【编译器性能提升指南】:优化技术的关键步骤揭秘
发布时间: 2024-12-28 02:40:04 阅读量: 12 订阅数: 14 

HGWO-SVR:采用差分进化(DE)改进原始的灰狼优化(GWO)得到HGWO(DE-GWO)算法,以优化SVR参数,对风速进行时序预测 matlab版本,有详细中文注释,可根据自己需求方便修改
# 摘要
编译器性能优化对于提高软件执行效率和质量至关重要。本文详细探讨了编译器前端和后端的优化技术,包括前端的词法与语法分析优化、静态代码分析和改进以及编译时优化策略,和后端的中间表示(IR)优化、指令调度与并行化技术、寄存器分配与管理。同时,本文还分析了链接器和运行时优化对性能的影响,涵盖了链接时代码优化、运行时环境的性能提升和调试工具的应用。最后,通过编译器优化案例分析与展望,本文对比了不同编译器的优化效果,并探索了机器学习技术在编译优化中的应用,为未来的优化工作指明了方向。
# 关键字
编译器优化;前端优化;后端优化;静态分析;指令调度;寄存器分配
参考资源链接:[编译原理第二版:逆波兰表达式与语法分析](https://wenku.csdn.net/doc/6412b62ebe7fbd1778d45ce6?spm=1055.2635.3001.10343)
# 1. 编译器性能优化概述
在现代编程中,编译器承担着将高级语言转换为机器语言的关键任务。性能优化是编译器设计中的一个关键环节,它直接影响着应用程序的运行效率和资源使用。编译器性能优化可以分为前端优化和后端优化两大类,前端优化侧重于理解源代码并生成中间表示(IR),而后端优化则致力于将IR转化为高效的机器代码。有效的性能优化不仅涉及算法和数据结构的优化,还涉及对特定硬件特性的充分利用。本文将探讨编译器性能优化的整体框架,为读者提供深入理解优化技术的途径。
# 2. 编译器前端优化技术
## 2.1 词法和语法分析优化
### 2.1.1 优化的词法分析器设计
词法分析是编译过程的第一步,其主要任务是将源代码的字符序列转换为有意义的词素序列,这些词素是编译器进一步处理的最小单位。设计一个高效的词法分析器是提高编译器前端性能的关键。
在优化词法分析器设计时,需要考虑到以下几个方面:
1. **消除冗余的回溯**:在传统的词法分析器设计中,为了处理复杂的正则表达式,可能需要频繁地回溯字符流。优化的方法是采用确定性有限自动机(DFA)来替换非确定性有限自动机(NFA),从而避免不必要的回溯。
2. **状态压缩**:对于拥有大量状态的DFA,状态空间可能会非常庞大。通过状态压缩技术,可以减少存储和计算的需求。
3. **生成器模式**:使用生成器模式来逐个产生词素,这可以避免一次性构建整个词素表,从而减少内存使用。
以下是一个简单的词法分析器代码示例,展示了如何使用DFA来避免不必要的回溯:
```python
import re
# DFA 状态定义
states = {
'start': {
'if': 'if_keyword',
'int': 'int_keyword',
# ... 其他关键字或符号的处理
'default': 'identifier',
},
'if_keyword': {
# ... 如果下一个字符是空格或符号,则完成处理
},
# ... 其他状态的定义
}
# 词法分析函数
def lexical_analysis(code):
current_state = 'start'
token = ''
for char in code:
if current_state in states:
current_state = states[current_state].get(char, 'default')
else:
current_state = 'default'
# 如果状态为 'default',则认为当前字符开始新的词素
if current_state == 'default':
if token:
yield token
token = char
else:
token += char
if token:
yield token
# 示例代码字符串
code = "if (i < 10) { int n; n = 5; }"
# 进行词法分析
for token in lexical_analysis(code):
print(token)
```
在上述示例中,`states` 字典定义了不同的状态以及当输入字符匹配时的状态转移。通过避免回溯,这个简化的词法分析器在处理输入时会更加高效。
### 2.1.2 高效语法分析算法的选择
语法分析的任务是基于词法单元流建立语法结构,通常采用上下文无关文法(CFG)。选择和实现一个高效的语法分析算法对于编译器性能至关重要。
1. **LL(k) 和 LR(k) 算法**:LL(k) 是一种自顶向下的解析策略,而 LR(k) 是一种自底向上的策略。对于现代编译器而言,LR(k) 类型的解析器因其强大的错误检测和恢复能力而更受青睐。其中,LR(1) 是最常用的一种,而更复杂的 LALR(1) 和 GLR 算法则在实际中也有广泛应用。
2. **Earley 解析器**:对于包含复杂左递归的文法,Earley 解析器能够有效处理,尽管其性能相比 LR 类解析器有所下降,但其通用性和健壮性使得它在某些场景下成为更好的选择。
3. **增量解析**:在处理大型项目或者需要快速响应的场景下,增量解析可以用来更新和重用之前的分析结果,只对发生变化的部分进行重新分析,从而节省资源。
下面展示了一个简单的 LL(1) 解析器的框架:
```python
class LL1Parser:
def __init__(self, grammar):
self.grammar = grammar
self.first = self.calculate_first()
self.follow = self.calculate_follow()
self.parse_table = self.create_parse_table()
def calculate_first(self):
# 计算文法的FIRST集合
pass
def calculate_follow(self):
# 计算文法的FOLLOW集合
pass
def create_parse_table(self):
# 创建解析表
pass
def parse(self, tokens):
# 解析输入tokens
pass
# 示例文法
grammar = {
'S': ['AB'],
'A': ['aA', 'a'],
'B': ['b'],
}
# 创建解析器实例并进行解析
parser = LL1Parser(grammar)
tokens = ['a', 'a', 'b']
result = parser.parse(tokens)
```
在这个框架中,`calculate_first` 和 `calculate_follow` 方法用于计算文法的 FIRST 和 FOLLOW 集合,这对于构造 LL(1) 解析表至关重要。`parse` 方法则负责使用解析表来处理输入的 token 序列。
## 2.2 静态代码分析和改进
### 2.2.1 静态分析工具的原理与应用
静态代码分析是在不执行程序的情况下,对源代码进行分析的过程。它旨在发现代码中的错误、不规范之处、性能瓶颈等。静态分析工具有时被用来在编译阶段提前发现运行时错误,并辅助开发者改进代码质量。
1. **数据流分析**:分析程序中变量的定义和使用情况,以检测潜在的错误,如变量使用前未定义等。
2. **控制流分析**:构建程序的控制流图(CFG),分析程序的执行路径,有助于发现循环结构中的问题或者潜在的死循环。
3. **抽象解释**:通过抽象的语义域来分析程序的行为,可以用来检测程序是否满足特定的属性。
4. **类型检查**:对程序中使用的数据类型进行分析,确保类型正确性和一致性。
静态分析工具的实现往往依赖于上述技术,它们可以集成到开发环境(IDE)中,提供实时反馈,或者在代码提交前进行集成测试。
### 2.2.2 代码重写的策略与实践
代码重写是静态代码分析的一个重要应用,它涉及将代码转换成等价的、更高效的或更易于维护的形式。在某些情况下,它还包括简化复杂的代码逻辑,或者将特定模式的代码转换成标准模式。
1. **循环优化**:包括循环展开、循环合并、循环分割等技术,旨在减少循环控制的开销,提高数据的局部性。
2. **条件判断优化**:通过调整条件判断的顺序或逻辑,减少分支的复杂度,提高预测准确性。
3. **死代码消除**:识别并移除永远不可能被执行到的代码,减少程序的大小和执行时间。
4. **内联函数**:将函数调用替换为函数体的副本,以减少函数调用的开销。
代码重写的实现通常需要对源代码进行精确的解析,并在保持语义一致的前提下修改代码结构。以下是一个简单的 Python 示例,演示了基本的条件判断优化:
```python
# 原始代码
if user_age >= 21:
allow_entry = True
else:
allow_entry = False
# 优化后的代码
allow_entry = user_age >= 21
# 或者使用更简洁的方式
allow_entry = user_age >= 21
# 代码逻辑分析
# 上述优化简化了条件判断逻辑,去掉了冗余的变量赋值操作。
# 在条件表达式后直接进行赋值,代码更加简洁易读。
```
通过这种方式,我们不仅减少了代码的复杂度,也提高了代码的执行效率。
# 3. 编译器后端优化技术
## 3.1 中间表示(IR)的选择与优化
### 3.1.1 选择合适的中间表示形式
中间表示(Intermediate Representation,简称IR)是编译器设计中的核心概念之一,它作为一种在源代

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《编译原理第二版课后答案》专栏深入剖析了编译器的各个方面,为读者提供了全面的编译原理知识。从词法分析器设计到内存管理,再到编译器优化和错误处理,专栏涵盖了编译器构建和优化的各个关键步骤。通过深入的讲解和丰富的示例,读者可以掌握编译器的前端工具链、解析策略、符号表管理、数据流分析和代码优化技术。专栏还提供了自动化词法分析器、寄存器分配和代码调度等高级技巧,帮助读者全面了解编译器的内部运作原理,并提升代码性能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
高光谱图像降维对比分析:PCA与多线性分析的终极对决
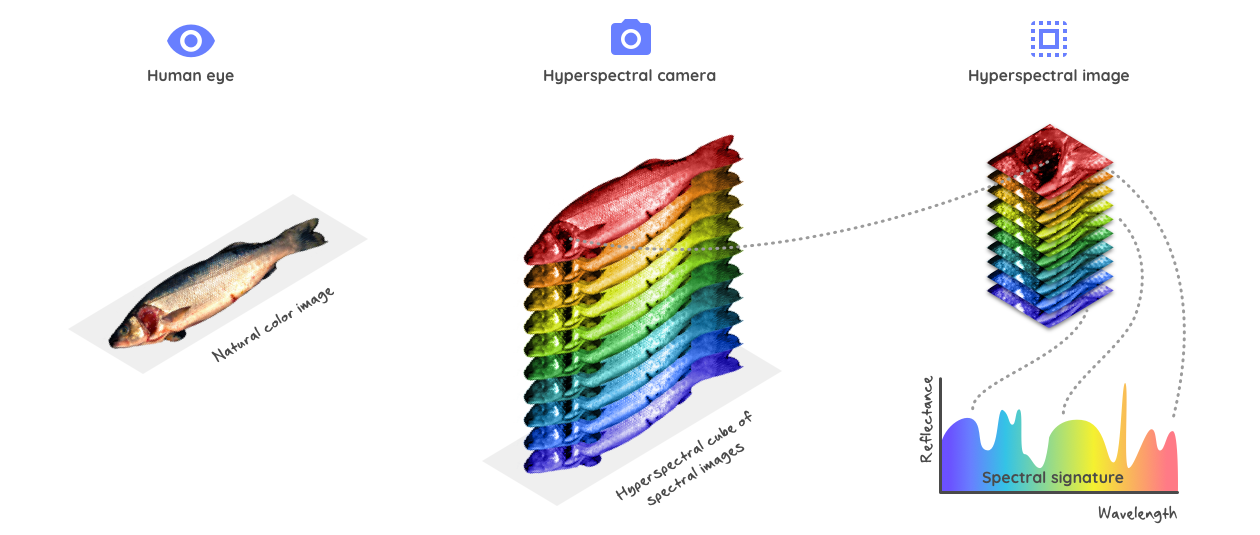
# 摘要
高光谱图像降维是遥感领域的一个关键技术和挑战,涉及到数据压缩、特征提取和图像分析。本文分别介绍了主成分分析(PCA)和多线性分析两种降维技术的原理和应用,包括它们的理论基础、实践操作以及评估与优化方法。通过对比实验,文章分析了PCA和多线性分析在高光谱数据处理中的优缺点,并对不同降维方法的实验结果进行了讨论。最后,本文展望了高光谱图像降维技术的未来发展趋势,探讨了其局限性、潜在
数字信号处理中的窗口函数:如何选择与应用,专家指南

# 摘要
数字信号处理广泛应用于多个领域,其中窗口函数起着至关重要的作用。本文回顾了数字信号处理的基础知识,并详细探讨了窗口函数的理论基础、作用原理以及选择标准。通过分析窗口函数在频谱分析、滤波器设计和信号变换中的应用,本文揭示了窗口函数如何影响信号处理的质量和精度。进一步的章节涵盖了多重窗口技术、自适应窗口技术以及
【MIPI DSI调试技术】:问题定位与性能优化的方法论,打造完美显示体验

# 摘要
随着移动设备显示性能要求的不断提升,MIPI DSI技术作为高效连接显示面板的关键接口,其优化和调试策略显得尤为重要。本文从MIPI DSI技术的基本概念出发,详细分析了DSI接口的信号电气特性和协议构成,并探讨了通信流程的关键环节。进而,本文深入研究了DSI调试与问题定位的实用方法,并提供了性能优化
【华为折叠屏应用稳定性测试必杀技】:确保折叠屏上的应用无懈可击

# 摘要
本文旨在详细介绍华为折叠屏技术,并探讨其理论基础、稳定性测试方法以及实际应用测试案例。文章首先概述了折叠屏技术的基本原理和优势,强调了应用稳定性在用户体验中的重要性,并分析了当前测试框架和工具的选择。随后,文章深入探讨了华为折叠屏应用稳定性测试的方法,包括自动化测试策略、性能
【AST2400 BMC问题诊断手册】:快速定位并解决故障的步骤
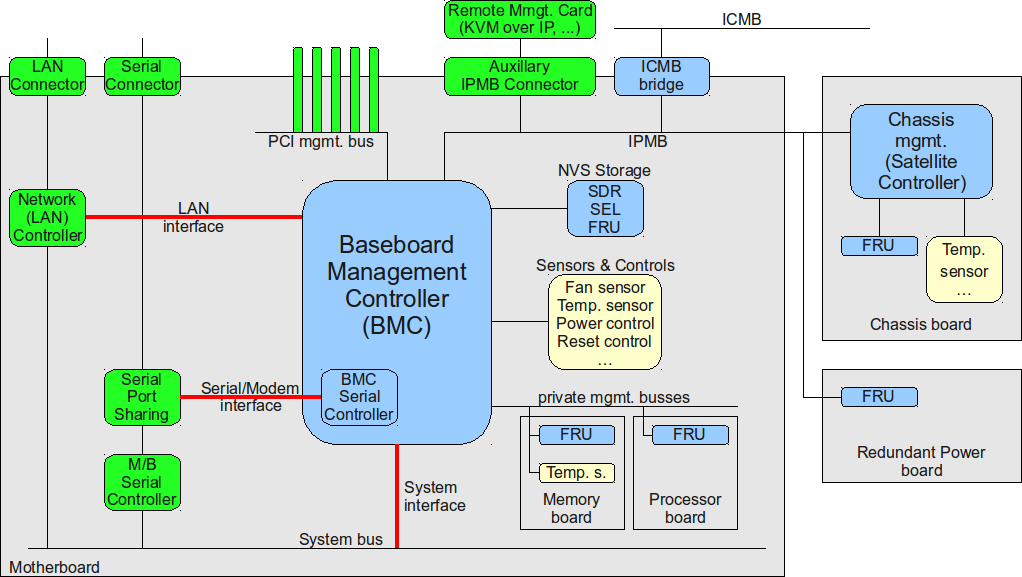
# 摘要
随着信息技术的发展,基础管理工作站(BMC)在服务器和嵌入式系统的远程监控与管理中扮演了至关重要的角色。本文详细介绍了BMC的基础知识、故障诊断的理论基础、实践指南、深入的诊断技巧,以及案例实战分析。文中从BMC的硬件和软件架构出发,讨论了故障诊断的基本原则和性能监控方法,提供了常见故障类型及案例分析,并进一步探讨了命令行诊断技巧、固件更新、
【主成分分析入门】:掌握PCA在故障诊断中的关键应用
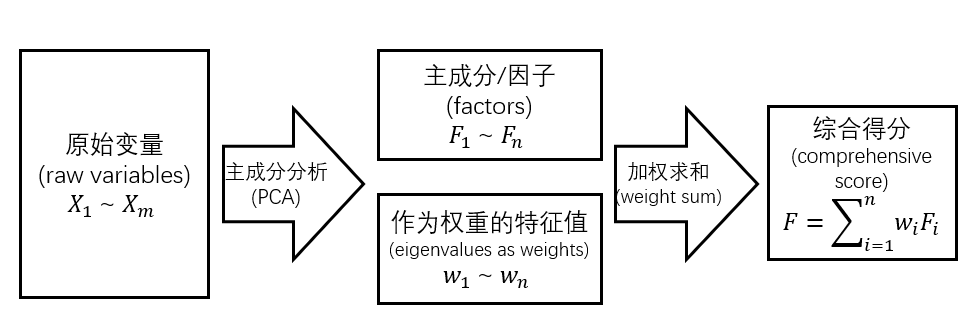
# 摘要
主成分分析(PCA)作为一种强大的统计工具,广泛应用于数据降维和特征提取。本文首先介绍了PCA的理论基础及其数学原理,包括数据降维的必要性、方差和协方差矩阵的作用、主成分的提取过程以及主成分得分的计算。其次,文章探讨了PCA在故障诊断中的应用,详细说明了故障诊断的基本概念、PCA在故障检测中的角色,并通过案例分析展示了PCA模型的实际操作和结果解读。此外,本文还提供了PCA实践操作的指南,指导读者如何选择合适的软件工
【自动化测量新时代】:GeoCOM脚本编写技巧,提升工作效率

# 摘要
GeoCOM脚本作为一种用于地理信息系统的编程语言,提供了强大的自动化处理和数据交互功能。本文从GeoCOM脚本的基础知识入手,深入探讨其结构和语法,包括核心组成部分、控制结构、输入输出操作。接着,文章重点介绍了高级编程技巧,如错误处理、复杂数据处理以及与外部系统的集成方法。在实际应用方面,本文详细阐述了GeoCOM脚本在自动化测量中的应用,包括地理信息系统的自动化任务、自动化测试和实时数据监控与警报
Android自定义View与table布局的结合:创造独特的界面元素
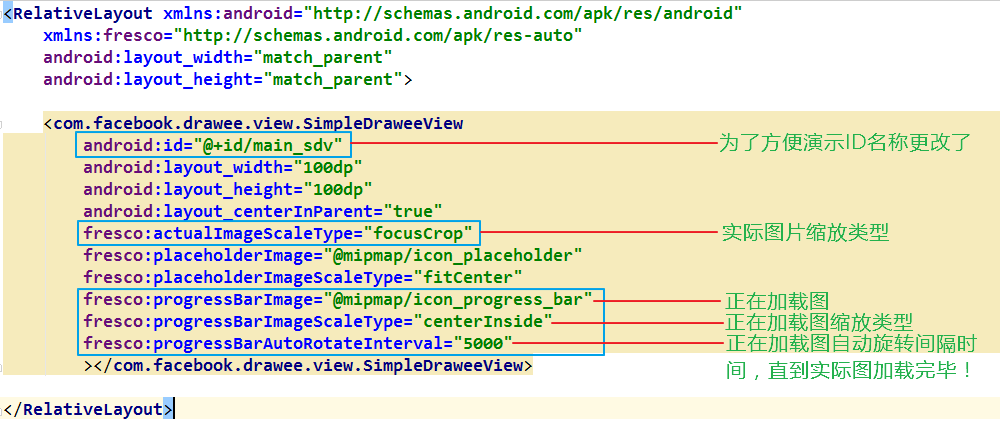
# 摘要
本文全面介绍了Android自定义View的开发基础、深入理解table布局以及如何将这些知识应用于实际开发中。首先,概述了自定义View的基本概念和table布局的核心原理。其次,通过具体案例讲解了如何设计基础结构、实现自定义View与table布局的结合,并提供了优化绘制性能的实践技巧。第三部分深入探讨了交互式自定义View的事件处理、动态效果的实现与性能调优,以及创造性布局的案例分析。最后一章涵盖了自定义Vie
移动存储新纪元:EMMC在移动设备中的创新应用案例
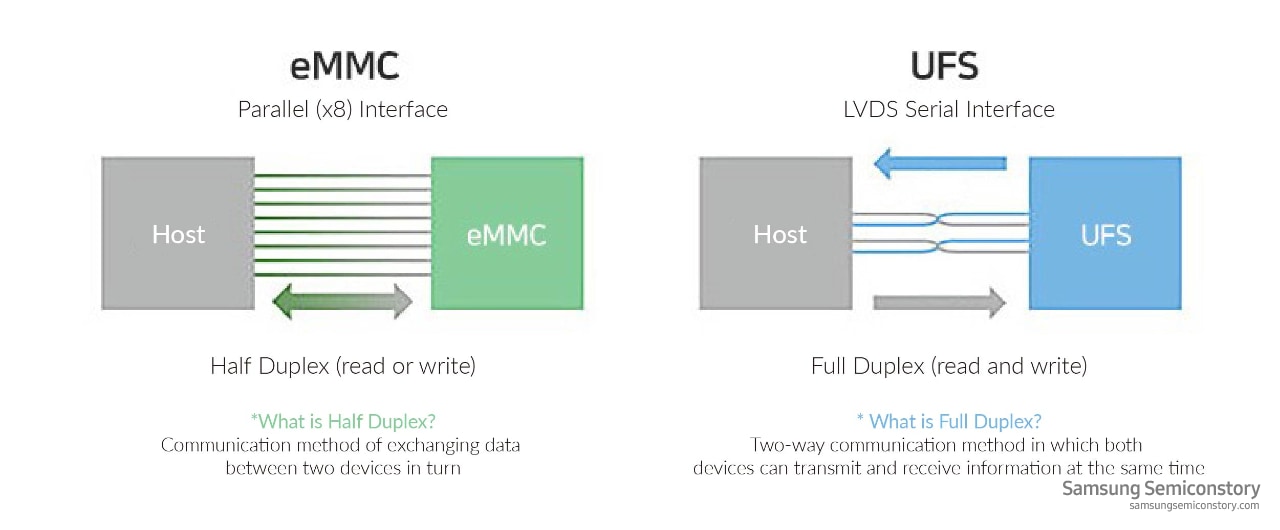
# 摘要
本文对EMMC技术进行了全面的概述和深入分析,从其理论基础、应用实例,到技术的创新点和发展趋势,以及性能优化和故障处理。EMMC技术作为一种广泛应用于移动设
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )