正则表达式:Python习题解答与高效模式匹配
发布时间: 2024-12-17 13:45:20 阅读量: 1 订阅数: 3 

Python核心编程习题解答.zip

参考资源链接:[《Python语言程序设计》课后习题解析与答案](https://wenku.csdn.net/doc/5guzi5pw84?spm=1055.2635.3001.10343)
# 1. 正则表达式的概念和基础
## 1.1 正则表达式的定义
正则表达式是一种文本模式匹配的工具,它使用一系列特殊的字符组合来描述字符串中的某种规律。这使得用户可以快速地执行查找、替换、验证等操作。
## 1.2 正则表达式的作用
正则表达式广泛应用于文本编辑器、搜索工具、编程语言中进行数据的匹配、提取和验证。例如,它可以用于验证电子邮件格式、查找代码中的特定模式或者从文档中提取信息。
## 1.3 正则表达式的组成
正则表达式由普通字符(字母、数字、汉字等)和元字符(如*、?、[、]、^、$等)组成。普通字符代表其自身,而元字符则具有特殊的含义,用于定义匹配规则。
正则表达式的概念和基础对于任何希望提高文本处理能力的IT专业人员来说都是必须掌握的基础知识,接下来的章节将深入探讨正则表达式在Python中的应用和实战演练。
# 2. Python中正则表达式的使用
## 2.1 正则表达式的语法规则
### 2.1.1 元字符和特殊序列
在Python中使用正则表达式进行模式匹配时,元字符和特殊序列是构建这些模式的基础。元字符是具有特殊含义的字符,它们代表了正则表达式中的各种模式组件。下面是一些常用的元字符:
- `.`:匹配除换行符以外的任意字符。
- `^`:匹配字符串的开始位置。
- `$`:匹配字符串的结束位置。
- `*`:匹配前一个字符零次或多次。
- `+`:匹配前一个字符一次或多次。
- `?`:匹配前一个字符零次或一次。
- `{n}`:匹配前一个字符恰好n次。
- `{n,}`:匹配前一个字符至少n次。
- `{n,m}`:匹配前一个字符至少n次,但不超过m次。
- `[abc]`:匹配方括号内的任意一个字符(如a、b或c)。
- `[^abc]`:匹配不在方括号内的任意字符。
- `|`:逻辑“或”操作符,匹配任一条件。
特殊序列用来表示那些难以用字符表示的特殊模式,例如:
- `\d`:匹配任何一个数字字符,等价于[0-9]。
- `\D`:匹配任何一个非数字字符,等价于[^0-9]。
- `\s`:匹配任何一个空白字符,包括空格、制表符等。
- `\S`:匹配任何一个非空白字符。
- `\w`:匹配任何一个字母数字字符,等价于[a-zA-Z0-9_]。
- `\W`:匹配任何一个非字母数字字符。
示例代码:
```python
import re
pattern = r'\d{3}-\d{2}-\d{4}'
text = 'My phone number is 123-45-6789'
match = re.search(pattern, text)
if match:
print('Phone number found:', match.group())
```
上述代码中,我们使用了`\d{3}-\d{2}-\d{4}`模式来匹配一个标准的美国电话号码。这段代码会在文本中搜索符合该模式的电话号码,并打印出来。
### 2.1.2 字符类和量词的使用
在构建复杂的正则表达式时,字符类和量词是经常使用的两个概念。字符类允许在单个字符的位置匹配多种可能的字符,而量词则用于指定前一个字符或者字符类可以出现的次数。
使用字符类时,可以列出所有可接受的字符,或者使用连字符`-`来表示字符的范围。例如,`[a-z]`表示任意小写字母,而`[a-zA-Z]`表示任意字母,包括大写和小写。
量词则描述了前面的字符或字符组可以出现的次数。常见量词包括:
- `*`:匹配前面的子表达式零次或多次。
- `+`:匹配前面的子表达式一次或多次。
- `?`:匹配前面的子表达式零次或一次。
- `{n}`:匹配前面的子表达式恰好n次。
- `{n,}`:匹配前面的子表达式至少n次。
- `{n,m}`:匹配前面的子表达式至少n次,但不超过m次。
使用量词时,需要特别注意贪婪模式与非贪婪模式的区别。在贪婪模式下,正则表达式引擎会尽可能多地匹配字符。在非贪婪模式下,正则表达式引擎会尽可能少地匹配字符,也就是在满足模式的最早位置停止匹配。
示例代码:
```python
import re
pattern = r'<.*>'
text = '<div>Hello, World!</div>'
match = re.search(pattern, text)
if match:
print('Matched:', match.group())
pattern_non_greedy = r'<.*?>'
match = re.search(pattern_non_greedy, text)
if match:
print('Non-greedy Matched:', match.group())
```
在这个示例中,第一个正则表达式`<.*>`由于使用了贪婪的`*`量词,它会匹配包含`<div>`标签的整个字符串。而第二个正则表达式`<.*?>`使用了非贪婪量词`*?`,它会匹配到第一个闭合的`>`,即`<div>`标签本身。
## 2.2 Python的re模块
### 2.2.1 re模块的基本用法
Python标准库中的`re`模块提供了许多用于处理正则表达式的函数和方法。这些函数和方法可以分为几个类别,包括模式编译、搜索匹配、字符串分割、替换以及编译对象的使用等。
在使用`re`模块之前,需要导入它:
```python
import re
```
下面介绍一些`re`模块中最基本的函数:
- `re.compile(pattern, flags=0)`:编译正则表达式模式,返回一个`RegexObject`。
- `re.search(pattern, string, flags=0)`:在字符串中搜索匹配的模式,如果找到就返回一个匹配对象。
- `re.match(pattern, string, flags=0)`:从字符串开始处匹配正则表达式模式。
- `re.findall(pattern, string, flags=0)`:返回字符串中所有匹配的列表。
- `re.finditer(pattern, string, flags=0)`:返回一个迭代器,包含所有匹配的`MatchObject`。
- `re.sub(pattern, repl, string, count=0, flags=0)`:将字符串中的匹配项替换为`repl`。
举个简单的例子来展示`re.search()`和`re.match()`的区别:
```python
import re
text = "Hello, this is a sample text."
# re.search()可以匹配字符串中的任意部分
match = re.search(r'Hello', text)
print('Search found:', match.group())
# re.match()只能匹配字符串的开始部分
match = re.match(r'Hello', text)
print('Match found:', match.group())
```
在本例子中,`re.search()`在文本中找到了"Hello",不论它出现在字符串的哪个位置。而`re.match()`只有在"Hello"位于字符串的开始位置时才会匹配成功。
### 2.2.2 编译正则表达式和匹配对象
在处理重复的正则表达式匹配操作时,编译正则表达式可以提高效率,因为编译后的模式对象可以重复使用而无需每次都重新编译正则表达式字符串。
编译正则表达式:
```python
import re
# 编译一个正则表达式模式
pattern = re.compile(r'\d+')
# 使用编译后的模式进行搜索
matches = pattern.findall('The first 3 numbers are 123 and 456')
print('Found numbers:', matches)
```
在上面的代码中,我们首先使用`re.compile()`函数编译了一个正则表达式模式,该模式用于匹配一个或多个数字。然后我们使用编译后的模式对象`pattern`来调用`findall()`方法,找出所有匹配的数字。
接下来我们来看看匹配对象(Match Objects):
```python
import re
text = 'This is an example.'
# 使用re.search()进行搜索
match = re.search(r'an (\w+)', text)
# 使用Match对象的方法
if match:
print('Full match:', match.group())
print('First group:', match.group(1))
print('Start position:', match.start())
print('End position:', match.end())
print('Span tuple:', match.span())
```
在上面的代码中,`re.search()`找到了字符串中的一个匹配项,并返回了一个匹配对象。通过匹配对象,我们可以获取到匹配的完整字符串、分组、匹配的起始和结束位置以及匹配的跨度。
匹配对象是可迭代的,支持索引访问,并且它还提供了许多用于提取匹配信息的方法,如`groups()`, `groupdict()`, `start()`, `end()`, `span()`等。
## 2.3 捕获组和反向引用
### 2.3.1 创建和使用捕获组
捕获组(Capture Groups)是正则表达式中重要的功能,允许你对子模式进行分组并在匹配中捕获其内容。使用圆括号`()`来创建一个捕获组

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Vivado DDS IP核:最佳实践分析】:揭秘定制频率正弦波输出的奥秘

参考资源链接:[VIVADO DDS IP核详解:设置、频率计算与仿真实战](https://wenku.csdn.net/doc/6412b5eebe7fbd1778d44e92?spm=1055.2635.3001.10343)
# 1. Vivado DDS IP核概述
数
NGboost算法理解:深入概率提升树背后的故事

参考资源链接:[清华镜像源安装NGBoost、XGBoost和CatBoost:数据竞赛高效预测工具](https://wenku.csdn.net/doc/64532205ea0840391e76f23b?spm=1055.2635.3001.10343)
# 1. NGBoost算法的理论基础
## 1.1 NGBoost的起源与定义
NGBoost,即Natural Grad
【LSI SAS 9311-8i集成与虚拟化指南】:无缝对接与配置技巧大解析

参考资源链接:[LSI SAS 9311-8i PCIe适配器用户指南](https://wenku.csdn.net/doc/604komobop?spm=1055.2635.3001.10343)
# 1. LSI SAS 9311-8i集成基础介绍
LSI SAS 9311-8i是LSI公司推出的一款高性能SAS控制器,广泛应用于服务器和存储系统中,是存储网络的
【高级应用手册】:文件系统维护与优化的高级技巧
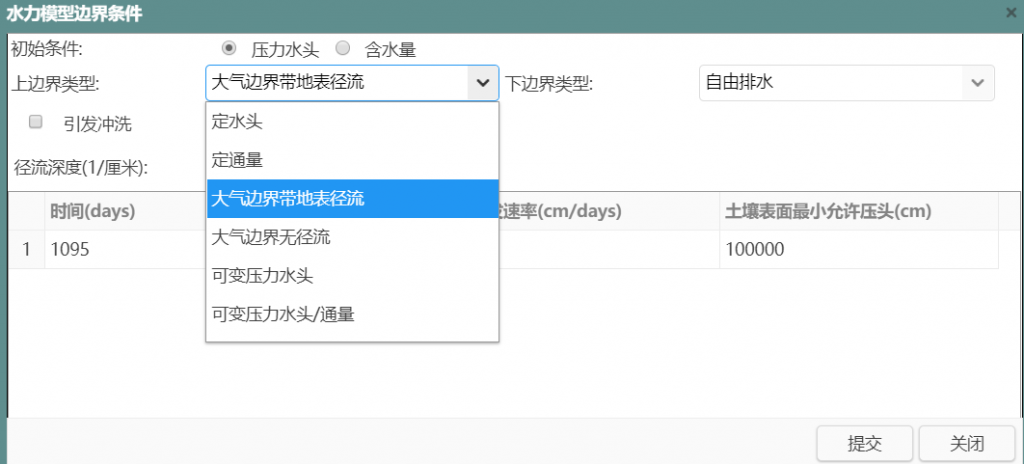
参考资源链接:[MIKE 11 模型设置教程:从断面数据到水文参数](https://wenku.csdn.net/doc/7fx3ry4v8x?spm=1055.2635.3001.10343)
# 1. 文件系统的基本概念和重要性
## 1.1 文件系统的定义和功能
文件系统是操作系统用于管理数据的逻辑结构和物理存储的系统。它负责数据的存储、检索、更新、和删除。从技术角度讲,文件系统将数据存储为文件,而文件是一系
定制化PDF文档查看体验:PDFView.ocx的个性化开发技巧(个性化视图大揭秘)
参考资源链接:[YCanPDF PDFView OCX 控件功能与使用方法详解](https://wenku.csdn.net/doc/6412b6cdbe7fbd1778d48088?spm=1055.2635.3001.10343)
# 1. PDFView.ocx简介与应用场景
## 1.1
RS-485网络构建秘诀:CAHO P961多设备通信解决方案

参考资源链接:[CAHO_P961温控器RS-485 MODBUS编程与连接详解](https://wenku.csdn.net/doc/64617f5e5928463033b0f182?spm=1055.2635.3001.10343)
# 1. RS-485网络概述与技术标准
RS-485网络是工业通信领域常
【解决Git冲突】:Windows下Git合并冲突解决技巧
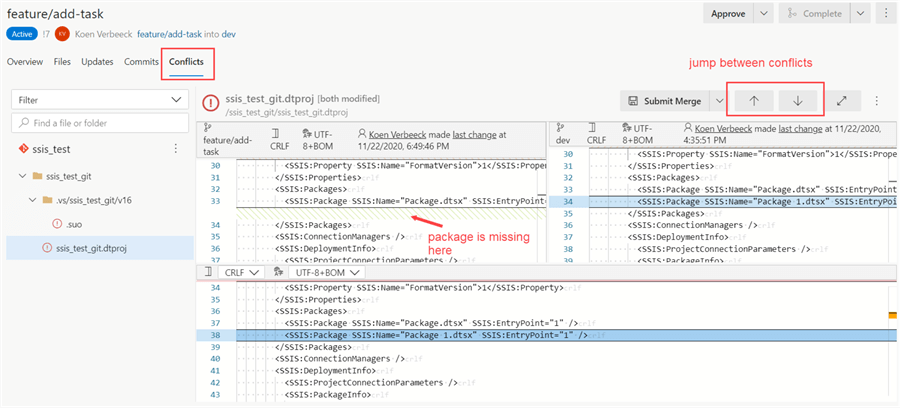
参考资源链接:[加速下载:Windows Git 官方版本百度网盘分享](https://wenku.csdn.net/doc/1o88jkk5vw?spm=1055.2635.3001.10343)
# 1. Git冲突的基本概念
## 1.1 什么是Git冲突
Git冲突发生在多人协作开发过程中,当两个或多个开发者对同一文件的同一部分进行了
【键盘的世界,全球化的选择】:Filco圣手二代满足全球用户需求之道

参考资源链接:[Filco圣手二代:多语言操作指南与设置详解](https://wenku.csdn.net/doc/9bvnictv8o?spm=1055.2635.3001.10343)
# 1. 键盘的世界与全球化市场
键盘作为计算机时代必不可少的输入设备,承载着全球化沟通与交流的核心功能。本章将简要概述键盘的发展历程,分析其在不同文化和市场中的多样性,并探讨全
Conefor Sensinode 2.6 数据保护:备份策略与灾难恢复的终极指南
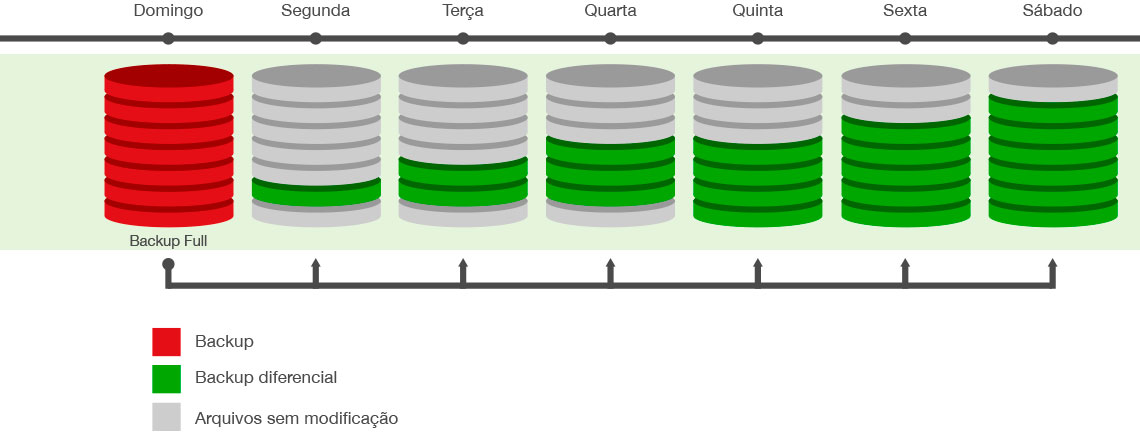
参考资源链接:[conefor sensinode2.6操作手册(中文版)](https://wenku.csdn.net/doc/64
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )