【MATLAB算法优化101】:从菜鸟到高手,提升算法效率
发布时间: 2024-06-12 21:38:25 阅读量: 91 订阅数: 39 

Matlab教程(从新手到神级级玩家)

# 1. MATLAB算法优化基础**
MATLAB算法优化是指通过各种技术和策略,提高MATLAB代码的执行效率和性能。它涉及分析算法的复杂度、选择合适的算法和数据结构,以及优化代码结构和实现。
算法优化对于处理大型数据集、复杂计算和实时应用至关重要。通过优化算法,可以显著减少执行时间,提高程序响应速度,并节省计算资源。
# 2. MATLAB算法性能分析
### 2.1 算法复杂度分析
算法复杂度是衡量算法效率的重要指标,它描述了算法执行时间与输入规模之间的关系。MATLAB中常用的复杂度分析方法包括:
- **渐进分析:**使用大O符号来表示算法在输入规模趋于无穷大时的复杂度。例如,O(n)表示算法执行时间与输入规模n成正比。
- **经验分析:**通过实际运行算法来测量其执行时间,并绘制执行时间与输入规模之间的关系曲线。
### 2.2 性能分析工具和方法
MATLAB提供了多种性能分析工具和方法,用于分析算法的执行时间和资源占用情况:
- **tic/toc:**用于测量代码段的执行时间。
- **profile:**生成函数调用树,显示每个函数的执行时间和调用次数。
- **perfview:**交互式性能分析工具,可显示函数调用树、内存占用情况和CPU利用率等信息。
**代码块:**
```matlab
% 使用 tic/toc 测量代码段执行时间
tic;
% 执行代码段
toc;
```
**逻辑分析:**
tic和toc函数用于测量代码段的执行时间。tic启动计时器,toc停止计时器并返回从tic开始到toc结束的执行时间。
**代码块:**
```matlab
% 使用 profile 分析函数调用树
profile on;
% 执行代码段
profile viewer;
```
**逻辑分析:**
profile函数启动性能分析,记录函数调用树和执行时间等信息。profile viewer命令打开交互式性能分析工具,显示函数调用树,允许用户深入分析函数的执行情况。
**代码块:**
```matlab
% 使用 perfview 进行交互式性能分析
perfview;
% 执行代码段
```
**逻辑分析:**
perfview命令启动交互式性能分析工具。该工具提供了多种视图,包括函数调用树、内存占用情况和CPU利用率等信息。用户可以在perfview中分析算法的性能瓶颈和优化机会。
# 3. MATLAB算法优化策略
### 3.1 数据结构优化
数据结构是组织和存储数据的基本方式,选择合适的数据结构可以显著提高算法的性能。MATLAB提供了丰富的内置数据结构,包括数组、结构体、单元格数组、哈希表和链表等。
**数组**是MATLAB中存储同类型数据的基本数据结构,它具有快速访问和索引的特点。对于大规模数据处理,使用稀疏数组可以节省大量内存空间。
**结构体**允许将不同类型的数据组织成一个单一实体,便于管理和访问。它可以包含字段、方法和属性,为复杂数据结构提供了灵活性和可扩展性。
**单元格数组**是一种动态数据结构,可以存储不同类型和大小的数据,包括数组、结构体和函数句柄。它提供了极大的灵活性,但访问和索引速度可能较慢。
**哈希表**是一种基于键值对的数据结构,可以快速查找和插入数据。它对于查找操作频繁的数据集非常有用。
**链表**是一种线性数据结构,由节点组成,每个节点包含数据和指向下一个节点的指针。它可以有效地插入和删除元素,但随机访问速度较慢。
### 3.2 算法选择与设计
算法选择是优化MATLAB代码的关键因素。对于给定的问题,可能有多种算法可供选择,每种算法都有自己的优点和缺点。
**时间复杂度**是衡量算法执行时间的一种度量,它描述了算法执行所需的时间与输入规模之间的关系。常见的复杂度包括O(1)、O(n)、O(n^2)、O(log n)等。
**空间复杂度**是衡量算法内存使用的一种度量,它描述了算法执行所需的空间与输入规模之间的关系。常见的复杂度包括O(1)、O(n)、O(n^2)等。
在选择算法时,需要考虑问题的规模、输入类型和所需的性能要求。对于大规模数据集,选择时间复杂度较低的算法至关重要。对于需要快速响应的应用程序,选择空间复杂度较低的算法更为合适。
### 3.3 代码优化
代码优化是指通过修改代码结构和语法来提高其性能。MATLAB提供了多种优化技术,包括:
**向量化**是利用MATLAB的向量和矩阵运算来避免循环,从而提高代码效率。它可以显著减少代码行数和执行时间。
**预分配**是指在循环开始前预先分配内存空间,避免多次分配和释放内存带来的性能开销。
**避免不必要的拷贝**是指通过使用引用或指针传递数据,避免不必要的内存拷贝操作。
**使用内置函数**MATLAB提供了大量的内置函数,可以高效地执行常见任务,例如数学运算、字符串操作和文件处理。使用内置函数可以避免编写自定义代码,并确保代码的可靠性和性能。
**代码审查**定期审查代码可以发现潜在的性能瓶颈和错误。通过识别和修复这些问题,可以显著提高代码的性能和可维护性。
# 4. MATLAB算法优化实践
### 4.1 矩阵运算优化
矩阵运算在MATLAB中非常常见,优化矩阵运算可以显著提高算法性能。以下是一些优化矩阵运算的策略:
- **使用内置函数:**MATLAB提供了许多高效的内置函数来执行矩阵运算,如`sum()`、`mean()`和`std()`。这些函数通常比手动实现的循环更快。
- **避免不必要的复制:**在矩阵运算中,避免创建不必要的副本。例如,使用`A(:)`而不是`A`来创建矩阵的副本。
- **使用稀疏矩阵:**对于稀疏矩阵(即大部分元素为零),使用稀疏矩阵格式可以节省内存和计算时间。
- **利用并行计算:**MATLAB支持并行计算,可以将矩阵运算分解为多个任务并行执行。
```
% 创建一个1000x1000的矩阵
A = rand(1000);
% 使用内置函数计算矩阵和
sum_A = sum(A);
% 使用循环手动计算矩阵和
sum_A_manual = 0;
for i = 1:1000
for j = 1:1000
sum_A_manual = sum_A_manual + A(i, j);
end
end
% 比较执行时间
tic;
sum_A = sum(A);
time_builtin = toc;
tic;
sum_A_manual = 0;
for i = 1:1000
for j = 1:1000
sum_A_manual = sum_A_manual + A(i, j);
end
end
time_manual = toc;
disp(['内置函数执行时间:' num2str(time_builtin)]);
disp(['手动循环执行时间:' num2str(time_manual)]);
```
### 4.2 循环优化
循环是MATLAB算法中另一个常见的性能瓶颈。以下是一些优化循环的策略:
- **使用向量化操作:**向量化操作可以将循环转换为元素级操作,从而提高效率。例如,使用`.*`而不是`for`循环来执行逐元素乘法。
- **预分配内存:**在循环开始前预分配内存可以避免多次内存分配,从而提高性能。
- **避免嵌套循环:**嵌套循环会显著降低性能,应尽量避免。
```
% 创建一个1000x1000的矩阵
A = rand(1000);
% 使用向量化操作计算矩阵和
sum_A = sum(A, 2);
% 使用嵌套循环手动计算矩阵和
sum_A_manual = zeros(1000, 1);
for i = 1:1000
for j = 1:1000
sum_A_manual(i) = sum_A_manual(i) + A(i, j);
end
end
% 比较执行时间
tic;
sum_A = sum(A, 2);
time_vectorized = toc;
tic;
sum_A_manual = zeros(1000, 1);
for i = 1:1000
for j = 1:1000
sum_A_manual(i) = sum_A_manual(i) + A(i, j);
end
end
time_manual = toc;
disp(['向量化操作执行时间:' num2str(time_vectorized)]);
disp(['嵌套循环执行时间:' num2str(time_manual)]);
```
### 4.3 函数调用优化
函数调用也会影响算法性能。以下是一些优化函数调用的策略:
- **避免不必要的函数调用:**只在需要时才调用函数。
- **内联函数:**对于小函数,可以内联到主代码中,以避免函数调用的开销。
- **使用匿名函数:**匿名函数可以避免创建新的函数对象,从而提高性能。
```
% 定义一个函数
function my_function(x)
y = x^2;
end
% 使用函数调用
y = my_function(5);
% 内联函数
y = 5^2;
% 使用匿名函数
y = @(x) x^2;
y = y(5);
% 比较执行时间
tic;
y = my_function(5);
time_function = toc;
tic;
y = 5^2;
time_inline = toc;
tic;
y = @(x) x^2;
y = y(5);
time_anonymous = toc;
disp(['函数调用执行时间:' num2str(time_function)]);
disp(['内联函数执行时间:' num2str(time_inline)]);
disp(['匿名函数执行时间:' num2str(time_anonymous)]);
```
# 5. MATLAB算法优化高级技巧**
MATLAB提供了多种高级技巧来进一步优化算法性能。这些技巧包括:
**5.1 并行计算优化**
MATLAB支持并行计算,允许在多核处理器或分布式系统上并行执行代码。这可以显著提高涉及大量计算任务的算法的性能。
**并行计算示例:**
```matlab
% 创建一个并行池
parpool(4);
% 创建一个需要并行化的函数
function result = myParallelFunction(x)
% 执行一些计算
result = x^2;
end
% 创建一个数据数组
data = 1:10000;
% 并行计算结果
results = parfeval(@myParallelFunction, 1, data);
% 关闭并行池
delete(gcp);
```
**5.2 GPU加速优化**
MATLAB支持使用图形处理器(GPU)来加速计算。GPU具有大量并行处理单元,非常适合执行数据密集型任务。
**GPU加速示例:**
```matlab
% 创建一个 GPU 数组
data = gpuArray(1:10000);
% 在 GPU 上执行计算
result = gpuArray.abs(data);
% 将结果从 GPU 传输到 CPU
result = gather(result);
```
**5.3 人工智能算法优化**
MATLAB提供了各种人工智能(AI)算法,可以用于优化复杂问题。这些算法包括机器学习、深度学习和强化学习。
**AI算法优化示例:**
```matlab
% 加载训练数据
data = load('training_data.mat');
% 创建一个神经网络
net = feedforwardnet(10, 10, 1);
% 训练神经网络
net = train(net, data.inputs, data.targets);
% 使用神经网络进行预测
predictions = net(data.test_inputs);
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
**MATLAB 算法专栏:从菜鸟到高手**
本专栏旨在帮助 MATLAB 用户提升算法技能,涵盖从基础优化到高级设计模式的各个方面。通过深入探讨常见问题、解锁优化策略、掌握并行化技巧和可视化技术,您将学会提升算法效率、准确性、稳定性和可维护性。此外,您还将了解算法选择、数据结构、复杂度分析、数值方法和机器学习中的算法应用。本专栏为您提供全面的知识和实用技巧,让您从 MATLAB 算法菜鸟蜕变为算法高手,提升代码可靠性、可扩展性和性能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【状态机深度解析】:在Verilog中如何设计高效自动售货机
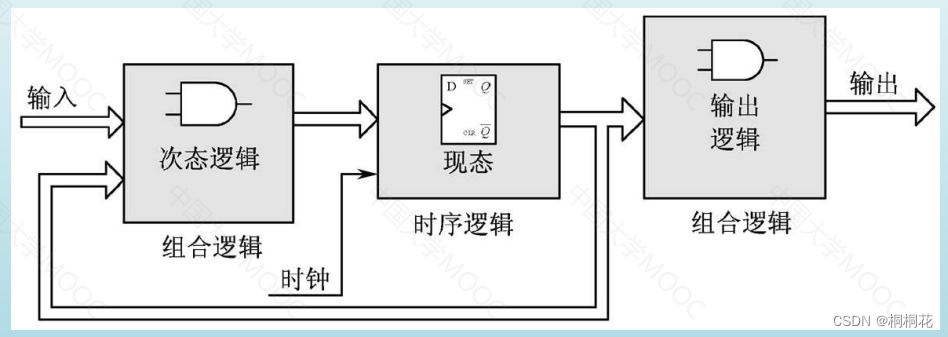
# 摘要
本文系统地探讨了状态机的设计与应用,首先介绍了状态机设计的基础知识,并详细阐述了在Verilog中实现状态机的设计原则,包括状态的分类、建模方法、状态编码及转换表的设计。接着,针对自动售货机的场景,本文详细描述了状态机的设计实现过程,包括用户界面交互、商品选择、货币处理和状态转换逻辑编写等。此外,还探讨了状态机的设计验证与测试,包括测试环境构建、仿真测试、调试和硬件实现验证。最后,本文提出了状态机优化的方法,并讨论了状态机在其他领域中的应
【MATLAB高级索引攻略】:解锁数据处理的隐藏技能

# 摘要
MATLAB作为一种高效的数据处理工具,其高级索引技术在数据科学领域发挥着重要作用。本文首先概述了MATLAB高级索引的基本概念与作用,随后深入探讨了索引操作的数学原理及数据结构。进一步,文章详细介绍了MATLAB高级索引实践技巧,包括复杂条件下的索引应用和高效数据提取与处理方法。在数据处理应用方面,本文阐述了处理大型数据集的索引策略、多维数据的可视化索引技术,以及M
C语言高级编程:子程序参数传递的全面解析
# 摘要
本文深入探讨了C语言中子程序参数传递的机制及其优化技术,首先概述了参数传递的基础知识,随后详细分析了按值传递和按引用传递的优缺点,以及在实现机制中的具体应用,包括内存中的参数布局、指针的作用和复合数据类型的传递。文章进一步探讨了高级参数传递技术,如指针的指针、const修饰符的使用以及可变参数列表的处理,并通过实践案例和最佳实践,讨论了在实际项目中应用这些技术的策略和技巧。本文旨在为C语言开发者提供系
【故障无忧】:西门子SINUMERIK 840D sl_828D测量循环问题全解析及解决之道

# 摘要
本文对西门子数控系统的核心组件SINUMERIK 840D sl/828D的测量循环功能进行了详尽的探讨。文章首先概述了测量循环的基本概念及其在制造业中的应用价值,然后详细介绍了测量循环的操作流程、编程指令以及高级应用技巧。通过故障分析章节,本文分类并识别了测量循环中常见的硬件和软件故障,提供了故障案例分析以及预防和监控策略。进一步地
数字签名机制全解析:RSA和ECDSA的工作原理及应用

# 摘要
本文全面概述了数字签名机制,详细介绍了公钥加密的理论基础,包括对称与非对称加密的原理和局限性、大数分解及椭圆曲线数学原理。通过深入探讨RSA和ECDSA算法的工作原理,本文揭示了两种算法在密钥生成、加密解密、签名验证等方面的运作机制,并分析了它们相对于传统加密方式
【CAD2002高级技巧】
# 摘要
本文对CAD2002软件进行全面的介绍和分析,从软件概述、界面布局、基础操作深入剖析,到绘图与编辑技巧实战,再到高级功能拓展以及优化与故障排除。文章详细阐述了CAD2002的工具与命令高级使用技巧、图层管理、块与外部参照应用等基础操作,深入探讨了精确绘图、高级编辑命令和综合绘图案例。此外,还介绍了CAD2002的参数化绘图、数据交换、自定义脚本编写等高级功能,以及性
Word 2016 Endnotes加载项疑难杂症:专家级解决方案
# 摘要
本文详细介绍了Word 2016中Endnotes功能的概述、工作原理、常见问题诊断以及应用实践,并展望了其发展。首先,对Endnotes功能进行了基础性的介绍,并探讨了其加载项的结构和作用。接着,分析了在使用Endnotes加载项时可能遇到的问题,包括不工作、冲突以及性能问题,并提
【搜索引擎查询优化】:提速与相关性提升的双重攻略

# 摘要
本文旨在综述搜索引擎查询优化的各个方面,从搜索引擎的工作原理、查询优化策略到实践案例分析,再到未来趋势。首先介绍了搜索引擎的基础工作流程,包括爬虫抓取、索引构建、查询处理和排名算法。随后,探讨了提升网页相关性、前端性能优化以及CDN和缓存机制的使用。案例分析部分深入研究了相关性改进、响应时间加
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )