【Python与Google App Engine】:精通模块化开发的6大关键功能
发布时间: 2024-10-14 08:41:30 阅读量: 3 订阅数: 4 

# 1. Python与Google App Engine简介
Python作为一种高级编程语言,以其简洁的语法和强大的库支持在开发领域广泛应用。它的动态类型系统和解释性质使得Python在快速开发和迭代中表现出色。Google App Engine(GAE)则是一个由Google提供的全托管的平台即服务(PaaS)解决方案,它允许开发者构建、部署和扩展Web应用和移动后端。
## 1.1 Python的特性和应用场景
Python拥有许多吸引开发者的特点,如动态类型、内存管理、广泛的第三方库和框架。这些特性使得Python非常适合Web开发、数据分析、人工智能、科学计算等领域。
### 特点
- **动态类型**:开发者不需要在编写代码时声明变量类型。
- **解释执行**:Python代码在执行前不需要编译,提高了开发效率。
- **丰富的库和框架**:例如Django和Flask用于Web开发,NumPy和Pandas用于数据分析。
### 应用场景
- **Web开发**:通过框架如Django和Flask,可以快速构建和部署复杂的Web应用。
- **数据科学**:利用NumPy、Pandas和Scikit-learn等库进行数据处理和机器学习。
- **自动化脚本**:编写脚本来自动化日常任务,如文件操作、系统管理等。
## 1.2 Google App Engine简介
Google App Engine提供了一个高度可扩展的平台,允许开发者专注于编写应用代码,而不必担心服务器的配置和管理。GAE支持多种编程语言,包括Python,并提供了多种服务和工具来帮助开发者构建可扩展的应用。
### 核心功能
- **全托管**:GAE负责底层硬件和软件的管理,开发者无需处理服务器。
- **可扩展性**:应用可以根据流量自动扩展,无需手动干预。
- **集成服务**:提供了数据库、缓存、任务队列等集成服务。
### 开发优势
- **快速部署**:应用可以快速上线并响应用户请求。
- **高可用性**:GAE提供了高可用性的基础设施,确保应用稳定运行。
- **成本控制**:按实际使用量计费,无需为峰值容量支付额外费用。
# 2. 模块化开发的基本原理
模块化开发是软件工程中的一种重要思想,它将复杂系统分解为独立、可替换的模块,以提高代码的可维护性和可重用性。在Python和Google App Engine的开发实践中,模块化是构建高效、可扩展应用的关键。
## 2.1 模块化概念与优势
### 2.1.1 模块化的定义
模块化是指将程序分解成独立的模块单元,每个模块都包含特定的功能和职责。这些模块可以独立开发、测试和维护,并且可以组合成更大的系统。在Python中,模块可以是一个`.py`文件,包含函数、类和变量。
### 2.1.2 模块化开发的优势
模块化开发主要有以下优势:
- **可维护性**:模块化使得代码更加清晰和易于理解,便于维护和升级。
- **可重用性**:模块可以被复用于不同的项目或应用中,无需重复编写代码。
- **可测试性**:独立的模块可以单独测试,提高了代码的可靠性。
- **并行开发**:不同的开发团队可以同时工作在不同的模块上。
## 2.2 Python模块与包
### 2.2.1 模块的导入与使用
在Python中,模块可以通过`import`语句导入和使用。例如:
```python
import math
print(math.sqrt(16))
```
这段代码导入了`math`模块,并使用了其中的`sqrt`函数来计算16的平方根。
### 2.2.2 包的结构与命名空间
包(Package)是包含多个模块的集合,它们通常是相关功能的集合。在文件系统中,包是一个包含`__init__.py`文件的文件夹。例如,`requests`库就是一个包,它包含多个模块,如`requests.models`、`requests.sessions`等。
命名空间是Python中的一个概念,用于避免命名冲突。每个模块和包都有自己的命名空间。
## 2.3 Google App Engine的沙盒环境
### 2.3.1 沙盒环境的概念
沙盒环境是一种安全机制,它为运行中的程序提供了一个隔离的环境,防止程序对系统造成未授权的访问或修改。在Google App Engine中,每个应用运行在一个沙盒环境中,确保了应用之间的隔离和安全。
### 2.3.2 沙盒环境对模块化的影响
由于沙盒环境的存在,应用需要在环境的限制内运行。这意味着模块化开发在App Engine中需要考虑沙盒环境的限制,例如文件系统访问、网络通信等。开发者需要利用App Engine提供的API和服务来实现模块间的交互。
在本章节中,我们介绍了模块化开发的基本概念、Python中模块和包的使用,以及Google App Engine沙盒环境对模块化的影响。接下来的章节将进一步探讨如何构建模块化应用的实践技巧。
# 3. 构建模块化应用的实践技巧
在本章节中,我们将深入探讨如何在Python与Google App Engine的结合下,构建模块化应用的实践技巧。模块化开发是现代软件工程的关键组成部分,它允许开发者构建可维护、可扩展的应用程序。我们将从设计可重用的模块开始,探讨模块化设计原则,模块的接口与抽象,然后讨论高效模块间通信的实现方式,包括函数与对象的调用,以及事件驱动与消息队列的应用。最后,我们将讨论版本控制与依赖管理的最佳实践,以及如何选择和使用依赖管理工具。
## 3.1 设计可重用的模块
### 3.1.1 模块化设计原则
模块化设计原则是构建模块化应用的基础。这些原则帮助开发者创建独立、可复用的代码块,从而提高代码的可维护性和可扩展性。
#### *.*.*.* 单一职责原则
单一职责原则是模块化设计的核心。每个模块应该只有一个职责或功能。这有助于减少模块之间的耦合,使得代码更加清晰和易于维护。
```python
# 示例代码:单一职责原则
class UserModule:
def __init__(self):
pass
def get_user_data(self, user_id):
# 获取用户数据
pass
def save_user_data(self, user_data):
# 保存用户数据
pass
def delete_user_data(self, user_id):
# 删除用户数据
pass
```
#### *.*.*.* 低耦合高内聚
低耦合高内聚是模块化设计的另一个重要原则。模块之间的耦合应该尽可能低,而模块内部的功能应该紧密相关。
### 3.1.2 模块的接口与抽象
设计模块时,接口和抽象是关键。接口定义了模块与外界交互的方式,而抽象则是实现接口的具体方式。
#### *.*.*.* 接口定义
接口定义了模块提供的服务和可以调用的方法。在Python中,接口通常通过抽象基类(ABC)来实现。
```python
from abc import ABC, abstractmethod
class ModuleInterface(ABC):
@abstractmethod
def get_data(self):
pass
```
#### *.*.*.* 抽象实现
抽象实现提供了接口的具体实现。在Python中,可以使用抽象基类的子类来实现抽象方法。
```python
class UserModuleImpl(ModuleInterface):
def get_data(self):
# 实现获取数据的具体逻辑
pass
```
## 3.2 高效的模块间通信
### 3.2.1 函数与对象的调用
模块间通信是模块化应用的关键。Python提供了多种方式来调用函数和对象。
#### *.*.*.* 函数调用
函数调用是模块间通信的基础。在Python中,函数可以作为参数传递给其他函数或方法。
```python
def process_data(func, data):
# 使用函数处理数据
return func(data)
def transform_data(data):
# 数据转换逻辑
return data.upper()
# 调用示例
result = process_data(transform_data, "hello")
print(result) # 输出: HELLO
```
### 3.2.2 事件驱动与消息队列
除了函数调用,事件驱动和消息队列是模块间通信的高级方式。
#### *.*.*.* 事件驱动
事件驱动允许模块通过监听和响应事件来进行通信。Python中的`asyncio`库可以用来实现事件驱动的通信。
```python
import asyncio
async def handle_event(event):
# 处理事件
print(f"Event received: {event}")
async def event_loop():
# 创建事件循环
event = await asyncio.wait_for(asyncio.Future(), timeout=5)
await handle_event(event)
# 启动事件循环
asyncio.run(event_loop())
```
#### *.*.*.* 消息队列
消息队列允许模块通过发送和接收消息来进行通信。`redis-py`库可以用来实现基于Redis的消息队列。
```python
import redis
class MessageQueue:
def __init__(self):
self.client = redis.StrictRedis(host='localhost', port=6379, db=0)
def send_message(self, channel, message):
self.client.publish(channel, message)
def receive_message(self, channel):
pubsub = self.client.pubsub()
pubsub.subscribe(channel)
message = pubsub.get_message()
return message.get('data')
# 使用示例
mq = MessageQueue()
mq.send_message('example', 'Hello, world!')
print(mq.receive_message('example')) # 输出: Hello, world!
```
## 3.3 版本控制与依赖管理
### 3.3.1 版本控制的最佳实践
版本控制是管理代码变更的重要工具。在本小节中,我们将讨论版本控制的最佳实践。
#### *.*.*.* 使用Git进行版本控制
Git是目前最流行的版本控制系统。它允许开发者创建分支,进行并行开发,并且可以轻松地合并更改。
```bash
# 初始化Git仓库
git init
# 添加文件到暂存区
git add .
# 提交更改
git commit -m "Initial commit"
# 创建新分支
git branch feature-branch
# 切换到新分支
git checkout feature-branch
# 合并分支
git merge feature-branch
```
### 3.3.2 依赖管理工具的选择与使用
依赖管理是管理项目依赖的工具。在Python中,`pip`是最常用的依赖管理工具。
#### *.*.*.* 使用pip进行依赖管理
`pip`是Python的包管理工具,它可以安装和管理Python包。
```bash
# 安装包
pip install package-name
# 更新包
pip install --upgrade package-name
# 列出已安装的包
pip list
```
通过本章节的介绍,我们了解了如何设计可重用的模块,实现高效的模块间通信,以及如何进行版本控制和依赖管理。这些实践技巧是构建模块化应用的关键,它们可以帮助开发者创建更加健壮、可维护的应用程序。
# 4. Google App Engine特色功能
在本章节中,我们将深入探讨Google App Engine(GAE)的特色功能,这些功能是构建高效、可扩展的Web应用的关键。我们将从数据存储与管理开始,然后讨论异步任务处理和安全与合规性问题。每个主题都将结合实际应用案例和最佳实践,帮助读者更好地理解和运用这些特色功能。
## 4.1 数据存储与管理
Google App Engine提供了多种数据存储选项,包括Datastore、Memcache等。这些工具的设计旨在帮助开发者存储和检索数据,同时保持应用的高性能和可扩展性。
### 4.1.1 Datastore的基本操作
Google App Engine Datastore是一个高度可扩展的NoSQL数据库,它支持结构化数据存储,并且可以自动处理数据的分区和复制。Datastore适用于处理大量数据的应用,特别是那些需要高可用性和水平扩展性的应用。
#### 操作步骤
1. **初始化Datastore客户端**
在Python代码中,首先需要初始化Datastore客户端。这通常涉及到创建一个`Client`对象,使用应用的`app.yaml`配置文件中的默认项目ID。
```python
from google.cloud import datastore
client = datastore.Client(project='your-project-id')
```
2. **查询数据**
查询是Datastore中常见的操作。下面的代码展示了如何执行一个简单的查询来获取所有实体。
```python
query = client.query(kind='YourEntity')
results = list(query.fetch(limit=10))
```
在这个例子中,`kind`参数指定了要查询的实体类型。`fetch`方法用于获取查询结果。
#### 参数说明
- `kind`: 指定实体类型。
- `limit`: 限制查询返回的结果数量。
### 4.1.2 Memcache与缓存策略
Memcache是一个分布式内存缓存系统,它可以提高应用的性能,通过减少数据库的访问次数来缓存频繁使用的数据。
#### 使用Memcache
在GAE中使用Memcache非常简单,首先需要获取Memcache客户端,然后进行读写操作。
```python
from google.appengine.api import memcache
def get_value(key):
# 尝试从缓存中获取值
value = memcache.get(key)
if value is None:
# 缓存未命中,从数据库或其他数据源获取
value = fetch_from_database(key)
# 将值存储到缓存中
memcache.set(key, value)
return value
def fetch_from_database(key):
# 这里是获取数据的逻辑,例如从数据库查询
pass
```
#### 缓存策略
正确实施缓存策略是高效利用Memcache的关键。以下是一些推荐的缓存策略:
- **过期时间**:为每个缓存项设置一个合理的过期时间。
- **缓存失效**:在数据更新后,立即使相关的缓存项失效。
- **缓存穿透**:对于不存在的数据,也要设置一个缓存项,避免大量的无效查询。
## 4.2 异步任务处理
在现代Web应用中,异步任务处理是一个重要的特性,它可以提高应用的响应性和可扩展性。GAE提供了Task Queue来处理异步任务。
### 4.2.1 Task Queue的使用
Task Queue允许应用将任务排队,并在后台处理它们。这些任务可以是时间消耗型的,比如发送电子邮件,或者是重复性的,比如定时更新数据。
#### 创建任务
以下是一个创建并添加任务到队列的示例。
```python
from google.appengine.api import taskqueue
def enqueue_task(url, payload=None, queue_name='default'):
task = taskqueue.Task(url=url, payload=payload, queue_name=queue_name)
taskqueue.add(task=task)
def handle_task(request):
# 处理任务的逻辑
pass
```
在这个例子中,`enqueue_task`函数用于创建并排队一个任务。`url`参数指定了任务处理的URL,`payload`参数是传递给处理函数的额外数据。
### 4.2.2 Cron作业调度
除了手动触发任务外,GAE的Task Queue还支持Cron作业调度,允许定时执行任务。
#### 配置Cron作业
在`app.yaml`文件中配置Cron作业非常简单。
```yaml
cron:
- description: "每天凌晨1点更新数据"
url: "/cron/update-data"
schedule: "0 1 ***"
```
在这个配置中,`schedule`字段使用了cron表达式来定义执行频率。这个Cron作业每天凌晨1点触发。
### 4.3 安全与合规性
随着应用的发展,安全和合规性变得越来越重要。GAE提供了一系列安全特性来保护应用和数据。
### 4.3.1 Google App Engine的安全模型
GAE的安全模型包括身份验证、授权、网络防护等多个方面。
#### 身份验证
GAE提供了多种身份验证方法,包括OAuth 2.0、Google账户登录等。
```python
from google.appengine.api import users
def login(request):
if users.is_current_user_admin():
# 用户是管理员
pass
else:
# 用户不是管理员
pass
```
在这个例子中,`users.is_current_user_admin()`方法检查当前用户是否是管理员。
### 4.3.2 合规性考量与实践
合规性是确保应用遵循行业标准和法规要求的过程。GAE提供了多种工具和最佳实践来帮助开发者确保应用的合规性。
#### 实践建议
- **数据加密**:使用GAE提供的加密工具对敏感数据进行加密。
- **访问控制**:严格控制对敏感数据的访问权限。
- **日志记录**:记录所有访问和操作,以便进行审计和故障排除。
在本章节中,我们介绍了GAE的特色功能,包括数据存储与管理、异步任务处理以及安全与合规性。这些功能是构建可靠、高效和安全的Web应用的关键。通过理解这些概念和实践,开发者可以更好地利用GAE的优势,创建出色的应用。
# 5. 模块化开发高级应用
## 5.1 微服务架构在App Engine中的实现
在微服务架构中,应用程序被分解为一组小型、独立的服务,每个服务运行在其独立的进程中,并通过轻量级机制(通常是HTTP资源API)进行通信。微服务架构的优势在于其提供了更高的灵活性、可扩展性和可维护性。在Google App Engine平台上,我们可以利用其强大的服务支持来实现微服务架构。
### 5.1.1 微服务的概念与优势
微服务架构的核心概念是将复杂的应用程序分解为一组小的、松耦合的服务。每个服务实现特定的业务功能,并可以通过API与其它服务交互。以下是微服务的一些主要优势:
- **服务自治**:每个微服务可以独立开发、部署和扩展。
- **技术多样性**:不同的服务可以使用不同的编程语言和数据存储技术。
- **弹性与容错性**:单个服务的故障不会影响到整个系统。
- **可扩展性**:可以根据需要独立扩展特定服务。
### 5.1.2 App Engine中的微服务实践
在App Engine中实现微服务通常涉及以下步骤:
1. **服务划分**:根据业务功能将应用程序分解为多个服务。
2. **API设计**:为每个服务设计RESTful API,以实现服务之间的通信。
3. **服务部署**:将每个微服务独立部署到App Engine的实例中。
4. **服务发现**:使用App Engine的服务发现机制来定位和连接服务。
#### 示例代码
假设我们有一个简单的用户管理系统,可以将其拆分为以下微服务:
- 用户服务(User Service)
- 订单服务(Order Service)
**用户服务(User Service)代码示例:**
```python
# user_service.py
from flask import Flask, jsonify, request
app = Flask(__name__)
# 假设的用户数据
users = {
"user1": {"name": "Alice", "email": "***"},
"user2": {"name": "Bob", "email": "***"}
}
@app.route('/user/<username>', methods=['GET'])
def get_user(username):
return jsonify(users.get(username, "User not found"))
if __name__ == '__main__':
app.run(host='***.*.*.*', port=8000)
```
**订单服务(Order Service)代码示例:**
```python
# order_service.py
from flask import Flask, jsonify, request
app = Flask(__name__)
# 假设的订单数据
orders = {
"order1": {"user_id": "user1", "items": ["book", "pen"]},
"order2": {"user_id": "user2", "items": ["phone"]}
}
@app.route('/order/<order_id>', methods=['GET'])
def get_order(order_id):
return jsonify(orders.get(order_id, "Order not found"))
if __name__ == '__main__':
app.run(host='***.*.*.*', port=8001)
```
**服务发现**
在App Engine中,服务可以通过自动发现机制进行查找。以下是使用App Engine的服务发现机制来连接用户服务和订单服务的示例:
```python
# discovery_client_example.py
from google.appengine.api import discovery
from google.appengine.api import users
def find_user_service():
# 使用App Engine服务发现机制找到用户服务
user_service_url = discovery.find_service_url('user-service', version='v1')
return user_service_url
def find_order_service():
# 使用App Engine服务发现机制找到订单服务
order_service_url = discovery.find_service_url('order-service', version='v1')
return order_service_url
def main():
user_service_url = find_user_service()
order_service_url = find_order_service()
# 使用发现的URL来调用其他服务的API
# 示例:获取用户信息
user_response = requests.get(f"{user_service_url}/user/user1").json()
print(user_response)
if __name__ == '__main__':
main()
```
在这个示例中,我们展示了如何在App Engine中设置和发现微服务,并通过HTTP请求调用它们的API。每个服务都是独立的,可以独立部署和扩展。这种架构使得每个团队都可以专注于服务的开发和维护,而不必担心整个应用程序的复杂性。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
专栏深入探讨了 Google App Engine 工具库,提供了全面的指南,帮助开发者充分利用这个强大的云平台。从快速入门到高级优化,专栏涵盖了各个方面,包括模块化开发、本地环境搭建、Web 服务开发、性能提升、数据存储、错误处理、缓存机制、实例扩展、静态文件管理、云服务集成、自动化测试、CI/CD 实践和应用监控。通过一系列循序渐进的步骤和实用技巧,专栏旨在帮助开发者构建高效、可扩展且可靠的云端应用。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Django信号错误处理】:优雅处理异常,保证系统健壮性

# 1. Django信号机制概述
Django作为Python的一个高级Web框架,其信号机制是一种强大的工具,允许开发者在特定的事件发生时执行自定义的代码。这种机制类似于发布/订阅模式,允许组件之间的松耦合。在Django中,信号可以在模型保存、删除、表单验证
Jinja2模板中的条件逻辑详解:实现复杂逻辑判断的秘诀

# 1. Jinja2模板概述
Jinja2是Python中最流行的模板引擎之一,它广泛应用于Web开发框架如Flask和Django中,用于生成动态HTML页面。Jinja2模板使用简洁的语法,允许开发者将Python风格的逻辑集成到HTML模板中,而无需编写复杂的代码。
Jinja2的核心优势在于它的安全性。模板中的变量和表达式都在沙盒环境中执行,这意味着模板作者无法访问服务器的敏感数据,
测试套件管理艺术:Python test库中的测试集组织技巧
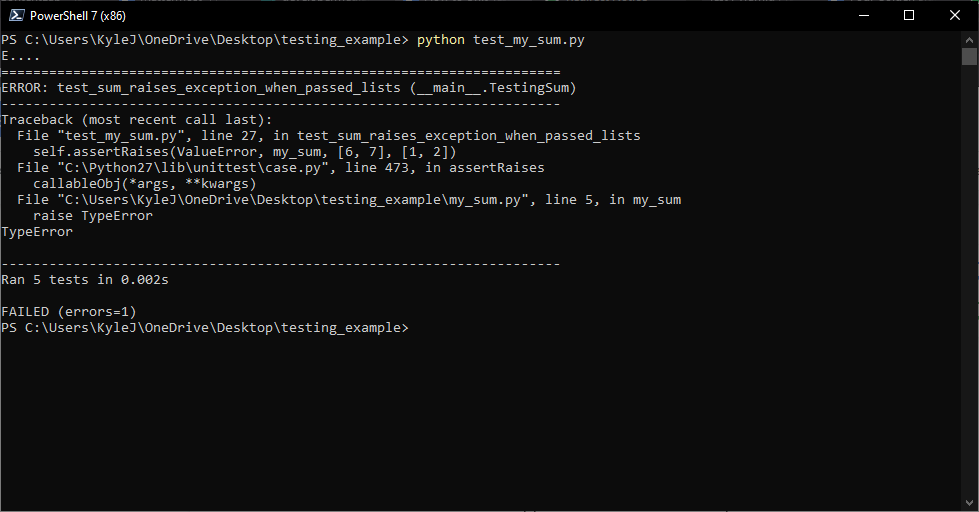
# 1. Python测试库概述
## 1.1 测试库的重要性
在软件开发过程中,自动化测试是确保产品质量的关键环节。Python作为一门广受欢迎的编程语言,拥有众多强大的测试库,这些库极大地简化了测试过程,提高了测试效率。通过使用这些库,开发者可以轻松编写测试脚本,自动化执行测试用例,并生成详细的测试报告。
## 1.2 常用的Python测试库
Python社区提供了多种
【并发处理】:django.db.connection在高并发场景下的应用,提升并发处理能力

# 1. 并发处理的基础概念
## 1.1 并发与并行的区别
在讨论并发处理之前,我们首先需要明确并发与并行的区别。并发是指两个或多个事件在同一时间间隔内发生,而并行则是指两个或多个事件在同一时刻同时发生。在计算机系统中,由于硬件资源的限制,完全的
Python库文件学习之HTTPServer:基础概念与代码示例
# 1. HTTPServer的基本概念和功能
在互联网技术的众多组成部分中,HTTPServer扮演着至关重要的角色。HTTPServer,即HTTP服务器,是实现Web服务的基础,它负责处理客户端(如Web浏览器)发出的HTTP请求,并返回相应的响应。HTTPServer不仅能够提供静态内容(如HTML文件
Numpy.random随机信号处理:数字信号分析的核心技术
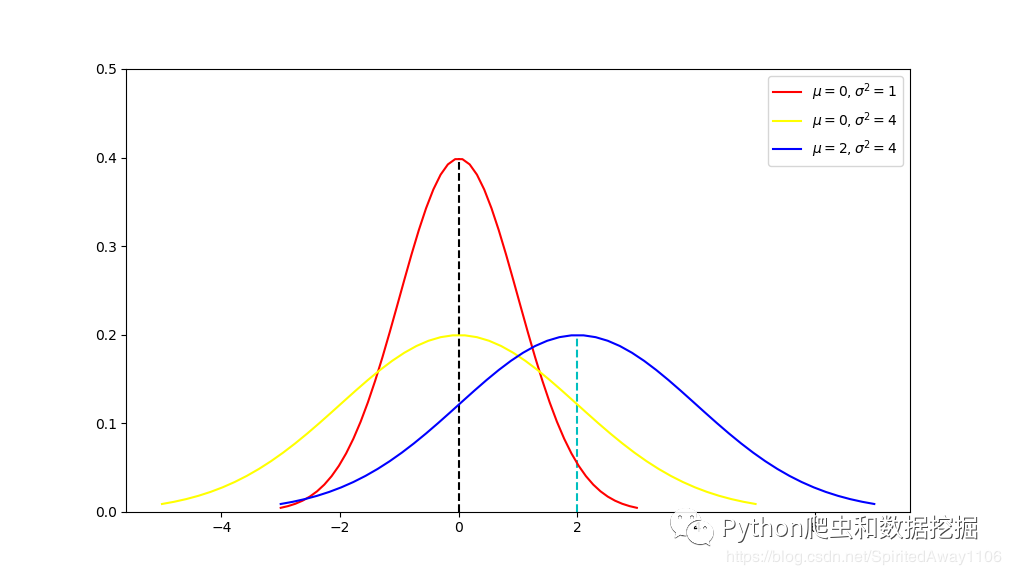
# 1. Numpy.random随机信号处理基础
在本章节中,我们将深入探讨Numpy.random模块在随机信号处理中的基础应用。首先,我们会介绍Numpy.random模块的基本功能和随机数生成的原理,然后逐步分析如何使用这些功能生成基本的随机信号。通过实例演示,我们将展示如何利用Numpy.random模块中
【GMPY库的跨平台使用】:确保GMPY库在多平台兼容性与稳定性,无缝跨平台

# 1. GMPY库概述
## GMPY库的简介与特性
GMPY库是一个基于GMP(GNU多精度库)和MPIR(多精度整数库的增强版)的Python扩展库,专为提供高性能的数学运算而设计。它支持多种数据类型,包括多精度整数、有理数和浮点数,并能够执行复杂的数学运算
Python日志分析与机器学习应用:从日志中挖掘数据模式

# 1. 日志分析与机器学习概述
在信息技术高速发展的今天,日志文件成为了系统监控和问题诊断不可或缺的组成部分。日志分析不仅能够帮助我们了解系统运行状态,还能通过数据挖掘发现潜在的问题。随着机器学习技术的兴起,将机器学习应用于日志分析已经成为了一种趋势,它能够帮助我们实现自动化和智能化的日志处理。
## 日志分析的基本概念
日志分析是指对系统产生
Python库文件学习之Upload:安全性增强的策略与实践
# 1. Upload库的基本概念和功能
在本章中,我们将介绍Upload库的基本概念和功能,为后续章节中关于安全性分析和高级应用的讨论打下基础。
## 1.1 Upload库概述
Upload库是Python中用于处理文件上传的库,它提供了一系列API来简化文件上传过程中的编码工作。使用这个库,开发者可以更加方便地在Web应用中实现文件的上传功能,而不必从头开始编写
【多进程编程中的simplejson】:在Django多进程环境中安全使用simplejson的技巧
# 1. 多进程编程与simplejson的简介
在现代Web开发中,多进程编程是提升应用性能和响应速度的关键技术之一。特别是在使用Django这样的高性能Web框架时,多进程可以显著提高处理并发请求的能力。本章将首先介绍多进程编程的基本概念和它在Web应用中的作用,然后逐步深入探讨如何在Django项目中有效地利用多进程来优化性能。
#
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )