【find命令的限制与替代方案】:当find不够用时的解决方案
发布时间: 2024-09-27 12:27:45 阅读量: 75 订阅数: 30 

AndroidStudio构建项目提示“unable to find valid certification”最新解决方案

# 1. find命令的介绍与基本使用
Unix-like 系统中,`find` 命令是强大的文件搜索工具,可用于在文件系统中查找符合特定条件的文件或目录。在本章中,我们将介绍 `find` 命令的基本概念和基本使用方法。
## 基本概念
`find` 命令的基本语法如下:
```bash
find [路径] [选项] [测试条件] [动作]
```
其中:
- **路径**:指定开始搜索的目录。
- **选项**:改变 `find` 命令的行为,例如 `-name`、`-type`、`-size` 等。
- **测试条件**:根据特定条件过滤搜索结果,例如文件名、类型、大小等。
- **动作**:对找到的文件执行的操作,如打印路径、删除文件等。
## 常见使用案例
1. **按文件名搜索**:
要查找名为 `example.txt` 的文件,可以使用:
```bash
find /path/to/search -type f -name example.txt
```
这里 `-type f` 表示搜索的类型为文件。
2. **按文件大小搜索**:
查找大于 1MB 的文件:
```bash
find /path/to/search -type f -size +1M
```
`-size +1M` 表示匹配大于1MB的文件。
3. **对搜索结果执行操作**:
删除所有 `.log` 结尾的文件:
```bash
find /path/to/search -type f -name "*.log" -exec rm {} \;
```
这里的 `-exec rm {} \;` 是对每个找到的文件执行 `rm` 命令。
通过这些基础实例,我们可以看到 `find` 命令的灵活性和实用性。在接下来的章节中,我们将深入探讨 `find` 命令的高级用法和最佳实践。
# 2. find命令的限制分析
## 2.1 find命令的局限性
### 2.1.1 性能瓶颈
`find` 命令虽然功能强大,但在处理大型文件系统时可能遇到性能瓶颈。随着文件数量的增加,搜索时间线性增长,特别是在没有索引机制的情况下。对于含有数以万计文件的目录,`find` 需要花费较长的时间来遍历每一个文件,这直接限制了其在大容量存储上的应用。此外,当搜索涉及复杂的模式匹配时,性能下降得更快,因为需要评估每个文件是否符合指定的搜索条件。
```bash
time find / -type f -name "*.log" -print 2>/dev/null
```
上面的命令会搜索根目录 `/` 下所有的 `.log` 文件,并打印它们的路径。在执行过程中,我们可能会观察到随着目录深度和文件数量的增加,该命令的执行时间大幅增长。
### 2.1.2 功能不足的场景
在某些场景下,`find` 命令可能无法提供所需的全部功能。比如,`find` 不支持基于文件内容的全文搜索,无法直接定位具有特定内容的文件。对于这类需求,用户不得不借助如 `grep` 这样的工具来辅助完成任务。再者,`find` 默认输出的格式通常只包括文件名,如果需要更多的文件属性信息,还需要额外的命令来处理,比如结合 `ls` 或 `stat` 命令。
```bash
find /var/log -type f -exec grep "error" {} \; -print
```
上述命令尝试使用 `find` 和 `grep` 结合的方式查找 `/var/log` 目录下包含 "error" 文本的文件。然而,这需要遍历所有文件,并在每个文件上运行 `grep`,效率较低。
## 2.2 环境因素对find的影响
### 2.2.1 文件系统的限制
不同的文件系统具有不同的特性和限制,这些限制可能会对 `find` 命令的性能和功能产生影响。例如,某些文件系统可能不支持某些文件属性的查询,或者查询速度较慢。例如,搜索具有扩展属性的文件在某些文件系统上可能无法使用 `find` 来直接完成。
```bash
# 检查支持的文件类型
find / -fstype ext4 -type f -print 2>/dev/null
```
这个命令尝试列出所有在 `ext4` 文件系统上的文件。如果执行失败,可能说明当前环境对 `find` 命令的某些操作有限制。
### 2.2.2 权限和所有权问题
在多用户环境中,文件和目录的权限与所有权设置可能会对 `find` 命令产生重要影响。如果用户没有足够的权限访问某个目录或文件,`find` 将无法搜索到这些资源。此外,用户可能需要以 root 用户身份来执行 `find`,以便获得对系统上所有文件的访问权限,但这样做会带来安全风险。
```bash
# 尝试以普通用户身份执行find
find /root -type f -print
```
如果普通用户尝试执行上述命令,可能会收到权限拒绝的错误消息,因为 `/root` 目录一般只对 root 用户开放。
## 2.3 find命令的潜在风险
### 2.3.1 安全隐患
使用 `find` 命令时,如果不小心指定了错误的搜索模式或路径,可能会意外地修改或删除重要文件。尤其是当使用 `-delete` 选项时,如果没有恰当的筛选条件,可能会导致数据丢失。另外,`find` 命令的执行结果可能被恶意用户利用,特别是当输出包含敏感信息时。
```bash
# 示例:不当的使用 -delete 选项
find /home -name "*.bak" -delete
```
执行这个命令将删除 `/home` 目录下所有的 `.bak` 备份文件。如果路径选择不当,可能会删除重要文件。
### 2.3.2 数据一致性问题
`find` 命令在搜索时可能面临数据一致性问题。尤其是在文件系统动态变化的情况下(例如,当文件正在被移动或重命名),`find` 可能返回不一致的搜索结果。在数据一致性要求较高的场景下,必须采取额外的措施以确保搜索结果的准确性。
```bash
# 示例:可能返回不一致结果的命令
find / -type f -name "important_file" -print 2>/dev/null
```
如果在搜索的过程中,名为 `important_file` 的文件正在被移动或删除,`find` 可能会返回错误或不一致的结果。
通过上述内容的分析,我们理解了 `find` 命令在不同环境和场景下可能遇到的限制和潜在风险。这为我们在实际应用中如何更加谨慎和高效地使用 `find` 命令提供了必要的背景知识。在下一章节中,我们将探讨 `find` 的替代方案和技巧,以应对这些挑战。
# 3. 替代find的工具与技巧
## 3.1 常用的find替代工具
### 3.1.1 locate和updatedb的使用
`locate` 是一个快速的文件搜索工具,它通过预先建立的数据库来进行文件查询,这个数据库是由 `updatedb` 命令定期更新的。与 `find` 相比,`locate` 的优势在于其速度,特别是对于需要频繁搜索大量文件的场景。然而,`locate` 也有局限性,它不能实时更新文件系统变化,因此对于最近新增或删除的文件可能不准确。
下面是 `locate` 和 `updatedb`

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
在 Linux 系统中,find 命令是一个强大的搜索工具,可用于查找文件和目录。本专栏提供了一个全面的指南,涵盖了从初学者到高级用户的各种用法。
对于初学者,专栏介绍了 find 命令的基本用法,例如按名称、类型或大小搜索文件。它还提供了高级技巧,例如使用正则表达式进行复杂搜索和优化搜索性能。
此外,专栏还深入探讨了 find 命令的文本搜索功能,介绍了三种方法来匹配文本内容。这对于查找包含特定字符串或模式的文件非常有用。
通过阅读本专栏,您将掌握 find 命令的全部功能,并能够有效地搜索 Linux 系统中的文件和目录。无论您是 Linux 新手还是经验丰富的用户,本指南都将帮助您提升您的搜索效率。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【LAMMPS初探】:如何快速入门并掌握基本模拟操作

# 摘要
LAMMPS模拟软件因其在分子动力学领域的广泛应用而著称,本文提供了关于如何安装、配置和使用LAMMPS进行基本和高级模拟操作的全面指南。文章首先介绍了LAMMPS的系统环境要求、安装流程以及配置选项,并详细说明了运行环境的设置方法。接着,重点介绍了LAMMPS进行基本模拟操作的核心步骤,包括模拟体系的搭建、势能的选择与计算,以及模拟过程的控制。此外,还探讨了高级模拟技术,如分子动力学进阶应用
安全第一:ELMO驱动器运动控制安全策略详解

# 摘要
ELMO驱动器作为运动控制领域内的关键组件,其安全性能的高低直接影响整个系统的可靠性和安全性。本文首先介绍了ELMO驱动器运动控制的基础知识,进而深入探讨了运动控制系统中的安全理论,包括安全运动控制的定义、原则、硬件组件的作用以及软件层面的安全策略实现。第三章到第五章详细阐述了ELMO驱动器安全功能的实现、案例分析以及实践指导,旨在为技术人
编程新手福音:SGM58031B编程基础与接口介绍

# 摘要
SGM58031B是一款具有广泛编程前景的设备,本文首先对其进行了概述并探讨了其编程的应用前景。接着,详细介绍了SGM58031B的编程基础,包括硬件接口解析、编程语言选择及环境搭建,以及基础编程概念与常用算法的应用。第三章则着重于软件接口和驱动开发,阐述了库文件与API接口、驱动程序的硬件交互原理,及驱动开发的具体流程和技巧。通过实际案例
【流程标准化实战】:构建一致性和可复用性的秘诀

# 摘要
本文系统地探讨了流程标准化的概念、重要性以及在企业级实践中的应用。首先介绍了流程标准化的定义、原则和理论基础,并分析了实现流程标准化所需的方法论和面临的挑战。接着,本文深入讨论了流程标准化的实践工具和技术,包括流程自动化工具的选择、模板设计与应用,以及流程监控和质量保证的策略。进一步地,本文探讨了构建企业级流程标准化体系的策略,涵盖了组织结构的调整、标准化实施
【ER图设计速成课】:从零开始构建保险公司全面数据模型
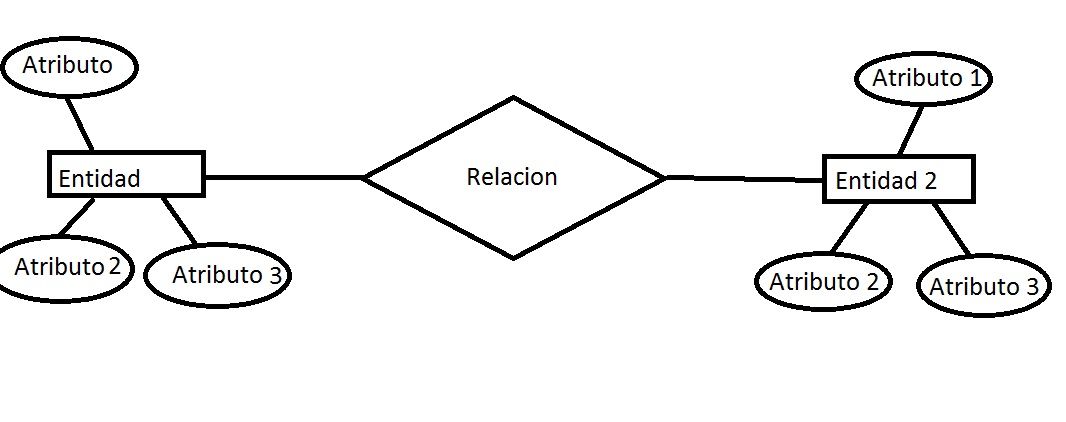
# 摘要
本文详细介绍了实体-关系图(ER图)在保险公司业务流程中的设计和应用。通过理解保险业务流程,识别业务实体与关系,并在此基础上构建全面的数据模型,本文阐述了ER图的基本元素、规范化处理、以及优化调整的策略。文章还讨论了ER图设计实践中的详细实体设计、关系实现和数据模型文档化方法。此外,本文探讨了ER图在数据库设计中的应用,包括ER图到数据库结构的映射、
揭秘Renewal UI:3D技术如何重塑用户体验
![[Renewal UI] Chapter4_3D Inspector.pdf](https://habrastorage.org/getpro/habr/upload_files/bd2/ffc/653/bd2ffc653de64f289cf726ffb19cec69.png)
# 摘要
本文首先介绍了Renewal UI的创新特点及其在三维(3D)技术中的应用。随后,深入探讨了3D技术的基础知识,以及它在用户界面(UI)设计中的作用,包括空间几何、纹理映射、交互式元素设计等。文中分析了Renewal UI在实际应用中的案例,如交互设计实践、用户体验定性分析以及技术实践与项目管理。此外,
【信息化系统建设方案编写入门指南】:从零开始构建你的第一个方案

# 摘要
信息化系统建设是现代企业提升效率和竞争力的关键途径。本文对信息化系统建设进行了全面概述,从需求分析与收集方法开始,详细探讨了如何理解业务需求并确定需求的优先级和范围,以及数据收集的技巧和分析工具。接着,本文深入分析了系统架构设计原则,包括架构类型的确定、设计模式的运用,以及安全性与性能的考量。在实施与部署方面,本文提供了制定实施计划、部署策
【多核与并行构建】:cl.exe并行编译选项及其优化策略,加速构建过程
# 摘要
本文系统地介绍了多核与并行构建的基础知识,重点探讨了cl.exe编译器在多核并行编译中的理论基础和实践
中文版ARINC653:简化开发流程,提升航空系统软件效率

# 摘要
ARINC653标准作为一种航空系统软件架构,提供了模块化设计、时间与空间分区等关键概念,以增强航空系统的安全性和可靠性。本文首先介绍了ARINC653的定义、发展、模块化设计原则及其分区机制的理论基础。接着,探讨了ARINC653的开发流程、所需开发环境和工具,以及实践案例分析。此外,本文还分析了ARINC653在航空系统中的具体应用、软件效率提升
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )