Python函数与模块的使用技巧
发布时间: 2024-02-01 15:05:38 阅读量: 56 订阅数: 41 

Python函数的运用方法
# 1. 简介
## 1.1 什么是Python函数和模块
在Python中,函数是一段可重用的代码块,用于执行特定的任务。它可以接受输入参数并返回输出结果,使得代码更加简洁、可读性更高。而模块则是一个包含了多个函数、变量和类的文件,通过将相关的函数封装在模块中,可以更好地组织和管理代码。
## 1.2 Python函数和模块的重要性
函数和模块是Python编程中不可或缺的一部分,具有以下重要性:
- **提高代码复用性**:通过将代码封装为函数和模块,可以在不同的程序中反复使用,避免重复编写相同的代码,提高开发效率。
- **代码的可维护性**:将代码按照功能模块化,可以更容易地维护和修改代码,减少出错的可能性。
- **促进团队开发**:在团队合作开发过程中,通过使用函数和模块,可以实现任务的分工和模块的独立开发,提高团队的协作效率。
在接下来的章节中,我们将深入探讨函数和模块的使用技巧,以及如何将其应用到实际项目中。
# 2. 函数基础
在Python中,函数是用来执行特定任务的一组语句的集合。通过定义和调用函数,我们可以将复杂的问题分解为简单的步骤,并实现代码的模块化和复用。本章节将介绍函数的基础知识,包括函数的定义、参数和返回值的使用以及函数的调用方式。
### 2.1 定义函数
在Python中,可以使用关键字`def`来定义函数。函数的定义包含函数名、参数列表和函数体。下面是一个简单的例子:
```python
def greet(name):
# 函数体
print("Hello, " + name + "!")
# 调用函数
greet("Alice")
```
上述代码中,我们定义了一个名为`greet`的函数,它接受一个参数`name`并在函数体中打印出对应的问候语。在函数定义之后,我们通过`greet("Alice")`的方式调用函数,并将名字`Alice`作为参数传递给函数。运行上述代码,输出结果为`Hello, Alice!`。
### 2.2 函数的参数和返回值
函数可以接受一个或多个参数,并且可以返回一个值。参数是函数定义时用来接收外部传递数据的占位符,而返回值则是函数执行完毕后将结果返回给调用者。
参数可以分为两类:位置参数和关键字参数。位置参数是按照定义顺序传递的,而关键字参数则是根据参数名进行传递。
下面是一个例子,演示了函数的参数和返回值的使用:
```python
def add(x, y):
# 函数体
result = x + y
return result
# 调用函数
sum = add(3, 4)
print(sum) # 输出结果为7
```
上述代码中,我们定义了一个名为`add`的函数,它接受两个参数`x`和`y`,并将它们相加的结果返回。在调用函数时,我们传递参数`3`和`4`,并将返回值存储在变量`sum`中。最后,我们通过`print(sum)`将结果打印出来,输出结果为`7`。
### 2.3 函数的调用
函数的调用是指通过函数名和参数列表来执行函数体中的代码。在前面的例子中,我们已经展示了如何调用函数。下面是一些关于函数调用的注意事项:
- 函数名后面需要添加一对小括号`()`,用来表示函数的调用;
- 在调用函数时,需要根据函数定义时的参数列表传递相应的参数;
- 函数的返回值可以通过赋值给变量或者直接打印输出来查看。
```python
def say_hello():
print("Hello!")
# 调用函数
say_hello() # 输出结果为Hello!
```
上述代码中,我们定义了一个名为`say_hello`的函数,它不接受任何参数,只是在函数体中打印出`Hello!`。通过调用`say_hello()`,我们可以看到相应的输出。
在函数调用时,还可以根据具体需求传递不同的参数值,例如:
```python
name = "Bob"
def greet(name):
print("Hello, " + name + "!")
# 调用函数
greet(name) # 输出结果为Hello, Bob!
```
上述代码中,我们通过在调用`greet`函数时传递变量`name`作为参数值,实现了动态地向函数传递不同的数据的效果。
# 3. 使用函数提高代码复用性
代码的复用性是衡量代码质量的重要指标之一。而函数的设计和使用可以很好地提高代码的复用性,避免重复编写相似的代码。本章将介绍如何将代码封装为函数,并讨论如何设计可重用的函数。
#### 3.1 将代码封装为函数
将代码封装为函数是一种常见的代码复用方式。通过将一段功能相对独立的代码封装为一个函数,可以在需要时直接调用该函数,避免重复编写相同的代码。
下面是一个简单的例子,将计算两个数的和封装为一个函数:
```python
def add_numbers(a, b):
return a + b
result = add_numbers(5, 3)
print(result) # 输出:8
```
在上面的例子中,我们定义了一个名为`add_numbers`的函数,它接受两个参数`a`和`b`,返回它们的和。我们可以通过调用`add_numbers`函数来得到两个数的和,并将结果打印出来。
#### 3.2 如何设计可重用的函数
设计可重用的函数需要考虑以下几个方面:
- 保持函数的单一职责:一个函数应该只负责完成一个特定的任务,这样可以使函数更加可靠、可测试和易于维护。
- 使用参数和返回值:函数的参数用于接收外部传入的数据,而返回值则是函数向外部传递结果的方式。合理使用参数和返回值可以增加函数的灵活性和可复用性。
- 考虑函数的通用性:尽量设计通用的函数,能够处理多种情况,而不是过于特定的场景。这样可以使函数在不同的应用场景下都能够重复使用。
下面是一个示例,演示如何设计一个可重用的函数来计算列表中元素的平均值:
```python
def calculate_average(numbers):
total = sum(numbers)
average = total / len(numbers)
return average
scores = [85, 92, 78, 90, 88]
average_score = calculate_average(scores)
print(average_score) # 输出:86.6
```
在上面的例子中,我们定义了一个名为`calculate_average`的函数,它接受一个列表作为参数,计算并返回列表中元素的平均值。通过将列表作为参数传递给函数,我们可以在不同的场景下复用该函数来计算平均值。
通过合理的函数封装和设计,我们可以提高代码的复用性,减少冗余代码的编写,更加高效地开发项目。
# 4. 模块的概念和使用
在本章中,将介绍Python中模块的概念以及如何使用模块来组织和管理代码。
#### 4.1 导入模块
在Python中,可以使用`import`语句来导入模块。模块是一个包含了函数、类和变量定义的文件,其后缀名为`.py`。在导入模块后,就可以使用模块中定义的函数、类和变量。
```python
# 导入整个模块
import module_name
# 导入模块并指定别名
import module_name as alias_name
# 从模块中导入特定的函数或类
from module_name import function_name, class_name
```
#### 4.2 常用的Python标准库模块
Python标准库包含了丰富的模块,常用的标准库模块包括:
- `os`: 提供了丰富的操作系统函数
- `sys`: 用于访问Python解释器的变量和函数
- `math`: 提供了数学运算函数
- `random`: 用于生成随机数
- `datetime`: 处理日期和时间
等等。
#### 4.3 使用第三方模块
除了Python标准库,还可以使用第三方模块来扩展Python的功能。常用的第三方模块管理工具包括`pip`,可以使用`pip`来安装第三方模块。一些常用的第三方模块包括:
- `requests`: 用于发送HTTP请求
- `pandas`: 用于数据分析和处理
- `matplotlib`: 用于绘制数据图表
- `tensorflow`: 用于机器学习和深度学习
等等。
通过学习和使用模块,可以更好地组织代码,提高代码的复用性和可维护性。
# 5. 模块的组织和管理
在本章中,将讨论如何创建、控制和管理Python模块。模块是一组相关的功能代码的集合,可以供其他程序使用。良好的模块组织和管理可以提高代码的可读性和可维护性。
#### 5.1 创建自定义模块
Python提供了创建自定义模块的功能,可以将一段代码封装在一个.py文件中,并通过import语句导入到其他程序中使用。
创建一个自定义模块非常简单,只需在一个.py文件中编写函数、类或变量,并保存为独立的.py文件即可。以下是一个示例:
```python
# mymodule.py
def greet(name):
print("Hello, " + name)
def calculate_sum(a, b):
return a + b
```
上述代码定义了一个自定义模块,包含了两个函数:greet和calculate_sum。我们可以在其他程序中导入并使用这个模块。例如:
```python
# main.py
import mymodule
mymodule.greet("Alice")
result = mymodule.calculate_sum(3, 4)
print(result)
```
通过import语句导入了mymodule模块,并使用其中的函数greet和calculate_sum。输出结果为:
```
Hello, Alice
7
```
#### 5.2 控制模块的可见性和访问权限
在Python中,模块中的函数、类和变量可以通过不同的方式设置可见性和访问权限。
- 默认情况下,模块中定义的函数、类和变量是对外可见的。其他程序可以直接导入模块并使用其中的内容。
- 可以使用下划线(_)来将函数、类或变量命名为私有的。私有的函数、类和变量只能在模块内部使用,不能被其他程序直接访问。
- 可以使用双下划线(__)来将函数、类或变量命名为特殊的,这样可以避免与其他模块中的内容冲突。
以下是一个示例:
```python
# mymodule.py
def public_function():
print("This is a public function")
def _private_function():
print("This is a private function")
class PublicClass:
def __init__(self):
self.public_variable = 10
self._private_variable = 20
class _PrivateClass:
def __init__(self):
self.variable = 30
```
在上述示例中,public_function和PublicClass是对外可见的,其他程序可以导入并使用。而_private_function和_PrivateClass是私有的,只能在mymodule模块内部使用。
#### 5.3 模块的打包和发布
当我们的项目变得更加复杂时,可能涉及到多个相关的模块。为了方便管理和发布,我们可以将这些模块打包为一个独立的模块。
打包一个模块意味着将多个相关的模块放在同一个目录下,并在该目录下创建一个特殊的__init__.py文件。这个文件会被Python解释器识别为一个包。
以下是一个简单的包的结构示例:
```
mymodule/
__init__.py
greet.py
calculate.py
```
在上述示例中,mymodule是一个包,包含了greet和calculate两个模块。在其他程序中,可以使用import语句导入整个包或特定的模块。
在发布模块时,可以将打包好的模块上传到Python包管理工具(如PyPI)上,并通过pip命令来安装和使用。这样其他用户就可以通过pip安装你的模块并使用了。
通过以上内容,我们了解了如何创建自定义模块、控制模块的可见性和访问权限,以及如何打包和发布模块。合理的模块组织和管理可以提高代码的可读性和可维护性,同时也方便了模块的重用和分享。
# 6. 实战案例
在这一章节中,我们将介绍一些实际案例,展示如何使用函数和模块解决实际问题,并展示模块化开发的示例项目。
### 6.1 使用函数解决实际问题
#### 场景描述
假设我们需要编写一个程序,计算某个数的平方、立方和平方根。我们可以使用函数来完成这个任务,提高代码的可读性和复用性。
#### 代码示例
```python
import math
def calculate(number):
square = number ** 2
cube = number ** 3
square_root = math.sqrt(number)
return square, cube, square_root
num = 5
result = calculate(num)
print(f"The square of {num} is {result[0]}")
print(f"The cube of {num} is {result[1]}")
print(f"The square root of {num} is {result[2]}")
```
#### 代码说明
- 首先导入了Python标准库中的math模块,以使用sqrt函数来计算平方根。
- 接下来,定义了一个名为calculate的函数,该函数接受一个参数number。
- 在函数内部使用了乘方操作符**来计算平方和立方,使用math.sqrt函数来计算平方根。
- 最后,通过return语句返回了计算的结果。
- 在主程序中,我们定义了一个名为num的变量,并将其传递给calculate函数获取计算结果。
- 最后,使用print语句将结果打印出来。
#### 结果说明
对于输入的数字5,程序会计算其平方、立方和平方根,并将结果打印出来。
### 6.2 模块化开发示例项目
#### 场景描述
假设我们正在开发一个学生管理系统的模块,该模块包含了学生的基本信息(姓名、年龄、性别等),以及对学生信息的增加、删除、更新和查询等操作。
#### 代码示例
```python
# student.py
class Student:
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
def get_name(self):
return self.name
def update_age(self, new_age):
self.age = new_age
def update_gender(self, new_gender):
self.gender = new_gender
def delete(self):
del self
# main.py
from student import Student
def add_student(name, age, gender):
student = Student(name, age, gender)
# 添加学生到数据库或其他数据结构中
def delete_student(student):
student.delete()
# 从数据库或其他数据结构中删除学生
def update_student_age(student, new_age):
student.update_age(new_age)
# 更新学生的年龄
def update_student_gender(student, new_gender):
student.update_gender(new_gender)
# 更新学生的性别
def get_student_name(student):
return student.get_name()
# 获取学生的姓名
# 使用示例
student1 = add_student("Alice", 18, "Female")
student2 = add_student("Bob", 20, "Male")
update_student_age(student1, 20)
update_student_gender(student2, "Female")
print(f"Student 1 name: {get_student_name(student1)}, age: {student1.age}, gender: {student1.gender}")
print(f"Student 2 name: {get_student_name(student2)}, age: {student2.age}, gender: {student2.gender}")
```
#### 代码说明
- 在student.py模块中,定义了一个名为Student的类,包含了学生的基本信息和相关操作方法。
- 在main.py模块中,定义了一系列操作学生信息的函数,如添加学生、删除学生、更新学生信息等。
- 在使用示例中,我们首先通过add_student函数添加了两个学生,并使用update_student_age和update_student_gender函数更新了学生的信息。
- 最后,通过get_student_name函数获取学生的姓名,并使用print语句将结果打印出来。
#### 结果说明
使用示例中,我们添加了两个学生,并更新了其中一个学生的年龄和性别。最后将学生的姓名、年龄和性别打印出来。
### 6.3 实践中的注意事项
在实践中,使用函数和模块化开发可以提高代码的可维护性和复用性。下面是一些使用函数和模块的注意事项:
- 好的函数命名和模块组织结构可以使代码更加易读和易于理解。
- 函数的参数和返回值的设计应符合单一职责原则,保持功能的独立性。
- 模块之间的关系应合理抽象,并使用适当的访问权限来控制模块的可见性。
- 需要注意函数和模块的命名冲突问题,避免命名冲突导致的错误。
- 在模块的打包和发布过程中,需要考虑版本管理、依赖管理等问题。
总之,函数和模块是编写可维护、可扩展和可复用代码的重要工具,掌握它们的使用技巧对于提高开发效率和代码质量非常重要。
以上就是关于Python函数和模块的详细介绍,希望对你在实际项目中应用函数和模块有所帮助。祝你在编程之路上越走越远!

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Python开发基础与应用》是一本涵盖了Python开发各方面知识的专栏,旨在帮助读者全面掌握Python语言的基础与应用技巧。从Python基础语法与数据类型详解、函数与模块的使用技巧到面向对象编程的实战指南,再到文件操作与异常处理的最佳实践,专栏逐步引领读者深入了解Python的核心概念和编程思想。此外,还介绍了利用Python进行数据处理与分析、网络编程、并发编程、爬虫开发、图像处理与计算机视觉等实际应用,以及Python在自然语言处理、Web开发、数据可视化、机器学习与深度学习、大数据处理与分析、物联网开发、区块链技术等领域的使用案例和技术探索。同时,还介绍了Python在自动化测试与持续集成、网络安全与数据加密等安全领域的利用技巧。无论您是初学者还是有一定编程经验的开发者,本专栏都将为您提供实用的知识与经验,助您在Python开发领域取得更大的成就。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
NVIDIA ORIN NX性能基准测试:超越前代的关键技术突破
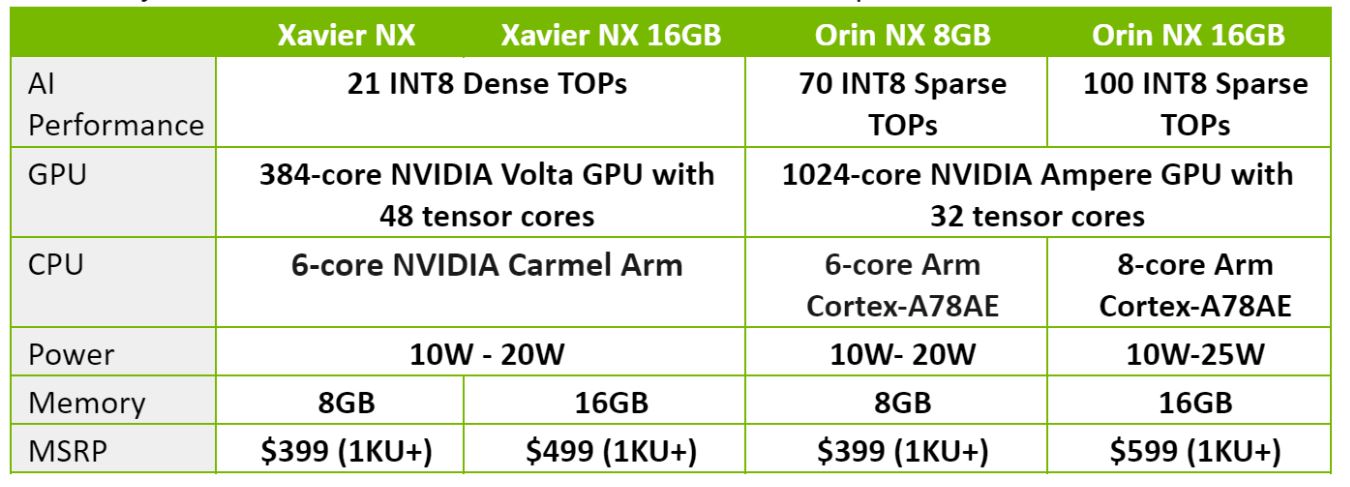
# 摘要
本文全面介绍了NVIDIA ORIN NX处理器的性能基准测试理论基础,包括性能测试的重要性、测试类型与指标,并对其硬件架构进行了深入分析,探讨了处理器核心、计算单元、内存及存储的性能特点。此外,文章还对深度学习加速器及软件栈优化如何影响AI计算性能进行了重点阐述。在实践方面,本文设计了多个实验,测试了NVI
图论期末考试必备:掌握核心概念与问题解答的6个步骤

# 摘要
图论作为数学的一个分支,广泛应用于计算机科学、网络分析、电路设计等领域。本文系统地介绍图论的基础概念、图的表示方法以及基本算法,为图论的进一步学习与研究打下坚实基础。在图论的定理与证明部分,重点阐述了最短路径、树与森林、网络流问题的经典定理和算法原理,包括Dijkstra和Floyd-Warshall算法的详细证明过程。通过分析图论在社交网络、电路网络和交通网络中的实际应用,本文探讨了图论问题解决策略和技巧,包括策略规划、数学建模与软件
【无线电波传播影响因素详解】:信号质量分析与优化指南
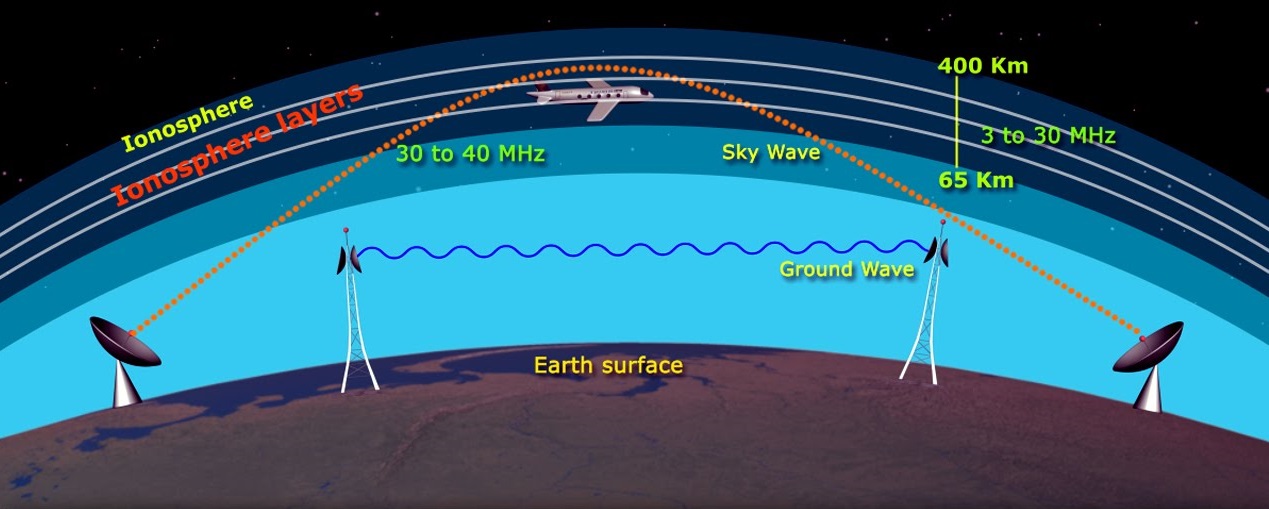
# 摘要
本文综合探讨了无线电波传播的基础理论、环境影响因素以及信号质量的评估和优化策略。首先,阐述了大气层、地形、建筑物、植被和天气条件对无线电波传播的影响。随后,分析了信号衰减、干扰识别和信号质量测量技术。进一步,提出了包括天线技术选择、传输系统调整和网络规划在内的优化策略。最后,通过城市、农村与偏远地区以及特殊环境下无线电波传播的实践案例分析,为实际应用提供了理论指导和解决方案。
# 关键字
无线电波传播;信号衰减;信号干扰;信号
FANUC SRVO-062报警:揭秘故障诊断的5大实战技巧

# 摘要
FANUC SRVO-062报警是工业自动化领域中伺服系统故障的常见表现,本文对该报警进行了全面的综述,分析了其成因和故障排除技巧。通过深入了解FANUC伺服系统架构和SRVO-062报警的理论基础,本文提供了详细的故障诊断流程,并通过伺服驱动器和电机的检测方法,以及参数设定和调整的具体操作
【单片微机接口技术速成】:快速掌握数据总线、地址总线与控制总线
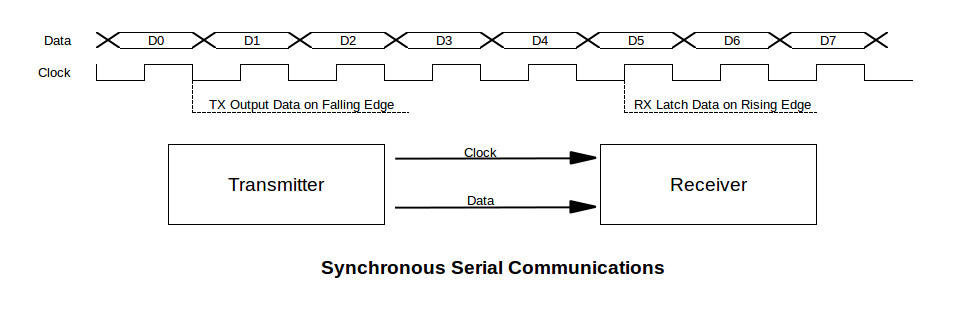
# 摘要
本文深入探讨了单片微机接口技术,重点分析了数据总线、地址总线和控制总线的基本概念、工作原理及其在单片机系统中的应用和优化策略。数据总线的同步与异步机制,以及其宽度对传输效率和系统性能的影响是本文研究的核心之一。地址总线的作用、原理及其高级应用,如地址映射和总线扩展,对提升寻址能力和系统扩展性具有重要意义。同时,控制总线的时序控制和故障处理也是确保系统稳定运行的关键技术。最后
【Java基础精进指南】:掌握这7个核心概念,让你成为Java开发高手

# 摘要
本文全面介绍了Java语言的开发环境搭建、核心概念、高级特性、并发编程、网络编程及数据库交互以及企业级应用框架。从基础的数据类型和面向对象编程,到集合框架和异常处理,再到并发编程和内存管理,本文详细阐述了Java语言的多方面知识。特别地,对于Java的高级特性如泛型和I/O流的使用,以及网络编程和数据库连接技
电能表ESAM芯片安全升级:掌握最新安全标准的必读指南
# 摘要
ESAM芯片作为电能表中重要的安全组件,对于确保电能计量的准确性和数据的安全性发挥着关键作用。本文首先概述了ESAM芯片及其在电能表中的应用,随后探讨了电能表安全标准的演变历史及其对ESAM芯片的影响。在此基础上,深入分析了ESAM芯片的工作原理和安全功能,包括硬件架构、软件特性以及加密技术的应用。接着,本文提供了一份关于ESAM芯片安全升级的实践指南,涵盖了从前期准备到升级实施以及后
快速傅里叶变换(FFT)实用指南:精通理论与MATLAB实现的10大技巧
# 摘要
快速傅里叶变换(FFT)是信号处理和数据分析的核心技术,它能够将时域信号高效地转换为频域信号,以进行频谱分析和滤波器设计等。本文首先回顾FFT的基础理论,并详细介绍了MATLAB环境下FFT的使用,包括参数解析及IFFT的应用。其次,深入探讨了多维FFT、离散余弦变换(DCT)以及窗函数在FFT中的高级应用和优化技巧。此外,本文通过不同领域的应用案例
【高速ADC设计必知】:噪声分析与解决方案的全面解读

# 摘要
高速模拟-数字转换器(ADC)是现代电子系统中的关键组件,其性能受到噪声的显著影响。本文系统地探讨了高速ADC中的噪声基础、噪声对性能的影响、噪声评估与测量技术以及降低噪声的实际解决方案。通过对噪声的分类、特性、传播机制以及噪声分析方法的研究,我们能
【Python3 Serial数据完整性保障】:实施高效校验和验证机制
# 摘要
本论文首先介绍了Serial数据通信的基础知识,随后详细探讨了Python3在Serial通信中的应用,包括Serial库的安装、配置和数据流的处理。本文进一步深入分析了数据完整性的理论基础、校验和验证机制以及常见问题。第四章重点介绍了使用Python3实现Serial数据校验的方法,涵盖了基本的校验和算法和高级校验技
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )