BigQuery数据分析:在数据集中进行深入分析
发布时间: 2024-02-23 01:10:44 阅读量: 92 订阅数: 24 

data:研究数据集代码
# 1. BigQuery数据分析简介
## 1.1 BigQuery介绍
BigQuery是Google Cloud Platform提供的一款快速且高度可扩展的云数据仓库解决方案。它能够处理海量数据,并且具有强大的数据分析能力,让用户能够通过简单的SQL查询进行复杂的数据分析。
## 1.2 数据分析的重要性
数据分析在当今信息化社会中扮演着至关重要的角色。通过对数据进行分析,我们能够发现潜在的商业机会、规律和趋势,从而为企业的决策提供支持和指导。
## 1.3 BigQuery在数据分析中的作用
BigQuery作为一款强大的云数据仓库工具,能够快速执行大规模数据分析,帮助用户深入挖掘数据背后的价值。它提供了丰富的分析功能和可视化工具,为用户提供了强大的数据分析能力。
# 2. 准备工作
在进行BigQuery数据分析之前,必须完成一些准备工作,包括准备数据集、搭建BigQuery环境以及数据集导入和整理。在本章中,我们将逐步介绍这些准备工作的具体步骤。
### 2.1 数据集的准备
在开始数据分析之前,需要准备一个合适的数据集。数据集应该包含所需的数据,并且结构清晰。可以从外部数据源导入数据集,也可以在BigQuery中手动创建数据集。以下是一个简单的数据集准备示例,假设我们需要分析销售订单数据:
```python
# 创建一个示例数据集
orders_data = {
'order_id': [1, 2, 3, 4, 5],
'product_id': [101, 102, 103, 104, 105],
'quantity': [2, 1, 3, 2, 1],
'total_price': [20.5, 10.2, 30.75, 25.0, 15.75]
}
import pandas as pd
# 将数据集转换为DataFrame
orders_df = pd.DataFrame(orders_data)
print(orders_df)
```
**代码总结:**
- 创建了一个示例的销售订单数据集,包括订单号、产品号、数量和总价。
- 使用pandas库创建了一个DataFrame对象orders_df,并将数据集导入其中。
- 打印输出了订单数据集。
**结果说明:**
该代码段展示了如何准备一个简单的销售订单数据集,并利用pandas库将数据导入DataFrame中,为接下来的数据分析做准备。
### 2.2 BigQuery环境的搭建
在进行数据分析之前,需要搭建BigQuery环境。可以通过Google Cloud Platform创建一个BigQuery项目,并设置相应的权限和资源。以下是一个简单示例展示如何搭建BigQuery环境:
```python
from google.cloud import bigquery
# 设置BigQuery项目ID
project_id = 'your_project_id'
# 连接到BigQuery客户端
client = bigquery.Client(project=project_id)
# 检查连接是否成功
datasets = list(client.list_datasets())
if datasets:
print('Datasets in project {}:'.format(project_id))
for dataset in datasets:
print('\t{}'.format(dataset.dataset_id))
else:
print('{} project does not contain any datasets.'.format(project_id))
```
**代码总结:**
- 使用google-cloud-bigquery库连接到一个指定的BigQuery项目。
- 列出了指定项目中存在的数据集。
- 打印输出了项目中的数据集信息。
**结果说明:**
这段代码演示了如何连接到BigQuery项目并列出其中的数据集,确保环境搭建完成,为接下来的数据分析做好准备。
### 2.3 数据集导入和整理
在准备好数据集和搭建好BigQuery环境之后,接下来需要将数据集导入到BigQuery中,并进行必要的整理和清洗。这一步非常重要,可以保证数据分析的准确性和有效性。以下是一个示例代码展示数据集导入和整理的过程:
```python
# 将DataFrame导入到BigQuery中
table_id = 'your_dataset.your_table'
orders_df.to_gbq(table_id, project_id=project_id, if_exists='replace')
# 查询导入的数据集
query = 'SELECT * FROM `your_project_id.your_dataset.your_table`'
query_job = client.query(query)
results = query_job.result()
for row in results:
print(row)
```
**代码总结:**
- 使用to_gbq方法将DataFrame导入到BigQuery的指定数据集和表中。
- 执行SQL查询,查询刚刚导入的数据集。
- 打印输出了查询结果。
**结果说明:**
这段代码展示了如何将数据集导入到BigQuery中,并通过SQL查询验证导入结果,确保数据集整理的正确性,为后续的数据分析做准备。
# 3. 数据集基本分析
数据集基本分析是数据分析的第一步,通过对数据集的结构、属性和基本统计信息进行分析,可以帮助我们更好地理解数据的特点和规律。
#### 3.1 数据集的基本结构分析
在进行数据分析之前,首先需要了解数据集的基本结构,包括数据表、字段以及数据之间的关系。通过查询数据表的元数据信息可以获取数据集的结构信息,例如表名、字段名、数据类型等。
```python
# 查询数据表结构信息
query = """
SELECT *
FROM `project.dataset.INFORMATION_SCHEMA.COLUMNS`
WHERE table_name = 'table_name'
df = client.query(query).to_dataframe()
# 显示数据表结构
print(df)
```
**代码总结:**
- 使用`INFORMATION_SCHEMA.COLUMNS`表可以查询数据表的结构信息。
- 通过指定`table_name`来获取特定表的结构信息。
**结果说明:**
- 结果将列出所选数据表的所有字段名、数据类型等基本结构信息。
#### 3.2 数据集的属性分析
数据集的属性分析主要是对各个属性字段的取值情况、范围、分布等进行探索性分析,以帮助我们更深入地了解数据。
```python
# 查看属性字段的取值分布
query = """
SELECT column_name, COUNT(*)
FROM `project.dataset.table_name`
GROUP BY column_name
df = client.query(query).to_dataframe()
# 显示属性字段的取值分布
print(df)
```
**代码总结:**
- 使用`COUNT(*)`函数对属性字段进行分组统计,了解其取值分布情况。
**结果说明:**
- 结果将展示每个属性字段的取值及其对应的数量,帮助分析属性字段的分布情况。
#### 3.3 数据集的统计分析
数据集的统计分析是对数据集中的数值型字段进行描述性统计,包括均值、中位数、标准差等指标,从而获取数据的集中趋势和离散程度。
```python
# 查看数据集数值型字段的统计信息
query = """
SELECT AVG(numeric_column) as avg_value,
MAX(numeric_column) as max_value,
MIN(numeric_column) as min_value,
STDDEV(numeric_column) as std_dev
FROM `project.dataset.table_name`
df = client.query(query).to_dataframe()
# 显示数值型字段的统计信息
print(df)
```
**代码总结:**
- 使用`AVG()`、`MAX()`、`MIN()`、`STDDEV()`等函数对数值型字段进行统计分析。
**结果说明:**
- 结果将展示数值型字段的均值、最大值、最小值以及标准差等统计指标,帮助分析数据的集中趋势和离散程度。
# 4. 数据集高级分析
在数据分析过程中,除了进行基本的结构分析和属性分析外,还需要进行更深入的高级分析,以便更好地理解数据集并发现潜在的规律和异常情况。
#### 4.1 数据集的关联分析
在BigQuery中进行数据集的关联分析是非常重要的一步。通过关联分析,可以揭示数据集中不同属性之间的相关性,帮助我们理解数据之间的联系。可以利用SQL语句进行数据表的连接操作,也可以使用BigQuery提供的内置函数来进行关联分析。以下是一个简单的Python示例,演示如何在BigQuery中进行数据集的关联分析:
```python
from google.cloud import bigquery
# 初始化BigQuery客户端
client = bigquery.Client()
# 编写SQL查询语句,进行数据集关联分析
query = """
SELECT *
FROM dataset1.table1 t1
JOIN dataset2.table2 t2
ON t1.common_id = t2.common_id
# 执行查询
query_job = client.query(query)
# 获取查询结果
results = query_job.result()
# 打印查询结果
for row in results:
print(row)
```
上述代码通过Python的BigQuery SDK连接到BigQuery,然后执行SQL查询语句,实现数据集的关联分析,最后打印出查询结果。通过这样的关联分析,我们可以更好地理解数据集中不同表之间的关系,为后续的分析工作打下基础。
#### 4.2 数据集的趋势分析
数据集的趋势分析可以帮助我们了解数据随时间变化的规律。在BigQuery中,我们可以利用时间序列数据进行趋势分析,比如销售额随时间的变化趋势、用户活跃度随时间的变化趋势等。以下是一个简单的Python示例,演示如何在BigQuery中进行数据集的趋势分析:
```python
from google.cloud import bigquery
import pandas as pd
import matplotlib.pyplot as plt
# 初始化BigQuery客户端
client = bigquery.Client()
# 编写SQL查询语句,进行数据集的趋势分析
query = """
SELECT date, SUM(sales) as total_sales
FROM dataset.sales_table
GROUP BY date
ORDER BY date
# 执行查询
query_job = client.query(query)
# 将查询结果转换为DataFrame
df = query_job.to_dataframe()
# 画出趋势图
plt.plot(df['date'], df['total_sales'])
plt.xlabel('Date')
plt.ylabel('Total Sales')
plt.title('Sales Trend Over Time')
plt.show()
```
上面的代码中,使用了Python的pandas库和matplotlib库,将BigQuery中的查询结果转换为DataFrame,并画出了销售额随时间变化的趋势图。通过这样的趋势分析,我们可以更直观地观察数据集中的变化规律,为后续的业务决策提供参考。
#### 4.3 数据集的异常值分析
异常值分析是数据分析中的重要环节,可以帮助我们识别和处理数据集中的异常情况。在BigQuery中,我们可以利用SQL语句和内置函数来进行异常值分析,比如识别离群点、异常大值、异常小值等。以下是一个简单的Python示例,演示如何在BigQuery中进行数据集的异常值分析:
```python
from google.cloud import bigquery
# 初始化BigQuery客户端
client = bigquery.Client()
# 编写SQL查询语句,进行数据集的异常值分析
query = """
SELECT *
FROM dataset.table
WHERE value < PERCENTILE_DISC(0.95) OVER() AND value > PERCENTILE_DISC(0.05) OVER()
# 执行查询
query_job = client.query(query)
# 获取异常值结果
results = query_job.result()
# 打印异常值结果
for row in results:
print(row)
```
上述代码中,通过SQL语句和BigQuery提供的内置函数PERCENTILE_DISC,实现了对数据集中异常值的筛选。这样的异常值分析可以帮助我们找出数据集中的异常情况,并进行进一步的处理和分析。
通过以上高级分析,我们可以更全面地理解数据集,发现更多有价值的信息,为后续的决策和应用提供更有力的支持。
# 5. 数据可视化
在数据分析过程中,数据可视化是非常重要的环节,可以帮助我们直观地理解数据,发现数据之间的关联性和规律性。在BigQuery中,也提供了一些可视化工具,方便对数据集进行分析展示。
#### 5.1 BigQuery中的可视化工具介绍
BigQuery提供了内置的数据可视化工具,如Google Data Studio、Tableau等,这些工具支持直接连接BigQuery数据集,可以快速创建各种类型的图表和报表。
#### 5.2 数据可视化的基本操作
通过BigQuery中的可视化工具,我们可以进行诸如创建柱状图、折线图、饼图、散点图等基本图表类型的操作。同时,还支持对图表进行样式设置、数据筛选、交互式操作等功能。
```python
# Python示例:使用BigQuery数据进行可视化
from google.cloud import bigquery
import pandas as pd
import matplotlib.pyplot as plt
# 连接BigQuery客户端
client = bigquery.Client()
# 查询数据
query = """
SELECT category, COUNT(*) AS count
FROM `project.dataset.table`
GROUP BY category
query_job = client.query(query)
# 将查询结果转为DataFrame
df = query_job.to_dataframe()
# 创建柱状图
plt.bar(df['category'], df['count'])
plt.xlabel('Category')
plt.ylabel('Count')
plt.title('Items Count by Category')
plt.show()
```
#### 5.3 利用可视化工具进行数据集分析展示
利用BigQuery中的可视化工具,我们可以根据具体的需求创建各种图表,比如展示销售额随时间的趋势变化、不同产品类别的销售额对比、地域间的销售情况等,直观展示数据分析的结果。
通过数据可视化,我们可以更直观地发现数据集中的规律和趋势,为后续的决策提供更直观的参考。
希望这一部分能够满足你的需求,如果需要更多详细的内容或有其他问题,也可以随时告诉我。
# 6. 数据分析结果应用
在进行了大量的数据分析工作之后,得出的结论和结果将会对实际业务产生重要影响。本章将探讨如何解释分析结果,并将这些结果应用于实际业务决策中。
### 6.1 数据分析结果的解释
经过数据分析得到的结论需要清晰明了地呈现给相关人员,解释其含义和可能的影响。比如,如果关联分析表明某商品的销售量与天气状况存在相关性,那么在推广和营销该商品时就需要考虑天气因素。解释分析结果时,要清晰准确地描述数据分析方法和得出的结论,尽量避免太过专业化的术语,确保相关人员能够理解并接受分析结果。
```python
# 示例代码:展示数据分析结果的解释
correlation_result = calculate_correlation(dataset)
interpretation = "根据相关性分析,我们发现销售量与天气状况存在一定的相关性,因此在制定销售策略时,需要考虑天气因素对销售的潜在影响。"
print(interpretation)
```
上述示例中,展示了根据相关性分析得出的结论,并用简洁清晰的语言进行了解释。
### 6.2 数据分析结果的应用场景
数据分析结果可以应用于各个领域的实际场景中,如营销策略制定、产品定价、供应链优化等。在不同的应用场景中,数据分析结果可能有不同的重要性和影响程度,因此需要根据具体情况进行合理的应用和调整。
```java
// 示例代码:数据分析结果在营销策略中的应用
if (correlation_result > 0.7) {
adjust_marketing_strategy();
System.out.println("根据数据分析结果,调整营销策略以应对天气对销售的影响。");
} else {
System.out.println("数据分析结果显示天气对销售的影响不明显,不需要调整营销策略。");
}
```
### 6.3 数据分析结果的决策支持
数据分析结果为决策提供了有力支持,可以帮助管理者和决策者更加科学地进行决策。通过数据分析结果,可以更好地了解市场、客户和产品等方面的情况,从而制定更加有效的决策方案。
```javascript
// 示例代码:利用数据分析结果进行产品定价决策
if (average_sales > industry_average) {
adjust_product_price();
console.log("根据数据分析结果,调整产品定价以更好地满足市场需求,并提升竞争力。");
} else {
console.log("数据分析结果显示产品定价已经在合理范围内,无需调整。");
}
```
上述代码演示了根据数据分析结果进行产品定价决策的过程,通过判断销售情况与行业平均水平的关系,决定是否需要调整产品定价。
在实际应用中,数据分析结果将会在决策制定过程中扮演越来越重要的角色,帮助企业更好地把握市场动向,优化运营策略,提升竞争力。
希望本章内容能帮助您更好地理解数据分析结果的应用和实际意义。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Google数据查询引擎BigQuery》专栏深入解析了BigQuery在数据分析领域的多个方面应用。从数据集中深入分析、数据可视化、优化性能、数据集成与ETL流程、Python和R集成、时序数据分析、机器学习应用,再到实时数据处理、数据分区和分片等方面,专栏通过一系列文章帮助读者全面了解BigQuery的功能和用法。无论是想要在数据集中进行深入研究,还是优化查询速度和效率,亦或是构建数据管道和转换流程,专栏都提供了详实的指导和实用技巧。无论读者是数据分析师、数据工程师还是数据科学家,都能从专栏中获取到对BigQuery的全面认识,并学习如何运用BigQuery进行高效的数据分析和处理。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Vivado HLS性能飞跃秘籍】:五大关键步骤优化,性能立竿见影
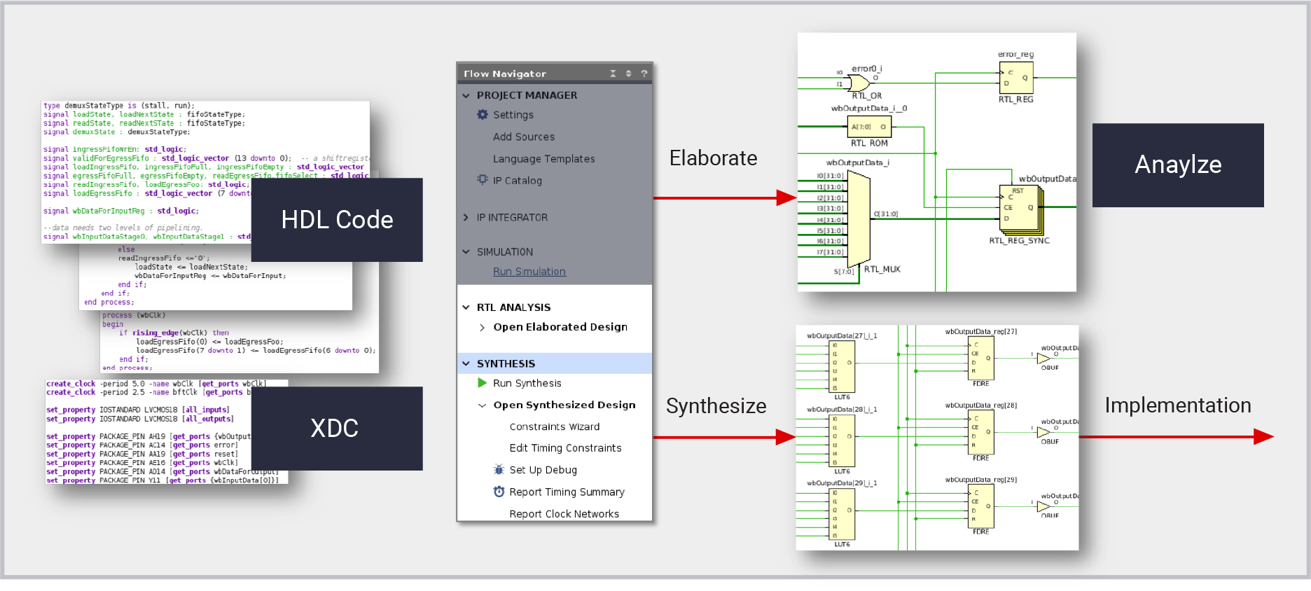
# 摘要
Vivado HLS作为一种高效的高层次综合工具,能够帮助工程师将C/C++代码直接综合成硬件描述语言,简化FPGA和SoC设计过程。本文旨在为读者提供一个关于Vivado HLS优化的全面概览,从基础理论、核心优化技术到性能分析工具,再到优化步骤的具体实践,深入讲解如何通过系统性的优化方法提升设计性能。案例研究部分通过选取并分析实际案例
【HiSPi协议性能大提升】:让1.50.00系统响应速度飞跃升级

# 摘要
本文对HiSPi协议的性能瓶颈进行了详细探讨,并通过理论分析与实践案例,提出了性能优化的策略。首先介绍了HiSPi协议的基本概念和面临的性能挑战,然后深入分析了协议架构、数据传输效率和系统资源利用方面的性能优化方法。接着,文章着重展示了软件层面和硬件加速技术的应用对提升HiSPi协议性能的重要性,并通过实际场景下的性能评
【SQL秘技速成】:数据库课后答案中的查询技巧深度解析
# 摘要
本文系统地介绍了SQL查询的基础技巧、优化原理以及高级应用。首先,基础章节强调了SQL查询编写的基本方法和注意事项。接着,优化原理章节深入探讨了查询优化器的作用、执行计划的解读、索引原理与优化策略,以及性能监控与分析技巧。高级技巧章节则涉及联合查询、子查询、数据聚合、分组、字符串处理等高级技巧的应用。此外,通过数据操作实践章节,本文提供了高效的数据操作方法、视图和存储过程的应用,以及错误处理和调试的策略。最后,通过实际案例的分析,本文展示了数据库设计的最佳实践、复杂查询的优化、以及数据库维护与备份策略。整体而言,本文旨在为数据库开发者提供一个全面的SQL知识框架,并强调了理论与实践相
【自动化测试框架剖析】:LMS_Test.Lab应用案例深度解析

# 摘要
本文全面介绍了LMS_Test.Lab自动化测试框架,从其架构和组件讲起,深入探讨了框架支持的测试类型和方法、项目管理策略以及自动化脚本的编写与调试。
【STM32串口DMA全攻略】:从新手到专家的数据接收秘籍
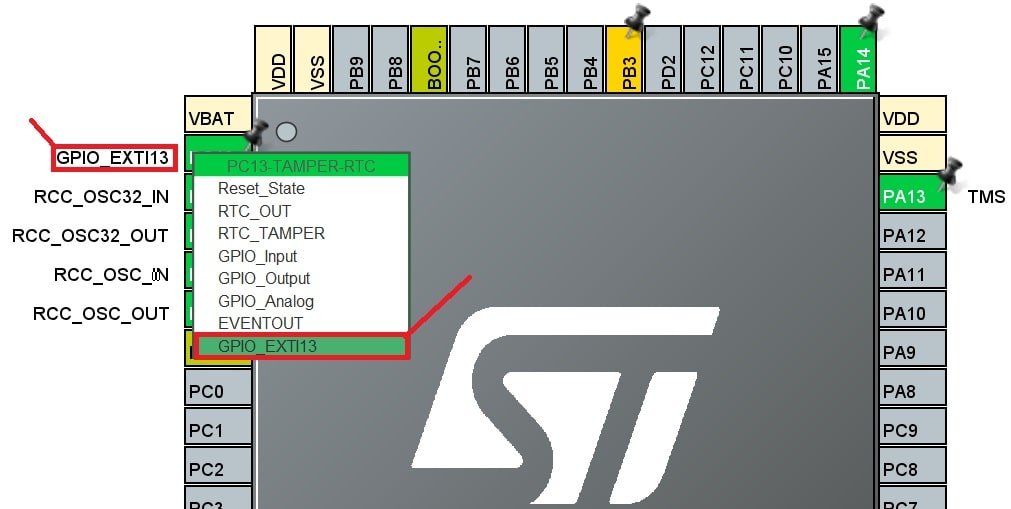
# 摘要
本文全面介绍了STM32微控制器与串口通信中DMA(直接内存访问)技术的应用。从基础概念到深入优化,文章详细探讨了DMA在串口通信中的工作原理、配置流程以及传输模式,并提供了实践应用中的编程案例和常见问题解决方案。文中还讨论了DMA传输的实时性优化策略、与低功耗模式的结合方法,以及
【供电系统升级】:机械厂供电系统改造的成本效益分析
# 摘要
本文全面探讨了供电系统升级改造的各个方面,首先概述了供电系统升级的必要性和理论基础,包括供电系统的基本组成、性能指标以及技术改造的必要性。随后,文章深入分析了供电系统改造的成本效益,从理论上解释了成本效益分析的意义,并通过具体案例展示了实践应用。此外,本文还对供电系统改造的成本进行了详细考量,从初期投资到运营维护成本进行了评估,并预测了改造带来的直接与间接效益。最后,文章总结了供电系统改造项目的关键因素,并对未来的发展方向和策略提出了建议。
# 关键字
供电系统升级;成本效益分析;技术改造;投资成本;运营维护;可持续发展
参考资源链接:[工厂供电课程设计_某机械厂降压变电所的电气
【元数据管理】:深入解析PDF元数据的作用及其管理方法(元数据操作全攻略)
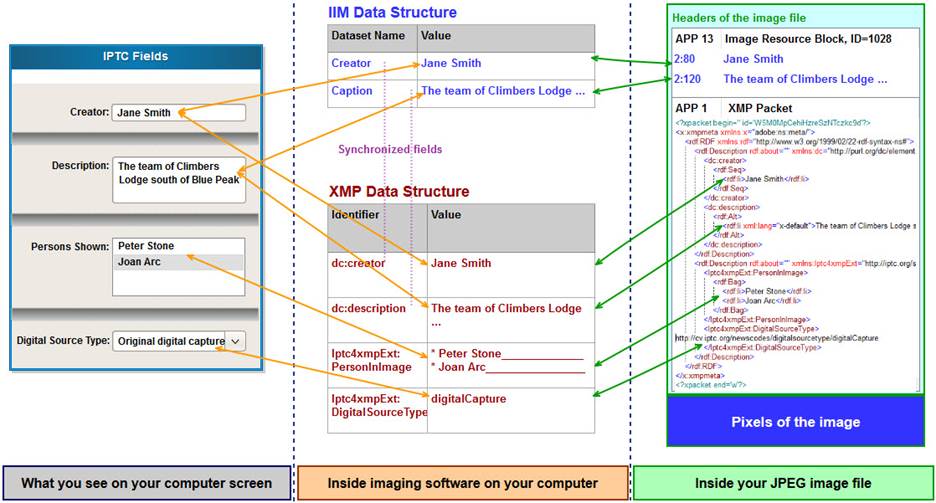
# 摘要
本文系统地探讨了元数据管理的概念及其重要性,并专注于PDF格式元数据的作用、结构、提取、编辑、保护和安全等方面。通过分析元数据在信息管理中的关键角色,本文详细阐述了PDF元数据的类型、结构以及在数字图书馆、档案管理和在线文档共享中的应用。文中还介绍了多种提取与查看PDF元数据的技术手段,包括命令行工具
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )