
傅里叶变换是现代信号处理中的基础理论,其高效的实现——快速傅里叶变换(FFT)算法,极大地推动了数字信号处理技术的发展。本文首先介绍了傅里叶变换的基础理论和离散傅里叶变换(DFT)的基本概念及其计算复杂度。随后,详细阐述了FFT算法的发展历程,特别是Coo
MTK-ATA核心算法深度揭秘:全面解析ATA协议运作机制

# 摘要
本文深入探讨了MTK-ATA核心算法的理论基础、实践应用、高级特性以及问题诊断与解决方法。首先,本文介绍了ATA协议和MTK芯片架构之间的关系,并解析了ATA协议的核心概念,包括其命令集和数据传输机制。其次,文章阐述了MTK-ATA算法的工作原理、实现框架、调试与优化以及扩展与改进措施。此外,本文还分析了MTK-ATA算法在多
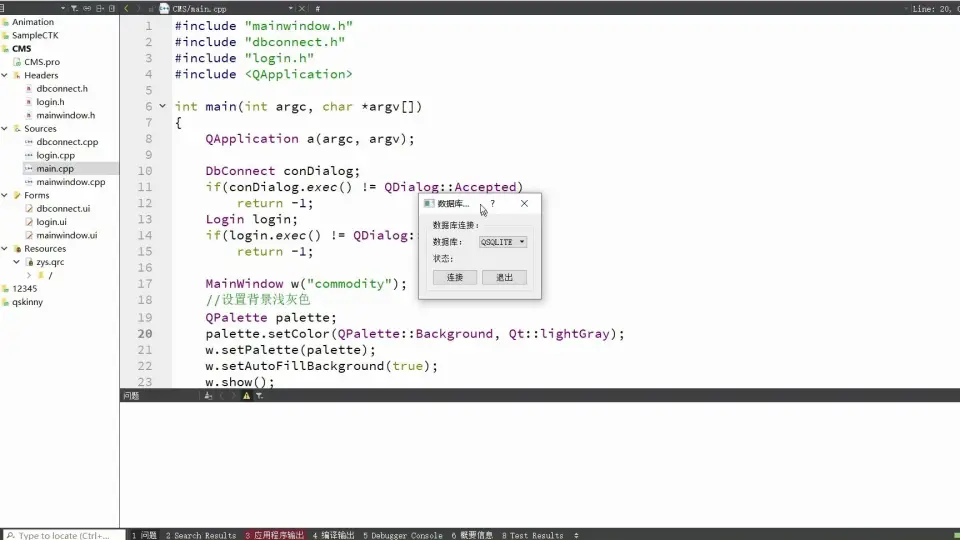
【MIPI摄像头与显示优化】:掌握CSI与DSI技术应用的关键
# 摘要
本文全面介绍了MIPI摄像头与显示技术,从基本概念到实际应用进行了详细阐述。首先,文章概览了MIPI摄像头与显示技术的基础知识,并对比分析了CSI与DSI标准的架构、技术要求及适用场景。接着,文章探讨了MIPI摄像头接口的配置、控制、图像处理与压缩技术,并提供了高级应用案例。对于MIPI显示接口部分,文章聚焦于配置、性能调优、视频输出与图形加速技术以及应用案例。第五章对性能测试工具与
揭秘PCtoLCD2002:如何利用其独特算法优化LCD显示性能

# 摘要
PCtoLCD2002作为一种高性能显示优化工具,在现代显示技术中占据重要地位。本文首先概述了PCtoLCD2002的基本概念及其显示性能的重要性,随后深入解析了其核心算法,包括理论基础、数据处理机制及性能分析。通过对算法的全面解析,探讨了算法如何在不同的显示设备上实现性能优化,并通过实验与案例研究展示了算法优化的实际效果。文章最后探讨了PCtoLCD2002算法的进阶应用和面临
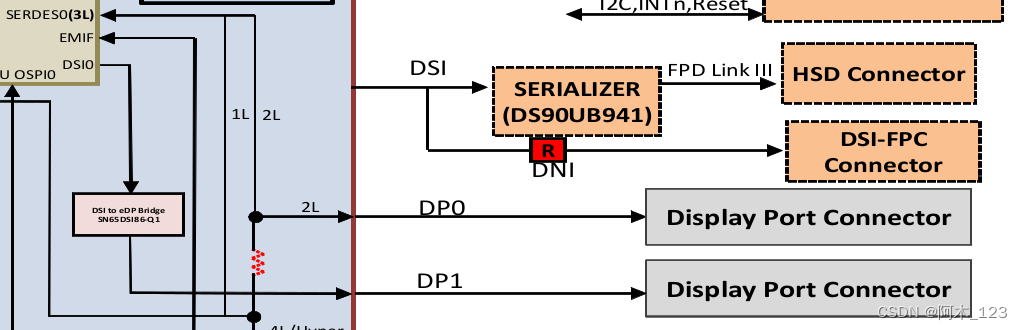
DSP系统设计实战:TI 28X系列在嵌入式系统中的应用(系统优化全攻略)
# 摘要
TI 28X系列DSP系统作为一种高性能数字信号处理平台,广泛应用于音频、图像和通信等领域。本文旨在提供TI 28X系列DSP的系统概述、核心架构和性能分析,探讨软件开发基础、优化技术和实战应用案例。通过深入解析DSP系统的设计特点、性能指标、软件开发环境以及优化策略,本文旨在指导工程师有效地利用DSP系统的
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )