数据库基础知识回顾:如何构建坚实的数据系统理论基础?
发布时间: 2025-01-10 07:05:00 阅读量: 5 订阅数: 4 

模具状态监测行业发展趋势:预计到2030年市场规模为5.06亿美元

# 摘要
数据库系统是信息技术基础设施的关键组成部分,本文从关系型数据库的核心概念讲起,详细介绍了关系模型的基础、SQL语言的三大功能以及事务管理和并发控制。接着,本文深入探讨了数据库设计的各个阶段,包括需求分析、逻辑设计和物理设计,重点阐述了数据规范化理论和性能优化策略。在非关系型数据库方面,文章概述了NoSQL数据库和新型数据库技术的发展与应用。最后,本文针对数据库安全性、备份与恢复技术进行了分析,并展望了云数据库、人工智能融合以及数据库管理员角色转变的未来趋势。
# 关键字
数据库系统;关系型数据库;SQL语言;数据规范化;事务管理;非关系型数据库;安全性与备份;未来趋势
参考资源链接:[数据库系统概念第六版3答案](https://wenku.csdn.net/doc/34pffsedzy?spm=1055.2635.3001.10343)
# 1. 数据库系统概述
## 1.1 数据库的定义和作用
数据库系统是一种按照数据结构来组织、存储和管理数据的系统,它能够高效地获取和维护数据。数据库的主要作用是存储、检索、更新、管理数据,为各种应用系统提供数据服务,是信息化社会的重要基础设施。
## 1.2 数据库的类型
按照数据模型的不同,数据库主要分为关系型数据库和非关系型数据库。关系型数据库如MySQL,Oracle等,以表格形式存储数据,数据结构清晰,易于维护;非关系型数据库如MongoDB,Redis等,适用于处理大量的数据,灵活性强。
## 1.3 数据库的应用场景
数据库广泛应用于各种领域,如电子商务、社交媒体、金融服务等。在这些应用中,数据库不仅存储用户信息,交易记录,还能高效处理大量并发访问请求,保证数据的一致性和完整性。
# 2. 关系型数据库核心概念
### 2.1 关系模型的基础
在关系型数据库中,数据被组织成表格的形式,这种表格被称为关系。每一个关系都有一个名称,并且包含一系列的行和列。列通常被称为属性,而行则被称为元组。关系模型是建立在数学理论——关系代数基础上的,为数据库操作提供了坚实的基础。
#### 2.1.1 关系代数与运算
关系代数是一种抽象的查询语言,它使用一组运算符来操作关系,并且允许我们表达各种查询。基本的关系代数运算符包括选择(σ)、投影(π)、并(∪)、差(−)、笛卡尔积(×)、重命名(ρ)和连接(⋈)等。
选择操作σ用于选取满足特定条件的行,其表达式为σ<sub>C</sub>(R),其中C是条件表达式,R是关系名。例如,σ<sub>age>30</sub>(Employees)选取所有年龄大于30的员工。
投影操作π用于选择某些列,其表达式为π<sub>A<sub>1</sub>,A<sub>2</sub>,...,A<sub>n</sub></sub>(R),表示从关系R中选择列A1, A2, ..., An的投影。例如,π<sub>name,age</sub>(Employees)将只选择员工的名字和年龄。
连接操作⋈用于将两个关系的相关列结合起来,形成一个新的关系。它可以根据共同的列值进行,如R ⋈<sub>r.A=s.B</sub> S,表示根据r关系中的A列和s关系中的B列进行匹配的连接操作。
关系代数提供了强大的工具来执行复杂的查询,而这些查询正是SQL语言的基础。
#### 2.1.2 数据完整性与约束
数据完整性是指数据的正确性和一致性。关系型数据库通过约束来实现数据完整性,常见的约束包括实体完整性、参照完整性和用户定义的完整性。
实体完整性确保每个表都有一个主键,用于唯一地标识表中的每条记录。参照完整性确保外键值要么为空,要么引用另一个表的主键值。用户定义的完整性则是根据实际业务需求设定的规则,比如性别字段只允许是"男"或"女"。
通过设置约束,关系型数据库保证了数据的质量,避免了不一致和错误的数据导致的问题。
```sql
-- 下面的SQL语句创建了一个员工表,并为其添加了主键和外键约束。
CREATE TABLE Employees (
EmpID INT PRIMARY KEY, -- 实体完整性约束
Name VARCHAR(100),
DeptID INT,
FOREIGN KEY (DeptID) REFERENCES Departments(DeptID) -- 参照完整性约束
);
```
在上述SQL代码中,`EmpID` 被定义为员工表的主键,而`DeptID`是外键,它引用了另一个表`Departments`中的`DeptID`主键。
### 2.2 SQL语言精讲
SQL(Structured Query Language,结构化查询语言)是关系型数据库的核心,主要用于对数据库进行操作。SQL语言可以分为数据定义语言(DDL)、数据操作语言(DML)、数据查询语言(DQL)和数据控制语言(DCL)。
#### 2.2.1 SQL的数据定义功能
数据定义语言主要用于创建和修改数据库结构,包括创建表、视图、索引等。
```sql
-- 创建新表
CREATE TABLE Students (
StudentID INT PRIMARY KEY,
Name VARCHAR(100),
Major VARCHAR(100),
EnrollmentDate DATE
);
-- 修改表结构,例如添加一个新列
ALTER TABLE Students ADD COLUMN Grade VARCHAR(10);
```
在上述代码块中,我们首先创建了一个包含学号、姓名、专业和入学日期的学生表。随后我们修改了表结构,添加了一个新的列`Grade`用来存储学生的成绩。
#### 2.2.2 SQL的数据操作功能
数据操作语言用于对数据库中的数据进行增删改操作。基本的DML操作包括INSERT、UPDATE和DELETE。
```sql
-- 增加新记录
INSERT INTO Students (StudentID, Name, Major, EnrollmentDate) VALUES (1, 'Alice', 'Computer Science', '2023-09-01');
-- 更新现有记录
UPDATE Students SET Grade = 'A' WHERE StudentID = 1;
-- 删除记录
DELETE FROM Students WHERE StudentID = 1;
```
以上三个操作分别用于向学生表中插入新的学生记录、更新学生的成绩、以及删除特定学生的记录。
#### 2.2.3 SQL的数据查询功能
数据查询语言是SQL中最常用的部分,它使用SELECT语句来从一个或多个表中检索数据。SELECT语句非常强大和灵活,可以进行各种数据筛选、排序和分组操作。
```sql
-- 查询特定条件的记录
SELECT * FROM Students WHERE Major = 'Computer Science';
-- 排序和分组
SELECT Major, AVG(Grade) as AverageGrade FROM Students GROUP BY Major ORDER BY AverageGrade DESC;
```
第一个查询语句从学生表中选择了所有计算机科学专业的学生,第二个查询则计算了每个专业的平均成绩,并按平均成绩降序排序。
### 2.3 事务管理和并发控制
事务是数据库管理系统执行过程中的一个逻辑单位,由一个或多个操作序列组成,这些操作要么全部执行,要么全部不执行,保证数据库的一致性。
#### 2.3.1 事务的基本概念
事务具有四个基本特性,即原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability),简称ACID特性。
- 原子性:事务是不可分割的工作单位,事务中的操作要么全部完成,要么全部不完成。
- 一致性:事务必须使数据库从一个一致性状态转变到另一个一致性状态。
- 隔离性:事务的执行不能被其他事务干扰,即一个事务内部的操作及使用的数据对并发的其他事务是隔离的。
- 持久性:一旦事务提交,则其所做的修改会永久保存在数据库中。
```sql
-- 开始一个事务
START TRANSACTION;
-- 执行一系列操作
UPDATE Accounts SET Balance = Balance - 100 WHERE AccountID = 101;
UPDATE Accounts SET Balance = Balance + 100 WHERE AccountID = 102;
-- 提交事务
COMMIT;
-- 如果在操作中出现错误,可以回滚事务
ROLLBACK;
```
在上面的伪代码中,我们开始了一个事务,在该事务中,我们从一个账户转出100单位的货币,并转入到另一个账户。如果这些操作都成功执行,我们则提交事务。如果有任何问题发生,我们可以回滚事务来取消这些操作。
#### 2.3.2 并发问题及其控制策略
在多用户并发访问数据库时,可能会发生多个事务同时操作相同数据的情况,这会导致数据不一致的问题,如脏读、不可重复读和幻读等。为了解决这些问题,数据库系统提供了事务隔离级别。
事务隔离级别包括:
- 读未提交(Read Uncommitted)
- 读已提交(Read Committed)
- 可重复读(Repeatable Read)
- 串行化(Serializable)
不同的隔离级别具有不同的性能影响,并且在保证数据一致性方面也有所不同。数据库管理员需要根据应用场景和性能要求,选择合适的隔离级别。
```mermaid
graph LR
A[事务开始] --> B[设置隔离级别]
B --> C[执行事务]
C --> D{是否发生冲突}
D -- 是 --> E[处理冲突]
D -- 否 --> F[提交事务]
E --> F
F --> G[事务结束]
```
在上述流程图中,我们可以看到一个事务从开始到结束的过程,包括设置隔离级别、执行事务、处理冲突(如果发生的话)以及最后的提交或回滚。
并发控制是数据库管理系统的重要组成部分,它保证了即使在高并发环境下,数据库也能保持数据的一致性和完整性。通过适当的隔离级别和锁策略,数据库可以安全地处理大量的并发请求。
在本章节的探讨中,我们涉及了关系型数据库的理论基础,包括关系模型、数据完整性约束,以及SQL语言的精要介绍。通过对事务管理和并发控制的了解,我们进一步认识到了关系型数据库的核心机制,这些知识对于构建稳定、高效的关系型数据库系统至关重要。接下来的章节,我们将深入探讨数据库的设计、规范化理论、物理设计和性能优化等话题。
# 3. 数据库设计与规范化
在数据库管理系统的应用中,设计一个高效、稳定、且易于维护的数据库结构是至关重要的。良好的数据库设计不仅仅涉及到用户需求的满足,也关系到系统性能的优化和数据一致性的保证。规范化理论作为数据库设计中不可或缺的一部分,其目的就是消除数据冗余和更新异常,从而维护数据的完整性和一致性。本章将深入探讨数据库设计的整个过程,从需求分析到概念设计,再到逻辑设计和物理设计,以及最后的性能优化。
## 3.1 数据库需求分析与概念设计
### 3.1.1 需求收集与分析
在数据库设计的初期阶段,需求收集与分析是一项基础且关键的工作。这一过程需要与所有相关的业务人员和最终用户进行交流,了解他们对数据库的基本需求。需求分析的目的在于确定数据库必须支持的业务规则和数据项,以及这些数据项间的关系。
需求分析通常分为以下几个步骤:
1. **访谈和问卷:** 通过访谈潜在用户和业务人员,或者发放问卷来收集他们对数据库的需求。
2. **业务流程理解:** 深入理解业务流程,明确哪些数据是必需的,数据之间有哪些关联。
3. **需求文档编写:** 将收集到的需求汇总并编写成文档,以便在后续设计阶段使用。
### 3.1.2 E-R模型的构建
概念设计阶段的核心是创建实体-关系(Entity-Relationship,简称E-R)模型。E-R模型是一种高层数据模型,用于表示实体、实体属性以及实体间关系的图形化工具。
在构建E-R模型时,需要遵循以下步骤:
1. **确定实体:** 确定数据库中需要建模的实体,每个实体都代表了现实世界中的一个对象或者事物。
2. **定义属性:** 为每个实体定义其属性,属性描述了实体的具体特征。
3. **确定关系:** 识别实体之间的关系,包括一对一、一对多和多对多等类型。
4. **创建E-R图:** 将实体、属性和关系整合到一张图中,这张图就是E-R图。
下面是一个简单的E-R图示例代码块,用于展示一家公司的员工和部门关系:
```plaintext
[Employee] --Works In--> [Department]
```
在E-R图中,实体用矩形表示,关系用菱形表示,而属性用椭圆表示。通过E-R图,数据库设计师可以直观地展示实体间的关系,为进一步的逻辑设计提供清晰的蓝图。
## 3.2 逻辑设计与数据规范化
### 3.2.1 从E-R模型到关系模型
逻辑设计阶段主要是将概念设计中的E-R模型转换成数据库管理系统能够理解和操作的关系模型。关系模型使用一系列二维表来表达数据,每个表都有自己的列(属性)和行(元组)。
转换步骤包括:
1. **将E-R模型的实体转换为表:** 每个实体都转换成一个关系表,实体的属性成为表的列。
2. **将E-R模型的关系转换为表:** 一对多和多对多关系需要引入外键(Foreign Key)来实现。
3. **处理复合属性和多值属性:** 分解复合属性为多个列,并将多值属性转换为单独的表。
### 3.2.2 数据库的规范化理论
数据库规范化理论是关系数据库设计的一个核心概念,它通过一系列规则消除数据冗余和依赖,从而提高数据的完整性。规范化理论主要包含以下范式:
- **第一范式 (1NF):** 确保表中每个列都是不可分割的基本数据项。
- **第二范式 (2NF):** 在1NF的基础上,消除对主键部分依赖的属性。
- **第三范式 (3NF):** 在2NF的基础上,消除对主键传递依赖的属性。
规范化对于确保数据的完整性和减少更新异常至关重要。但是,需要注意的是,规范化也可能降低数据库的性能,因为它可能增加表的连接数量。因此,在设计时,需要在规范化和性能之间找到一个平衡点。
## 3.3 物理设计与性能优化
### 3.3.1 物理存储结构
物理设计阶段主要关注数据库在存储介质上的具体实现。在这一阶段,设计师需要考虑如何在硬件层面上有效地存储数据,包括定义文件存储结构、索引策略、数据分区和分布等。
物理设计的关键点包括:
1. **存储分配:** 如何在磁盘上分配和组织数据页。
2. **索引策略:** 如何创建索引以提高查询效率。
3. **数据分区:** 如何根据数据访问模式对表进行分区,以改善性能和管理。
### 3.3.2 查询优化与索引策略
查询优化是物理设计中非常重要的一环。其目标是制定有效的查询执行计划,以最小的代价获取数据。索引是查询优化中的关键工具,它可以显著减少查询所需的时间,因为索引提供了数据的快速访问路径。
索引策略的制定包括以下方面:
1. **决定索引类型:** 例如B树、哈希索引、全文索引等。
2. **选择索引列:** 根据查询模式和数据分布选择合适的列创建索引。
3. **索引维护:** 索引在使用过程中会产生碎片,需要定期维护以保持性能。
在优化查询时,数据库管理员(DBA)需要使用数据库管理系统提供的查询优化器,这是一个分析不同查询执行路径并选择最优路径的工具。通过执行计划和性能监控,DBA可以不断调整索引和查询策略,以达到最佳的性能表现。
在数据库设计的整个过程中,每个阶段都是至关重要的。需求分析与概念设计确保了数据库的业务正确性和可用性;逻辑设计与数据规范化确保了数据库的结构性和数据一致性;物理设计与性能优化确保了数据库的高效性和稳定性。只有综合考虑这些因素,才能设计出既能满足业务需求,又具有高性能的数据库系统。
# 4. 非关系型数据库简介
在数据管理领域,关系型数据库已经历了数十年的发展,并且在许多关键业务应用中都发挥着核心作用。然而,随着互联网和大数据时代的到来,数据类型多样化、数据量爆炸性增长以及实时数据处理的需求不断提出新的挑战。在此背景下,非关系型数据库(NoSQL)应运而生,因其独特的数据模型和系统设计,特别适合解决大规模分布式数据存储和快速读写访问的需求。
## 4.1 NoSQL数据库概述
### 4.1.1 NoSQL的特点与分类
NoSQL数据库旨在满足现代应用程序的特定需求,它与传统的关系型数据库有着明显的不同。NoSQL数据库有四个主要特点:水平扩展、灵活的数据模型、分布式计算和高可用性。这些特点使得NoSQL数据库在处理非结构化或半结构化数据、大数据以及提供快速读写响应时具有显著优势。
NoSQL数据库可以大致分为以下几类:
- 键值存储(Key-Value Stores):这是最简单的NoSQL数据库类型,它通过键来存储、获取和删除数据。例如,Redis和DynamoDB。
- 文档存储(Document-Oriented Stores):这类数据库存储的是文档,通常是JSON或XML格式,它们在存储层次化数据和灵活的数据结构方面很有优势。如MongoDB和CouchDB。
- 列存储(Column-Family Stores):以列簇形式存储数据,特别适合于大规模的分布式数据集,支持极高的写入吞吐量和对大量列的高效读写。如Cassandra和HBase。
- 图数据库(Graph Databases):这些数据库专门用来存储实体之间的关系,非常适合处理社交网络、推荐系统等图结构数据。如Neo4j和Amazon Neptune。
### 4.1.2 NoSQL数据库的使用场景
NoSQL数据库在处理特定类型的数据或应用需求时,可以提供更高效的解决方案。以下是NoSQL数据库常见的使用场景:
- 实时大数据分析:对于需要快速读写数据的实时分析应用,如推荐引擎,列存储可以提供极高的性能。
- 大规模数据存储:社交网络、电子商务和物联网(IoT)等应用产生大量非结构化或半结构化数据,键值存储和文档存储可以快速扩展以存储这些数据。
- 内容管理系统(CMS):内容管理系统需要灵活的数据模型来处理各种类型的媒体和内容,文档存储提供了这种灵活性。
- 高可用性和分布式计算:由于NoSQL数据库通常是分布式的,它们能在多个数据中心或云环境中提供高可用性和可扩展性。
## 4.2 分布式数据库与大数据
### 4.2.1 分布式数据库的原理
分布式数据库是数据库技术的一个重要分支,其核心原理是将数据分布式地存储在多个物理节点上,利用网络将这些节点连接起来,形成一个统一的逻辑数据库。这与传统集中式数据库有根本的不同。
分布式数据库系统设计中常见的几个关键点包括:
- 数据分片(Sharding):将数据分布式存储在多个服务器上,每个服务器存储数据的一个子集,从而减少单点故障的可能性,并提高系统的可扩展性。
- 数据复制(Replication):为了提高数据的可靠性和可用性,分布式数据库会在多个节点间复制数据。
- 一致性模型:由于数据是跨多个节点分布存储的,因此需要一致性模型来保证数据在各个节点间的一致状态。
- 分区容忍性(Partition Tolerance):网络分区是分布式系统中不可避免的现象,分区容忍性指的是系统即便在分区发生的情况下也能继续工作。
### 4.2.2 大数据环境下的数据库应用
在大数据环境下,NoSQL数据库的应用变得尤为重要,原因如下:
- **数据规模**:传统关系型数据库在处理PB级数据时会遇到性能瓶颈,而NoSQL数据库通过分布式架构设计可以更好地应对大规模数据。
- **读写负载**:大数据应用往往伴随着高频率的读写请求,NoSQL数据库通过分布式设计可以有效地扩展读写能力。
- **灵活性**:NoSQL数据库通常提供更灵活的数据模型,可以更好地适应非结构化或半结构化数据,如日志、文档、JSON、XML等格式。
- **高可用性**:在大数据应用中,数据的重要性非常高,NoSQL数据库的分布式特性使其在节点故障时仍能提供服务,保证了高可用性。
## 4.3 新型数据库技术探索
### 4.3.1 图数据库的应用
图数据库是为了解决数据之间复杂关系而设计的NoSQL数据库。它们特别适合处理高度互联的数据,如社交网络、金融欺诈检测、推荐系统等。
图数据库的优势在于:
- 高效的关联查询:在图数据库中,关系和实体被存储为图形,每个节点和边都可直接关联,查询效率远高于传统数据库。
- 灵活的模式(Schema-less):图数据库支持没有固定模式的设计,可以随时添加新的实体和关系类型。
- 自然的图形表示:复杂的关系数据可以直接表示为图形,易于理解和维护。
### 4.3.2 时间序列数据库的特性
时间序列数据库专为时间序列数据优化设计,可以高效地存储和查询时间标记的数据点。这类数据库在股票市场分析、天气数据监测、物联网等领域中至关重要。
时间序列数据库的关键特性包括:
- 时间索引:高效的时间戳索引机制,优化了时间序列数据的查询性能。
- 数据聚合:支持对时间间隔内的数据进行聚合,如求平均值、最大/最小值等,以减少数据量。
- 数据压缩:为了优化存储空间和提高读写速度,这类数据库通常采用高效的压缩算法。
- 特定查询语法:提供专门的时间序列查询语言,以支持复杂的时间序列分析操作。
时间序列数据库的例子包括InfluxDB、TimescaleDB等。
在这一章中,我们深入了解了NoSQL数据库的类型、原理和应用,探索了分布式数据库在大数据环境下的应用,以及对新型数据库技术进行了分析。通过这些内容,我们认识到NoSQL数据库在现代数据管理中的重要性和多样性。在下一章节中,我们将探讨数据库的安全性与备份策略。
# 5. 数据库的安全性与备份
## 5.1 数据库安全策略
### 5.1.1 认证与授权机制
数据库认证是确保只有合法用户能访问数据的第一道防线。认证机制通常分为三种类型:基于知识的认证、基于持有的认证和基于身份的认证。其中,基于知识的认证是通过密码或PIN码来实现的;基于持有的认证依赖于物理令牌或设备,比如手机上的验证码或硬件令牌;基于身份的认证则依赖于生物识别技术,如指纹识别、虹膜扫描或面部识别。
授权机制确保经过认证的用户只能执行他们被授权的操作。在数据库系统中,访问控制列表(ACL)和角色基础的访问控制(RBAC)是常见的授权方式。通过定义用户角色和权限,系统管理员能够控制不同用户对数据库资源的访问权限。例如,一个普通用户可能只能读取数据,而管理员则可以修改数据。
### 5.1.2 安全审计与加密技术
数据库安全审计是对数据库访问和活动的持续监控和记录,用于检测和分析潜在的安全威胁。安全审计工具会记录谁在什么时间对数据库进行了什么操作,帮助管理员追踪异常行为,并作为事后分析的依据。在实施安全审计时,应该考虑审计的粒度和性能开销,避免对系统性能造成显著影响。
数据库加密技术用于保护数据在存储和传输过程中的安全性。常见的加密方法包括对称加密和非对称加密。对称加密速度快但密钥管理复杂,而非对称加密则提供了一个安全的密钥交换机制,但处理速度慢。在实际应用中,两者常常结合使用,例如,使用非对称加密来安全地交换对称加密的密钥,然后使用对称加密来加密数据库中的数据。
## 5.2 数据库备份与恢复
### 5.2.1 备份的策略与方法
备份数据库是确保数据安全和可用性的关键措施。备份策略需要根据业务需求、数据重要性及恢复时间目标(RTO)和恢复点目标(RPO)来制定。备份类型主要分为全备份、增量备份和差异备份。
全备份是备份数据库中的所有数据。它在备份时间上最长,但恢复速度最快。增量备份只备份自上次备份以来发生变化的数据,节省了存储空间并减少了备份时间,但恢复过程比较复杂。差异备份则备份自上次全备份以来的所有变化数据,其恢复速度和存储空间需求介于全备份和增量备份之间。
### 5.2.2 恢复技术与灾难恢复计划
数据库恢复是指在数据丢失或损坏后,使用备份数据将数据库还原到某个一致状态的过程。恢复技术包括冷备份恢复和热备份恢复。冷备份恢复是将备份数据直接复制到原位置,而热备份恢复则包括日志重做和撤销未完成的事务等步骤,保证数据的一致性。
灾难恢复计划是企业应对可能发生的灾难性事件(如自然灾害、硬件故障等)的预案。一个有效的灾难恢复计划应包括定期的备份策略、备份数据的远程存储、备用数据库服务器的准备以及灾难发生时的快速响应流程。通过灾难恢复计划的实施,能够最大限度地减少数据丢失和业务中断的风险。
## 表格展示
| 备份类型 | 优点 | 缺点 | 应用场景 |
| --- | --- | --- | --- |
| 全备份 | 简单快速恢复 | 需要大量存储空间,备份时间长 | 数据库初次部署或重要更新后 |
| 增量备份 | 节省存储空间,备份快速 | 恢复复杂,耗时 | 经常变动的数据集 |
| 差异备份 | 平衡的存储需求和恢复速度 | 介于全备份和增量备份之间 | 日常备份,结合全备份使用 |
## 代码块及分析
以下是一个简单的脚本,用于执行一次数据库全备份:
```sql
BACKUP DATABASE [AdventureWorks]
TO DISK = 'D:\Backups\AdventureWorks.bak'
WITH FORMAT,
MEDIANAME = 'AdventureWorks Backup',
NAME = 'Full Backup of AdventureWorks';
```
- `BACKUP DATABASE` 指令开始备份指定的数据库。
- `TO DISK` 指定了备份文件的存储路径和名称。
- `WITH FORMAT` 用于创建一个新的备份集,并覆盖任何旧的备份集。
- `MEDIANAME` 可以用来标识磁带的媒体家族,这里也用于文件名。
- `NAME` 定义了备份集的描述性名称。
在执行这个脚本前,确保有足够的磁盘空间,并且数据库服务已经停止或数据库处于可以备份的状态。另外,定期备份策略的实施通常需要结合任务调度程序(例如 SQL Server Agent)来自动执行脚本。
## 流程图展示
```mermaid
graph LR
A[开始备份] --> B[检查存储空间]
B --> C[选择备份类型]
C --> D[执行备份操作]
D --> E[备份成功?]
E -- 是 --> F[备份完成]
E -- 否 --> G[处理错误]
F --> H[备份记录]
G --> I[告警和日志记录]
H --> J[备份文件存档]
I --> K[手动干预]
```
该流程图描述了数据库备份的逻辑流程,从开始备份到备份成功或失败的处理。它强调了备份前的准备工作和备份操作后的检查步骤。如果备份失败,需要进行错误处理和日志记录,确保问题可以追踪和解决。
在实际操作中,备份和恢复策略的制定应该是一个持续的过程,需要不断地评估、测试和优化,以确保在数据安全性和业务连续性方面达到最佳平衡。
# 6. 数据库系统的未来趋势
## 6.1 云数据库的发展与应用
随着云计算的快速发展,云数据库作为一种新的数据库服务模式,正在逐渐改变企业和个人存储、管理和使用数据的方式。云数据库是指基于云平台提供数据库服务的一种数据库系统,用户无需自行搭建和维护硬件环境,可以在任何时间、任何地点通过网络访问和使用数据库服务。
### 6.1.1 云计算环境下的数据库服务
在云计算环境中,数据库服务通常以三种形式提供:IaaS(基础设施即服务)、PaaS(平台即服务)和SaaS(软件即服务)。
- **IaaS** 提供虚拟化的计算资源,包括虚拟机、存储等。在IaaS层面上,数据库管理员负责安装和配置数据库软件。
- **PaaS** 提供了数据库服务的运行平台,包括操作系统、数据库管理系统、编程语言执行环境等。在PaaS层面上,数据库管理员关注数据库配置和管理而非底层硬件。
- **SaaS** 提供包括数据库在内的应用程序。在这种模式中,数据库管理员的角色更多地转向数据治理和数据分析,而不是传统的数据库管理。
### 6.1.2 云数据库的优势与挑战
云数据库具有多种优势,包括可扩展性、弹性、多租户支持以及较低的总体拥有成本。然而,它们也面临着数据安全、合规性和性能等挑战。
#### 优势
- **弹性**:云数据库支持按需扩展资源,能够快速适应业务需求的变化。
- **高可用性**:通过数据复制和分布式架构,云数据库可以确保高可用性。
- **成本效益**:云数据库服务通常按使用量计费,可以减少前期的资本支出。
#### 挑战
- **数据安全**:如何确保数据在云中的安全是一个重要的问题。
- **性能**:网络延迟和带宽限制可能会影响云数据库的性能。
- **合规性**:数据可能存储在不同国家或地区,需要遵守各自的法律和规定。
### 6.1.3 云数据库服务提供商示例
- **Amazon Web Services (AWS)** 提供RDS、DynamoDB等数据库服务。
- **Microsoft Azure** 提供Azure SQL Database、Cosmos DB等服务。
- **Google Cloud** 提供Cloud SQL、Cloud Spanner等数据库服务。
## 6.2 人工智能与数据库技术的融合
人工智能(AI)和数据库技术的融合是当前数据库系统发展的另一个重要趋势。AI和机器学习的算法需要大量数据支持,数据库作为存储和处理数据的核心技术,为AI提供了必要的基础设施。
### 6.2.1 数据库在AI中的应用案例
在AI应用中,数据库不仅用于存储训练数据和结果,还用于实时数据的处理和分析。例如,通过数据库技术,可以实现对实时监控视频流的分析和处理,快速响应变化并做出预测。
### 6.2.2 数据库系统自适应和自学习能力的发展
随着技术的进步,数据库系统正逐步增加自适应和自学习的能力。通过集成机器学习算法,数据库可以自动调整查询优化策略,提高查询性能和准确性。
## 6.3 持续学习和适应:数据库管理员的新角色
数据库管理员(DBA)的角色在不断演变,不仅需要掌握传统的数据库管理技能,还需要不断学习新技术,如云技术、大数据、AI等。
### 6.3.1 持续学习的重要性
在快速发展的IT行业中,持续学习是保持竞争力的关键。DBA需要不断更新知识库,以适应新技术带来的挑战。
### 6.3.2 数据库管理员的技能提升路径
DBA的技能提升路径可能包括:
- 学习和掌握云数据库服务的管理。
- 深入了解AI和机器学习技术,理解它们如何与数据库技术结合。
- 掌握自动化工具和脚本编写技能,以提高工作效率。
通过这些方式,DBA可以更好地适应未来的技术趋势,确保数据库系统的稳定和安全运行。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《数据库系统概念第六版3答案》专栏为数据库专业人士和学习者提供全面的知识和实践指导。专栏涵盖了从基础知识到高级概念的广泛主题,包括:
* 数据库基础知识:构建坚实的数据系统理论基础
* SQL语言精进:掌握核心查询优化技术
* 数据库规范化:从理论到实践的进阶指南
* 事务处理与并发控制:维护数据库一致性的核心策略
* 数据库性能监控与调优:从指标到优化的实战方法
* 数据库备份与恢复:保障数据安全的核心策略
* 数据库日志分析与故障诊断:深入剖析数据库健康
* NoSQL数据库的崛起:理解和应用非关系型数据库
* 大数据与数据库技术的融合:探索数据的新维度
* 数据库集群与复制技术:提升可用性和伸缩性
* 数据库中间件的应用与优化:连接应用与数据的桥梁
* 数据库缓存策略:优化性能的秘密武器
* 数据库自动化部署与运维:提高效率的现代实践
* 数据库版本控制与迁移策略:保障系统平滑升级
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
揭秘以太网的演化之旅:从10Mbps到100Gbps的跨越

# 摘要
本文详细介绍了以太网从诞生至今的发展历程,以及其基础技术和标准演进。通过对以太网工作原理和标准的深入分析,本文阐述了从10Mbps到100Gbps关键技术的发展以及数据中心应用和管理。文章还探讨了以太网未来的展望,包括速度增长的潜力、绿色以太网的发展以及面临的挑战,如安全性问题和网络拥塞。文中提供了以太网技术的未来趋势预测,并建议了相应的解决方案,以期为网络技
【跨浏览器控件SDK高级应用】:个性化控件体验打造指南,代码级别的定制技巧

# 摘要
随着网络应用的日益复杂和多样化,跨浏览器控件SDK为开发者提供了一套高效的解决方案,以实现一致的用户体验。本文首先概述了跨浏览器控件SDK的概念和架构,深入探讨了其核心组件、兼容性处理和性能优化策略。随后,本文着重于控件SDK在个性化体验和高级应用方面的代码实现技巧,包括外观定制、动态行为实现和用户交互增强。接着,本文介绍了高级应用技巧,如数据绑定、模板技术以及安全性和代码保护措施。最
【Python新手变专家秘籍】:掌握这100个关键习题

# 摘要
Python作为一种流行的高级编程语言,以其简洁的语法和强大的功能,广泛应用于Web开发、数据分析、自动化脚本编写以及人工智能等众多领域。本文从基础概念开始,涵盖了Python的环境搭建、核心语法、面向对象编程基础、高级特性和模块应用。同时,通过实践项目和问题解决部分,深入探讨了Python在Web开发、数据分析与可视化以及自动化脚本编写方面的实际应用。本文还进一步对Python的并发编程、算法和数据结构、以及机器学习和人工智能的基
Sybyl_X 1.2环境搭建教程:专业配置一步到位

# 摘要
本文全面介绍了Sybyl_X 1.2环境的搭建和优化过程。首先,我们从硬件和软件需求出发,为安装Sybyl_X 1.2做好前期准备工作。接着,详细描述了软件的官方安装包下载、验证和安装步骤,包括图形界面和命令行两种安装方式,并提供了常见的问题解决方案。安装完成后,本文进一步阐述了环境验证和功能性测试的必要步骤,确保软件的正确运行。此外,还介绍了扩展组件和插件的选择、安装
【iOS UDID的秘密】:深度挖掘UDID在开发者工具中的关键作用

# 摘要
UDID(唯一设备识别码)作为iOS设备的身份标识,在过去的iOS开发中扮演了重要角色。本文首先介绍了UDID的定义与历史,阐述了其在iOS开发中的理论基础,包括UDID的定义、作用和与开发者工具的关联。随后,本文探讨了UDID的管理与限制,以及在应用测试和
公共云SDM(MRCP-SERVER)故障全解析:快速排错与解决方案

# 摘要
随着云计算技术的发展和应用的普及,公共云SDM(MRCP-SERVER)在提供高质量语音服务中扮演着关键角色。然而,SDM平台的稳定性和可靠性是持续面临挑战,故障的发生可能对服务造成重大影响。本文首先概述了公共云SDM(MRCP-SERVER)的常见故障类型和影响,并详细探讨了故障诊断的理论基础,包括故障
【光伏组件性能优化秘籍】:5大技巧提升效率与寿命
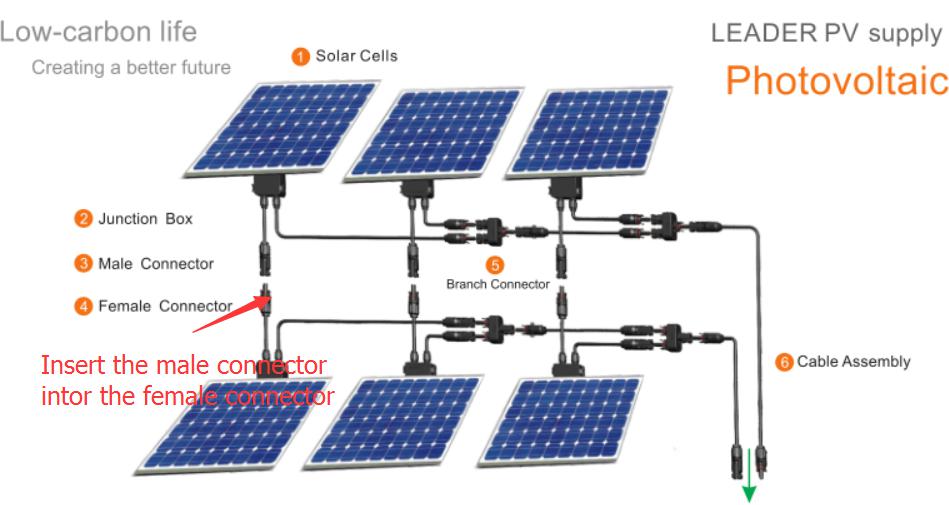
# 摘要
随着可再生能源的快速发展,光伏组件性能优化成为了提高能源转换效率、降低发电成本的关键因素。本文首先概述了光伏组件性能优化的重要性,接着介绍了光伏组件的理论基础、工作原理、电性能参数以及故障诊断与预测维护理论。在实践技巧方面,文中探讨了安装定位、清洁维护策略、热管理和冷却技术的优化方法。此外,本文还详细阐述了光伏系统智能监控与数据分析的重要性,以及如何通过分析工具与AI预测模型来评估和优化系统性能。最后,本文探讨了光伏组
业务定制:根据独特需求调整CANSTRESS
# 摘要
本文针对CANSTRESS业务定制进行了全面概述和分析,探讨了CANSTRESS的原理、架构及其工作机制和性能指标。通过需求分析方法论,本文收集并分类了独特业务需求,并确定了定制化目标。技术实现章节详细阐述了模块化定制的步骤和方法,算法优化的原则,以及系统集成与测试策略。实践案例分析展示了定制实施的过程和效益评估。最后,本文对未来技术革新下的CANSTRESS适应性、定制化服务市场潜力及持续改进优化路径进行了展望,指出这些因素对于推动业务定制服务的未来发展具有重要意义。
# 关键字
CANSTRESS;业务定制;模块化;算法优化;系统集成;ROI分析;技术革新
参考资源链接:[C
Pycharm用户必读:一步到位解决DLL load failed问题指南
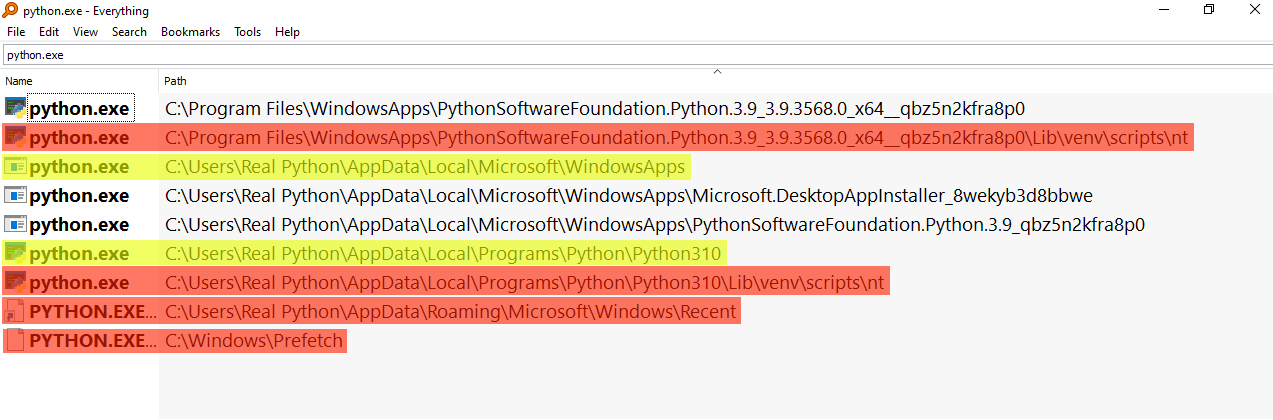
# 摘要
本文深入探讨了Pycharm环境下遇到的DLL文件加载失败问题,提供了对DLL load failed错误的综合理解,并分享了多种实用的解决策略。通过详细分析DLL文件的基本概念、作用机制以及在Windows系统中的工作原理,本文旨在帮助开发者诊断和修复与DLL相关的错误。同时,文章还介绍了Pycharm中的依赖管理和环境变量配置,强调了
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )