国际编码必备知识:深入探索Unicode的核心优势


Decoder_Project:暑期项目
摘要
Unicode作为一种全球统一的编码标准,解决了不同语言文本在计算机系统中的表示问题,是全球文本统一的基础。本文首先介绍了Unicode的诞生背景和编码基础,包括字符集的发展、Unicode编码格式及标准版本的更新。接着,文章深入探讨了Unicode在现代技术中的应用,包括操作系统、Web技术以及编程语言中的集成与实践。最后,分析了Unicode在数据存储、传输、兼容性问题解决以及应用最佳实践方面面临的挑战,并展望了Unicode未来的发展趋势,特别是其在人工智能、机器学习领域的应用前景及社会文化影响。
关键字
Unicode;全球文本统一;编码格式;标准更新;技术应用;兼容性问题;人工智能;机器学习;社会文化影响
参考资源链接:国内外标准代码大全
1. Unicode的诞生与全球文本统一
1.1 信息时代与文本标准化的需求
随着信息技术的迅猛发展,全球范围内的数据交换变得前所未有的频繁。然而,早期计算机系统主要基于西方语言,这导致了在处理非西方语言文本时的诸多不便。为了实现全球范围内的文本通用性和统一,Unicode应运而生。
Unicode不仅仅是一种编码标准,它是一个致力于为世界上所有书面语言提供唯一编码的宏伟计划。Unicode的设计目标是解决文本编码的兼容性和扩展性问题,确保跨平台、跨语言和跨时代的信息交流无障碍。
1.2 Unicode的诞生背景
Unicode的开发始于上世纪80年代末,当时不同的计算机系统厂商有着自己的字符集,例如ASCII、EBCDIC等,这导致了计算机系统之间的文本信息交换困难。为了解决这一问题,Unicode组织制定了统一的编码规则,旨在容纳地球上所有文字。
Unicode的出现,结束了历史上编码标准林立、互不兼容的局面,为全球互联网信息交换和处理提供了强有力的技术保障。经过几十年的发展,Unicode逐渐成为全球文本编码的事实标准,对推动国际交流和文化多样性的发展发挥了巨大作用。
2. Unicode编码基础
2.1 Unicode字符集概述
2.1.1 字符集的起源和发展
字符集的起源可以追溯到计算机诞生的初期,那时为了表示文本信息,人们发明了字符编码系统。最初,由于硬件和存储的限制,字符集非常简单,只能表示有限的字符。随着计算机技术的发展和国际化的需求,字符集逐渐变得复杂和丰富。
ASCII(美国信息交换标准代码)作为早期的字符集,仅包含了128个字符,这足以表示英文字母、数字和一些控制符。但它不支持多语言,无法表示如中文、阿拉伯文等其他语言的字符。随着全球化的发展,对字符集的需求变得更加迫切,这促使了Unicode的诞生。
Unicode旨在解决全球范围内各种文字系统的编码问题,提供一个统一的字符编码标准。Unicode字符集使用一个唯一的编码来表示每一个字符,从而避免了字符集之间的冲突和不兼容问题。
2.1.2 Unicode与ASCII的比较
Unicode与ASCII的比较主要体现在编码范围和能力上。ASCII是一个7位的字符集,能够表示128个字符,而Unicode是一个扩展的16位字符集,能够表示65,536个字符。Unicode不仅包含了ASCII的所有字符,还有额外的编码空间来表示其他语言和符号。
ASCII字符集的限制在于它只能表示英语字符和一些基本的标点符号,而Unicode能够表示世界上几乎所有的书面语言。这一点使得Unicode在处理国际化文本时,比ASCII具有明显的优势。
2.2 Unicode编码方案
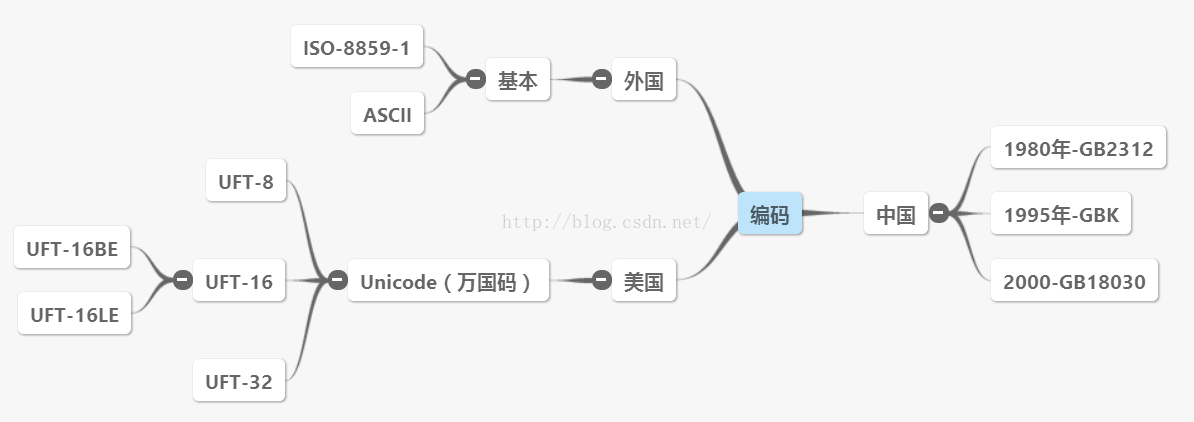
2.2.1 Unicode编码格式:UTF-8、UTF-16和UTF-32
Unicode提供了多种编码格式以满足不同的应用场景需求,其中UTF-8、UTF-16和UTF-32是三种最常用的编码格式。
UTF-8(8-bit Unicode Transformation Format)是一种变长的编码方式,它使用1到4个字节来表示一个字符,与ASCII兼容。UTF-8的使用非常广泛,特别是在线上文本传输和存储时,它能够节省空间,尤其是用于英文和拉丁语系文本。
UTF-16(16-bit Unicode Transformation Format)使用2个或者4个字节来表示一个字符,它解决了某些Unicode字符无法在UTF-8中表示的问题,适用于需要处理大量字符的系统。
UTF-32(32-bit Unicode Transformation Format)使用固定长度的4个字节来表示一个字符,这种格式简化了字符与编码之间的关系,但是由于每个字符占用4个字节,它可能导致存储和传输上较大的开销。
2.2.2 字符映射与代理对的处理
在Unicode标准中,字符映射是将字符与它们在字符集中对应的编码关联起来的过程。大多数常用字符都可以直接映射到单一的Unicode码点上。但对于一些历史遗留的字符和一些特殊的符号,Unicode通过代理对(surrogate pairs)的方式来处理。
代理对是UTF-16编码中用于表示那些无法用单个UTF-16码元表示的Unicode字符的一种机制。在这种机制下,一个字符被分为两个16位的码元,这两个码元一起表示一个字符。这允许Unicode完全表示所有的字符,即使是在UTF-16这种使用16位码元的编码格式中。
2.3 Unicode标准版本及其更新
2.3.1 主要版本的演变和新特性
Unicode标准自1991年首次发布以来,已经经历了多个版本的更新。每个新版本都会包含更多的字符和符号,改进编码方案,并修正前一版本中的错误。
早期版本的Unicode主要集中在基础拉丁字母、希腊字母、西里尔字母、阿拉伯字母和各种标点符号上。随着时间的推移,版本更新增加了对汉字、日文假名、韩文字符等的支持。Unicode 1.1版本开始引入了代理对的概念,以便于支持更广泛的字符。
随着互联网和移动设备的普及,Unicode标准更是加入了各种表情符号、特殊符号和脚本。例如,Unicode 6.0版本增加了来自30多个新脚本的字符,而Unicode 8.0版本引入了数千个新的表情符号。
2.3.2 Unicode标准如何适应语言多样性
Unicode通过不断地扩展和更新字符集,适应了语言的多样性。它不仅包含各种古老和现代语言的字符,还能够适应语言的发展和变化。
Unicode标准的设计允许包含任何书面语言所需的字符集,从古代的楔形文字到现代的计算机编程语言符号。在Unicode中,每个字符都有唯一的标识,不同的语言和书写系统可以在同一个统一框架下共存。
除了字符的增加,Unicode还提供了语言标记、脚本变化和文本方向等支持。这允许文本处理软件能够识别和正确地显示各种语言。例如,从右到左的语言(如阿拉伯语和希伯来语)就得到了特别的考虑,确保在文本布局和编辑上的正确性。此外,Unicode还考虑了拼写变化、注音符号和语言变种等问题,旨在为全球所有语言提供一个统一的编码平台。
3. Unicode在现代技术中的应用
随着信息技术的迅速发展,Unicode作为一种全球文本统一的标准,其在操作系统、Web技术以及编程语言中的应用已经成为现代技术不可或缺的一部分。在本章节中,将详细探讨Unicode在这三个领域中的角色和应用。
3.1 Unicode在操作系统中的角色
3.1.1 操作系统对Unicode的支持
Unicode在操作系统中的支持是其成为全球标准的关键因素之一。现代操作系统,包括Windows、macOS和Linux的发行版,都全面支持Unicode。这种支持不仅仅体现在系统级别的字符编码转换,还包括文件系统的命名规范、输入法编辑器的处理以及用户界面的多语言显示等。
例如,Windows系统从Windows NT开始就内建了对Unicode的支持。在后续的版本中,如Windows XP、Windows 7、Windows 10,这种支持变得更为成熟和高效。系统API大量使用了宽字符(wchar_t)作为函数参数和返回值,从而确保了对Unicode的全面支持。
macOS系统也是从早期的版本就开始集成Unicode支持,并且使用UTF-8作为系统文件名的默认编码,这在多种操作系统共存的环境中显得尤为重要。Linux操作系统,由于其开放源代码的特性,社区能够迅速地集成和更新对Unicode的支持,这使得Linux系统在处理全球文本方面的能力同样非常强大。
3.1.2 跨平台软件中的Unicode处理
对于跨平台软件而言,Unicode不仅是一种标准,更是实现国际化(i18n)和本地化(l10n)的基础。Unicode允许开发者用统一的方式来处理不同语言的文本数据,无论是在Windows、macOS还是Linux平台上。
在跨平台软件的开发过程中,Unicode使得开发者可以编写一次代码,然后在不同的操作系统上编译和运行,而无需修改源代码中的文本处理逻辑。这大大降低了维护成本,并提高了开发效率。例如,Java语言在设计之初就决定使用Unicode作为其内部字符表示,这使得Java程序在不同平台上具有相同的文本处理表现。
在实际应用中,开发者使用Unicode编写软件时,应当注意字符编码的一致性。特别是在读写文件、网络通信以及数据库交互等场景中,明确指定使用UTF-8等Unicode编码格式,可以避免在不同平台之间迁移时出现的编码不一致问题。
3.2 Unicode在Web技术中的应用
3.2.1 Unicode与国际化网站
互联网的全球普及使得Web技术必须支持多语言和国际化。Unicode在国际化网站的建设中起着至关重要的作用。Unicode的广泛应用使得Web开发人员可以轻松地为网站添加多种语言的支持,而无需担心字符编码问题。
从HTML5开始,网页默认编码推荐使用UTF-8,这种编码能够表示Unicode标准中的所有字符,也成为了互联网上使用最广泛的编码格式。当一个网页的字符集设置为UTF-8时,无论是使用拉丁字母、中文字符、阿拉伯文还是其他任何Unicode支持的文字,都可以无损地在网页上显示和传输。
3.2.2 Unicode在HTML和CSS中的实现
Unicode在HTML和CSS中的实现,为网页设计师和前端开发者提供了强大的工具,让他们能够自由地使用任何语言和符号,而不用担心显示问题。通过在HTML中使用<meta charset="UTF-8">声明,以及在CSS中使用@font-face引入支持Unicode的字体,可以确保网页中的文本正确显示。
在CSS中,Unicode的使用还体现在字符实体的引用上。例如,&代表&符号, 代表空格,©代表版权符号等。这些字符实体实际上是将Unicode代码点嵌入到CSS或HTML中,从而实现了跨浏览器和平台的文本兼容。
3.3 Unicode在编程语言中的集成
3.3.1 不同编程语言中的Unicode API
不同的编程语言提供了各种API来处理Unicode文本。从底层语言如C和C++到高级语言如Python和JavaScript,都内建了对Unicode的支持。在C语言中,wchar.h头文件提供了一系列处理宽字符的函数。而在Python中,内置的字符串类型默认就是以Unicode格式进行处理的。
使用这些API,开发者可以很容易地进行Unicode文本的编码转换、字符处理以及正则表达式匹配等操作。例如,在Python中,encode()和decode()方法允许开发者在不同的字符编码格式间转换字符串,而unicodedata模块则提供了丰富的Unicode字符属性查询功能。
3.3.2 字符串处理与库函数的兼容性
为了提高字符串处理的兼容性,许多编程语言都提供了标准库中的函数来处理Unicode文本。这些函数能够正确地处理Unicode字符序列,并且在处理字符串时考虑到字符的边界,避免产生“截断”错误。
此外,现代编程语言的标准库中还包含了一些专门针对Unicode的库函数。例如,在Python中,re模块已经能够很好地处理Unicode字符,使得正则表达式匹配时能够正确地考虑字符的编码。在JavaScript中,ECMAScript 6(ES6)规范引入了更多的Unicode特性,如字符串的Unicode表示和正则表达式中的Unicode标识。
通过使用这些库函数,开发者可以写出更加健壮和兼容性更强的代码,同时减少了因字符编码引起的错误和兼容性问题。这不仅提升了开发效率,也保证了软件应用能够在全球范围内正常运行。
- // 示例代码:Python中的Unicode字符串处理
- def handle_unicode_string(text):
- # 将输入的字符串按Unicode字符进行分割
- characters = list(text)
- # 处理每个Unicode字符
- for char in characters:
- if ord(char) > 128:
- print(f"High-order Unicode character: {char}")
- # 将处理后的字符重新组合成字符串
- return ''.join(characters)
- original_string = "Hello, 世界!"
- processed_string = handle_unicode_string(original_string)
- print(processed_string)
在上述示例中,我们定义了一个简单的Python函数handle_unicode_string,该函数接收一个字符串参数,遍历并打印所有Unicode值大于128的字符。最后,函数将处理后的字符重新组合并返回。通过这样的函数,我们可以确保在处理Unicode字符串时,不会因为字符编码的处理不当而出现错误。
本章将重点介绍了Unicode在操作系统、Web技术和编程语言中的应用。下一章,将详细探讨Unicode在实际应用中遇到的挑战,以及如何在开发过程中应用最佳实践来确保Unicode文本的正确显示和处理。
4. Unicode的挑战与最佳实践
4.1 Unicode数据存储和传输
Unicode为全球文本处理带来了便利,但在数据存储和传输过程中仍面临诸多挑战。了解Unicode数据的存储和传输机制对于创建稳定和可扩展的系统至关重要。
4.1.1 数据库中的Unicode字符集选择
数据库管理系统(DBMS)是存储数据的关键组件,Unicode支持的程度直接影响数据处理能力。大多数现代数据库,如MySQL、PostgreSQL和SQL Server,原生支持Unicode,但存储选择(例如UTF-8、UTF-16或UTF-32)会对其性能和功能产生重要影响。
- UTF-8:由于其变长特性(1到4个字节),UTF-8通常在存储空间和性能之间提供了一个很好的平衡点,成为许多Web应用的首选。
- UTF-16:采用固定16位或32位编码,适合那些大量存储文本的应用程序,尽管在存储方面可能比UTF-8占用更多空间。
- UTF-32:以固定32位编码每个字符,对于处理复杂脚本和要求绝对字符定位的应用程序非常有用,但其通常会占用更多的存储空间。
在选择字符集时,除了考虑存储效率,还应该考虑以下因素:
- 语言支持:确保所选的编码能够支持所有需要存储的语言和字符。
- 查询性能:不同的编码可能对查询性能有不同的影响,比如索引和排序操作。
- 应用程序兼容性:应用程序可能需要特定的字符集支持来确保数据的正确处理。
4.1.2 Unicode文本在网络中的编码和传输
在网络上,Unicode文本通常会转换为传输格式,以确保跨平台的兼容性和高效传输。以下是在网络中传输Unicode文本时需要考虑的关键点:
- 内容协商:使用HTTP的
Content-Type头部的charset参数来声明传输内容的字符集,如Content-Type: text/html; charset=utf-8。 - 字符编码转换:在服务器和客户端之间传递数据时,确保字符编码的正确转换是非常重要的,以避免乱码和数据损失。
- 数据压缩:对于大型数据传输,采用压缩方法(如gzip)可以减少传输所需时间和带宽。
- 安全传输:使用SSL/TLS加密来保护传输过程中的文本数据,避免中间人攻击和数据泄露。
以下是示例代码,展示了如何在Python中处理HTTP请求,并确保Unicode字符正确编码和解码:
- import requests
- from urllib.parse import urlencode
- # 在请求中指定字符集编码
- url = "https://example.com/search"
- params = {'q': '测试'}
- encoded_params = urlencode(params, encoding='utf-8')
- response = requests.get(url, params=encoded_params)
- content = response.content.decode('utf-8')
- # 输出内容
- print(content)
在上述代码中,我们使用了urllib.parse模块中的urlencode函数来确保查询参数以UTF-8格式编码,并使用requests库发起HTTP请求。然后,我们确保响应内容按照UTF-8编码进行解码,以获取正确的文本输出。
在传输和存储过程中,Unicode数据的处理可能涉及到复杂的编码转换和错误处理机制。理解这些机制能够帮助开发者构建更健壮的应用程序。
4.2 Unicode兼容性问题的解决
在处理遗留系统或不同平台之间的文本兼容性问题时,开发者可能需要解决多种挑战。本节将探讨如何处理旧有系统与Unicode的兼容性以及Unicode字体支持和渲染问题。
4.2.1 旧有系统与Unicode的兼容性处理
早期的系统可能不支持Unicode或者仅支持部分字符集,比如仅限于ASCII或ISO 8859-1。将这些系统升级以支持Unicode涉及以下挑战:
- 文件编码转换:旧有文件可能使用了特定的编码,需要在读取和保存文件时进行转换。
- 字体支持:旧系统可能没有适当的字体支持来正确显示Unicode字符。
- API和库的更新:系统中的API和库可能需要更新以支持Unicode。
4.2.2 Unicode字体支持和渲染问题
在多语言环境中,显示正确字符取决于字体文件和渲染技术的支持。Unicode字体支持和渲染问题包括:
- 字体缺失:系统可能缺少显示特定Unicode字符所需的字体。
- 字体渲染问题:即使字体可用,也可能存在渲染问题,比如字符形状和布局的不正确。
接下来将详细探讨解决这些兼容性问题的方法。
解决方案与最佳实践
解决方案
- 转换工具:使用转换工具或库,比如iconv或Java的
java.nio.charset.Charset类,将旧编码转换为Unicode编码。 - 字体库:引入额外的字体库,比如Google的Noto字体系列,以确保覆盖所有Unicode字符。
- 智能渲染:采用高级渲染引擎,如FreeType或HarfBuzz,来改善字符的显示效果。
最佳实践
- 升级支持Unicode:尽可能升级系统或应用,以原生支持Unicode。
- 测试环境:创建测试环境,模拟不同平台和环境,以确保Unicode的兼容性。
- 逐步实施:在多语言支持需求较低时,逐步实施Unicode支持,以减少升级风险。
4.3 Unicode应用的最佳实践
在处理Unicode文本时,开发者应遵循一些最佳实践,以确保文本处理的准确性和效率。
4.3.1 Unicode设计原则与编码规范
设计原则和编码规范对于创建可维护和可扩展的Unicode文本处理至关重要。关键设计原则包括:
- 最小化转换:尽量减少字符编码之间的转换次数,以减少数据损坏的风险。
- 避免规范化问题:在设计和实现文本处理逻辑时,考虑到字符的规范化形式。
- 使用标准化库:使用广泛认可的库进行文本处理,比如Python的
unicodedata模块。
4.3.2 Unicode文本处理的性能优化
性能优化在处理大型文本或需要快速响应的应用中尤其重要。性能优化的一些策略包括:
- 使用高效的字符串库:选择支持Unicode并优化过的字符串处理库,以减少内存使用和提高执行速度。
- 利用现代编程语言的特性:如在Python中使用列表推导式和生成器来处理大型文本。
- 预分配内存:对于静态字符串,预分配足够的内存空间,避免在处理过程中进行多次内存分配。
以下是使用Python进行Unicode文本处理的代码示例,展示了如何使用unicodedata模块规范化字符串:
- import unicodedata
- original_text = "café"
- normalized_form = unicodedata.normalize('NFC', original_text)
- print(normalized_form)
在上述代码中,我们使用了unicodedata.normalize函数,它将输入的字符串按照指定的规范化形式(NFC)进行处理,从而确保字符以规范化的形式存储。
此外,我们可以优化这个过程,例如,通过批量处理字符串而非逐个字符操作,来提高性能。对于大规模文本处理,这些最佳实践可显著提升应用性能。
在本章中,我们深入探讨了Unicode数据存储和传输、解决兼容性问题以及应用最佳实践的方法。这些知识对于确保文本在各种应用中的正确处理和优化至关重要。了解并实践这些技巧,可以帮助开发者构建更为稳定和可扩展的全球性应用。
5. Unicode的未来展望与研究方向
5.1 Unicode标准的未来更新
Unicode作为全球文本编码标准,不断发展以适应新的语言需求和通讯技术。未来的Unicode标准更新,将包括更多未被覆盖的语言字符和脚本,以实现更广泛的全球文本支持。
5.1.1 预计加入Unicode的新字符和脚本
随着新发现的语言和符号的出现,Unicode联盟每年都会评估并更新其标准。例如,Unicode 13.0版本就包含了多个新加入的语言符号和表情符号。未来,我们可能看到:
- 古代和少数民族语言的脚本,如阿瓦尔文(Avar)和高棉的旧文字。
- 特殊符号,比如数学术语和符号,或是化学元素的新发现同位素符号。
- 为适应技术发展而设计的新字符,如编程语言中的特定符号。
5.1.2 Unicode标准化过程中的挑战与趋势
随着全球化的不断推进,Unicode标准化过程面临许多挑战和趋势。例如,如何保持对新兴技术的支持和现有字符集的兼容性,是一个持续的议题。
- 挑战包括确保新加入字符的正确性和实用性,以及处理多语言环境下的兼容性问题。
- 趋势则侧重于为国际标准提供更多的工具和资源,比如更好的字符分类工具和更易于使用的标准文档。
5.2 Unicode在人工智能与机器学习中的应用
随着人工智能(AI)和机器学习(ML)技术的兴起,Unicode在文本分析、自然语言处理和全球数据处理中扮演了关键角色。
5.2.1 Unicode在自然语言处理中的作用
自然语言处理(NLP)是AI领域内的重要分支,而Unicode为NLP提供了全球语言支持的基础。例如,在文本分类、情感分析、机器翻译等任务中,Unicode确保了算法能够正确理解和处理各种语言文本。
- Unicode支持的多语言模型可用于构建跨语言的机器学习应用,让AI能够跨越文化障碍进行有效沟通。
- Unicode使得在不同语言间构建语义映射成为可能,这对于开发诸如跨语言信息检索系统等应用至关重要。
5.2.2 Unicode对全球数字内容的影响力
Unicode的普及使得全球数字内容的创建、存储和分享变得更加容易。它不仅提升了信息的可访问性,也加强了全球知识和文化遗产的保护。
- 通过Unicode,可以更容易地为用户创建包含多语言信息的数字资源库,如在线图书馆或历史档案。
- Unicode标准的应用还有助于保存那些可能面临灭绝风险的语言和方言,保护人类语言的多样性。
5.3 Unicode技术发展的社会与文化影响
Unicode的影响远不止于技术领域,它对社会和文化层面产生了深远影响,促进了全球通讯和文化多样性的保护。
5.3.1 Unicode对全球沟通的促进作用
Unicode的普及使得不同国家和地区的人们可以更便捷地沟通交流。无论是在商业、教育还是日常生活中,Unicode都成为了不可或缺的一部分。
- 人们可以通过电子邮件、社交媒体、即时通讯工具等,使用自己的母语与其他语言使用者进行交流。
- 在全球化的大背景下,Unicode帮助创建了一个更加包容的数字化世界,让更多的人能够平等地参与到全球对话之中。
5.3.2 Unicode在保护文化遗产中的潜力
文化多样性是人类社会的重要组成部分,而语言是文化传承的关键载体。Unicode在文化遗产保护方面发挥着越来越重要的作用。
- Unicode使得长期保存和复兴濒临灭绝的语言成为可能,为未来的研究人员和社区提供了宝贵资源。
- Unicode提供了丰富多样的语言工具,助力于翻译和传播世界文学作品、历史文献以及其他文化相关的文本资料。
Unicode标准的未来展望以及它在AI、ML和全球文化交流中的应用,预示着一个更加开放和统一的信息世界。然而,这要求我们不断审视和优化Unicode的实现与应用,确保它能持续适应并支持技术进步和社会文化的发展。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐

专栏目录

文章持续更新中,敬请期待~
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
道路当量的秘密:如何量化使用效率并优化试验场设计
提升IDA数据类型性能:实战指南解锁性能与效率秘诀
【触发器的力量】:数据库自动化操作的高效实践
【硬件评估】:硬件对比:选择最适合mediapipe-selfie-segmentation的平台
【智能体沟通的艺术】:破解编队控制中的通信难题
【校园一卡通系统深度剖析】:实现校园管理的高效之道
深入揭秘:如何用Vivado FFT IP核优化FPGA信号处理性能
ZPW2000A轨道电路调试与测试流程:系统稳定性关键步骤详解
工业革命:Intel RealSense技术的创新应用与案例分享


专栏目录
文章持续更新中,敬请期待~
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )