YOLOv8算法详解:深入理解图像处理的数学魔法
发布时间: 2024-12-11 18:04:04 阅读量: 7 订阅数: 16 
# 1. YOLOv8算法概述
YOLOv8是一种先进的目标检测算法,其设计宗旨在于提供快速准确的目标检测能力。YOLO(You Only Look Once)系列算法以其高效性和实时性著称,YOLOv8进一步优化了这一特性,并引入了新的技术以提升检测精度。本章将简要介绍YOLOv8算法的起源、发展以及它在当前技术环境中的地位。
## 1.1 YOLO系列算法的演进
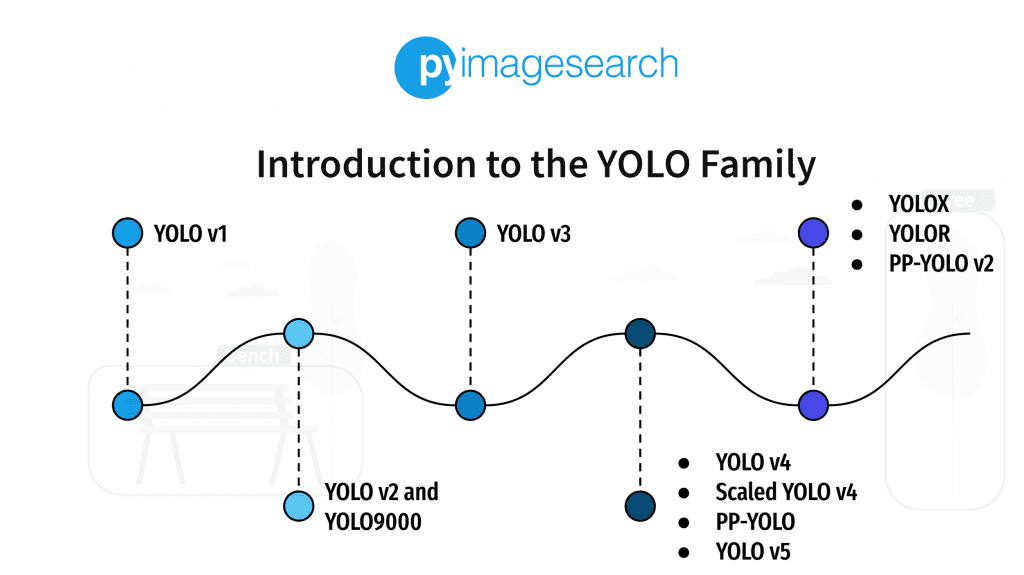
从YOLO的初始版本到YOLOv8,算法在速度和准确性上都有了显著提升。每一代的更新都伴随着模型结构、训练技术和损失函数的创新,这些改进显著提高了算法在各种复杂场景下的检测性能。
## 1.2 YOLOv8的关键特性
YOLOv8的关键特性之一是其改进的网络架构,该架构包括了多尺度特征提取和更加精细的目标分类技术。这些优化使得YOLOv8在处理不同大小和分辨率的图像时能够更加灵活。
## 1.3 应用场景与市场影响
YOLOv8适用于多种实时目标检测的应用场景,例如自动驾驶、监控系统和视频分析等。随着AI技术的快速发展,YOLOv8在工业和消费级市场的影响力不断扩大。
```markdown
# 第一章:YOLOv8算法概述
YOLOv8是一种先进的目标检测算法,其设计宗旨在于提供快速准确的目标检测能力。YOLO(You Only Look Once)系列算法以其高效性和实时性著称,YOLOv8进一步优化了这一特性,并引入了新的技术以提升检测精度。本章将简要介绍YOLOv8算法的起源、发展以及它在当前技术环境中的地位。
## 1.1 YOLO系列算法的演进
从YOLO的初始版本到YOLOv8,算法在速度和准确性上都有了显著提升。每一代的更新都伴随着模型结构、训练技术和损失函数的创新,这些改进显著提高了算法在各种复杂场景下的检测性能。
## 1.2 YOLOv8的关键特性
YOLOv8的关键特性之一是其改进的网络架构,该架构包括了多尺度特征提取和更加精细的目标分类技术。这些优化使得YOLOv8在处理不同大小和分辨率的图像时能够更加灵活。
## 1.3 应用场景与市场影响
YOLOv8适用于多种实时目标检测的应用场景,例如自动驾驶、监控系统和视频分析等。随着AI技术的快速发展,YOLOv8在工业和消费级市场的影响力不断扩大。
```
本文接下来将深入探讨YOLOv8算法的数学基础,为读者提供更深层次的技术理解。
# 2. YOLOv8算法的数学基础
## 2.1 空间向量和矩阵运算
### 2.1.1 向量的基本概念与运算
向量是数学中具有大小和方向的量,可以表示为一维数组的形式,在机器学习和深度学习中,向量通常用于表示数据点或者参数。向量运算包括加法、减法、标量乘法和点乘等基本运算。向量加法遵循平行四边形法则,即两个向量相加的和向量的起点为第一个向量的起点,终点为第二个向量的终点。
**代码示例:**
```python
import numpy as np
# 定义两个向量
vector_a = np.array([1, 2, 3])
vector_b = np.array([4, 5, 6])
# 向量加法
addition = vector_a + vector_b
print(addition) # 输出: [5 7 9]
# 向量减法
subtraction = vector_a - vector_b
print(subtraction) # 输出: [-3 -3 -3]
# 标量乘法
scalar_product = 2 * vector_a
print(scalar_product) # 输出: [2 4 6]
# 向量点乘(内积)
dot_product = np.dot(vector_a, vector_b)
print(dot_product) # 输出: 32
```
**参数说明:**
- `np.array()`: 创建数组。
- `+`: 向量加法。
- `-`: 向量减法。
- `*`: 标量乘法,即向量的每个元素都乘以一个常数。
- `np.dot()`: 计算两个数组的点积。
### 2.1.2 矩阵乘法与变换
矩阵乘法是线性代数中的核心概念之一,它在卷积神经网络的前向传播过程中扮演着重要角色。矩阵A的m行与矩阵B的n列必须相等,乘积矩阵C的大小将是m×n。矩阵变换能够对数据进行线性变换,用于特征提取、图像旋转、缩放等。
**代码示例:**
```python
# 定义两个矩阵
matrix_a = np.array([[1, 2], [3, 4]])
matrix_b = np.array([[5, 6], [7, 8]])
# 矩阵乘法
multiplication = np.dot(matrix_a, matrix_b)
print(multiplication)
```
输出结果将是一个2x2的矩阵,表示矩阵A和矩阵B的乘积。矩阵乘法不仅在理论上有重要意义,在实践中也是图像处理中不可或缺的数学工具。
## 2.2 边界框的几何原理
### 2.2.1 边界框的表示方法
边界框(Bounding Box)是用于图像中定位和识别物体的一个矩形框。它通常由四个值来表示:x,y坐标(矩形框左上角的位置)以及矩形框的宽度和高度。在深度学习中,通常使用归一化的坐标来表示边界框,即相对于图像宽度和高度的比例。
**代码示例:**
```python
# 定义边界框的参数(x, y, width, height)
bounding_box = [0.1, 0.2, 0.5, 0.6]
# 计算左上角和右下角的坐标
left_upper = (bounding_box[0], bounding_box[1])
right_lower = (bounding_box[0] + bounding_box[2], bounding_box[1] + bounding_box[3])
print("Left upper corner:", left_upper)
print("Right lower corner:", right_lower)
```
这段代码定义了一个边界框的参数,并计算了左上角和右下角的坐标。
### 2.2.2 非极大值抑制(NMS)
非极大值抑制是目标检测算法中一个重要的后处理步骤,用于去除多余的重叠边界框。该算法通过比较边界框的置信度,保留置信度最高的边界框,并去除那些与最高置信度边界框的IoU(交并比)超过一定阈值的其他边界框。
**代码示例:**
```python
# 假设有一个边界框列表及对应的置信度分数
boxes = [[0.1, 0.2, 0.3, 0.4, 0.8], [0.2, 0.3, 0.5, 0.6, 0.6], [0.1, 0.1, 0.4, 0.3, 0.7]]
scores = [0.8, 0.6, 0.7]
# 非极大值抑制的实现过程
def nms(boxes, scores, iou_threshold):
# 对边界框根据置信度进行排序
boxes = np.array(boxes)
scores = np.array(scores)
sorted_indices = np.argsort(scores)[::-1]
keep_indices = []
while sorted_indices.size > 0:
# 选择当前置信度最高的边界框
current_box = boxes[sorted_indices[0]]
keep_indices.append(sorted_indices[0])
# 计算其余边界框与当前框的IoU
ious = compute_iou(current_box, boxes[sorted_indices[1:]])
# 如果IoU小于阈值,则保留该框
keep_indices = np.append(keep_indices, sorted_indices[1:][ious < iou_threshold])
# 下一轮循环
sorted_indices = sorted_indices[keep_indices.size:]
return keep_indices.astype(int)
def compute_iou(box1, box2):
# 实现IoU计算函数...
pass
# 调用非极大值抑制函数
keep_indices = nms(boxes, scores, 0.5)
print(keep_indices)
```
在这个例子中,我们首先定义了边界框和对应的置信度分数,然后定义了一个非极大值抑制的函数。这个函数首先根据置信度对边界框进行排序,然后迭代地选择置信度最高的边界框,并计算其余边界框与它的交并比,若交并比小于阈值则保留该边界框。最后返回保留下来的边界框索引。
## 2.3 损失函数的设计
### 2.3.1 损失函数的作用与分类
损失函数是训练深度学习模型时优化的核心目标。它用于衡量模型预测值与真实值之间的差异。损失函数的选择会影响模型的训练效率和最终性能。常见的损失函数包括均方误差(MSE)、交叉熵损失等。
**代码示例:**
```python
# 假设我们有两个变量,一个是预测值,一个是真实值
prediction = np.array([0.1, 0.4, 0.5, 0.9])
ground_truth = np.array([0.0, 0.5, 0.6, 1.0])
# 计算均方误差损失函数
mse_loss = np.mean((prediction - ground_truth) ** 2)
print("MSE Loss:", mse_loss)
# 计算交叉熵损失函数
交叉熵损失 = -np.sum(ground_truth * np.log(prediction))
print("Cross-Entropy Loss:", 交叉熵损失)
```
**参数说明:**
- `np.mean()`: 计算均值。
- `np.log()`: 计算自然对数。
- `-`: 在交叉熵损失函数中,使用负号是为了将损失函数转化为最小化问题。
### 2.3.2 YOLOv8中损失函数的构建细节
YOLOv8作为一个目标检测模型,其损失函数涉及多个部分,包括定位损失、置信度损失和类别损失。定位损失是指边界框的坐标预测与真实坐标的差异;置信度损失是预测的物体置信度与真实值之间的差异;类别损失则是分类预测错误的惩罚。YOLOv8通过调整这些损失项的权重来平衡定位和分类任务的重要性。
**代码示例:**
```python
# 定义定位损失函数
def localization_loss(bbox_pred, bbox_true, coord_mask):
"""
定位损失计算公式为:
L_loc = coord_mask * (bbox_true - bbox_pred)^2
其中 coord_mask 是用于掩盖没有目标的边界框位置。
"""
loss = coord_mask * (bbox_true - bbox_pred) ** 2
return np.sum(loss)
# 定义置信度损失函数
def confidence_loss(conf_pred, conf_true, obj_mask):
"""
置信度损失计算公式为:
L_conf = obj_mask * (conf_true - conf_pred)^2
其中 obj_mask 是用于掩盖背景和没有目标的边界框位置。
"""
loss = obj_mask * (conf_true - conf_pred) ** 2
return np.sum(loss)
# 定义类别损失函数
def class_loss(classes_pred, classes_true, class_mask):
"""
类别损失计算公式为:
L_class = class_mask * cross_entropy_loss(classes_true, classes_pred)
其中 class_mask 是用于掩盖背景和没有目标的边界框位置。
""
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 YOLOv8,一种尖端的图像处理技术,它将图像分类和检测无缝结合。专栏提供了一系列全面的指南和教程,涵盖从入门到精通的各个方面。从优化速度的技巧到构建自定义系统的教程,再到模型压缩和性能评估的深入分析,本专栏为图像处理专业人士提供了宝贵的见解。此外,专栏还深入探讨了 YOLOv8 在工业视觉中的突破性应用,为读者提供了在现实世界中实施该技术的实用指南。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
SNAP在数据备份中的应用:最佳实践与案例分析

# 摘要
本文全面介绍了SNAP技术的理论基础、实践应用及其在现代信息技术环境中的高级应用。SNAP技术作为数据备份和恢复的一种高效手段,对于保障数据安全、提高数据一致性具有重要意义。文章首先阐述了SNAP技术的核心原理和分类,并讨论了选择合适SNAP技术的考量因素。接着,通过实践应用的介绍,提供了在数据备份和恢复方面的具体实施策略和常见问题解决方案。最后,文章探讨了SNAP
故障排除新视角:MMSI编码常见错误分析及预防措施

# 摘要
MMSI(Maritime Mobile Service Identity)编码是海上移动通信设备的关键标识符,其准确性和可靠性对船舶通信安全至关重要。本文系统介绍了MMSI编码的基础
ZKTime 5.0考勤机SQL Server数据备份与恢复终极策略

# 摘要
本文全面探讨了ZKTime 5.0考勤机与SQL Server数据库的备份和恢复流程。文章首先介绍了考勤机和SQL Server数据备份的基本概念与技术要点,然后深入分析了备份策略的设计、实践操作,以及不同场景下的数据恢复流程和技术。通过实例演示,文章阐述了如何为ZKTime 5.0设计自动化备份
深入揭秘iOS 11安全区域:适配原理与常见问题大解析

# 摘要
随着iOS 11的发布,安全区域成为设计师和开发者必须掌握的概念,用以创建适应不同屏幕尺寸和形状的界面。本文详细介绍了安全区域的概念、适配原理以及在iOS 11中的具体应用,并对安全区域在视图控制器、系统UI组件中的应用进行了深入探讨。文章还涉及了安全区域在跨平台框架中的高级应用
FC-AE-ASM协议实战指南:打造高可用性和扩展性的存储网络

# 摘要
FC-AE-ASM协议作为一种先进的存储网络协议,旨在实现光纤通道(FC)在以太网上的应用。本文首先概述了FC-AE-ASM协议的基本理论,包括协议架构、关键组件、通信机制及其与传统FC的区别。紧接着,文章详细讨论了FC-AE-ASM协议的部署与配置,包括硬件要求、软件安装、网络配置和性能监控。此外,本文还探讨了FC-AE-ASM存储网络高可用性的设计原理、实现策略以及案例优化。在此基础上,分析
【提升PAW3205DB-TJ3T性能的优化策略】:新手到专家的全面指南

# 摘要
本文详细介绍了PAW3205DB-TJ3T芯片的性能优化,从基础性能优化到系统级性能提升,再到高级优化技巧。在性能基础优化部分,重点讨论了电源、热管理和内存管理的优化策略。系统级性能优化章节着重于编译器优化技术、操作系统定制与调优以及性能监控与分析,强调了优化在提升整体性能中的重要性。应用中性能提升实践章节提出了具体的应用
【ZYNQ7045硬件加速与PetaLinux】:挖掘最佳实践的秘诀

# 摘要
本文介绍了ZYNQ7045处理器架构,并探讨了其在硬件加速方面的应用。首先,文章对PetaLinux系统进行了介绍和安装步骤说明,之后详细阐述了如何在PetaLinux环境下实现硬件加速,并涉及硬件模块的配置、驱动程序开发、用户空间应用程序开发等关键实现步骤。文章进一步分析了性能优化方法,包括性能评估标准、资源利用
Unity3D EasySave3高级应用:设计国际化多语言支持界面

# 摘要
本文对Unity3D EasySave3插件进行了全面的概述,并详细介绍了其在多语言数据存储方面的基础使用和高级应用。通过探讨EasySave3的安装、配置、数据序列化及反序列化方法,本文为开发者提供了实现国际化界面设计与实践的策略。此外,文章深入分析了如何高效管理和优化语言资源文件,探索了EasySave3的高级功能,如扩展数据类型存储
CR5000监控与日志分析:深入了解系统状态的关键方法

# 摘要
本文全面介绍了CR5000监控系统的概要、关键组件、理论基础、实践操作以及日志分析的进阶技术与策略。首先概述CR5000监控系统的基本情况和功能,然后深入解析了系统的核心组件和它们之间通信机制的重要性。文中还探讨了监控理论基础,包括系统性能指标和监控数据的收集与处理方法,并强调了日志分析的重要性和实施方法。第三章详细阐述了CR5000监控系统的配置、实时数据分析应用以及日志分析的
【硬件与软件升级】:Realtek瑞昱芯片显示器提升指南

# 摘要
随着技术的快速发展,显示器硬件升级成为提高视觉体验的关键途径。本文首先概述了显示器硬件升级的必要性,接着分析了Realtek瑞昱芯片在显示器领域的市场地位及其技术特点,包括其核心技术介绍以及技术优势与劣势。文章继续探讨了软件驱动升级的必要性与方法,并提供了详细的升级步骤和工具介绍。针对Realtek瑞
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )