从零开始掌握MATLAB GPU并行编程:入门指南
发布时间: 2024-06-11 05:00:45 阅读量: 168 订阅数: 82 

# 1. MATLAB GPU并行编程概述**
GPU(图形处理单元)并行编程利用了GPU强大的计算能力来加速复杂计算。MATLAB提供了一个全面的GPU编程环境,使工程师和科学家能够轻松地将他们的代码并行化。
GPU并行编程的主要优势包括:
- **加速计算:** GPU的并行架构允许同时执行大量操作,从而显著提高计算速度。
- **内存带宽高:** GPU具有高内存带宽,可快速访问大量数据,从而减少了内存瓶颈。
- **可扩展性:** GPU并行代码可以轻松扩展到具有多个GPU的系统,进一步提高性能。
# 2. MATLAB GPU编程基础
### 2.1 GPU体系结构和CUDA编程模型
**GPU体系结构**
GPU(图形处理单元)是一种专门用于并行处理图形和计算密集型任务的硬件设备。与CPU(中央处理单元)相比,GPU具有以下特点:
* **并行处理能力强:**GPU包含大量处理核心,可以同时执行多个线程,实现并行计算。
* **内存带宽高:**GPU具有宽带内存接口,可以快速传输大量数据。
* **功耗低:**GPU的功耗比CPU低,适合处理大规模计算任务。
**CUDA编程模型**
CUDA(Compute Unified Device Architecture)是NVIDIA开发的并行编程模型,用于在GPU上执行计算任务。CUDA编程模型包括以下关键概念:
* **设备:**GPU设备,用于执行计算任务。
* **主机:**CPU,负责管理设备和传输数据。
* **内核:**并行执行的函数,在设备上运行。
* **线程:**内核中的执行单元,每个线程执行内核中的指令。
* **线程块:**线程组,由多个线程组成。
* **网格:**线程块组,由多个线程块组成。
### 2.2 MATLAB GPU编程环境和数据传输
**MATLAB GPU编程环境**
MATLAB提供了GPU编程接口,允许用户在MATLAB中编写和执行GPU代码。主要函数包括:
* `gpuDevice`:创建GPU设备对象。
* `gpuArray`:将数据传输到GPU设备。
* `gather`:将数据从GPU设备传输回主机。
* `parallel.gpu.GPUArray`:创建GPU数组对象。
**数据传输**
在MATLAB GPU编程中,数据在主机和设备之间传输至关重要。数据传输可以通过以下方式进行:
* **显式数据传输:**使用`gpuArray`和`gather`函数手动传输数据。
* **隐式数据传输:**MATLAB会自动在需要时传输数据,例如在GPU函数中使用数据时。
### 2.3 GPU内核函数和并行计算
**GPU内核函数**
GPU内核函数是在设备上执行的并行函数。内核函数由线程执行,每个线程处理数据的一个元素。内核函数的语法如下:
```
__global__ void kernel_name(input_parameters) {
// Kernel code
}
```
**并行计算**
在MATLAB中,可以使用`parallel.gpu.GPUArray`对象执行并行计算。`GPUArray`对象提供以下方法:
* `numlabs`:返回网格中线程块的数量。
* `threadsPerBlock`:返回每个线程块中线程的数量。
* `launch`:启动内核函数,指定网格和线程块的尺寸。
**示例:并行矩阵乘法**
以下代码演示了如何使用MATLAB并行计算执行矩阵乘法:
```matlab
% 创建GPU数组
A = gpuArray(rand(1000, 1000));
B = gpuArray(rand(1000, 1000));
% 定义内核函数
kernel = parallel.gpu.GPUFunction( ...
@kernel_matrix_multiply, ...
[1000 1000]);
% 设置网格和线程块尺寸
gridSize = [ceil(1000 / 32), ceil(1000 / 32)];
blockSize = [32 32];
% 启动内核函数
C = gpuArray.zeros(1000, 1000);
launch(kernel, gridSize, blockSize, A, B, C);
% 将结果传输回主机
C = gather(C);
```
**代码逻辑分析**
* `kernel_matrix_multiply`函数是内核函数,执行矩阵乘法。
* `gridSize`和`blockSize`指定了网格和线程块的尺寸。
* `launch`函数启动内核函数,并指定输入和输出参数。
* `gather`函数将结果从GPU设备传输回主机。
# 3. MATLAB GPU并行编程实践
### 3.1 GPU矩阵运算加速
#### 3.1.1 基本矩阵运算
MATLAB提供了丰富的GPU矩阵运算函数,可以显著加速基本矩阵运算,如加法、减法、乘法和除法。这些函数以`gpuArray`对象作为输入和输出,并使用GPU并行计算来执行操作。
```
% 创建两个GPU矩阵
A = gpuArray(rand(1000, 1000));
B = gpuArray(rand(1000, 1000));
% 执行GPU矩阵加法
C = A + B;
% 将结果从GPU传输回CPU
C_cpu = gather(C);
```
**代码逻辑分析:**
1. `gpuArray`函数将MATLAB矩阵转换为GPU数组。
2. `+`运算符执行GPU矩阵加法,结果存储在`C`中。
3. `gather`函数将GPU数组传输回CPU,以便在MATLAB工作空间中使用。
#### 3.1.2 矩阵分解和求解
MATLAB还提供了GPU矩阵分解和求解函数,用于解决线性方程组、特征值问题和奇异值分解等复杂矩阵问题。这些函数利用GPU并行性来加速计算,从而提高求解效率。
```
% 创建一个GPU矩阵
A = gpuArray(rand(1000, 1000));
% 执行GPU矩阵LU分解
[L, U] = gpu_lu(A);
% 求解GPU线性方程组
b = gpuArray(rand(1000, 1));
x = gpu_solve(L, U, b);
% 将结果从GPU传输回CPU
x_cpu = gather(x);
```
**代码逻辑分析:**
1. `gpu_lu`函数执行GPU矩阵LU分解,将`A`分解为下三角矩阵`L`和上三角矩阵`U`。
2. `gpu_solve`函数使用LU分解求解线性方程组`Ax = b`,其中`b`是右端常数向量。
3. `gather`函数将GPU求解结果传输回CPU。
### 3.2 GPU图像处理加速
#### 3.2.1 图像基本操作
MATLAB提供了GPU图像基本操作函数,用于处理图像数据,如图像读取、转换、裁剪和缩放。这些函数利用GPU并行性来加速图像处理,从而提高处理效率。
```
% 读取图像并转换为GPU数组
I = imread('image.jpg');
I_gpu = gpuArray(I);
% 执行GPU图像裁剪
I_cropped = imcrop(I_gpu, [100, 100, 200, 200]);
% 将结果从GPU传输回CPU
I_cropped_cpu = gather(I_cropped);
```
**代码逻辑分析:**
1. `imread`函数读取图像并转换为MATLAB矩阵。
2. `gpuArray`函数将MATLAB图像矩阵转换为GPU数组。
3. `imcrop`函数执行GPU图像裁剪,指定裁剪区域为`[100, 100, 200, 200]`。
4. `gather`函数将GPU裁剪结果传输回CPU。
#### 3.2.2 图像增强和滤波
MATLAB还提供了GPU图像增强和滤波函数,用于改善图像质量和提取图像特征。这些函数利用GPU并行性来加速图像处理,从而提高处理效率。
```
% 创建一个GPU图像数组
I_gpu = gpuArray(imread('image.jpg'));
% 执行GPU图像直方图均衡化
I_eq = histeq(I_gpu);
% 执行GPU图像高斯滤波
I_filtered = imgaussfilt(I_eq, 2);
% 将结果从GPU传输回CPU
I_filtered_cpu = gather(I_filtered);
```
**代码逻辑分析:**
1. `histeq`函数执行GPU图像直方图均衡化,提高图像对比度。
2. `imgaussfilt`函数执行GPU图像高斯滤波,平滑图像并减少噪声。
3. `gather`函数将GPU处理结果传输回CPU。
### 3.3 GPU深度学习加速
#### 3.3.1 深度学习基础
深度学习是一种机器学习技术,它使用人工神经网络来学习数据中的复杂模式。深度学习模型通常由多个层组成,每层执行特定的转换或操作。
#### 3.3.2 GPU深度学习框架和模型训练
MATLAB支持多种GPU深度学习框架,如TensorFlow和PyTorch。这些框架提供了一系列函数和工具,用于构建、训练和部署深度学习模型。
```
% 创建一个GPU深度学习模型
net = alexnet;
% 训练GPU深度学习模型
[net, info] = trainNetwork(train_data, net);
% 评估GPU深度学习模型
[accuracy, precision, recall] = evaluateNetwork(test_data, net);
```
**代码逻辑分析:**
1. `alexnet`函数创建AlexNet深度学习模型。
2. `trainNetwork`函数训练GPU深度学习模型,使用训练数据`train_data`。
3. `evaluateNetwork`函数评估GPU深度学习模型,使用测试数据`test_data`。
# 4. MATLAB GPU并行编程优化
### 4.1 GPU并行性能分析和优化
#### 4.1.1 性能瓶颈识别
**1. 内存瓶颈**
* **症状:**数据传输到GPU或从GPU传输到主机时发生延迟。
* **原因:**GPU内存带宽有限,数据传输速度可能成为瓶颈。
* **解决方法:**
* 优化数据传输策略,例如使用异步传输或批量传输。
* 减少在GPU和主机之间传输的数据量。
**2. 计算瓶颈**
* **症状:**GPU内核执行时间过长。
* **原因:**内核代码效率低下,导致GPU利用率低。
* **解决方法:**
* 优化内核代码,例如使用并行化、循环展开和数据局部性。
* 调整内核块大小和线程数量以提高并行效率。
**3. 同步瓶颈**
* **症状:**GPU和主机之间的同步操作导致延迟。
* **原因:**同步操作会阻塞执行,直到所有GPU内核完成。
* **解决方法:**
* 减少同步操作的频率,例如使用异步内核启动。
* 使用事件和流来重叠同步操作和计算。
#### 4.1.2 优化策略和实践
**1. 数据局部性优化**
* **目的:**减少对全局内存的访问,提高数据访问速度。
* **策略:**
* 将相关数据存储在共享内存或寄存器中。
* 使用循环展开和块划分来提高数据局部性。
**2. 并行化优化**
* **目的:**最大化GPU并行性,提高计算效率。
* **策略:**
* 使用并行循环和并行归约操作。
* 调整内核块大小和线程数量以获得最佳并行性。
**3. 内存优化**
* **目的:**优化GPU内存使用,减少内存瓶颈。
* **策略:**
* 使用共享内存和寄存器来减少全局内存访问。
* 使用纹理内存来存储大数据集。
* 避免内存碎片,使用紧凑的数据结构。
### 4.2 GPU并行可扩展性和容错性
#### 4.2.1 可扩展性优化
* **目的:**提高GPU并行程序在多GPU系统上的可扩展性。
* **策略:**
* 使用多GPU编程模型,例如CUDA多GPU编程或MATLAB并行计算工具箱。
* 优化数据分布和通信策略以减少GPU之间的通信开销。
#### 4.2.2 容错性处理
* **目的:**提高GPU并行程序的容错性,处理GPU故障或错误。
* **策略:**
* 使用错误处理机制,例如CUDA错误处理或MATLAB异常处理。
* 实现检查点和恢复机制以在GPU故障后恢复计算。
* 使用冗余GPU以提高系统可用性。
**代码示例:**
```matlab
% 优化并行循环
parfor i = 1:n
% 并行计算任务
end
% 使用共享内存优化数据局部性
__shared__ float data[1024];
% 并行内核函数
__global__ void kernel() {
int tid = threadIdx.x + blockIdx.x * blockDim.x;
data[tid] = ...; % 计算任务
}
```
**代码逻辑分析:**
* `parfor`循环使用并行计算工具箱实现并行循环。
* 共享内存数组`data`用于存储共享数据,提高数据局部性。
* `__global__`函数`kernel`是一个并行内核函数,在每个线程上执行计算任务。
# 5.1 GPU并行数值计算
### 5.1.1 数值积分和微分方程求解
数值积分和微分方程求解是科学计算中至关重要的任务。GPU并行计算可以显著加速这些计算。
#### 数值积分
数值积分是计算积分近似值的过程。在MATLAB中,可以使用`integral`函数进行数值积分。对于GPU并行计算,可以使用`gpuArray`函数将数据传输到GPU,并使用`integral`函数的`'gpu'`选项进行计算。
```matlab
% 创建在 [0, 1] 上的函数 f(x) = x^2
f = @(x) x.^2;
% 定义积分区间
a = 0;
b = 1;
% 将数据传输到 GPU
f_gpu = gpuArray(f);
% 使用 GPU 并行计算积分
tic;
result_gpu = integral(@(x) f_gpu(x), a, b, 'gpu');
toc;
% 将结果从 GPU 传输回 CPU
result = gather(result_gpu);
% 显示结果
disp(['数值积分结果:' num2str(result)]);
```
#### 微分方程求解
微分方程是描述物理系统随时间变化的数学方程。求解微分方程对于建模和仿真至关重要。在MATLAB中,可以使用`ode45`函数求解常微分方程。对于GPU并行计算,可以使用`gpuArray`函数将数据传输到GPU,并使用`ode45`函数的`'gpu'`选项进行计算。
```matlab
% 定义微分方程 dy/dt = y
f = @(t, y) y;
% 定义初始条件
y0 = 1;
% 定义时间范围
t_span = [0, 1];
% 将数据传输到 GPU
f_gpu = gpuArray(f);
y0_gpu = gpuArray(y0);
% 使用 GPU 并行计算微分方程
tic;
[t_gpu, y_gpu] = ode45(@(t, y) f_gpu(t, y), t_span, y0_gpu, 'gpu');
toc;
% 将结果从 GPU 传输回 CPU
t = gather(t_gpu);
y = gather(y_gpu);
% 绘制结果
plot(t, y);
xlabel('时间');
ylabel('解');
title('微分方程求解结果');
```
### 5.1.2 蒙特卡罗模拟和优化算法
蒙特卡罗模拟和优化算法是解决复杂问题的重要工具。GPU并行计算可以显著加速这些计算。
#### 蒙特卡罗模拟
蒙特卡罗模拟是一种基于随机采样的统计方法。在MATLAB中,可以使用`rand`函数生成随机数。对于GPU并行计算,可以使用`gpuArray`函数将数据传输到GPU,并使用`rand`函数的`'gpu'`选项生成随机数。
```matlab
% 生成 100000 个均匀分布的随机数
n = 100000;
rand_gpu = gpuArray(rand(n, 1));
% 计算 π 的近似值
pi_approx = 4 * mean(rand_gpu);
% 显示结果
disp(['π 的近似值:' num2str(pi_approx)]);
```
#### 优化算法
优化算法用于找到函数的最小值或最大值。在MATLAB中,可以使用`fminunc`函数进行优化。对于GPU并行计算,可以使用`gpuArray`函数将数据传输到GPU,并使用`fminunc`函数的`'gpu'`选项进行计算。
```matlab
% 定义目标函数 f(x) = x^2
f = @(x) x.^2;
% 定义初始猜测
x0 = 1;
% 将数据传输到 GPU
f_gpu = gpuArray(f);
x0_gpu = gpuArray(x0);
% 使用 GPU 并行计算优化
tic;
x_opt_gpu = fminunc(@(x) f_gpu(x), x0_gpu, 'gpu');
toc;
% 将结果从 GPU 传输回 CPU
x_opt = gather(x_opt_gpu);
% 显示结果
disp(['优化结果:' num2str(x_opt)]);
```
# 6. MATLAB GPU并行编程案例研究
### 6.1 图像识别和分类
**简介:**
图像识别和分类是计算机视觉领域的关键任务,涉及识别和分类图像中的对象。MATLAB GPU并行编程可以显著加速这些任务,实现实时处理和高精度。
**方法:**
* 使用预训练的深度学习模型,如 AlexNet 或 VGGNet。
* 将图像数据加载到 GPU 中。
* 使用 `gpuArray` 函数将图像转换为 GPU 数组。
* 使用 `vl_simplenn` 函数执行前向传播和反向传播。
* 使用 `gather` 函数将结果从 GPU 传输回 CPU。
**代码示例:**
```matlab
% 加载图像数据
images = imread('images/*.jpg');
% 将图像转换为 GPU 数组
images_gpu = gpuArray(images);
% 创建深度学习网络
net = vl_simplenn_loadmodel('imagenet-vgg-f.mat');
% 执行前向传播
res = vl_simplenn(net, images_gpu);
% 将结果从 GPU 传输回 CPU
scores = gather(res(end).x);
% 对结果进行分类
[~, labels] = max(scores, [], 2);
```
### 6.2 自然语言处理
**简介:**
自然语言处理 (NLP) 涉及处理和理解人类语言。MATLAB GPU并行编程可以加速 NLP 任务,如文本分类、情感分析和机器翻译。
**方法:**
* 使用词嵌入技术将文本转换为数值表示。
* 将文本数据加载到 GPU 中。
* 使用 `text2vec` 函数将文本转换为词嵌入。
* 使用 `gpuArray` 函数将词嵌入转换为 GPU 数组。
* 使用神经网络模型执行分类或回归任务。
**代码示例:**
```matlab
% 加载文本数据
text_data = fileread('text_data.txt');
% 将文本转换为词嵌入
embeddings = text2vec(text_data);
% 将词嵌入转换为 GPU 数组
embeddings_gpu = gpuArray(embeddings);
% 创建神经网络模型
net = feedforwardnet([100, 50, 2]);
% 训练神经网络
net = train(net, embeddings_gpu, labels_gpu);
% 对新文本进行分类
new_text = 'This is a new text.';
new_embedding = text2vec(new_text);
new_embedding_gpu = gpuArray(new_embedding);
label = net(new_embedding_gpu);
```
### 6.3 科学计算和建模
**简介:**
科学计算和建模涉及求解复杂数学问题。MATLAB GPU并行编程可以加速这些任务,实现高性能计算和快速仿真。
**方法:**
* 使用并行算法和数据结构。
* 将数据加载到 GPU 中。
* 使用 `spmd` 和 `codistributed` 函数创建并行池。
* 使用 `gpuArray` 函数将数据转换为 GPU 数组。
* 使用并行循环和并行函数执行计算。
**代码示例:**
```matlab
% 创建并行池
pool = parpool('local', 4);
% 将数据加载到 GPU 中
data_gpu = gpuArray(data);
% 创建并行循环
parfor i = 1:length(data_gpu)
% 对每个数据元素进行计算
result(i) = compute(data_gpu(i));
end
% 删除并行池
delete(pool);
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
专栏“MATLAB GPU加速”深入探讨了利用图形处理器(GPU)提升 MATLAB 计算性能的强大潜力。它提供了一系列全面的指南,从入门指南到高级优化策略,帮助读者掌握 MATLAB GPU 并行编程的各个方面。专栏还展示了 MATLAB GPU 加速在人工智能、科学计算、金融、医疗、制造、交通、能源、通信、国防和教育等广泛领域的成功应用案例。此外,它还提供了疑难杂症解答和最佳实践指南,以确保高效和可靠的 GPU 并行计算。通过了解 MATLAB GPU 加速的原理、优势和应用,读者可以解锁其并行计算的强大功能,从而显著提高 MATLAB 代码的性能和效率。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【性能优化】:提升Virtex-5 FPGA RocketIO GTP Transceiver效率的实用指南
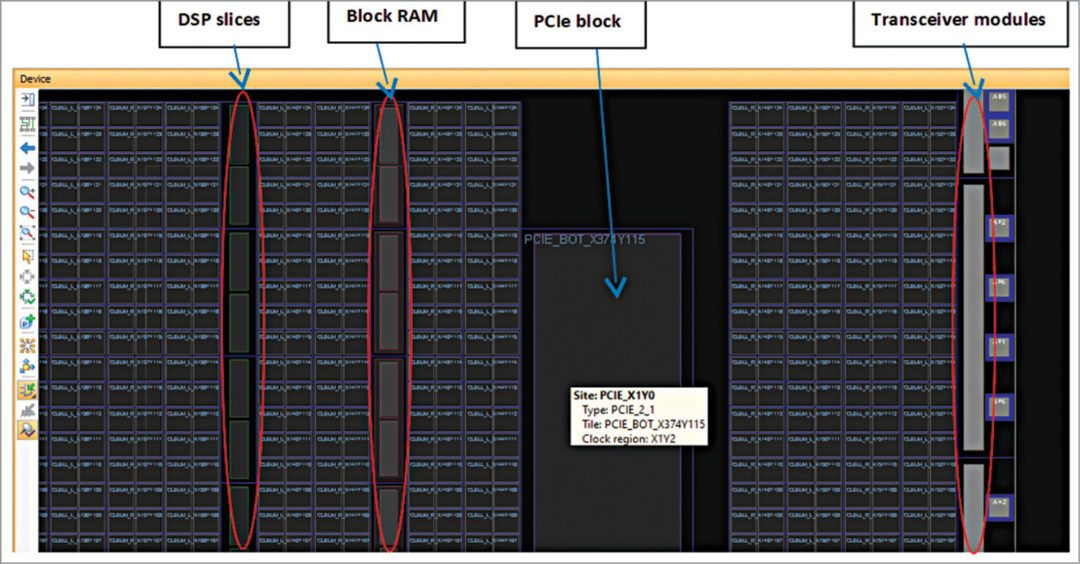
# 摘要
本文针对Virtex-5 FPGA RocketIO GTP Transceiver的性能优化进行了全面的探讨。首先介绍了GTP Transceiver的基本概念和性能优化的基础理论,包括信号完整性、时序约束分析以及功耗与热管理。然后,重点分析了硬件设计优化实践,涵盖了原理图设计、PCB布局布线策略以及预加重与接收端均衡的调整。在固件开发方面,文章讨论了GTP初始化与配置优化、串行协议栈性能调优及专用IP核的
【LBM方柱绕流模拟中的热流问题】:理论研究与实践应用全解析

# 摘要
本文全面探讨了Lattice Boltzmann Method(LBM)在模拟方柱绕流问题中的应用,特别是在热流耦合现象的分析和处理。从理论基础和数值方法的介绍开始,深入到流场与温度场相互作用的分析,以及热边界层形成与发展的研究。通过实践应用章节,本文展示了如何选择和配置模拟软
MBIM协议版本更新追踪:最新发展动态与实施策略解析

# 摘要
随着移动通信技术的迅速发展,MBIM(Mobile Broadband Interface Model)协议在无线通信领域扮演着越来越重要的角色。本文首先概述了MBIM协议的基本概念和历史背景,随后深入解析了不同版本的更新内容,包括新增功能介绍、核心技术的演进以及技术创新点。通过案例研究,本文探讨了MB
海泰克系统故障处理快速指南:3步恢复业务连续性
# 摘要
本文详细介绍了海泰克系统的基本概念、故障影响,以及故障诊断、分析和恢复策略。首先,概述了系统的重要性和潜在故障可能带来的影响。接着,详细阐述了在系统出现故障时的监控、初步响应、故障定位和紧急应对措施。文章进一步深入探讨了系统
从零开始精通DICOM:架构、消息和对象全面解析
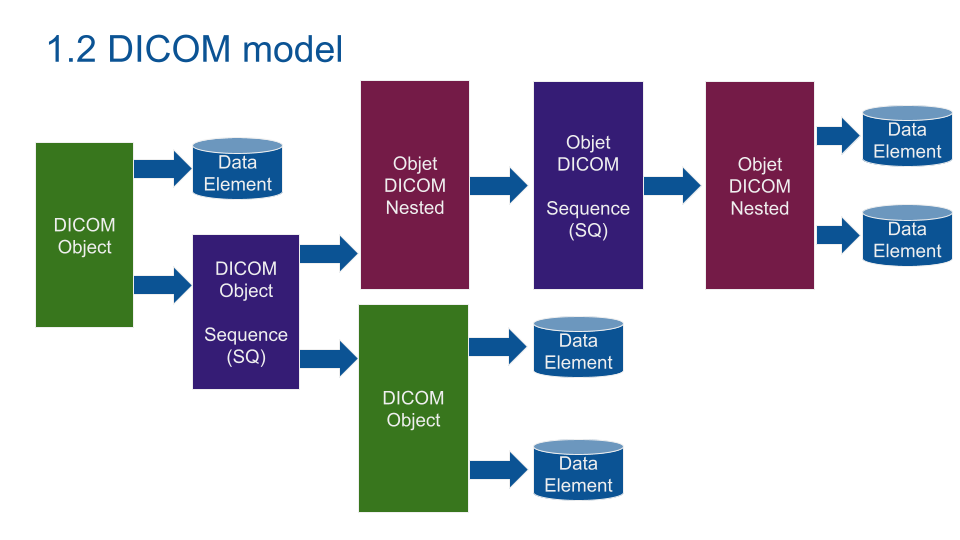
# 摘要
DICOM(数字成像和通信医学)标准是医疗影像设备和信息系统中不可或缺的一部分,本文从DICOM标准的基础知识讲起,深入分析了其架构和网络通信机制,消息交换过程以及安全性。接着,探讨了DICOM数据对象和信息模型,包括数据对象的结构、信息对象的定义以及映射资源的作用。进一步,本文分析了DICOM在医学影像处理中的应用,特别是医学影像设备的DICOM集成、医疗信息系统中的角色以及数据管理与后处理的
配置管理数据库(CMDB):最佳实践案例与深度分析

# 摘要
本文系统地探讨了配置管理数据库(CMDB)的概念、架构设计、系统实现、自动化流程管理以及高级功能优化。首先解析了CMDB的基本概念和架构,并对其数据模型、数据集成策略以及用户界面进行了详细设计说明。随后,文章深入分析了CMDB自
【DisplayPort over USB-C优势大揭秘】:为何技术专家力荐?

# 摘要
DisplayPort over USB-C作为一种新兴的显示技术,将DisplayPort视频信号通过USB-C接口传输,提供了更高带宽和多功能集成的可能性。本文首先概述了DisplayPort over USB-C技术的基础知识,包括标准的起源和发展、技术原理以及优势分析。随后,探讨了在移动设备连接、商
RAID级别深度解析:IBM x3650服务器数据保护的最佳选择

# 摘要
本文全面探讨了RAID技术的原理与应用,从基本的RAID级别概念到高级配置及数据恢复策略进行了深入分析。文中详细解释了RAID 0至RAID 6的条带化、镜像、奇偶校验等关键技术,探讨了IBM x3650服务器中RAID配置的实际操作,并分析了不同RAID级别在数据保护、性能和成本上的权衡。此外,本文还讨论了RAID技术面临的挑战,包括传统技术的局限性和新兴技术趋势,预测了RAID在硬件加速和软件定义存储领域的发展方向。通过对RAID技术的深入
【jffs2数据一致性维护】

# 摘要
本文全面探讨了jffs2文件系统及其数据一致性的理论与实践操作。首先,概述了jffs2文件系统的基本概念,并分析了数据一致性的基础理论,包括数据一致性的定义、重要性和维护机制。接着,详细描述了jffs2文件系统的结构以及一致性算法的核心组件,如检测和修复机制,以及日志结构和重放策略。在实践操作部分,文章讨论了如何配置和管理jffs2文件系统,以及检查和维护
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )