利用代理IP解决Python爬虫被封禁的问题
发布时间: 2024-04-16 13:09:52 阅读量: 116 订阅数: 77 

# 1. 爬虫被封禁的原因
#### 1.1 用户行为引发封禁
在爬虫过程中,若出现大量请求频繁访问网站,或者请求头信息未设置合理,很容易引起网站封禁。大量请求会造成服务器负担过重,触发网站防爬机制。请求头未设置合理信息可能暴露爬虫行为,被网站识别并封锁。
#### 1.2 网站防爬策略
常见的网站防爬策略包括IP封禁和检测爬虫行为。网站可以通过监控IP访问频率,封禁频繁访问的IP地址。此外,网站也会检测用户访问行为,如访问速度、请求头信息等,以识别爬虫并对其采取限制措施。
理解这些封禁原因和网站防爬策略是避免爬虫被封禁的关键。因此,在进行爬虫项目时,需要谨慎设计爬取策略,避免触发网站的防爬机制。
# 2. 代理IP的作用**
#### **2.1 什么是代理IP**
代理IP是一种用来隐藏真实访问者IP地址的工具,通过代理服务器进行访问,使得被访问的服务器无法直接获取真实IP地址。在网络爬虫中,代理IP被用来绕过网站的访问限制,保护用户真实IP地址。
##### **2.1.1 正向代理和反向代理的区别**
- **正向代理**:代理服务器代表客户端进行请求,目的是隐藏客户端的信息。客户端知道正在使用代理,而服务器不知道客户端的真实地址。
- **反向代理**:代理服务器代表服务端进行请求,目的是隐藏服务端的信息。客户端不知道正在与代理通信,而服务器客户端的真实地址。
##### **2.1.2 公开代理和私密代理的特点**
- **公开代理**:免费获得,但稳定性较差,易被封禁。
- **私密代理**:付费获取,稳定性较高,提供更好的访问速度和匿名性。
#### **2.2 代理IP解决爬虫封禁问题**
代理IP有效地解决了爬虫被封禁的问题,帮助爬虫程序绕过网站的反爬机制,降低被封禁的风险。
##### **2.2.1 匿名性保护用户IP**
使用代理IP可以有效保护用户的真实IP地址,确保用户在访问网站时的匿名性,避免个人信息泄露。
##### **2.2.2 轮换IP降低封禁风险**
通过不断轮换代理IP,爬虫程序可以避免在短时间内对同一IP地址过于频繁的访问,降低被网站封禁的概率。
##### **2.2.3 解决反爬手段的有效方法**
网站针对爬虫的反爬虫手段多种多样,使用代理IP可以有效绕过网站的封禁和限制,保证爬虫程序的正常运行。
# 3. Python爬虫设置代理IP
#### 3.1 使用代理IP模块
在进行爬虫数据采集时,经常需要使用代理IP来掩盖真实的访问IP,以避免被封禁。为了实现代理IP的功能,可通过以下步骤操作:
##### 3.1.1 安装requests库
首先,确保已经安装了Python的requests库,如果没有,可以通过pip进行安装:
```python
pip install requests
```
安装完成后,在Python脚本中导入requests库来实现对网站的请求和响应处理。
##### 3.1.2 导入代理IP池
借助第三方的代理IP

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Python爬虫爬取天气数据故障排除与优化》专栏深入探讨了Python爬虫在爬取天气数据过程中可能遇到的各种问题和优化策略。从选择合适的爬虫框架到解决反爬虫机制,从处理异常和错误信息到提升爬取效率,专栏涵盖了天气数据爬取的方方面面。此外,专栏还介绍了数据存储、代理IP、robots.txt文件、多线程爬虫、403 Forbidden错误应对、Cookies使用、验证码识别、反爬虫手段、正则表达式抓取数据、异常处理、IP代理池搭建和User-Agent伪装等相关技术,为Python爬虫开发者提供了全面的故障排除和优化指南。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【PSO-SVM算法调优】:专家分享,提升算法效率与稳定性的秘诀
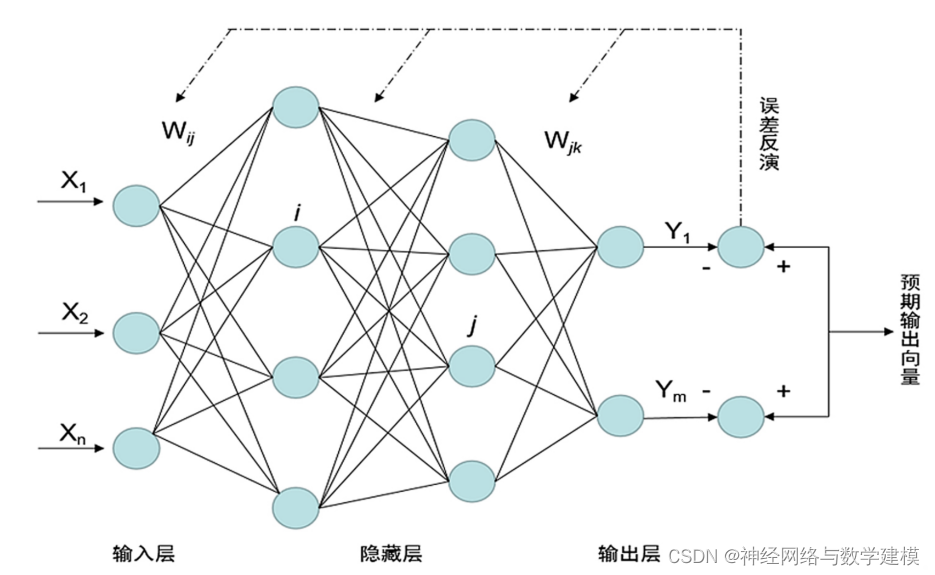
# 1. PSO-SVM算法概述
PSO-SVM算法结合了粒子群优化(PSO)和支持向量机(SVM)两种强大的机器学习技术,旨在提高分类和回归任务的性能。它通过PSO的全局优化能力来精细调节SVM的参数,优化后的SVM模型在保持高准确度的同时,展现出更好的泛化能力。本章将介绍PSO-SVM算法的来源、优势以及应用场景,为读者提供一个全面的理解框架。
## 1.1 算法来源与背景
PSO-SVM算法的来源基于两个领域:群体智能优化
机器人定位算法优化:从理论研究到实践操作

# 1. 机器人定位算法概述
在现代机器人技术中,机器人定位算法发挥着核心作用,它使得机器人能够在未知或动态变化的环境中自主导航。定位算法通常包含一系列复杂的数学和计算方法,目的是让机器人准确地知道自己的位置和状态。本章将简要介绍机器人定位算法的重要性、分类以及它们在实际应用中的表现形式。
## 1.1 机器人定
产品认证与合规性教程:确保你的STM32项目符合行业标准

# 1. 产品认证与合规性基础知识
在当今数字化和互联的时代,产品认证与合规性变得日益重要。以下是关于这一主题的几个基本概念:
## 1.1 产品认证的概念
产品认证是确认一个产品符合特定标准或法规要求的过程,通常由第三方机构进行。它确保了产品在安全性、功能性和质量方面的可靠性。
## 1.2 产品合规性的意义
合规性不仅保护消费者利益,还帮
【模块化设计】S7-200PLC喷泉控制灵活应对变化之道

# 1. S7-200 PLC与喷泉控制基础
## 1.1 S7-200 PLC概述
S7-200 PLC(Programmable Logic Controller)是西门子公司生产的一款小型可编程逻辑控制器,广泛应用于自动化领域。其以稳定、高效、易用性著称,特别适合于小型自动化项目,如喷泉控制。喷泉控制系统通过PLC来实现水位控制、水泵启停以及灯光变化等功能,能大大提高喷泉的
【同轴线老化与维护策略】:退化分析与更换建议

# 1. 同轴线的基本概念和功能
同轴电缆(Coaxial Cable)是一种广泛应用的传输介质,它由两个导体构成,一个是位于中心的铜质导体,另一个是包围中心导体的网状编织导体。两导体之间填充着绝缘材料,并由外部的绝缘护套保护。同轴线的主要功能是传输射频信号,广泛应用于有线电视、计算机网络、卫星通信及模拟信号的长距离传输等领域。
在物理结构上,
【Android主题制作工具推荐】:提升设计和开发效率的10大神器
# 1. Android主题制作的重要性与应用概述
## 1.1 Android主题制作的重要性
在移动应用领域,优秀的用户体验往往始于令人愉悦的视觉设计。Android主题制作不仅增强了视觉吸引力,更重要的是它能够提供一致性的
【数据表结构革新】租车系统数据库设计实战:提升查询效率的专家级策略

# 1. 数据库设计基础与租车系统概述
## 1.1 数据库设计基础
数据库设计是信息系统的核心,它涉及到数据的组织、存储和管理。良好的数据库设计可以使系统运行更加高效和稳定。在开始数据库设计之前,我们需要理解基本的数据模型,如实体-关系模型(ER模型),它有助于我们从现实世界中抽象出数据结构。接下来,我们会探讨数据库的规范化理论,它是减少数据冗余和提高数据一致性的关键。规范化过程将引导我们分解数据表,确保每一部分数据都保持其独立性和
【图形用户界面】:R语言gWidgets创建交互式界面指南

# 1. gWidgets在R语言中的作用与优势
gWidgets包在R语言中提供了一个通用的接口,使得开发者能够轻松创建跨平台的图形用户界面(GUI)。借助gWidgets,开发者能够利用R语言强大的统计和数据处理功能,同时创建出用户友好的应用界面。它的主要优势在于:
- **跨平台兼容性**:g
【项目管理】:如何在项目中成功应用FBP模型进行代码重构
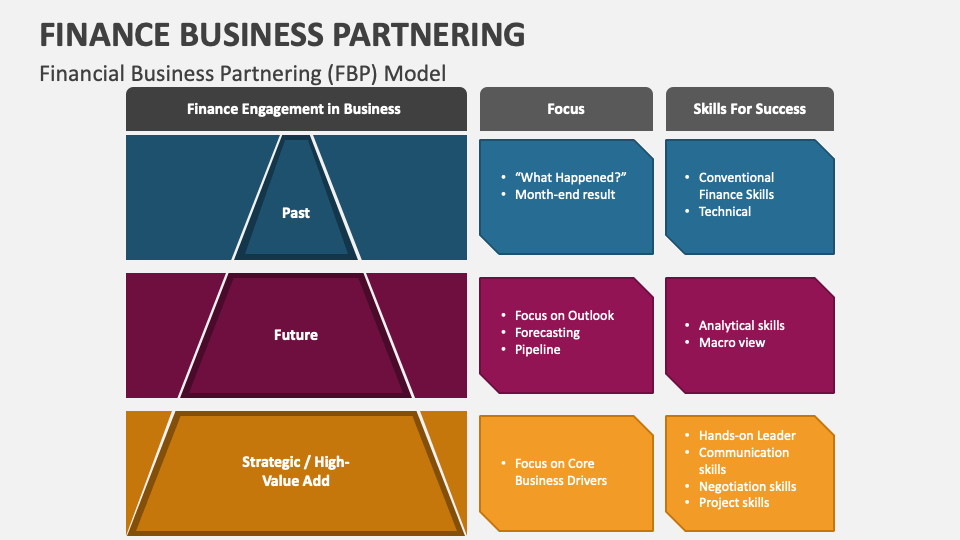
# 1. FBP模型在项目管理中的重要性
在当今IT行业中,项目管理的效率和质量直接关系到企业的成功与否。而FBP模型(Flow-Based Programming Model)作为一种先进的项目管理方法,为处理复杂
【可持续发展】:绿色交通与信号灯仿真的结合

# 1. 绿色交通的可持续发展意义
## 1.1 绿色交通的全球趋势
随着全球气候变化问题日益严峻,世界各国对环境保护的呼声越来越高。绿色交通作为一种有效减少污染、降低能耗的交通方式,成为实现可持续发展目标的重要组成部分。其核心在于减少碳排放,提高交通效率,促进经济、社会和环境的协调发展。
## 1.2 绿色交通的节能减排效益
相较于传统交通方式,绿色交
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )