ETAS ISOLAR 高级应用:数据管理和分析功能的深度掌握
发布时间: 2024-12-19 23:18:34 阅读量: 3 订阅数: 2 

autosar etas isolar-ab guide

# 摘要
ETAS ISOLAR是一个综合性的数据分析平台,本文对其进行了全面的概述和分析。首先介绍了ETAS ISOLAR的基本架构及其数据管理技巧,如数据导入导出、数据库构建维护,以及查询优化。接着,深入探讨了数据分析与处理的能力,包括统计分析、多维数据分析和数据可视化。文章进一步阐述了ETAS ISOLAR的高级分析功能,如预测性分析、大数据处理和自动化分析工作流。最后,通过实践案例展示了ETAS ISOLAR在汽车、制造和能源等行业中的应用,强调了数据分析对于提升行业效率和优化管理的重要作用。本文旨在提供对ETAS ISOLAR功能和应用的深刻理解,并指出其在行业中的潜在价值。
# 关键字
ETAS ISOLAR;数据管理;数据分析;预测性分析;大数据处理;自动化工作流
参考资源链接:[ETAS ISOLAR 9.2.1 操作教程:从工程创建到代码生成](https://wenku.csdn.net/doc/5e93qogv7i?spm=1055.2635.3001.10343)
# 1. ETAS ISOLAR概述与架构
## 1.1 ETAS ISOLAR简介
ETAS ISOLAR是一个为嵌入式软件开发和数据管理设计的综合平台。它通过提供一套完整的工具集帮助工程师进行软件集成、配置管理、需求跟踪和测试自动化,从而实现高效的开发流程。此平台特别适用于汽车行业的软件开发,同时也能在各种复杂的工程环境中发挥作用。
## 1.2 ETAS ISOLAR的核心架构
ETAS ISOLAR平台的核心架构基于模块化设计,它主要包括以下关键组件:
- **ISOLAR-EV**: 针对嵌入式软件版本和配置管理的工具。
- **ISOLAR-AWB**: 用于自动化构建和测试嵌入式系统的工作台。
- **ISOLAR-DAT**: 用于处理数据管理以及跟踪需求和缺陷。
## 1.3 平台的优势与应用场景
ETAS ISOLAR的优势在于其高集成度和模块化,它允许开发者轻松管理和自动化开发过程中的各种复杂任务。其应用场景广泛,覆盖了从传统的嵌入式软件开发到现代的智能化、互联化系统的构建。利用其数据管理功能,开发者能够确保软件配置的一致性,同时进行高效的需求管理和系统测试。
# 2. ETAS ISOLAR的数据管理技巧
在当今数字化转型的浪潮中,数据已成为企业最重要的资产之一。ETAS ISOLAR作为一个先进的工程数据管理平台,能够帮助企业更高效地管理庞大的数据集合。在本章中,我们将深入探讨ETAS ISOLAR在数据管理方面的技巧,包括数据导入导出、数据库构建维护、以及检索与查询优化等多个方面。
## 2.1 数据导入与导出
数据导入导出是数据管理流程中的基础且关键步骤,ETAS ISOLAR提供了强大的数据导入导出功能,支持多种数据格式,并允许用户进行灵活的数据转换。
### 2.1.1 支持的数据格式与转换
ETAS ISOLAR支持多种标准数据格式,如XML、CSV、JSON等,这意味着用户可以轻松地从不同的源系统中导入数据,并将数据导出到多种目标系统中。在转换过程中,ETAS ISOLAR提供了丰富的数据映射功能,能够将源数据映射到目标数据模型。
```xml
<!-- 示例:简单的XML数据导入文件 -->
<root>
<data>
<id>1</id>
<name>John Doe</name>
</data>
<data>
<id>2</id>
<name>Jane Smith</name>
</data>
</root>
```
### 2.1.2 实战案例:数据批量导入导出操作
在实际操作中,数据导入导出可以通过ETAS ISOLAR提供的工具或API完成。例如,要进行批量数据导入,可以使用ISOLAR的批量导入工具,配置相应的映射关系,并按照指定格式准备好数据文件。
```sh
# 命令行示例:使用ETAS ISOLAR CLI进行数据批量导入
ETAS_ISOLAR-cli --import --file=data.xml --format=xml --map=xml2model.map
```
在上述命令中,`--import` 参数指明了操作为数据导入,`--file` 指定了数据文件路径,`--format` 指明了数据格式,而 `--map` 指定了映射文件的路径。
## 2.2 数据库的构建与维护
ETAS ISOLAR允许用户构建高效的数据模型,并对数据库进行维护和优化,以确保数据的安全性和高可用性。
### 2.2.1 数据模型的创建和管理
在ETAS ISOLAR中,数据模型是构建数据库的蓝图。用户可以使用图形化的工具来创建和管理数据模型。数据模型定义了数据库的结构,包括表、列、数据类型、关系以及约束等。
上述图片展示了在ETAS ISOLAR中创建数据模型的图形化界面。
### 2.2.2 数据库的备份、恢复与性能调优
为了确保数据的完整性和可靠性,ETAS ISOLAR提供了数据库备份和恢复功能。通过简单配置,可以定期执行备份任务,并在发生故障时快速恢复数据。
```sql
-- SQL 示例:备份数据库
BACKUP DATABASE [ETASDB] TO DISK = 'C:\Backup\ETASDB.bak';
-- SQL 示例:恢复数据库
RESTORE DATABASE [ETASDB] FROM DISK = 'C:\Backup\ETASDB.bak';
```
性能调优是数据库维护中不可或缺的部分。ETAS ISOLAR允许用户监控数据库性能,并提供工具来诊断和解决性能瓶颈。
## 2.3 数据检索与查询优化
ETAS ISOLAR的数据库查询语言十分强大,其查询优化功能可以显著提高查询效率,缩短数据检索时间。
### 2.3.1 查询语言的基本应用
ETAS ISOLAR的查询语言类似于SQL,但为了工程数据管理而进行了扩展。以下是使用查询语言检索数据的基本语句示例。
```sql
-- 查询语言示例:检索特定ID的数据项
SELECT * FROM工程项目 WHERE ID = '2023-001';
```
### 2.3.2 高级查询技巧和索引优化
在数据检索中,高级查询技巧如联接(Joins)、子查询、以及使用聚合函数等是提升查询能力的关键。ETAS ISOLAR提供了强大的索引优化工具,能够自动识别并优化查询语句。
```sql
-- 查询语言示例:使用聚合函数进行数据统计
SELECT 项目ID, AVG(成本) AS 平均成本 FROM成本表 GROUP BY 项目ID;
```
本节介绍了ETAS ISOLAR数据管理的多个方面,从基础的数据导入导出功能,到构建和维护数据库的高级技巧,再到提高查询效率的优化措施,这些技巧将帮助IT专业人员在日常工作中更高效地管理和利用数据。在接下来的章节中,我们将深入探讨ETAS ISOLAR在数据分析和处理方面的高级功能。
# 3. ETAS ISOLAR的数据分析与处理
数据分析与处理是ETAS ISOLAR中至关重要的部分,它将原始数据转化为有意义的信息和知识。在本章中,我们将深入探讨ETAS ISOLAR提供的数据分析与处理工具及其应用。
## 3.1 数据统计分析工具应用
### 3.1.1 内置统计函数与分析工具
ETAS ISOLAR内置了丰富的统计函数和分析工具,能够帮助用户从多个维度进行数据统计分析。这些工具不仅包含了基本的统计功能,如平均值、中位数、最大最小值等,还包含了复杂的统计分析方法,比如回归分析、假设检验等。
**功能举例**:
- 基本统计函数:SUM(), AVG(), COUNT(), MIN(), MAX()
- 高级统计函数:REGression(), HYPothesis(), Var(), Covar()
**代码示例**:
```sql
SELECT
AVG(salary) AS average_salary,
MAX(salary) AS max_salary,
REGression(salary, years_of_experience) AS salary_regression
FROM
employee_data;
```
**逻辑分析**:
上述SQL语句计算了员工数据表`employee_data`中平均工资、最高工资,并通过`REGression`函数进行工资与工作经验之间的回归分析。
### 3.1.2 实战案例:复杂数据集的统计分析
在处理复杂数据集时,ETAS ISOLAR的统计分析工具显得尤为强大。假设我们有一个销售数据集,需要分析不同地区、不同产品线的销售额,并预测下一季度的销售趋势。
**步骤分解**:
1. 使用`SUM()`函数对不同地区的销售额进行汇总。
2. 通过`GROUP BY`语句对产品线进行分组,并计算每组的平均销售额。
3. 应用`REGression`函数进行时间序列分析,预测下一季度的销售额。
**代码示例**:
```sql
SELECT
region,
product_line,
SUM(sales_amount) AS total_sales
FROM
sales_data
GROUP BY
region,
product_line;
SELECT
NEXT_QUARTER,
REGression(sales_amount, Quarter) AS predicted_sales
FROM
sales_forecasting;
```
在上述代码中,第一步通过`GROUP BY`将销售额按地区和产品线分组并求和,第二步使用回归函数根据历史销售数据预测下一季度销售额。
## 3.2 多维数据分析与报告
### 3.2.1 OLAP分析的基本概念
OLAP(在线分析处理)提供了一种多维数据分析方式,使用户能够从不同角度查看和分析数据。ETAS ISOLAR通过OLAP功能实现数据的快速查询和复杂计算,能够以多维数据立方体的形式展现数据。
### 3.2.2 实战案例:多维数据报告的创建与应用
假设我们有一个汽车行业的数据集,需要分析不同车型、年份和地区的销售表现。我们将创建一个多维报告来展现这些数据。
**报告创建步骤**:
1. 定义数据立方体,选择合适的维度(车型、年份、地区)。
2. 设定度量(销售额、销售量)。
3. 使用OLAP工具生成报告,允许用户通过拖拽维度进行数据探索。
## 3.3 数据可视化与呈现
### 3.3.1 可视化工具的选择与应用
数据可视化是将复杂数据集通过图形化的方式直观展示。ETAS ISOLAR支持多种可视化工具,如图表、地图、仪表盘等,帮助用户更好地理解和传达数据信息。
### 3.3.2 实战案例:交互式数据仪表板的构建
为了更直观地展示销售数据,我们可以构建一个交互式数据仪表板,允许用户实时筛选和观察数据。
**构建步骤**:
1. 确定仪表板需要展示的关键指标和数据维度。
2. 使用ETAS ISOLAR中的可视化组件,如柱状图、折线图、饼图等,构建仪表板。
3. 利用仪表板中的交互功能,如下拉菜单、滑动条等,实现动态数据过滤和更新。
在本章中,我们介绍了ETAS ISOLAR在数据分析和处理方面的多种工具和实战案例,从基本统计到多维分析,再到数据可视化,展示了ETAS ISOLAR强大的数据处理能力。通过这些工具和案例,用户不仅可以深入理解数据,还可以将数据转化为实用的业务洞察。
# 4. ETAS ISOLAR的高级分析功能
## 4.1 预测性分析与机器学习
### 4.1.1 预测模型的基本原理与实现
在数据驱动的决策过程中,预测性分析发挥着至关重要的作用。通过历史数据的分析和机器学习算法的运用,预测模型可以帮助企业预测未来趋势,从而在业务上做出更加科学的决策。预测模型通常包括数据预处理、特征选择、模型训练、模型验证、以及最终的预测实施。
数据预处理阶段包含数据清洗、数据归一化、缺失值处理等步骤,为建立模型提供干净和一致的数据输入。特征选择则是为了剔除不相关或冗余的特征,提高模型的预测准确性和训练效率。模型训练阶段涉及到选择合适的算法,如线性回归、决策树、随机森林或深度学习模型,并利用历史数据集对模型参数进行调整优化。
模型验证是通过测试数据集来评估模型的泛化能力,确保模型不会过拟合(即过于依赖训练数据而失去对新数据的预测能力)。最后,一旦模型得到验证,就可以被用来对未知数据进行预测。
接下来,我们将通过一个简单的线性回归模型例子,展示如何在ETAS ISOLAR中实现预测模型的基本步骤。
```python
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
import numpy as np
# 示例数据集(X为特征,y为目标变量)
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([1, 2, 3, 2, 5])
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建线性回归模型
model = LinearRegression()
# 拟合模型
model.fit(X_train, y_train)
# 预测测试集结果
predictions = model.predict(X_test)
# 打印预测结果
print(predictions)
```
在这段代码中,我们首先导入了必要的库和算法,并创建了一个简单的线性回归模型。然后,我们使用`train_test_split`函数将数据集划分为训练集和测试集。接着,我们使用训练集拟合模型,并使用测试集来验证模型的准确性。
### 4.1.2 实战案例:集成机器学习的预测分析
在了解了预测模型的基本原理后,我们将具体展示如何在ETAS ISOLAR环境中运用机器学习技术进行实际的预测分析。在这个案例中,我们考虑一个典型的业务场景:根据历史销售数据预测未来几个月的销售趋势。
首先,我们需要从ETAS ISOLAR的数据库中提取历史销售数据,这涉及到数据查询语言的运用,如SQL语句:
```sql
SELECT date, sales_amount FROM sales_data WHERE date BETWEEN '2022-01-01' AND '2022-12-31';
```
提取数据之后,我们需要进行数据预处理,包括时间序列分析、季节性调整等,以准备输入到机器学习模型中。在ETAS ISOLAR中,我们可以使用内置的数据预处理工具,或者使用Python脚本进行处理。
```python
from statsmodels.tsa.seasonal import seasonal_decompose
# 加载数据
sales_data = pd.read_sql("SELECT date, sales_amount FROM sales_data WHERE date BETWEEN '2022-01-01' AND '2022-12-31'", connection)
# 对数据进行季节性分解
decomposition = seasonal_decompose(sales_data['sales_amount'], model='additive', period=12)
# 可视化分解结果
decomposition.plot()
```
在处理完数据后,我们可以选择适当的机器学习模型进行训练。在ETAS ISOLAR中,支持多种机器学习模型,并且可以将这些模型与ETAS ISOLAR的其他功能集成,创建端到端的预测分析工作流。例如,可以使用随机森林模型来处理非线性特征:
```python
from sklearn.ensemble import RandomForestRegressor
# 构建随机森林回归模型
model = RandomForestRegressor(n_estimators=100, random_state=42)
# 使用训练集数据拟合模型
model.fit(X_train, y_train)
# 使用测试集进行预测
predictions = model.predict(X_test)
```
最终,模型的预测结果可以被用来生成报告,或者被直接集成到业务决策支持系统中。在ETAS ISOLAR中,我们还可以设置模型评估机制,定期重新训练模型以适应最新的数据变化。
## 4.2 大数据处理与ETAS ISOLAR
### 4.2.1 大数据技术概述与ETAS ISOLAR的集成
大数据技术已经成为现代企业不可或缺的一部分,尤其在分析和处理大规模数据集时。ETAS ISOLAR通过集成大数据技术,提供了一套完整的解决方案,帮助企业有效地管理数据、提高分析的效率,并且处理复杂的数据结构。
ETAS ISOLAR与大数据技术的集成表现在几个方面:
- **数据存储与管理**:通过与分布式文件系统(如Hadoop HDFS)集成,支持存储和管理PB级别的大规模数据集。
- **数据处理能力**:集成如Apache Spark、Flink等大数据处理框架,提供批量或实时的数据处理能力。
- **分析与挖掘**:利用ETAS ISOLAR内置的数据分析工具,从大规模数据集中挖掘潜在的商业价值。
ETAS ISOLAR的大数据集成能力使其能够处理复杂的数据任务,例如时间序列分析、文本分析、图分析等。此外,它还可以与其他大数据相关的技术组件(如Kafka、HBase等)集成,构建完整的数据处理生态。
### 4.2.2 实战案例:处理大规模数据集的方法和技巧
在大规模数据集的处理中,我们通常会面临数据质量、数据安全、处理效率等方面的挑战。接下来,我们将以ETAS ISOLAR为平台,展示如何有效地处理大规模数据集。
首先,我们需要确定数据源和数据质量。大规模数据集可能来源于多种渠道,包括日志文件、社交媒体、物联网设备等。我们可以使用ETAS ISOLAR的ETL(抽取、转换、加载)工具从这些数据源中抽取数据,并对数据进行清洗和格式化。
```python
# 示例代码:数据清洗
import pandas as pd
# 加载数据
data = pd.read_csv("large_dataset.csv")
# 数据清洗,例如:删除空值
data_cleaned = data.dropna()
# 存储清洗后的数据
data_cleaned.to_csv("cleaned_large_dataset.csv", index=False)
```
之后,我们可以利用ETAS ISOLAR内置的大数据处理能力进行复杂的数据分析。例如,我们可以使用ETAS ISOLAR的SQL接口对数据进行分组聚合操作:
```sql
SELECT customer_id, COUNT(*) AS total_visits
FROM customer_visits
GROUP BY customer_id;
```
接下来,我们可以利用ETAS ISOLAR支持的集成开发环境(IDE)进行数据分析和可视化。在IDE中,我们可以通过编写Python脚本来进一步处理数据,并且使用ETAS ISOLAR内置的可视化组件来展示分析结果。
```python
import matplotlib.pyplot as plt
import seaborn as sns
# 加载清洗后的数据
customer_visits = pd.read_csv("cleaned_large_dataset.csv")
# 数据可视化
sns.set(style="whitegrid")
plt.figure(figsize=(10, 6))
plt.title('Customer Visits Distribution')
sns.countplot(x="total_visits", data=customer_visits)
plt.show()
```
以上示例只是处理大规模数据集的一部分,实际应用中,我们需要结合ETAS ISOLAR的大数据集成能力,设计合理的数据处理流程和工作流,以实现高效的分析和处理。
## 4.3 自动化分析与工作流
### 4.3.1 工作流自动化的设计与实施
在ETAS ISOLAR中实现自动化分析,旨在提升工作效率、降低人为错误,并且使业务决策过程更加智能化和及时。工作流自动化的设计与实施,需要我们先理解业务流程的各个环节,确定需要自动化的步骤,然后利用ETAS ISOLAR提供的工具和功能来构建自动化的工作流。
在设计工作流时,需要遵循以下步骤:
1. **需求分析**:明确工作流的目标,理解业务流程,确定自动化的需求。
2. **流程设计**:设计工作流的逻辑结构,包括数据流向、决策节点、以及任务执行序列。
3. **工具选择**:根据工作流的需求选择合适的ETAS ISOLAR功能组件,如脚本工具、数据分析模块、报告生成功能等。
4. **实施与测试**:构建工作流并进行测试,确保逻辑正确,数据准确无误。
5. **部署与监控**:部署工作流到生产环境,并设置监控机制,确保其稳定运行。
为了便于说明,假设我们正在设计一个销售数据报告的自动化工作流。该工作流需要每天定时从数据库中提取最新的销售数据,生成销售报告,并将报告发送到相关人员的邮箱。
首先,我们需要设计ETAS ISOLAR的工作流框架,包括数据提取、数据分析、报告生成以及发送报告的各个步骤:
- **数据提取**:编写自动化脚本,利用ETAS ISOLAR的数据库查询接口提取最新数据。
- **数据分析**:利用内置分析工具对数据进行处理,如计算销售额、增长率等指标。
- **报告生成**:根据分析结果,自动化生成报告的可视化展示。
- **报告发送**:将报告文件作为附件,通过ETAS ISOLAR的邮件服务自动发送给相关人员。
### 4.3.2 实战案例:自动化分析流程的搭建与优化
为了实现上述销售数据报告的自动化工作流,我们需要按照实际步骤搭建和优化工作流程。
首先,建立ETAS ISOLAR与数据库的连接,并编写脚本来定时执行数据提取:
```python
import schedule
import time
def extract_sales_data():
# ETAS ISOLAR数据库连接代码
connection = establish_connection()
# 编写SQL查询语句
sql_query = "SELECT * FROM sales_data WHERE date BETWEEN '2023-01-01' AND '2023-01-31'"
# 执行查询并获取数据
sales_data = pd.read_sql(sql_query, connection)
# 关闭数据库连接
connection.close()
return sales_data
# 定义任务计划
schedule.every().day.at("09:00").do(extract_sales_data)
while True:
schedule.run_pending()
time.sleep(1)
```
接着,使用ETAS ISOLAR内置的分析工具对提取的数据进行分析,并根据分析结果生成报告:
```python
# 假设已提取销售数据存储在sales_data变量中
# 进行数据处理和分析的代码
# ...
# 生成报告的函数
def generate_report(data):
# 生成报告的代码
# ...
# 调用函数生成报告
report = generate_report(sales_data)
```
最后,将报告文件作为附件,通过ETAS ISOLAR内置的邮件服务自动发送给相关人员:
```python
import smtplib
from email.mime.multipart import MIMEMultipart
from email.mime.base import MIMEBase
from email import encoders
def send_report_by_email(report, recipients):
msg = MIMEMultipart()
msg['From'] = 'sales@example.com'
msg['To'] = ", ".join(recipients)
msg['Subject'] = 'Monthly Sales Report'
# 添加报告作为附件
part = MIMEBase('application', 'octet-stream')
part.set_payload(report)
encoders.encode_base64(part)
part.add_header('Content-Disposition', "attachment; filename=report.pdf")
msg.attach(part)
# 发送邮件
with smtplib.SMTP('smtp.example.com', 587) as server:
server.starttls()
server.login('sales@example.com', 'password')
server.send_message(msg)
# 设置收件人列表并发送报告
recipients_list = ['user1@example.com', 'user2@example.com']
send_report_by_email(report, recipients_list)
```
通过这些步骤,我们成功搭建了一个自动化的工作流,它能够自动处理数据、生成报告,并通过邮件发送。这只是一个简单示例,实际应用中,我们可以在ETAS ISOLAR中添加更多的功能和步骤,以实现更加复杂和全面的自动化流程。
# 5. ETAS ISOLAR在行业应用中的实践案例
在前面的章节中,我们深入了解了ETAS ISOLAR的内部架构、数据管理、分析处理以及高级分析功能。现在,我们将目光转向实际应用案例,探讨ETAS ISOLAR是如何在不同行业中解决具体问题,并提升业务效率和分析能力的。
## 5.1 汽车行业的数据管理与分析
汽车行业不仅在制造过程中需要精细的数据管理,在车辆的研发、测试、维护以及整个供应链管理中也需要对大量数据进行处理与分析。
### 5.1.1 汽车领域数据的特殊性与处理策略
汽车行业的数据管理具有以下特点:
- 多源异构数据:包含来自不同供应商、车辆传感器、测试设备等来源的数据。
- 高频率实时数据:车辆在行驶过程中会产生高速实时数据流。
- 大数据量:现代汽车拥有成百上千的传感器,产生的数据量巨大。
针对这些特点,ETAS ISOLAR提供了一系列处理策略:
- 使用ETAS ISOLAR的数据导入工具来整合不同来源的数据。
- 应用实时数据处理和分析模块来处理高速数据流。
- 利用ETAS ISOLAR的分布式存储和处理能力来应对大数据量。
### 5.1.2 案例研究:ETAS ISOLAR在汽车行业的应用
在实际应用中,ETAS ISOLAR被广泛应用于以下几个方面:
- 功能安全分析:利用ETAS ISOLAR对车辆运行数据进行实时监控,分析潜在安全风险。
- 性能优化:通过数据分析,评估车辆性能指标,如燃油效率、排放控制等。
- 客户体验提升:通过车载数据分析,提供个性化驾驶建议,增强用户体验。
接下来,我们将通过具体的案例来展示ETAS ISOLAR在汽车行业数据管理与分析中的实际应用。
## 5.2 制造业的数据监控与优化
制造业作为国民经济的重要支柱,在提升效率、降低成本方面一直寻求创新。数据分析成为制造业转型升级的关键工具。
### 5.2.1 制造业数据监控的需求与挑战
制造业的数据监控需求包括:
- 实时监控生产线的运行状态。
- 分析生产过程中的异常事件和故障原因。
- 预测设备维护周期,减少停机时间。
面临的挑战主要为:
- 数据采集的准确性和实时性。
- 数据量大且复杂,需要有效管理。
- 分析结果的准确性和实用性。
### 5.2.2 案例研究:提升制造业效率的数据分析应用
在制造业,ETAS ISOLAR可以帮助企业实现:
- 利用ETAS ISOLAR的实时监控系统来跟踪生产流程,及时发现潜在问题。
- 通过数据挖掘和机器学习技术来分析生产数据,识别故障模式和维护需求。
- 利用ETAS ISOLAR的报表和仪表板功能,将复杂数据分析结果可视化,便于决策者理解。
## 5.3 能源行业的数据管理与分析
能源行业数据管理的挑战主要体现在:
- 多样化的数据来源:从风力发电到太阳能电池板,不同能源的监控系统各异。
- 时序数据的分析:需要分析长时间序列数据来预测能源产量。
- 效率优化:分析数据以提高能源利用效率,降低成本。
### 5.3.1 能源行业数据分析的特点与技术
ETAS ISOLAR在能源行业中的应用特点为:
- 时间序列分析:处理和分析能源产生的时序数据。
- 能效优化:通过分析数据来优化能源生产和分配的效率。
- 预测性维护:预测设备故障,避免意外停机和能源浪费。
### 5.3.2 案例研究:如何通过数据分析优化能源管理
在能源行业中,ETAS ISOLAR的实施案例包括:
- 使用ETAS ISOLAR进行风力发电场的性能监测,分析风速、风向等数据,优化能源产量。
- 利用ETAS ISOLAR的时间序列分析功能来预测太阳能发电量,更好地进行能源调度。
- 应用ETAS ISOLAR的预测性分析来减少设备故障,实现维护成本的降低和能效的提升。
通过这些案例,我们可以看到ETAS ISOLAR在处理不同行业数据问题方面的强大能力,以及它如何帮助企业提升生产效率和决策质量。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《ETAS ISOLAR 操作指南》专栏是一个全面的资源,为用户提供有关 ETAS ISOLAR 软件的深入指导。专栏涵盖了从入门指南到高级应用的各个方面,包括快速上手、基础配置、功能解析、操作技巧、数据管理和分析、实用案例分析、软件更新和维护、跨平台使用和 API 开发。通过循序渐进的教程和详细的解释,该专栏旨在帮助用户从新手快速成长为 ETAS ISOLAR 专家,充分利用软件的强大功能,提高工作效率和数据分析能力。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
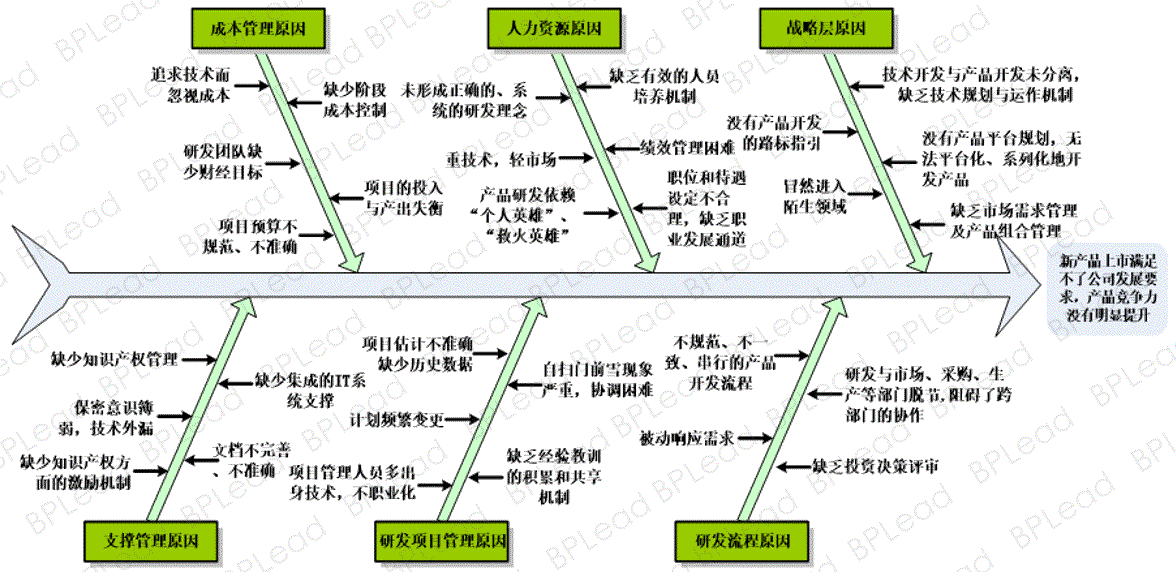
IPD研发流程:跨部门协作的10大成功案例分析
# 摘要
本文全面介绍了集成产品开发(IPD)的研发流程,从理论基础到实践应用案例,再到问题诊断与解决方案,以及技术与工具的应用,最后对IPD研发流程的未来趋势进行展望。IPD研发流程以集成和跨部门协作为核心,结合案例分析,探讨了部门间有效沟通的策略、项目管理工具的应用、产品开发周期和交付的优化策略。同时,识别了流程中潜在问题并提出了预防和解决策略,着重于技术创新在IPD流程中的融合和推动作用。本文强调了跨部门协作技术和工具的重要性,
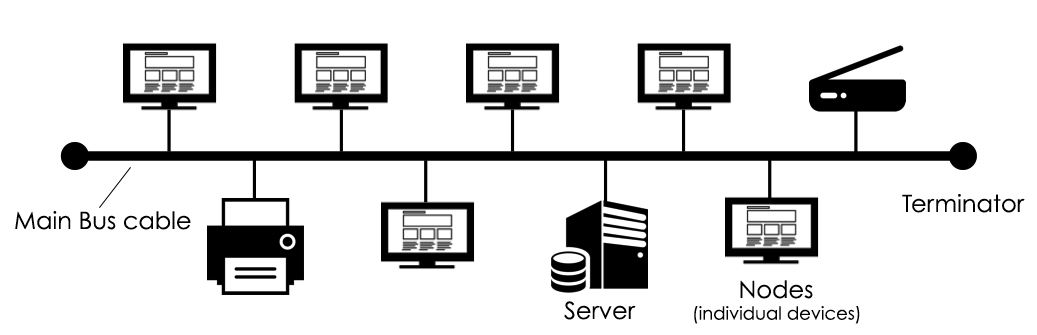
MAX488芯片应用全攻略:从新手到专家的6个实践技巧
# 摘要
本文旨在全面介绍MAX488芯片的功能与应用,为设计者和工程师提供深入的技术参考。首先概述了MAX488芯片的基本特性及其在串行通信中的作用。接着,详细解析了芯片的工作原理、硬件连接和软件配置方法。重点讨论了基于RS-485标准的通信协议,包括通信管理和提高通信稳定性的实践技巧。进一步,文章探讨了MAX488在高级应用中的多主机网络设计和故障诊断调试,并提供集成到复杂系统中的实践技巧。最后,通过分析工业
【Overture中文版:从零基础到音乐创作专家】:掌握每个功能,提升你的作曲效率
# 摘要
本文是一本关于Overture软件的综合指南,旨在向读者介绍如何安装和使用这款专业的音乐创作工具。文章首先概述了Overture中文版的特点并提供了安装指南。接着深入介绍了Overture的基本操作和音乐理论基础,包括工作界面、工具功能和音乐理论概念。文章进一步探讨了音符输入、编辑技巧以及音轨设置等高级功能。此外,本文还涵盖了如何利用Overture进行音乐创作,从基础到复杂创作的技巧,以及进阶应用和创作思维的培养。通过丰富的实例和技巧分享,本文为音乐创作者提供了一套完整的学习和实践方案。
# 关键字
Overture软件;音乐创作;音符编辑;音轨管理;音乐理论;进阶技巧
参考资
【PID巡线算法全解析】:24个实用技巧助您快速精通

# 摘要
本文介绍了PID巡线算法的基本概念及其在各种应用场景中的应用。首先,阐述了PID巡线算法的理论基础,涵盖PID控制原理、控制器设计与调整,以及数学模型。随后,详细描述了该算法的实践应用,包括实现步骤、优化技巧和针对不同环境的策略。最后,探讨了PID巡线算法的高级技巧和进阶应用,如自适应PID控制器、与其他算法的结合以及未来发展趋势。本文旨在为机器人巡线技术提供全面的理论和实践指导,推动自动化和智
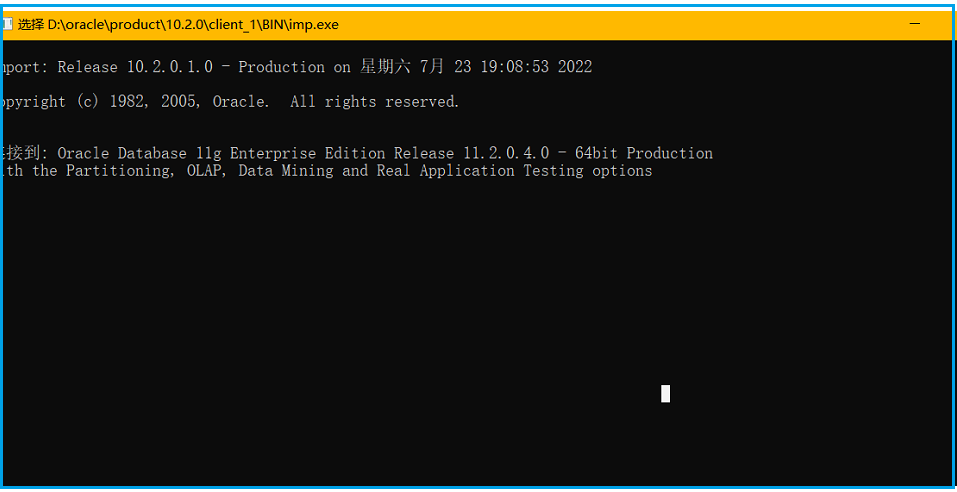
Oracle DMP文件导入达梦:存储过程、触发器迁移与字符集解决方案
# 摘要
随着信息系统的发展,企业面临着从Oracle数据库迁移到达梦数据库的挑战。本文系统地阐述了Oracle DMP文件的导入基础知识,存储过程、触发器的迁移策略和实现方法,以及字符集迁移对数据一致性的影响。文中详尽介绍了迁移过程中遇到的数据类型不匹配、权限与依赖、性能调优等问题,并提供了一系列解决方案
【Matrix 210N操作速成】:只需5步,你就能掌握基础操作!
# 摘要
Matrix 210N作为一款功能全面的设备,提供了用户界面友好、操作简便的入门体验以及深入的高级功能探索。本文首先概述了Matrix 210N的基本概念和设备入门知识,然后详细介绍了界面操作、个性化设置和文件管理的基本方法。随着内容的深入,文章深入探讨了Matrix 210N的高级功能,如网络配置、多任务处理和安全隐私设置。最后,针对设备可能遇到的故障排除、性能优化和更新恢复等方面,给出了实用的解决方案和建议。本文旨在为Matrix 210N用户提供全面的使用指南,帮助他们更好地掌握设备的使用技巧和故障应对方法。
# 关键字
Matrix 210N;用户界面;个性化定制;文件管理
西门子G120变频器宏功能安全管理:确保工业自动化系统安全运行的策略

# 摘要
本文全面介绍了西门子G120变频器的宏功能及其安全管理的基础知识。首先概述了变频器的功能和重要性,接着探讨了安全功能的理论基础、硬件与软件组件的作用以及安全策略和法规遵循的必要性。第三章详细说明了宏功能的配置步骤、安全宏功能的启动与测试以及
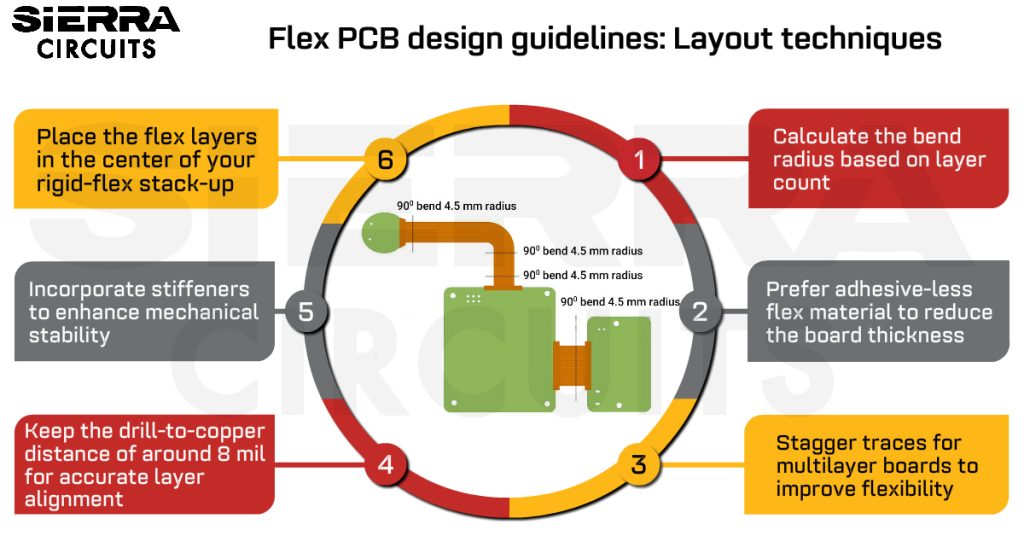
Aspeed 2500系统集成:设计高效嵌入式解决方案的5步法
# 摘要
本文全面分析了Aspeed 2500系统的集成过程,从硬件特性到软件环境,再到系统集成的理论基础,提供了一个深入理解Aspeed 2500系统架构的视角。实践章节重点介绍了环境搭建、驱动程序开发、性能优化和稳定性测试的详细步骤与技巧。此外,文章还探讨了Aspeed 2500在嵌入
阿里巴巴大数据可视化:从数据到信息转化的5个步骤
# 摘要
大数据可视化作为数据科学的重要组成部分,对信息的有效传达和决策制定具有显著的促进作用。本文首先界定了大数据可视化的概念,并强调了其在处理海量数据时的重要性。随后,详细探讨了数据收集与预处理的策略,包括数据抓取、清洗、质量评估与控制。文章接着转向数据存储与管理,分析了分布式文件系统和非关系型数据库的应用,以及数据治理和元数据管理的重要性。在数据分析与处理章节,本文介绍了数据挖掘、统
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )